
🚀 Active PRM
Collection
Efficient Process Reward Model Training via Active Learning.
•
4 items
•
Updated
•
3
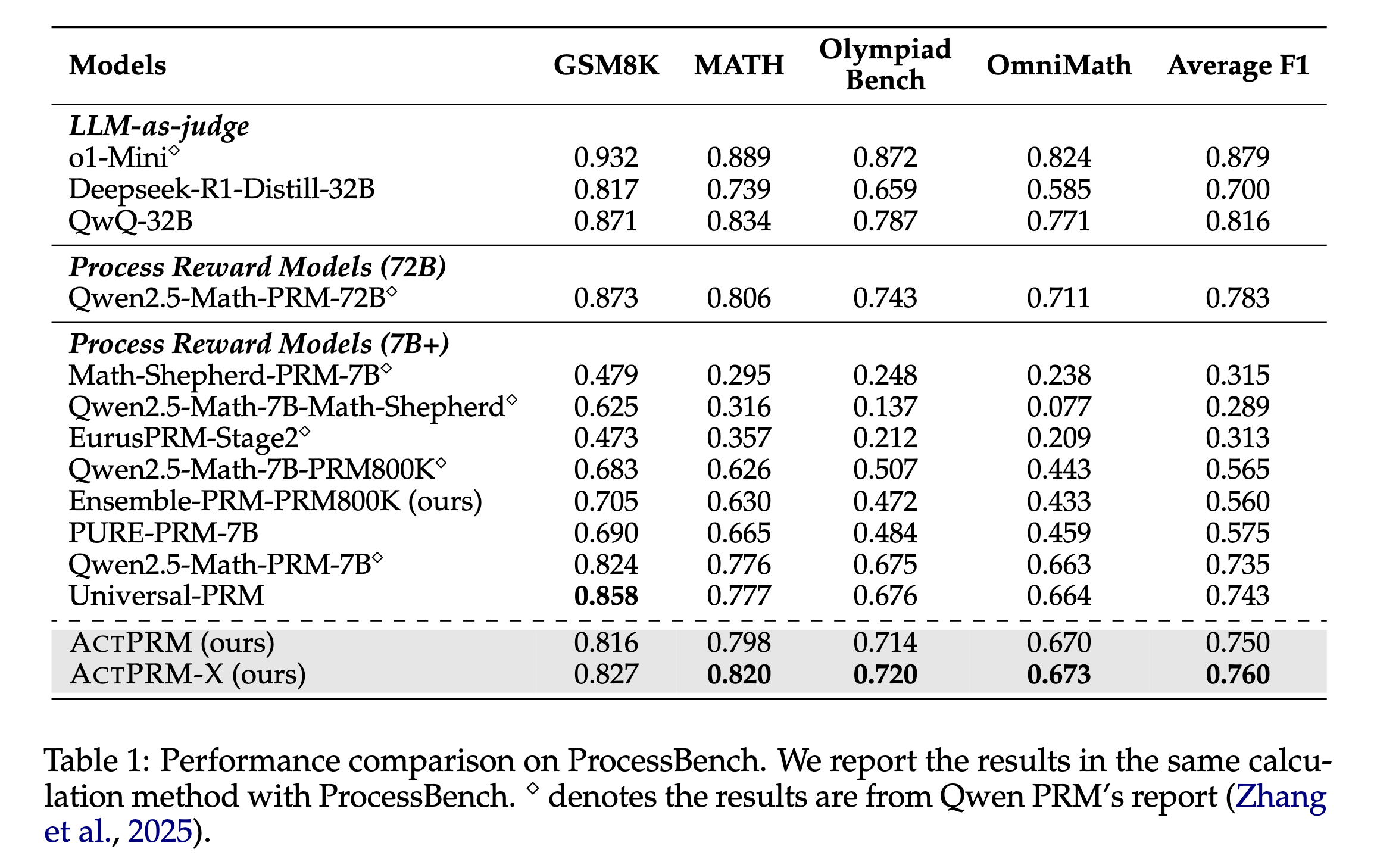
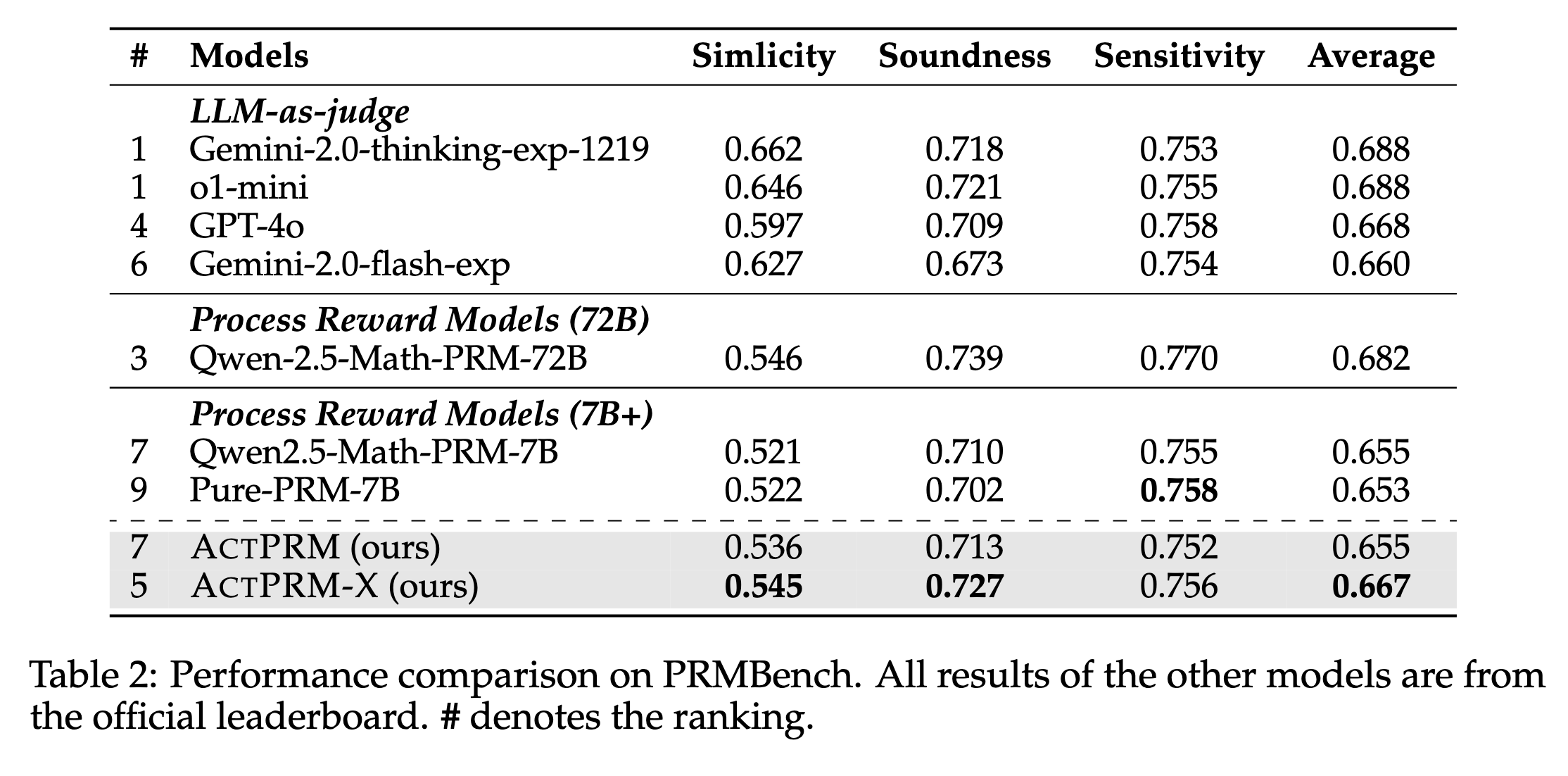
We release our process reward model effectively trained with active learning based on Qwen/Qwen2.5-Math-PRM-7B.
The model achieved 76.0% on ProcessBench and 66.7% on PRMBench.
Both achieve new state-of-the-art (SOTA) performance among 7B parameter models (as of 15/04/2025).
We provide a code snippet to show the usage of our PRM.
# modified from https://huggingface.co/Qwen/Qwen2.5-Math-PRM-7B/blob/main/README.md
from transformers import AutoModel, AutoTokenizer
def make_step_rewards(logits, token_masks):
res = []
for j in range(outputs.logits.size(1)):
logits = outputs.logits[:, j, token_masks[j]]
logits = logits.mean(dim=0)
res.append(logits.tolist())
return res
model_name = "sail/ActPRM-X"
device = "auto"
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
model = (
AutoModel.from_pretrained(
model_name,
torch_dtype="auto",
trust_remote_code=True,
)
.eval()
.to("cuda")
)
data = {
"system": "Please reason step by step, and put your final answer within \\boxed{}.",
"query": "Sue lives in a fun neighborhood. One weekend, the neighbors decided to play a prank on Sue. On Friday morning, the neighbors placed 18 pink plastic flamingos out on Sue's front yard. On Saturday morning, the neighbors took back one third of the flamingos, painted them white, and put these newly painted white flamingos back out on Sue's front yard. Then, on Sunday morning, they added another 18 pink plastic flamingos to the collection. At noon on Sunday, how many more pink plastic flamingos were out than white plastic flamingos?",
"response": [
"To find out how many more pink plastic flamingos were out than white plastic flamingos at noon on Sunday, we can break down the problem into steps. First, on Friday, the neighbors start with 18 pink plastic flamingos.",
"On Saturday, they take back one third of the flamingos. Since there were 18 flamingos, (1/3 \\times 18 = 6) flamingos are taken back. So, they have (18 - 6 = 12) flamingos left in their possession. Then, they paint these 6 flamingos white and put them back out on Sue's front yard. Now, Sue has the original 12 pink flamingos plus the 6 new white ones. Thus, by the end of Saturday, Sue has (12 + 6 = 18) pink flamingos and 6 white flamingos.",
"On Sunday, the neighbors add another 18 pink plastic flamingos to Sue's front yard. By the end of Sunday morning, Sue has (18 + 18 = 36) pink flamingos and still 6 white flamingos.",
"To find the difference, subtract the number of white flamingos from the number of pink flamingos: (36 - 6 = 30). Therefore, at noon on Sunday, there were 30 more pink plastic flamingos out than white plastic flamingos. The answer is (\\boxed{30}).",
],
}
messages = [
{"role": "system", "content": data["system"]},
{"role": "user", "content": data["query"]},
{"role": "assistant", "content": "<extra_0>".join(data["response"]) + "<extra_0>"},
]
conversation_str = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=False)
input_ids = tokenizer.encode(
conversation_str,
return_tensors="pt",
).to(model.device)
outputs = model.inference(input_ids=input_ids)
step_sep_id = tokenizer.encode("<extra_0>")[0]
token_masks = input_ids == step_sep_id
step_reward = make_step_rewards(outputs[0], token_masks)
print(step_reward) # [[0.9993686676025391, 0.2316841036081314, 0.7311716079711914, 0.8314468264579773]]
Base model
Qwen/Qwen2.5-7B