
txt
stringlengths 93
37.3k
|
|---|
## dist_zef-p6steve-Dan.md
# raku Dan
Top level raku **D**ata **AN**alysis Module that provides **a base set of raku-style** datatype roles, accessors & methods, primarily:
* DataSlices
* Series
* DataFrames
A common basis for bindings such as ... [Dan::Pandas](https://github.com/p6steve/raku-Dan-Pandas) (via Inline::Python), Dan::Polars(tbd) (via NativeCall / Rust FFI), etc.
It's rather a zen concept since raku contains many Data Analysis constructs & concepts natively anyway (see note 7 below)
Contributions via PR are very welcome - please see the backlog Issue, or just email [p6steve@furnival.net](mailto:p6steve@furnival.net) to share ideas!
# SYNOPOSIS
more examples in [bin/synopsis.raku](https://github.com/p6steve/raku-Dan/blob/main/bin/synopsis-dan.raku)
```
### Series ###
my \s = Series.new( [b=>1, a=>0, c=>2] ); #from Array of Pairs
# -or- Series.new( [rand xx 5], index => <a b c d e>);
# -or- Series.new( data => [1, 3, 5, NaN, 6, 8], index => <a b c d e f>, name => 'john' );
say ~s;
# Accessors
say s[1]; #2 (positional)
say s<b c>; #2 1 (associative with slice)
# Map/Reduce
say s.map(*+2); #(3 2 4)
say [+] s; #3
# Hyper
say s >>+>> 2; #(3 2 4)
say s >>+<< s; #(2 0 4)
# Update
s.data[1] = 1; # set value
s.splice(1,2,(j=>3)); # update index & value
# Combine
my \t = Series.new( [f=>1, e=>0, d=>2] );
s.concat: t; # concatenate
say "=============================================";
### DataFrames ###
my \dates = (Date.new("2022-01-01"), *+1 ... *)[^6];
my \df = DataFrame.new( [[rand xx 4] xx 6], index => dates, columns => <A B C D> );
# -or- DataFrame.new( [rand xx 5], columns => <A B C D>);
# -or- DataFrame.new( [rand xx 5] );
say ~df;
say "---------------------------------------------";
# Data Accessors [row;col]
say df[0;0];
df[0;0] = 3; # set value
# Cascading Accessors (ok to mix Positional and Associative)
say df[0][0];
say df[0]<A>;
say df{"2022-01-03"}[1];
# Object Accessors & Slices (see note 1)
say ~df[0]; # 1d Row 0 (DataSlice)
say ~df[*]<A>; # 1d Col A (Series)
say ~df[0..*-2][1..*-1]; # 2d DataFrame
say ~df{dates[0..1]}^; # the ^ postfix converts an Array of DataSlices into a new DataFrame
say "---------------------------------------------";
### DataFrame Operations ###
# 2d Map/Reduce
say df.map(*.map(*+2).eager);
say [+] df[*;1];
say [+] df[*;*];
# Hyper
say df >>+>> 2;
say df >>+<< df;
# Transpose
say ~df.T;
# Describe
say ~df[0..^3]^; # head
say ~df[(*-3..*-1)]^; # tail
say ~df.shape;
say ~df.describe;
# Sort
say ~df.sort: { .[1] }; # sort by 2nd col (ascending)
say ~df.sort: { -.[1] }; # sort by 2nd col (descending)
say ~df.sort: { df[$++]<C> }; # sort by col C
say ~df.sort: { df.ix[$++] }; # sort by index
# Grep (binary filter)
say ~df.grep( { .[1] < 0.5 } ); # by 2nd column
say ~df.grep( { df.ix[$++] eq <2022-01-02 2022-01-06>.any } ); # by index (multiple)
say "---------------------------------------------";
my \df2 = DataFrame.new([
A => 1.0,
B => Date.new("2022-01-01"),
C => Series.new(1, index => [0..^4], dtype => Num),
D => [3 xx 4],
E => Categorical.new(<test train test train>),
F => "foo",
]);
say ~df2;
say df2.data;
say df2.dtypes;
say df2.index; #Hash (name => row number) -or- df.ix; #Array
say df2.columns; #Hash (label => col number) -or- df.cx; #Array
say "---------------------------------------------";
### DataFrame Splicing ### (see notes 2 & 3)
# row-wise splice:
my $ds = df2[1]; # get a DataSlice
$ds.splice($ds.index<d>,1,7); # tweak it a bit
df2.splice( 1, 2, [j => $ds] ); # default
# column-wise splice:
my $se = df2.series: <a>; # get a Series
$se.splice(2,1,7); # tweak it a bit
df2.splice( :ax, 1, 2, [K => $se] ); # axis => 1
say "---------------------------------------------";
### DataFrame Concatenation ### (see notes 4 & 5)
my \dfa = DataFrame.new(
[['a', 1], ['b', 2]],
columns => <letter number>,
);
#`[
letter number
0 a 1
1 b 2
#]
my \dfc = DataFrame.new(
[['c', 3, 'cat'], ['d', 4, 'dog']],
columns => <animal letter number>,
);
#`[
letter number animal
0 c 3 cat
1 d 4 dog
#]
dfa.concat: dfc; # row-wise / outer join is default
#`[
letter number animal
0 a 1 NaN
1 b 2 NaN
0⋅1 c 3 cat
1⋅1 d 4 dog
#]
dfa.concat: dfc, join => 'inner';
#`[
letter number
0 a 1
1 b 2
0⋅1 c 3
1⋅1 d 4
#]
my \dfd = DataFrame.new( [['bird', 'polly'], ['monkey', 'george']],
columns=> <animal name>, );
dfb.concat: dfd, axis => 1; #column-wise
#`[
letter number animal name
0 a 1 bird polly
1 b 2 monkey george
#]
say "=============================================";
```
Notes:
[1] raku accessors may use any function that makes a List, e.g.
Positional slices: `[1,3,4], [0..3], [0..*-2], [*]`
Associative slices: `<A C D>, {'A'..'C'}`
viz. <https://docs.raku.org/language/subscripts>
[2] splice is the core update method
for all add, drop, move, delete, update & insert operations
viz. <https://docs.raku.org/routine/splice>
[3] named parameter 'axis' indicates if row(0) or col(1)
if omitted, default=0 (row) / 'ax' is an alias
use a Pair literal like `:!axis, :axis(1) or :ax`
[4] concat is the core combine method
for all join, merge & combine operations
duplicate labels are extended with `$mark ~ $i++`
`# $mark = '⋅'; # unicode Dot Operator U+22C5`
use `:ii (:ignore-index)` to reset the index (row or col)
[5] concat supports `join => outer|inner|right|left`
unknown values are set to NaN
default is outer, :jn is alias, and you can go :jn on first letter
set axis param (see splice above) for col-wise concatenation
[6] relies on hypers instead of overriding dyadic operators [+-\*/]
```
say ~my \quants = Series.new([100, 15, 50, 15, 25]);
say ~my \prices = Series.new([1.1, 4.3, 2.2, 7.41, 2.89]);
say ~my \costs = Series.new( quants >>*<< prices );
```
[7] what are we getting from raku core that others do in libraries?
* pipes & maps
* multi-dimensional arrays
* slicing & indexing
* references & views
* map, reduce, hyper operators
* operator overloading
* concurrency
* types (incl. NaN)
|
## -.md
.=
Combined from primary sources listed below.
# [In Operators](#___top "go to top of document")[§](#(Operators)_infix_.= "direct link")
See primary documentation
[in context](/language/operators#infix_.=)
for **infix .=**.
Calls the right-side method on the value in the left-side container, replacing the resulting value in the left-side container.
In most cases, this behaves identically to the postfix mutator, but the precedence is lower:
```raku
my $a = -5;
say ++$a.=abs;
# OUTPUT: «6»
```
```raku
say ++$a .= abs;
# OUTPUT: «Cannot modify an immutable Int
# in block <unit> at <tmp> line 1»
```
|
## dist_zef-lizmat-shorten-sub-commands.md
[](https://github.com/lizmat/shorten-sub-commands/actions) [](https://github.com/lizmat/shorten-sub-commands/actions) [](https://github.com/lizmat/shorten-sub-commands/actions)
# NAME
shorten-sub-commands - allow partial specification of sub-commands
# SYNOPSIS
```
# in script "frobnicate"
multi sub MAIN("foozle") { say "foozle" }
multi sub MAIN("barabas") { say "barabas" }
multi sub MAIN("bazzie") { say "bazzie" }
use shorten::sub::commands &MAIN;
```
```
$ raku frobnicate foo
foozle
$ raku frobnicate ba
'ba' is ambiguous, matches: barabas bazzie
$ raku frobnicate bar
barabas
```
# DESCRIPTION
The `shorten::sub::commands` distribution provides a helper module intended to be used for command-line applications that have a sub-command structure (in which the first positional parameter indicates what needs to be done, and there is a separate candidate to handle execution of that command).
When used **after** all `MAIN` candidates have been defined, it will add another candidate that will allow to shorten the command names to be as short as possible (e.g. just "foo" in the example above, or even just "f" as there is only one candidate that starts with "f". Numeric subcommands are also supported, but they will be matched as strings (so `4` on the command line will match `42` in the signature).
Special care has been taken to ensure that re-dispatch doesn't devolve into an infinite loop.
# AUTHOR
Elizabeth Mattijsen [liz@raku.rocks](mailto:liz@raku.rocks)
Source can be located at: <https://github.com/lizmat/shorten-sub-commands> . Comments and Pull Requests are welcome.
If you like this module, or what I'm doing more generally, committing to a [small sponsorship](https://github.com/sponsors/lizmat/) would mean a great deal to me!
# COPYRIGHT AND LICENSE
Copyright 2022, 2025 Elizabeth Mattijsen
This library is free software; you can redistribute it and/or modify it under the Artistic License 2.0.
|
## dist_zef-patrickb-Cro-HTTP-Middleware-GoatCounter.md
```
=begin pod
=head1 NAME
Cro::HTTP::Middleware::GoatCounter
=head1 SYNOPSIS
=begin code :lang
use Cro::HTTP::Server;
use Cro::HTTP::Middleware::GoatCounter;
my $gc-api-url = "https://MYCODE.goatcounter.com/api/v0";
my $gc-token = "hienaitkyvzjvriheac2402407538153tn7v53c520hihtaylei";
my Cro::Service $http = Cro::HTTP::Server.new(
:$host, :$port,
application => routes(),
before => [
Cro::HTTP::Middleware::GoatCounter.new(
api-url => $gc-api-url,
token => $gc-token
),
],
);
=end code
=head1 DESCRIPTION
This module provides a simple Cro to GoatCounter integration.
See the GoatCounter homepage L for more
information.
=head1 AUTHOR
Patrick Böker
=head1 COPYRIGHT AND LICENSE
Copyright 2020-2024 Patrick Böker
This library is free software; you can redistribute it and/or modify it under the Artistic License 2.0.
=end pod
```
|
## adhoc.md
class X::AdHoc
Error with a custom message
```raku
class X::AdHoc is Exception { }
```
`X::AdHoc` is the type into which objects are wrapped if they are thrown as exceptions, but don't inherit from [`Exception`](/type/Exception).
Its benefit over returning non-[`Exception`](/type/Exception) objects is that it gives access to all the methods from class [`Exception`](/type/Exception), like `backtrace` and `rethrow`.
You can obtain the original object with the `payload` method.
```raku
try {
die [404, 'File not found']; # throw non-exception object
}
print "Got HTTP code ",
$!.payload[0], # 404
" and backtrace ",
$!.backtrace.Str;
```
Note that young code will often be prototyped using `X::AdHoc` and then later be revised to use more specific subtypes of [`Exception`](/type/Exception). As such it is usually best not to explicitly rely on receiving an `X::AdHoc` – in many cases using the string returned by the `.message` method, which all [`Exception`](/type/Exception)s must have, is preferable. Please note that we need to explicitly call `.Str` to stringify the backtrace correctly.
# [Methods](#class_X::AdHoc "go to top of document")[§](#Methods "direct link")
## [method payload](#class_X::AdHoc "go to top of document")[§](#method_payload "direct link")
Returns the original object which was passed to `die`.
## [method Numeric](#class_X::AdHoc "go to top of document")[§](#method_Numeric "direct link")
```raku
method Numeric()
```
Converts the payload to [`Numeric`](/type/Numeric) and returns it
## [method from-slurpy](#class_X::AdHoc "go to top of document")[§](#method_from-slurpy "direct link")
```raku
method from-slurpy (|cap)
```
Creates a new exception from a capture and returns it. The capture will have the `SlurpySentry` role mixed in, so that the `.message` method behaves in a different when printing the message.
```raku
try {
X::AdHoc.from-slurpy( 3, False, "Not here" ).throw
};
print $!.payload.^name; # OUTPUT: «Capture+{X::AdHoc::SlurpySentry}»
print $!.message; # OUTPUT: «3FalseNot here»
```
The `SlurpySentry` role joins the elements of the payload, instead of directly converting them to a string.
|
## dist_zef-lizmat-Updown.md
[](https://github.com/lizmat/Updown/actions) [](https://github.com/lizmat/Updown/actions)
# NAME
Updown - provide basic API to Updown.io
# SYNOPSIS
```
use Updown;
my $ud = Updown.new; # assume API key in UPDOWN_API_KEY
my $ud = Updown.new(api-key => "secret-api-key");
for $ud.checks -> (:key($check-id), :value($check)) {
say "$check.apdex_t() $check.url()"
}
my $event = Updown::Event(%hash); # inside a webhook
```
# DESCRIPTION
Updown provides a simple object-oriented interface to the API as provided by <Updown.io>, a website monitoring service.
Access to functionality is provided through the `Updown` class, which has methods that perform the various functions and return objects in the `Updown::` hierarchy of classes.
The [Updown API](https://updown.io/api) is basically followed to the letter, with a little caching and some minor functional sugar added.
To be consistent with the names used in the API, all identifiers use underscores (snake\_case) in their names, rather then hyphens (kebab-case).
# CLI
This distribution also installs an `updown` command line interface. It (implicitely) takes an `--api-key` parameter (or if none specified, the one in the `UPDOWN_API_KEY` environment). It shows the status of all of the checks associated with that API key, and some more information about a check if a website is down.
# COMPARING
In order to allow you to compare the performance of "your" sites with other, more general sites, the methods accepting a `check_id` can also with one of these named arguments **instead** of a `check_id`:
```
:booking booking.com
:duckduckgo duckduckgo.com
:facebook facebook.com
:github github.com
:google google.com
:raku raku.org
```
# MAIN CLASSES
## Updown
The `Updown` object connects the code with all of the monitoring that has been configured for a user of the [Updown.io](https://updown.io) service.
### Parameters
The following parameters can be specified when creating the `Updown` object:
#### client
A `Cro::HTTP::Client` object that will be used to access the API of `Updown`. Defaults to a default `Cro::HTTP::Client` object.
#### api-key
The API key that should be used to authenticate requests with the `Updown` API. Defaults to the `UPDOWN_API_KEY` environment variable.
Any API key (implicitely) specified will be added to the headers of the `client` object used to facilitate authentication.
### Methods
The following methods are available on the `Updown` object:
#### check
Return the `Updown::Check` object associated with the given "check\_id". Takes an optional named boolean argument `:update` to indicate that the information should be refreshed if it was already obtained before.
#### check\_ids
Returns a list of "check\_id"s of the `Updown::Check`s that are being performed for the user associated with the given API key. Takes an optional named boolean argument `:update` to indicate that the information should be refreshed if it was already obtained before.
#### checks
Returns a `Hash` with `Updown::Check` objects, keyed to their "check\_id". Takes an optional named boolean argument `:update` to indicate that the information should be refreshed if it was already obtained before.
#### downtimes
Returns a list of up to 100 `Node::Downtime` objects for the given "check\_id". Takes an optional `:page` argument to indicate the "page": defaults to `1`.
#### hourly\_metrics
Returns an object `Hash` of `Updown::Metrics` objects for the given "check\_id" about overall metrics per hour, keyed to `DateTime` objects indicating the hour. Optionally takes two named arguments.
`:from`, a `DateTime` object indicating the **start** of the period for which to provide overall metrics. Defaults to `DateTime.now.earlier(:1month)`.
`:to`, a `DateTime` object indicating the **end** of the period for which to provide overal metrics. Defaults to `DateTime.now`.
#### node
Return the `Updown::Node` object associated with the given "node\_id". Takes an optional named boolean argument `:update` to indicate that the information should be refreshed if it was already obtained before.
#### node\_ids
Returns a list of "node\_id"s of the monitoring servers of the `Updown.io` network. Takes an optional named boolean argument `:update` to indicate that the information should be refreshed if it was already obtained before.
#### node\_metrics
Returns a `Hash` of `Updown::Metrics` objects for the given "check\_id" about overall metrics per monitoring server in the `Updown.io` network, keyed to "node\_id". Optionally takes two named arguments.
`:from`, a `DateTime` object indicating the **start** of the period for which to provide overall metrics. Defaults to `DateTime.now.earlier(:1month)`.
`:to`, a `DateTime` object indicating the **end** of the period for which to provide overal metrics. Defaults to `DateTime.now`.
#### nodes
Returns a `Hash` with `Updown::Node` objects, keyed to their "node\_id". Takes an optional named boolean argument `:update` to indicate that the information should be refreshed if it was already obtained before.
#### ipv4-nodes
Returns a list of strings with the IPv4 numbers of the nodes in the `Updown.io` network that are executing the monitoring checks. Takes an optional named boolean argument `:update` to indicate that the information should be refreshed if it was already obtained before.
#### ipv6-nodes
Returns a list of strings with the IPv6 numbers of the nodes in the `Updown.io` network that are executing the monitoring checks. Takes an optional named boolean argument `:update` to indicate that the information should be refreshed if it was already obtained before.
#### overall\_metrics
Returns a `Updown::Metric` object for the given "check\_id". Optionally takes two named arguments.
`:from`, a `DateTime` object indicating the **start** of the period for which to provide overall metrics. Defaults to `DateTime.now.earlier(:1month)`.
`:to`, a `DateTime` object indicating the **end** of the period for which to provide overal metrics. Defaults to `DateTime.now`.
## Updown::Event
Objects of this type are **not** created automatically, but need to be created **directly** with the hash of the JSON received by a server that handles a webhook (so no `Updown` object needs to have been created).
### event
A string indicating the type of event. Can be either "check.down" when a monitored website appears to be down, or "check.up" to indicate that a monitored website has become operational again.
### check
The associated `Updown::Check` object.
### downtime
The associated `Updown::Node` object.
# AUTOMATICALLY CREATED CLASSES
## Updown::Check
An object containing the configuration of the monitoring that the `Updown.io` network does for a given website.
### alias
A string that describes the check, usually a human readable name of the website being monitored.
### apdex\_t
A rational number indicating the [APDEX](https://updown.uservoice.com/knowledgebase/articles/915588) threshold.
### custom\_headers
A hash of custom headers that will be sent to the monitored website.
### disabled\_locations
An array of monitoring locations that have been disabled, indicated by `node_id`.
### down
A boolean that will be true if the website is currently considered to be down.
### down\_since
A `DateTime` object indicating when it was first discovered that the website was down, if down. Else, `Any`.
### enabled
A boolean indicating whether the monitoring is currently active.
### error
A string containing the error that was encountered if the website is considered down.
### favicon\_url
The URL of the favicon small icon representing the website, if any.
### http\_body
Unclear what the functionality is.
### http\_verb
A string describing the HTTP method that will be used to monitor the website. Is one of "GET/HEAD", "POST", "PUT", "PATCH", "DELETE", "OPTIONS".
### last\_check\_at
A `DateTime` object indicating when the last check was done.
### last\_status
An integer indicating the last HTTP status that was received.
### mute\_until
A string indicating until when notifications will be muted. Is either a string consisting of "recovery", "forever", or a `DateTime` object indicating until when notifications will be muted, or `Any` if no muting is in effect.
### next\_check\_at
A `DateTime` object indicating when the next monitoring check will be performed.
### period
An integer indicating the number of seconds between monitoring checks.
### published
A boolean indicating whether the monitoring page is publicly accessible or not.
### ssl
An `Updown::Check::SSL` object, indicating SSL certificate status of the monitored website.
### string\_match
A string that should occur in the first 1MB of the body returned by the monitored website. An empty string indicates no content checking is done.
#### title
Returns a string consisting of either the `.alias`, or the `.url` if there is no alias specified.
### token
A string indicating the identifier (check-id) of this monitoring check configuration.
### uptime
A rational number between 0 and 100 indicating the percentage uptime of the monitored website.
### url
A string consisting of the URL that will be fetched to assess whether the monitored website is up and running.
## Updown::Check::SSL
This object generally occurs as the `ssl` method in the `Updown::Check` object.
### tested\_at
A `DateTime` object indicating when the certificate of the monitored website was checked.
### expires\_at
A `DateTime` object indicating when the certificate of the monitored website will expire.
### valid
A boolean indicating whether the certificate of the monitored website was valid the last time it was checked.
### error
A string indicating the error encountered when checking the validity of the certificate of the monitored server, if any.
## Updown::Downtime
An object describing a downtime period as seen by at least one of the monitoring servers in the `Updown.io` network.
### duration
An integer indicating the number of seconds of downtime, or `Any` if the downtime is not ended yet.
### ended\_at
A `DateTime` object indicating the moment the downtime appeared to have ended, or `Any` if the downtime is not ended yet..
### error
A string describing the reason the website appeared to be down, e.g. a HTTP status code like "500".
### id
A string identifying this particular downtime.
### partial
A boolean indicating whether the downtime was partial or complete (e.g. not being reachable by IPv6, but operating normally with IPv4).
### started\_at
A `DateTime` object indicating the moment the downtime appeared to have started.
## Updown::Metrics
A collection of statistical data applicable for the current situation, or for a certain period, or for a certain `Updown::Node`.
### apdex
A rational number indicating the current [APDEX](https://updown.uservoice.com/knowledgebase/articles/915588) for this set of metrics.
### requests
The associated `Updown::Metrics::Requests` object.
### timings
The associated `Updown::Metrics::Timings` object.
## Updown::Metrics::Requests
This object is usually returned by the "requests" method of the `Updown::Metrics` object.
### by\_response\_time
The associated `Updown::Metrics::Timings::ByResponseTime` object.
### failures
An integer indicating the number of monitoring requests that failed.
### samples
An integer indicating the number of monitoring requests that were done.
### satisfied
An integer indicating the number of monitoring requests that were processed to the user's [APDEX](https://updown.uservoice.com/knowledgebase/articles/915588) satisfaction.
### tolerated
An integer indicating the number of monitoring requests that were processed to the user's [APDEX](https://updown.uservoice.com/knowledgebase/articles/915588) tolerance.
## Updown::Metrics::Requests::ByResponseTime
This object is usually returned by the "by\_response\_time" method of the `Updown::Metrics::Request` object.
### under125
An integer indicating the number of monitoring requests that were processed under 125 milliseconds.
### under250
An integer indicating the number of monitoring requests that were processed under 250 milliseconds.
### under500
An integer indicating the number of monitoring requests that were processed under 500 milliseconds.
### under1000
An integer indicating the number of monitoring requests that were processed under 1 second.
### under2000
An integer indicating the number of monitoring requests that were processed under 2 seconds.
### under4000
An integer indicating the number of monitoring requests that were processed under 4 seconds.
## Updown::Metrics::Timings
This object is usually returned by the "timings" method of the `Updown::Metrics` object.
### connection
An integer indicating the average number of milliseconds it took to set up a connection with the monitored website.
### handshake
An integer indicating the average number of milliseconds it took to do the TLS handshake with the monitored website.
### namelookup
An integer indicating the average number of milliseconds it took to look up the name of the monitored website.
### redirect
An integer indicating the average number of milliseconds it took to process any redirect that the monitored website did. Any value greater than 0 probably indicates a misconfigured URL of the monitored website.
### response
An integer indicating the average number of milliseconds it took for the monitored website to initiate a response.
### total
An integer indicating the average number of milliseconds it took for the monitored website to complete the monitoring request.
## Updown::Node
An object containing information about a monitoring node in the `Updown.io` network.
### city
A string with the name of the city where the monitoring node is located.
### country
A string with the name of the country where the monitoring node is located.
### country\_code
A string with the 2-letter code of the country where the monitoring node is located.
### ip
A string indicating the IPv4 number of the monitoring node.
### ip6
A string indicating the IPv6 number of the monitoring node.
### lat
A rational number indicating the latitude of the monitoring node.
### lng
A rational number indicating the longitude of the monitoring node.
### node\_id
A string indicating the ID with which the monitoring node can be indicated.
## Updown::Webhook
Objects returned by the `webhooks` method of the `Updown` object.
### id
A string identifying this webhook.
### url
A string with the URL to which any notifications should be sent.
# AUTHOR
Elizabeth Mattijsen [liz@raku.rocks](mailto:liz@raku.rocks)
Source can be located at: <https://github.com/lizmat/Updown> . Comments and Pull Requests are welcome.
If you like this module, or what I'm doing more generally, committing to a [small sponsorship](https://github.com/sponsors/lizmat/) would mean a great deal to me!
# COPYRIGHT AND LICENSE
Copyright 2021, 2022, 2024 Elizabeth Mattijsen
This library is free software; you can redistribute it and/or modify it under the Artistic License 2.0.
|
## dist_github-IanTayler-MinG.md
# MinG
A small module for working with Stabler's Minimalist Grammars in Perl6.
[](https://travis-ci.org/IanTayler/MinG)
# STRUCTURE
As of now there are five (sub)modules: MinG, MinG::S13, MinG::S13::Logic, MinG::EDMG and MinG::From::Text.
In MinG, you'll find the necessary classes and subroutines for creating descriptions of Minimalist Grammars. It's not of much use by itself unless you're planning to implement your own parser/etc. and want to save yourself the time of having to define classes and useful functions.
In MinG::S13, you'll find Stabler's (2013) "Two models of minimalist, incremental syntactic analysis" parser. Currently, this parser analyses all possibilities, while Stabler's parser discards low-probability derivations. There's a helper submodule called MinG::S13::Logic.
MinG::EDMG is currently under construction. To check what has been implemented already, you can view the milestone "EDMG Implementation".
Finally, in MinG::From::Text you'll find a parser that creates MinG::Grammar-s out of text descriptions of MGs.
More documentation can be found in HTML files inside the doc/ directory.
# INSTALLATION
If you have perl6 and panda or zef, the following should suffice:
```
zef update
zef install MinG
```
If you don't, the easiest is probably to install rakudobrew <https://github.com/tadzik/rakudobrew> and then run:
```
rakudobrew build moar --gen-moar --gen-nqp --backend=moar
rakudobrew build zef
```
and you should be ready to install this module with zef.
The best option may be to install Rakudo Star <http://rakudo.org/how-to-get-rakudo/> which comes with zef and some common modules. There's lots of tutorials about how to get perl6. Follow one of them and make sure you install zef (or panda).
# EXAMPLE USAGE
As of now, someone who isn't interested in the inner workings of the module but wants to try out some minimalist grammars can easily create their grammar following this template:
```
START=F
word1 :: =F =F -F F
word2 :: =F F
:: =F =F F
.
.
.
word23 :: =F F ...
```
Without the dots, and changing *wordi* for your phonetic word (and, of course, changing F for whatever features you want your grammars to have). For two example grammars, check the resources/ directory.
You can save that in a file and call it using `ming-analyser.p6` (you can use `ming-analyser.p6-j` to run it on the jvm if you have the jvm backend installed and you so wish). Assuming the file is in the directory `$HOME/grammars/` and it's called gr0.mg, you can run:
```
ming-analyser.p6 $HOME/grammars/gr0.mg
```
Each line you write of input will be parsed using your grammar. You can parse several sentences in a series by separating them with a ';'. You can modify gr0.mg at any point and restart `ming-analyser.p6` to have your new grammar working.
If you want to try out the example grammars, they can be accessed by passing the arguments `--eng0` for a very small grammar of something-like-English, copied from Stabler (2013), `--espa0` for a not-so-small (but small) grammar of Spanish written by myself, and --nihongo0 for a minimal grammar of japanese used to exemplify complement directionality in EDMGs. Like so:
```
ming-analyser.p6 --eng0
ming-analyser.p6 --espa0
ming-analyser.p6 --nihongo0
```
When inputting lines, pay attention *not* to put a final dot to your sentence. "dance." is a different word from "dance".
Default output is a list of derived tree descriptions in qtree format. If you have a latex distribution with pdflatex and qtree installed (under GNU/Linux) you can run `ming-analyser` with option `compile=<filename.tex>` to get a pdf with all derived trees for each sentence you input. For example:
```
ming-analyser.p6 --espa0 --compile=mytex.tex
```
Will compile a pdf named mytex.pdf with all derived trees each time you pass a sentence. Do note it will rewrite existing pdfs, so you have to restart the script if you want to get the trees of various sentences in pdf form.
If you want to call a grammar from a file, it should go after all flags (as of now, only the --compile flag can reasonable go with a file). For example:
```
ming-analyser.p6 --compile=mytex.tex $HOME/grammars/gr0.mg
```
# CURRENTLY
* Has classes that correctly describe MGs (MinG::Grammar), MG-LIs (MinG::LItem) and MG-style-features (MinG::Feature).
* Has a subroutine (feature\_from\_str) that takes a string description of a feature (e.g. "=D") and returns a MinG::Feature.
* Has lexical trees for Stabler's (2013) parsing method (MinG::Grammar.litem\_tree).
* Automatically generates LaTeX/qtree code for trees. (Node.qtree inside MinG)
* Has a working parser for MGs! (MinG::S13::Parser or MinG::S13.parse\_and\_spit())
* Has a parser that reads grammars from a file! (MinG::From::Text)
* Has an analyser script (ming-analyser.p6) that can be used to read grammars from files and analyse sentences from standard input.
# TODO
* Allow some useful expansions of MGs (EDMGs are being implemented).
* Make the parser more efficient by adding probabilistic rule-following.
# MAYDO
* Create a probabilistic trainer.
* Use annotated corpora to build lexical entries.
* Use a small subset of predefined lexical entries and a non-annotated corpus to "guess" the feature specification of unknown lexical items.
* Create a Montague-style semantics for MG trees.
* Create a world-model for a knowledgable AI using such semantics.
# AUTHOR
Ian G Tayler, `<iangtayler@gmail.com>`
# COPYRIGHT AND LICENSE
Copyright © 2017, Ian G Tayler [iangtayler@gmail.com](mailto:iangtayler@gmail.com). All rights reserved. This program is free software; you can redistribute it and/or modify it under the Artistic License 2.0.
|
## dist_zef-jonathanstowe-JSON-Marshal.md
# JSON::Marshal
Make JSON from an Object (the opposite of JSON::Unmarshal)

## Synopsis
```
use JSON::Marshal;
class SomeClass {
has Str $.string;
has Int $.int;
has Version $.version is marshalled-by('Str');
}
my $object = SomeClass.new(string => "string", int => 42, version => Version.new("0.0.1"));
my Str $json = marshal($object); # -> "{ "string" : "string", "int" : 42, "version" : "0.0.1" }'
```
Or with *opt-in* marshalling:
```
use JSON::Marshal;
use JSON::OptIn;
class SomeClass {
has Str $.string is json;
has Int $.int is json;
has Str $.secret;
has Version $.version is marshalled-by('Str');
}
my $object = SomeClass.new(secret => "secret", string => "string", int => 42, version => Version.new("0.0.1"));
my Str $json = marshal($object, :opt-in); # -> "{ "string" : "string", "int" : 42, "version" : "0.0.1" }'
```
## Description
This provides a single exported subroutine to create a JSON representation
of an object. It should round trip back into an object of the same class
using [JSON::Unmarshal](https://github.com/tadzik/JSON-Unmarshal).
It only outputs the "public" attributes (that is those with accessors
created by declaring them with the '.' twigil. Attributes without acccessors
are ignored.
If you want to ignore any attributes without a value you can use the
`:skip-null` adverb to `marshal`, which will supress the
marshalling of any undefined attributes. Additionally if you want a
finer-grained control over this behaviour there is a 'json-skip-null'
attribute trait which will cause the specific attribute to be skipped
if it isn't defined irrespective of the `skip-null`. If
you want to always explicitly suppress the marshalling of an attribute then
the the trait `json-skip` on an attribute will prevent it being output
in the JSON.
By default *all* public attributes will be candidates to be marshalled to JSON,
which may not be convenient for all applications (for example only a small
number of attributes should be marshalled in a large class,) so the `marshal`
provides an `:opt-in` adverb that inverts the behaviour so that only those
attributes which have one of the traits that control marshalling
(with the exception of `json-skip`,) will be candidates. The `is json` trait
from [JSON::OptIn](https://github.com/jonathanstowe/JSON-OptIn) can be supplied to
an attribute to mark it for marshalling explicitly, (it is implicit in all the
other traits bar `json-skip`.)
To allow a finer degree of control of how an attribute is marshalled an
attribute trait `is marshalled-by` is provided, this can take either
a Code object (an anonymous subroutine,) which should take as an argument
the value to be marshalled and should return a value that can be completely
represented as JSON, that is to say a string, number or boolean or a Hash
or Array who's values are those things. Alternatively the name of a method
that will be called on the value, the return value being constrained as
above.
By default the JSON produced is *pretty* (that is newlines and indentation,)
which is nice for humans to read but has a lot of superfluous characters in
it, this can be controlled by passing `:!pretty` to `marshal`.
## Installation
Assuming you have a working Rakudo installation, you can install this with `zef` :
```
# From the source directory
zef install .
# Remote installation
zef install JSON::Marshal
```
## Support
Suggestions/patches are welcomed via github at
<https://github.com/jonathanstowe/JSON-Marshal/issues>
## Licence
Please see the <LICENCE> file in the distribution
© Jonathan Stowe 2015, 2016, 2017, 2018, 2019, 2020, 2021
|
## dist_zef-bduggan-App-tmeta.md
# tmeta
A console for your console
[](https://travis-ci.org/bduggan/tmeta)
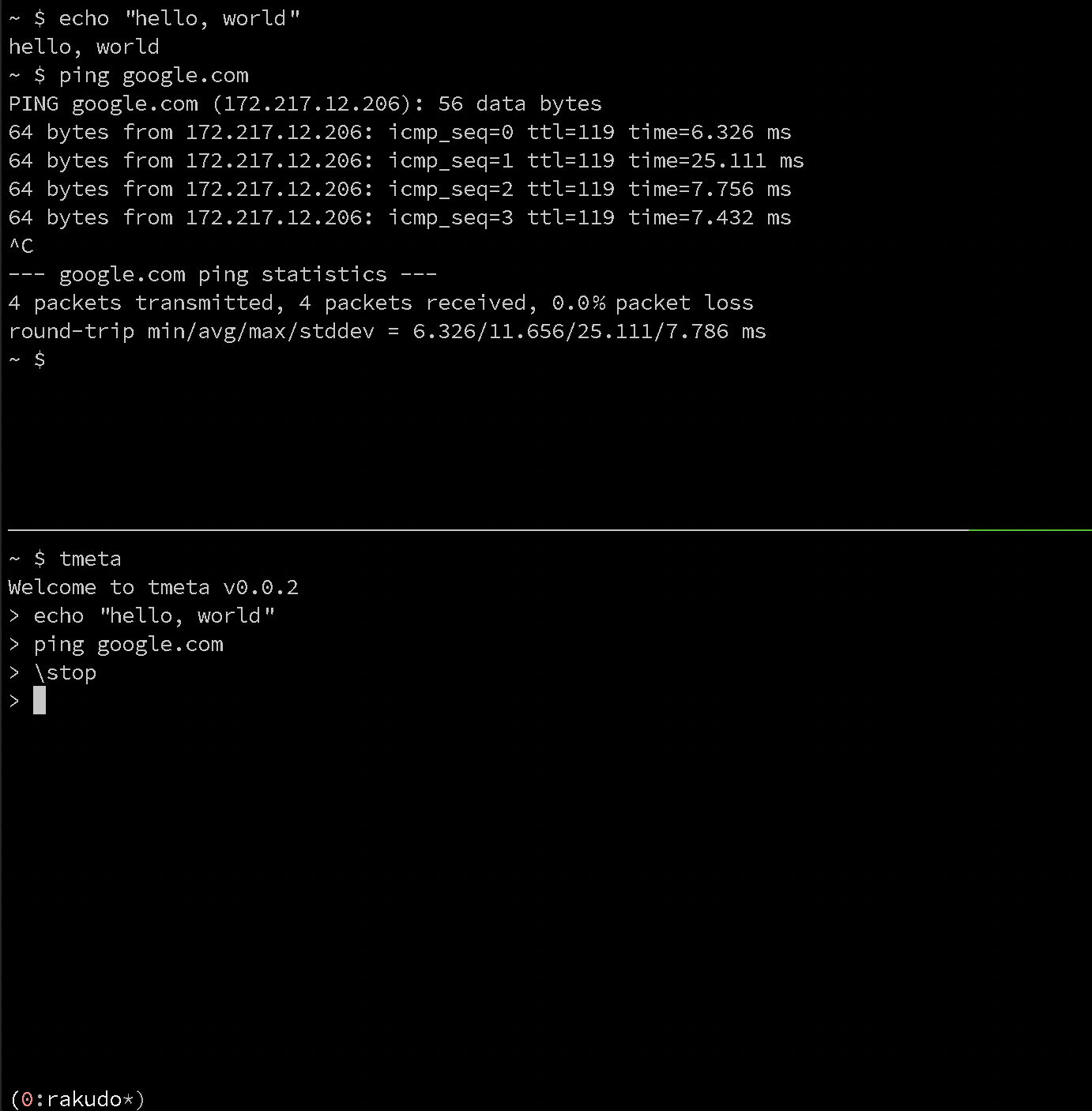
## Description
tmeta is a wrapper for tmux that supports
sending and receiving data to/from tmux panes.
Anything typed into the bottom pane is sent to the top one, but
lines that start with a backslash are commands for `tmeta`.
You can type `\help` to see all possible commands.
(To send a literal leading backslash, either start with a
space or start with a double backslash.)
## Why
Because you get:
* an uncluttered view of your commands separate from the output
* a local history for commands that are run remotely
* readline interface independent of the remote console
* scripting support for programs that require a TTY
* macros
* the ability to monitor or capture output
* other `expect`-like functionality
* controlled copy-and-paste operations into remote sessions
## Quick start
See below for installation.
There are a few different ways to start `tmeta`.
1. Start `tmux` yourself, then have `tmeta` split a window and
start up in its own pane:
```
$ tmux
$ tmeta
```
2. Let `tmeta` start tmux for you:
```
$ tmeta
```
1. Run a tmeta script. This will split and run in another pane.
```
$ tmux
$ tmeta script.tm
```
I use the `.tm` suffix for my `tmeta` scripts. If you do too, you
might like this [vim syntax file](syntax/tm.vim).
## What do I use it with
tmeta plays well with REPLs, or any console based
application that uses a tty. For instance, docker, rails
console, interactive ruby shell, the python debugger, the
jupyter console, psql, mysql, regular ssh sessions, local
terminal sessions, whatever
## More documentation
Please see the [documentation](https://github.com/bduggan/tmeta/blob/master/doc.md) for a complete list of commands.
## Examples
Show a list of commands.
```
> \help
```
Run `date` every 5 seconds until the output contains `02`
```
> date
> \repeat
> \await 02
```
Within a debugger session, send `next` every 2 seconds.
```
> next
> \repeat 2
```
Search the command history for the last occurrence of 'User' using [fzf](https://github.com/junegunn/fzf)
(readline command history works too)
```
> \find User
```
Search the output for "http"
```
> \grep http
```
Send a local file named `bigfile.rb` to a remote rails console
```
> \send bigfile.rb
```
Same thing, but throttle the copy-paste operation, sending 1 line per second:
```
> \delay 1
> \send bigfile.rb
```
Similar, but send it to an ssh console by first tarring and base64 encoding
and not echoing stdout, and note that 'something' can also be a directory:
```
> \xfer something
```
Run a command locally, sending each line of output to the remote console:
```
> \do echo date
```
Run a shell snippet locally, sending each line of output to the remote console:
```
> \dosh for i in `seq 5`; do echo "ping host-$i"; done
```
Start printing the numbers 1 through 100, one per second, but send a ctrl-c
when the number 10 is printed:
```
> \enq \stop
queue is now : \stop
> for i in `seq 100`; do echo $i; sleep 1; done
# .. starts running in other pane ...
> \await 10
Waiting for "10"
Then I will send:
\stop
Done: saw "10"
starting enqueued command: \stop
```
Add an alias `cat` which cats a local file
```
\alias cat \shell cat
```
Show a local file (do not send it to the other pane) using the above alias
```
\cat myfile
```
Edit a file named session.rb, in ~/.tmeta/scripts
```
\edit session.rb
```
After running the above, add this to session.rb:
```
irb
\expect irb(main):001:0>
"hello world"
\expect irb(main):002:0>
exit
```
Now running
```
\run session.rb
```
will start the interactive ruby console (irb) and the following
session should take place on the top panel:
```
$ irb
irb(main):001:0> "hello world"
=> "hello world"
irb(main):002:0> exit
$
```
## Installation
Prerequisites: fzf, tmux, libreadline, raku and a few modules
On OS/X
```
brew install fzf
brew install tmux
brew install rakudo
zef install https://github.com/bduggan/tmeta.git
```
You can also install raku with [rakubrew](https://rakubrew.org)
and then use `zef` to install tmeta.
## See also
* The [documentation](https://github.com/bduggan/tmeta/blob/master/doc.md), with links to the source
* The same [documentation](https://github.com/bduggan/tmeta/blob/master/help.md) as shown by the `\help` command
* This blog article: <https://blog.matatu.org/raku-tmeta>
|
## multipletypeconstraints.md
class X::Parameter::MultipleTypeConstraints
Compilation error due to a parameter with multiple type constraints
```raku
class X::Parameter::MultipleTypeConstraints does X::Comp { }
```
Compile time error thrown when a parameter has multiple type constraints. This is not allowed in Raku.0.
Example:
```raku
sub f(Cool Real $x) { }
```
dies with
「text」 without highlighting
```
```
Parameter $x may only have one prefix type constraint
```
```
# [Methods](#class_X::Parameter::MultipleTypeConstraints "go to top of document")[§](#Methods "direct link")
## [method parameter](#class_X::Parameter::MultipleTypeConstraints "go to top of document")[§](#method_parameter "direct link")
Returns the name of the offensive parameter.
|
## regexes.md
## Chunk 1 of 5
Regexes
Pattern matching against strings
A *regular expression* is a sequence of characters that defines a certain text pattern, typically one that one wishes to find in some large body of text.
In theoretical computer science and formal language theory, regular expressions are used to describe so-called [*regular languages*](https://en.wikipedia.org/wiki/Regular_language). Since their inception in the 1950's, practical implementations of regular expressions, for instance in the text search and replace functions of text editors, have outgrown their strict scientific definition. In acknowledgement of this, and in an attempt to disambiguate, a regular expression in Raku is normally referred to as a [`Regex`](/type/Regex) (from: *reg*ular *ex*pression), a term that is also in common use in other programming languages.
In Raku, regexes are written in a [*domain-specific language*](https://en.wikipedia.org/wiki/Domain-specific_language), i.e. a sublanguage or [*slang*](/language/slangs). This page describes this language, and explains how regexes can be used to search for text patterns in strings in a process called *pattern matching*.
# [Lexical conventions](#Regexes "go to top of document")[§](#Lexical_conventions "direct link")
Fundamentally, Raku regexes are very much like subroutines: both are code objects, and just as you can have anonymous subs and named subs, you can have anonymous and named regexes.
A regex, whether anonymous or named, is represented by a [`Regex`](/type/Regex) object. Yet, the syntax for constructing anonymous and named [`Regex`](/type/Regex) objects differs. We will therefore discuss them in turn.
## [Anonymous regex definition syntax](#Regexes "go to top of document")[§](#Anonymous_regex_definition_syntax "direct link")
An anonymous regex may be constructed in one of the following ways:
```raku
rx/pattern/; # an anonymous Regex object; 'rx' stands for 'regex'
/pattern/; # an anonymous Regex object; shorthand for 'rx/.../'
regex { pattern }; # keyword-declared anonymous regex; this form is
# intended for defining named regexes and is discussed
# in that context in the next section
```
The `rx/ /` form has two advantages over the bare shorthand form `/ /`.
Firstly, it enables the use of delimiters other than the slash, which may be used to improve the readability of the regex definition:
```raku
rx{ '/tmp/'.* }; # the use of curly braces as delimiters makes this first
rx/ '/tmp/'.* /; # definition somewhat easier on the eyes than the second
```
Although the choice is vast, not every character may be chosen as an alternative regex delimiter:
* You cannot use whitespace or alphanumeric characters as delimiters. Whitespace in regex definition syntax is generally optional, except where it is required to distinguish from function call syntax (discussed hereafter).
* Parentheses can be used as alternative regex delimiters, but only with a space between `rx` and the opening delimiter. This is because identifiers that are immediately followed by parentheses are always parsed as a subroutine call. For example, in `rx()` the [call operator](/language/operators#postcircumfix_(_)) `()` invokes the subroutine `rx`. The form `rx ( abc )`, however, *does* define a [`Regex`](/type/Regex) object.
* Use of a colon as a delimiter would clash with the use of [adverbs](/language/regexes#Adverbs), which take the form `:adverb`; accordingly, such use of the colon is forbidden.
* The hash character `#` is not available as a delimiter since it is parsed as the start of a [comment](/language/syntax#Single-line_comments) that runs until the end of the line.
Secondly, the `rx` form allows you to insert [regex adverbs](/language/regexes#Regex_adverbs) between `rx` and the opening delimiter to modify the definition of the entire regex. This is equivalent to inserting the adverb at the beginning of the regex, but may be clearer:
```raku
rx:r:s/pattern/; # :r (:ratchet) and :s (:sigspace) adverbs, defining
# a ratcheting regex in which whitespace is significant
rx/:r:s pattern/; # Same, but possibly less readable
```
Although anonymous regexes are not, as such, *named*, they may effectively be given a name by putting them inside a named variable, after which they can be referenced, both outside of an embedding regex and from within an embedding regex by means of [interpolation](/language/regexes#Regex_interpolation):
```raku
my $regex = / R \w+ /;
say "Zen Buddhists like Raku too" ~~ $regex; # OUTPUT: «「Raku」»
my $regex = /pottery/;
"Japanese pottery rocks!" ~~ / <$regex> /; # Interpolation of $regex into /.../
say $/; # OUTPUT: «「pottery」»
```
## [Named regex definition syntax](#Regexes "go to top of document")[§](#Named_regex_definition_syntax "direct link")
A named regex may be constructed using the `regex` declarator as follows:
```raku
regex R { pattern }; # a named Regex object, named 'R'
```
Unlike with the `rx` form, you cannot chose your preferred delimiter: curly braces are mandatory. In this regard it should be noted that the definition of a named regex using the `regex` form is syntactically similar to the definition of a subroutine:
```raku
my sub S { /pattern/ }; # definition of Sub object (returning a Regex)
my regex R { pattern }; # definition of Regex object
```
which emphasizes the fact that a [`Regex`](/type/Regex) object represents code rather than data:
```raku
&S ~~ Code; # OUTPUT: «True»
&R ~~ Code; # OUTPUT: «True»
&R ~~ Method; # OUTPUT: «True» (A Regex is really a Method!)
```
Also unlike with the `rx` form for defining an anonymous regex, the definition of a named regex using the `regex` keyword does not allow for adverbs to be inserted before the opening delimiter. Instead, adverbs that are to modify the entire regex pattern may be included first thing within the curly braces:
```raku
regex R { :i pattern }; # :i (:ignorecase), renders pattern case insensitive
```
Alternatively, by way of shorthand, it is also possible (and recommended) to use the `rule` and `token` variants of the `regex` declarator for defining a [`Regex`](/type/Regex) when the `:ratchet` and `:sigspace` adverbs are of interest:
```raku
regex R { :r pattern }; # apply :r (:ratchet) to entire pattern
```
and, alternatively
```raku
token R { pattern }; # same thing: 'token' implies ':r'
```
Or
```raku
regex R { :r :s pattern }; # apply :r (:ratchet) and :s (:sigspace) to pattern
```
with this alternative:
```raku
rule R { pattern }; # same thing: 'rule' implies ':r:s'
```
Named regexes may be used as building blocks for other regexes, as they are methods that may called from within other regexes using the `<regex-name>` syntax. When they are used this way, they are often referred to as *subrules*; see for more details on their use [here](/language/regexes#Subrules). [`Grammar`](/type/Grammar)s are the natural habitat of subrules, but many common predefined character classes are also implemented as named regexes.
## [Regex readability: whitespace and comments](#Regexes "go to top of document")[§](#Regex_readability:_whitespace_and_comments "direct link")
Whitespace in regexes is ignored unless the [`:sigspace`](/language/regexes#Sigspace) adverb is used to make whitespace syntactically significant.
In addition to whitespace, comments may be used inside of regexes to improve their comprehensibility just as in code in general. This is true for both [single line comments](/language/syntax#Single-line_comments) and [multi line/embedded comments](/language/syntax#Multi-line_/_embedded_comments):
```raku
my $regex = rx/ \d ** 4 #`(match the year YYYY)
'-'
\d ** 2 # ...the month MM
'-'
\d ** 2 /; # ...and the day DD
say '2015-12-25'.match($regex); # OUTPUT: «「2015-12-25」»
```
## [Match syntax](#Regexes "go to top of document")[§](#Match_syntax "direct link")
There are a variety of ways to match a string against a regex. Irrespective of the syntax chosen, a successful match results in a [`Match`](/type/Match) object. In case the match is unsuccessful, the result is [`Nil`](/type/Nil). In either case, the result of the match operation is available via the special match variable [`$/`](/syntax/$$SOLIDUS).
The most common ways to match a string against an anonymous regex `/pattern/` or against a named regex `R` include the following:
* *Smartmatch: "string" ~~ /pattern/, or "string" ~~ /<R>/*
[Smartmatching](/language/operators#index-entry-smartmatch_operator) a string against a [`Regex`](/type/Regex) performs a regex match of the string against the [`Regex`](/type/Regex):
Raku highlighting
```
say "Go ahead, make my day." ~~ / \w+ /; # OUTPUT: «「Go」»
my regex R { me|you };
say "You talkin' to me?" ~~ / <R> /; # OUTPUT: «「me」 R => 「me」»
say "May the force be with you." ~~ &R ; # OUTPUT: «「you」»
```
The different outputs of the last two statements show that these two ways of smartmatching against a named regex are not identical. The difference arises because the method call `<R>` from within the anonymous regex `/ /` installs a so-called ['named capture'](/language/regexes#Named_captures) in the [`Match`](/type/Match) object, while the smartmatch against the named [`Regex`](/type/Regex) as such does not.
* *Explicit topic match: m/pattern/, or m/<R>/*
The match operator `m/ /` immediately matches the topic variable [`$_`](/language/variables#index-entry-topic_variable) against the regex following the `m`.
As with the `rx/ /` syntax for regex definitions, the match operator may be used with adverbs in between `m` and the opening regex delimiter, and with delimiters other than the slash. However, while the `rx/ /` syntax may only be used with [*regex adverbs*](/language/regexes#Regex_adverbs) that affect the compilation of the regex, the `m/ /` syntax may additionally be used with [*matching adverbs*](/language/regexes#Matching_adverbs) that determine how the regex engine is to perform pattern matching.
Here's an example that illustrates the primary difference between the `m/ /` and `/ /` syntax:
Raku highlighting
```
my $match;
$_ = "abc";
$match = m/.+/; say $match; say $match.^name; # OUTPUT: «「abc」Match»
$match = /.+/; say $match; say $match.^name; # OUTPUT: «/.+/Regex»
```
* *Implicit topic match in sink and Boolean contexts*
In case a [`Regex`](/type/Regex) object is used in sink context, or in a context in which it is coerced to [`Bool`](/type/Bool), the topic variable [`$_`](/language/variables#index-entry-topic_variable) is automatically matched against it:
Raku highlighting
```
$_ = "dummy string"; # Set the topic explicitly
rx/ s.* /; # Regex object in sink context matches automatically
say $/; # OUTPUT: «「string」»
say $/ if rx/ d.* /; # Regex object in Boolean context matches automatically
# OUTPUT: «「dummy string」»
```
* *Match method: "string".match: /pattern/, or "string".match: /<R>/*
The [`match`](/type/Str#method_match) method is analogous to the `m/ /` operator discussed above. Invoking it on a string, with a [`Regex`](/type/Regex) as an argument, matches the string against the [`Regex`](/type/Regex).
* *Parsing grammars: grammar-name.parse($string)*
Although parsing a [grammar](/language/grammars) involves more than just matching a string against a regex, this powerful regex-based text destructuring tool can't be left out from this overview of common pattern matching methods.
If you feel that your needs exceed what simple regexes have to offer, check out this [grammar tutorial](/language/grammar_tutorial) to take regexes to the next level.
# [Literals and metacharacters](#Regexes "go to top of document")[§](#Literals_and_metacharacters "direct link")
A regex describes a pattern to be matched in terms of literals and metacharacters. Alphanumeric characters and the underscore `_` constitute the literals: these characters match themselves and nothing else. Other characters act as metacharacters and may, as such, have a special meaning, either by themselves (such as the dot `.`, which serves as a wildcard) or together with other characters in larger metasyntactic constructs (such as `<?before ...>`, which defines a lookahead assertion).
In its simplest form a regex comprises only literals:
```raku
/Cześć/; # "Hello" in Polish
/こんばんは/; # "Good afternoon" in Japanese
/Καλησπέρα/; # "Good evening" in Greek
```
If you want a regex to literally match one or more characters that normally act as metacharacters, those characters must either be escaped using a backslash, or be quoted using single or double quotes.
The backslash serves as a switch. It switches a single metacharacter into a literal, and vice versa:
```raku
/ \# /; # matches the hash metacharacter literally
/ \w /; # turns literal 'w' into a character class (see below)
/Hallelujah\!/; # matches string 'Hallelujah!' incl. exclamation mark
```
Even if a metacharacter does not (yet) have a special meaning in Raku, escaping (or quoting) it is required to ensure that the regex compiles and matches the character literally. This allows the clear distinction between literals and metacharacters to be maintained. So, for instance, to match a comma this will work:
```raku
/ \, /; # matches a literal comma ','
```
while this will fail:
```raku
/ , /; # !! error: an as-yet meaningless/unrecognized metacharacter
# does not automatically match literally
```
While an escaping backslash exerts its effect on the next individual character, both a single metacharacter and a sequence of metacharacters may be turned into literally matching strings by quoting them in single or double quotes:
```raku
/ "abc" /; # quoting literals does not make them more literal
/ "Hallelujah!" /; # yet, this form is generally preferred over /Hallelujah\!/
/ "two words" /; # quoting a space renders it significant, so this matches
# the string 'two words' including the intermediate space
/ '#!:@' /; # this regex matches the string of metacharacters '#!:@'
```
Quoting does not necessarily turn every metacharacter into a literal, however. This is because quotes follow Raku's normal [rules for interpolation](/language/quoting#The_Q_lang). In particular, `「…」` quotes do not allow any interpolation; single quotes (either `'…'` or `‘…’`) allow the backslash to escape single quotes and the backslash itself; and double quotes (either `"…"` or `“…”`) enable the interpolation of variables and code blocks of the form `{…}`. Hence all of this works:
```raku
/ '\\\'' /; # matches a backslash followed by a single quote: \'
/ 「\'」 /; # also matches a backslash followed by a single quote
my $x = 'Hi';
/ "$x there!" /; # matches the string 'Hi there!'
/ "1 + 1 = {1+1}" /; # matches the string '1 + 1 = 2'
```
while these examples illustrate mistakes that you will want to avoid:
```raku
/ '\' /; # !! error: this is NOT the way to literally match a
# backslash because now it escapes the second quote
/"Price tag $0.50"/; # !! error: "$0" is interpreted as the first positional
# capture (which is Nil), not as '$0'
```
Strings are searched left to right, so it is enough if only part of the string matches the regex:
```raku
if 'Life, the Universe and Everything' ~~ / and / {
say ~$/; # OUTPUT: «and»
say $/.prematch; # OUTPUT: «Life, the Universe »
say $/.postmatch; # OUTPUT: « Everything»
say $/.from; # OUTPUT: «19»
say $/.to; # OUTPUT: «22»
};
```
Match results are always stored in the `$/` variable and are also returned from the match. They are both of type [`Match`](/type/Match) if the match was successful; otherwise both are of type [`Nil`](/type/Nil).
# [Wildcards](#Regexes "go to top of document")[§](#Wildcards "direct link")
An unescaped dot `.` in a regex matches any single character.
So, these all match:
```raku
'raku' ~~ /rak./; # matches the whole string
'raku' ~~ / rak . /; # the same; whitespace is ignored
'raku' ~~ / ra.u /; # the . matches the k
'raker' ~~ / rak. /; # the . matches the e
```
while this doesn't match:
```raku
'raku' ~~ / . rak /;
```
because there's no character to match before `rak` in the target string.
Notably `.` also matches a logical newline `\n`:
```raku
my $text = qq:to/END/
Although I am a
multi-line text,
I can be matched
with /.*/.
END
;
say $text ~~ / .* /;
# OUTPUT: «「Although I am amulti-line text,I can be matchedwith /.*/.」»
```
# [Character classes](#Regexes "go to top of document")[§](#Character_classes "direct link")
## [Backslashed character classes](#Regexes "go to top of document")[§](#Backslashed_character_classes "direct link")
There are predefined character classes of the form `\w`. Its negation is written with an uppercase letter, `\W`.
### [`\n` and `\N`](#Regexes "go to top of document")[§](#\n_and_\N "direct link")
`\n` matches a logical newline. `\N` matches a single character that's not a logical newline.
The definition of what constitutes a logical newline follows the [Unicode definition of a line boundary](https://unicode.org/reports/tr18/#Line_Boundaries) and includes in particular all of: a line feed (LF) `\U+000A`, a vertical tab (VT) `\U+000B`, a form feed (FF) `\U+000C`, a carriage return (CR) `\U+000D`, and the Microsoft Windows style newline sequence CRLF.
The interpretation of `\n` in regexes is independent of the value of the variable `$?NL` controlled by the [newline pragma](/language/pragmas#newline).
### [`\t` and `\T`](#Regexes "go to top of document")[§](#\t_and_\T "direct link")
`\t` matches a single tab/tabulation character, `U+0009`. `\T` matches a single character that is not a tab.
Note that exotic tabs like the `U+000B VERTICAL TABULATION` character are not included here.
### [`\h` and `\H`](#Regexes "go to top of document")[§](#\h_and_\H "direct link")
`\h` matches a single horizontal whitespace character. `\H` matches a single character that is not a horizontal whitespace character.
Examples of horizontal whitespace characters are
「text」 without highlighting
```
```
U+0020 SPACE
U+00A0 NO-BREAK SPACE
U+0009 CHARACTER TABULATION
U+2001 EM QUAD
```
```
Vertical whitespace such as newline characters are explicitly excluded; those can be matched with `\v`; `\s` matches any kind of whitespace.
### [`\v` and `\V`](#Regexes "go to top of document")[§](#\v_and_\V "direct link")
`\v` matches a single vertical whitespace character. `\V` matches a single character that is not vertical whitespace.
Examples of vertical whitespace characters:
「text」 without highlighting
```
```
U+000A LINE FEED
U+000B VERTICAL TABULATION
U+000C FORM FEED
U+000D CARRIAGE RETURN
U+0085 NEXT LINE
U+2028 LINE SEPARATOR
U+2029 PARAGRAPH SEPARATOR
```
```
Use `\s` to match any kind of whitespace, not just vertical whitespace.
### [`\s` and `\S`](#Regexes "go to top of document")[§](#\s_and_\S "direct link")
`\s` matches a single whitespace character. `\S` matches a single character that is not whitespace.
```raku
say $/.prematch if 'Match the first word.' ~~ / \s+ /;
# OUTPUT: «Match»
```
### [`\d` and `\D`](#Regexes "go to top of document")[§](#\d_and_\D "direct link")
`\d` matches a single decimal digit (Unicode General Category *Number, Decimal Digit*, `Nd`); conversely, `\D` matches a single character that is *not* a decimal digit.
```raku
'ab42' ~~ /\d/ and say ~$/; # OUTPUT: «4»
'ab42' ~~ /\D/ and say ~$/; # OUTPUT: «a»
```
Note that not only the Arabic digits (commonly used in the Latin alphabet) match `\d`, but also decimal digits from other scripts.
Examples of decimal digits include:
「text」 without highlighting
```
```
U+0035 5 DIGIT FIVE
U+0BEB ௫ TAMIL DIGIT FIVE
U+0E53 ๓ THAI DIGIT THREE
U+17E5 ៥ KHMER DIGIT FIVE
```
```
Also note that "decimal digit" is a narrower category than "Number" because (Unicode) numbers include not only decimal numbers (`Nd`) but also letter numbers (`Nl`) and other numbers (`No`) Examples of Unicode numbers that are not decimal digits include:
「text」 without highlighting
```
```
U+2464 ⑤ CIRCLED DIGIT FIVE
U+2476 ⑶ PARENTHESIZED DIGIT THREE
U+2083 ₃ SUBSCRIPT THREE
```
```
To match against all numbers, you can use the [Unicode property](#Unicode_properties) `N`:
```raku
say '⑤' ~~ /<:N>/ # OUTPUT: «「⑤」»
```
### [`\w` and `\W`](#Regexes "go to top of document")[§](#\w_and_\W "direct link")
`\w` matches a single word character, i.e. a letter (Unicode category L), a digit or an underscore. `\W` matches a single character that is not a word character.
Examples of word characters:
「text」 without highlighting
```
```
0041 A LATIN CAPITAL LETTER A
0031 1 DIGIT ONE
03B4 δ GREEK SMALL LETTER DELTA
03F3 ϳ GREEK LETTER YOT
0409 Љ CYRILLIC CAPITAL LETTER LJE
```
```
### [`\c` and `\C`](#Regexes "go to top of document")[§](#\c_and_\C "direct link")
`\c` takes a parameter delimited by square-brackets which is the name of a Unicode character as it appears in the [Unicode Character Database (UCD)](https://unicode.org/ucd/) and matches that specific character. For example:
```raku
'a.b' ~~ /\c[FULL STOP]/ and say ~$/; # OUTPUT: «.»
```
`\C` matches a single character that is not the named Unicode character.
Note that the word "character" is used, here, in the sense that the UCD does, but because Raku uses [NFG](/language/glossary#NFG), combining code points and the base characters to which they are attached, will generally not match individually. For example if you compose `"ü"` as `"u\x[0308]"`, that works just fine, but matching may surprise you:
```raku
say "u\x[0308]" ~~ /\c[LATIN SMALL LETTER U]/; # OUTPUT: «Nil»
```
To match the unmodified character, you can use the [`:ignoremark`](#Ignoremark) adverb.
### [`\x` and `\X`](#Regexes "go to top of document")[§](#\x_and_\X "direct link")
`\x` takes a parameter delimited by square-brackets which is the hexadecimal representation of the Unicode codepoint representing the character to be matched. For example:
```raku
'a.b' ~~ /\x[2E]/ and say ~$/; # OUTPUT: «.»
```
`\X` matches a single character that is not the given Unicode codepoint.
In addition, `\x` and `\X` can be used without square brackets, in which case, any characters that follow the `x` or `X` that are valid hexadecimal digits will be consumed. This means that all of these are equivalent:
```raku
/\x2e/ and /\x002e/ and /\x00002e/
```
But this format can be ambiguous, so the use of surrounding whitespace is highly recommended in non-trivial expressions.
For additional provisos with respect to combining codepoints, see [`\c` and `\C`](#\c_and_\C).
## [Predefined character classes](#Regexes "go to top of document")[§](#Predefined_character_classes "direct link")
| Class | Shorthand | Description |
| --- | --- | --- |
| <alpha> | | Alphabetic characters plus underscore (\_) |
| <digit> | \d | Decimal digits |
| <xdigit> | | Hexadecimal digit [0-9A-Fa-f] |
| <alnum> | \w | <alpha> plus <digit> |
| <punct> | | Punctuation and Symbols (only Punct beyond ASCII) |
| <graph> | | <alnum> plus <punct> |
| <space> | \s | Whitespace |
| <cntrl> | | Control characters |
| <print> | | <graph> plus <space>, but no <cntrl> |
| <blank> | \h | Horizontal whitespace |
| <lower> | <:Ll> | Lowercase characters |
| <upper> | <:Lu> | Uppercase characters |
The predefined character classes in the leftmost column are all of the form `<name>`, a hint to the fact that they are implemented as built-in [named regexes](/language/regexes#Subrules). As such they are subject to the usual capturing semantics. This means that if a character class is called with the syntax `<name>` (i.e. as indicated in the leftmost column), it will not only match, but also capture, installing a correspondingly named ['named capture'](/language/regexes#Named_captures) in the resulting [`Match`](/type/Match). In case just a match and no capture is desired, the capture may be suppressed through the use of call syntax that includes a leading dot: `<.name>`.
## [Predefined Regexes](#Regexes "go to top of document")[§](#Predefined_Regexes "direct link")
Besides the built-in character classes, Raku provides built-in [anchors](/language/regexes#Anchors) and [zero-width assertions](/language/regexes#Zero-width_assertions) defined as named regexes. These include `wb` (word boundary), `ww` (within word), and `same` (the next and previous character are the same). See the [anchors](/language/regexes#Anchors) and [zero-width assertions](/language/regexes#Zero-width_assertions) sections for details.
Raku also provides the two predefined tokens (i.e., regexes that don't [backtrack](/language/regexes#Backtracking)) shown below:
| Token | Regex equivalent | Description |
| --- | --- | --- |
| <ws> | <!ww> \s\*: | Word-separating whitespace (including zero, e.g. at EOF) |
| <ident> | <.alpha> \w\*: | Basic identifier (no support for ' or -). |
## [Unicode properties](#Regexes "go to top of document")[§](#Unicode_properties "direct link")
The character classes mentioned so far are mostly for convenience; another approach is to use Unicode character properties. These come in the form `<:property>`, where `property` can be a short or long Unicode General Category name. These use pair syntax.
To match against a Unicode property you can use either smartmatch or [`uniprop`](/routine/uniprop):
```raku
"a".uniprop('Script'); # OUTPUT: «Latin»
"a" ~~ / <:Script<Latin>> /; # OUTPUT: «「a」»
"a".uniprop('Block'); # OUTPUT: «Basic Latin»
"a" ~~ / <:Block('Basic Latin')> /; # OUTPUT: «「a」»
```
These are the Unicode general categories used for matching:
| Short | Long |
| --- | --- |
| L | Letter |
| LC | Cased\_Letter |
| Lu | Uppercase\_Letter |
| Ll | Lowercase\_Letter |
| Lt | Titlecase\_Letter |
| Lm | Modifier\_Letter |
| Lo | Other\_Letter |
| M | Mark |
| Mn | Nonspacing\_Mark |
| Mc | Spacing\_Mark |
| Me | Enclosing\_Mark |
| N | Number |
| Nd | Decimal\_Number or digit |
| Nl | Letter\_Number |
| No | Other\_Number |
| P | Punctuation or punct |
| Pc | Connector\_Punctuation |
| Pd | Dash\_Punctuation |
| Ps | Open\_Punctuation |
| Pe | Close\_Punctuation |
| Pi | Initial\_Punctuation |
| Pf | Final\_Punctuation |
| Po | Other\_Punctuation |
| S | Symbol |
| Sm | Math\_Symbol |
| Sc | Currency\_Symbol |
| Sk | Modifier\_Symbol |
| So | Other\_Symbol |
| Z | Separator |
| Zs | Space\_Separator |
| Zl | Line\_Separator |
| Zp | Paragraph\_Separator |
| C | Other |
| Cc | Control or cntrl |
| Cf | Format |
| Cs | Surrogate |
| Co | Private\_Use |
| Cn | Unassigned |
For example, `<:Lu>` matches a single, uppercase letter.
Its negation is this: `<:!property>`. So, `<:!Lu>` matches a single character that is not an uppercase letter.
Categories can be used together, with an infix operator:
| Operator | Meaning |
| --- | --- |
| + | set union |
| \- | set difference |
To match either a lowercase letter or a number, write `<:Ll+:N>` or `<:Ll+:Number>` or `<+ :Lowercase_Letter + :Number>`.
It's also possible to group categories and sets of categories with parentheses; for example:
```raku
say $0 if 'raku9' ~~ /\w+(<:Ll+:N>)/ # OUTPUT: «「9」»
```
## [Enumerated character classes and ranges](#Regexes "go to top of document")[§](#Enumerated_character_classes_and_ranges "direct link")
Sometimes the pre-existing wildcards and character classes are not enough. Fortunately, defining your own is fairly simple. Within `<[ ]>`, you can put any number of single characters and ranges of characters (expressed with two dots between the end points), with or without whitespace.
```raku
"abacabadabacaba" ~~ / <[ a .. c 1 2 3 ]>* /;
# Unicode hex codepoint range
"ÀÁÂÃÄÅÆ" ~~ / <[ \x[00C0] .. \x[00C6] ]>* /;
# Unicode named codepoint range
"αβγ" ~~ /<[\c[GREEK SMALL LETTER ALPHA]..\c[GREEK SMALL LETTER GAMMA]]>*/;
# Non-alphanumeric
'$@%!' ~~ /<[ ! @ $ % ]>+/ # OUTPUT: «「$@%!」»
```
As the last line above illustrates, within `<[ ]>` you do *not* need to quote or escape most non-alphanumeric characters the way you do in regex text outside of `<[ ]>`. You do, however, need to escape the much smaller set of characters that have special meaning within `<[ ]>`, such as `\`, `[`, and `]`.
To escape characters that would have some meaning inside the `<[ ]>`, precede the character with a `\`.
```raku
say "[ hey ]" ~~ /<-[ \] \[ \s ]>+/; # OUTPUT: «「hey」»
```
You do not have the option of quoting special characters inside a `<[ ]>` – a `'` just matches a literal `'`.
Within the `< >` you can use `+` and `-` to add or remove multiple range definitions and even mix in some of the Unicode categories above. You can also write the backslashed forms for character classes between the `[ ]`.
```raku
/ <[\d] - [13579]> /;
# starts with \d and removes odd ASCII digits, but not quite the same as
/ <[02468]> /;
# because the first one also contains "weird" unicodey digits
```
You can include Unicode properties in the list as well:
```raku
/<:Zs + [\x9] - [\xA0] - [\x202F] >/
# Any character with "Zs" property, or a tab, but not a "no-break space" or "narrow no-break space"
```
To negate a character class, put a `-` after the opening angle bracket:
```raku
say 'no quotes' ~~ / <-[ " ]> + /; # <-["]> matches any character except "
```
A common pattern for parsing quote-delimited strings involves negated character classes:
```raku
say '"in quotes"' ~~ / '"' <-[ " ]> * '"'/;
```
This regex first matches a quote, then any characters that aren't quotes, and then a quote again. The meaning of `*` and `+` in the examples above are explained in the next section on quantifiers.
Just as you can use the `-` for both set difference and negation of a single value, you can also explicitly put a `+` in front:
```raku
/ <+[123]> / # same as <[123]>
```
# [Quantifiers](#Regexes "go to |
## regexes.md
## Chunk 2 of 5
top of document")[§](#Quantifiers "direct link")
A quantifier makes the preceding atom match a variable number of times. For example, `a+` matches one or more `a` characters.
Quantifiers bind tighter than concatenation, so `ab+` matches one `a` followed by one or more `b`s. This is different for quotes, so `'ab'+` matches the strings `ab`, `abab`, `ababab` etc.
## [One or more: `+`](#Regexes "go to top of document")[§](#One_or_more:_+ "direct link")
The `+` quantifier makes the preceding atom match one or more times, with no upper limit.
For example, to match strings of the form `key=value`, you can write a regex like this:
```raku
/ \w+ '=' \w+ /
```
## [Zero or more: `*`](#Regexes "go to top of document")[§](#Zero_or_more:_* "direct link")
The `*` quantifier makes the preceding atom match zero or more times, with no upper limit.
For example, to allow optional whitespace between `a` and `b` you can write:
```raku
/ a \s* b /
```
## [Zero or one: `?`](#Regexes "go to top of document")[§](#Zero_or_one:_? "direct link")
The `?` quantifier makes the preceding atom match zero or once.
For example, to match `dog` or `dogs`, you can write:
```raku
/ dogs? /
```
## [General quantifier: `** min..max`](#Regexes "go to top of document")[§](#General_quantifier:_**_min..max "direct link")
To quantify an atom an arbitrary number of times, use the `**` quantifier, which takes a single [`Int`](/type/Int) or a [`Range`](/type/Range) on the right-hand side that specifies the number of times to match. If a [`Range`](/type/Range) is specified, the end-points specify the minimum and maximum number of times to match.
```raku
say 'abcdefg' ~~ /\w ** 4/; # OUTPUT: «「abcd」»
say 'a' ~~ /\w ** 2..5/; # OUTPUT: «Nil»
say 'abc' ~~ /\w ** 2..5/; # OUTPUT: «「abc」»
say 'abcdefg' ~~ /\w ** 2..5/; # OUTPUT: «「abcde」»
say 'abcdefg' ~~ /\w ** 2^..^5/; # OUTPUT: «「abcd」»
say 'abcdefg' ~~ /\w ** ^3/; # OUTPUT: «「ab」»
say 'abcdefg' ~~ /\w ** 1..*/; # OUTPUT: «「abcdefg」»
```
Only basic literal syntax for the right-hand side of the quantifier is supported, to avoid ambiguities with other regex constructs. If you need to use a more complex expression, for example, a [`Range`](/type/Range) made from variables, enclose the [`Range`](/type/Range) in curly braces:
```raku
my $start = 3;
say 'abcdefg' ~~ /\w ** {$start .. $start+2}/; # OUTPUT: «「abcde」»
say 'abcdefg' ~~ /\w ** {π.Int}/; # OUTPUT: «「abc」»
```
Negative values are treated like zero:
```raku
say 'abcdefg' ~~ /\w ** {-Inf}/; # OUTPUT: «「」»
say 'abcdefg' ~~ /\w ** {-42}/; # OUTPUT: «「」»
say 'abcdefg' ~~ /\w ** {-10..-42}/; # OUTPUT: «「」»
say 'abcdefg' ~~ /\w ** {-42..-10}/; # OUTPUT: «「」»
```
If then, the resultant value is `Inf` or `NaN` or the resultant [`Range`](/type/Range) is empty, non-Numeric, contains `NaN` end-points, or has minimum effective end-point as `Inf`, the `X::Syntax::Regex::QuantifierValue` exception will be thrown:
```raku
(try say 'abcdefg' ~~ /\w ** {42..10}/ )
orelse say ($!.^name, $!.empty-range);
# OUTPUT: «(X::Syntax::Regex::QuantifierValue True)»
(try say 'abcdefg' ~~ /\w ** {Inf..Inf}/)
orelse say ($!.^name, $!.inf);
# OUTPUT: «(X::Syntax::Regex::QuantifierValue True)»
(try say 'abcdefg' ~~ /\w ** {NaN..42}/ )
orelse say ($!.^name, $!.non-numeric-range);
# OUTPUT: «(X::Syntax::Regex::QuantifierValue True)»
(try say 'abcdefg' ~~ /\w ** {"a".."c"}/)
orelse say ($!.^name, $!.non-numeric-range);
# OUTPUT: «(X::Syntax::Regex::QuantifierValue True)»
(try say 'abcdefg' ~~ /\w ** {Inf}/)
orelse say ($!.^name, $!.inf);
# OUTPUT: «(X::Syntax::Regex::QuantifierValue True)»
(try say 'abcdefg' ~~ /\w ** {NaN}/)
orelse say ($!.^name, $!.non-numeric);
# OUTPUT: «(X::Syntax::Regex::QuantifierValue True)»
```
## [Modified quantifier: `%`, `%%`](#Regexes "go to top of document")[§](#Modified_quantifier:_%,_%% "direct link")
To more easily match things like comma separated values, you can tack on a `%` modifier to any of the above quantifiers to specify a separator that must occur between each of the matches. For example, `a+ % ','` will match `a` or `a,a` or `a,a,a`, etc.
`%%` is like `%`, with the difference that it can optionally match trailing delimiters as well. This means that besides `a` and `a,a`, it can also match `a,` and `a,a,`.
The quantifier interacts with `%` and controls the number of overall repetitions that can match successfully, so `a* % ','` also matches the empty string. If you want match words delimited by commas, you might need to nest an ordinary and a modified quantifier:
```raku
say so 'abc,def' ~~ / ^ [\w+] ** 1 % ',' $ /; # OUTPUT: «False»
say so 'abc,def' ~~ / ^ [\w+] ** 2 % ',' $ /; # OUTPUT: «True»
```
## [Preventing backtracking: `:`](#Regexes "go to top of document")[§](#Preventing_backtracking:_: "direct link")
One way to prevent [backtracking](/language/regexes#Backtracking) is through the use of the `ratchet` adverb as described [below](/language/regexes#Ratchet). Another more fine-grained way of preventing backtracking in regexes is attaching a `:` modifier to a quantifier:
```raku
my $str = "ACG GCT ACT An interesting chain";
say $str ~~ /<[ACGT\s]>+ \s+ (<[A..Z a..z \s]>+)/;
# OUTPUT: «「ACG GCT ACT An interesting chain」 0 => 「An interesting chain」»
say $str ~~ /<[ACGT\s]>+: \s+ (<[A..Z a..z \s]>+)/;
# OUTPUT: «Nil»
```
In the second case, the "A" in "An" had already been absorbed by the pattern, preventing the matching of the second part of the pattern, after `\s+`. Generally we will want the opposite: prevent backtracking to match precisely what we are looking for.
In most cases, you will want to prevent backtracking for efficiency reasons, for instance here:
```raku
say $str ~~ m:g/[(<[ACGT]> **: 3) \s*]+ \s+ (<[A..Z a..z \s]>+)/;
# OUTPUT:
# «(「ACG GCT ACT An interesting chain」
# «0 => 「ACG」»
# «0 => 「GCT」»
# «0 => 「ACT」»
# «1 => 「An interesting chain」)»
```
Although in this case, eliminating the `:` from behind `**` would make it behave exactly in the same way. The best use is to create *tokens* that will not be backtracked:
```raku
$_ = "ACG GCT ACT IDAQT";
say m:g/[(\w+:) \s*]+ (\w+) $$/;
# OUTPUT:
# «(「ACG GCT ACT IDAQT」»
# «0 => 「ACG」»
# «0 => 「GCT」»
# «0 => 「ACT」»
# «1 => 「IDAQT」)»
```
Without the `:` following `\w+`, the *ID* part captured would have been simply `T`, since the pattern would go ahead and match everything, leaving a single letter to match the `\w+` expression at the end of the line.
## [Greedy versus frugal quantifiers: `?`](#Regexes "go to top of document")[§](#Greedy_versus_frugal_quantifiers:_? "direct link")
By default, quantifiers request a greedy match:
```raku
'abababa' ~~ /a .* a/ && say ~$/; # OUTPUT: «abababa»
```
You can attach a `?` modifier to the quantifier to enable frugal matching:
```raku
'abababa' ~~ /a .*? a/ && say ~$/; # OUTPUT: «aba»
```
You can also enable frugal matching for general quantifiers:
```raku
say '/foo/o/bar/' ~~ /\/.**?{1..10}\//; # OUTPUT: «「/foo/」»
say '/foo/o/bar/' ~~ /\/.**!{1..10}\//; # OUTPUT: «「/foo/o/bar/」»
```
Greedy matching can be explicitly requested with the `!` modifier.
# [Alternation: `||`](#Regexes "go to top of document")[§](#Alternation:_|| "direct link")
To match one of several possible alternatives, separate them by `||`; the first matching alternative wins.
For example, `ini` files have the following form:
「text」 without highlighting
```
```
[section]
key = value
```
```
Hence, if you parse a single line of an `ini` file, it can be either a section or a key-value pair and the regex would be (to a first approximation):
```raku
/ '[' \w+ ']' || \S+ \s* '=' \s* \S* /
```
That is, either a word surrounded by square brackets, or a string of non-whitespace characters, followed by zero or more spaces, followed by the equals sign `=`, followed again by optional whitespace, followed by another string of non-whitespace characters.
An empty string as the first branch is ignored, to allow you to format branches consistently. You could have written the previous example as
```raku
/
|| '[' \w+ ']'
|| \S+ \s* '=' \s* \S*
/
```
Even in non-backtracking contexts, the alternation operator `||` tries all the branches in order until the first one matches.
# [Longest alternation: `|`](#Regexes "go to top of document")[§](#Longest_alternation:_| "direct link")
In short, in regex branches separated by `|`, the longest token match wins, independent of the textual ordering in the regex. However, what `|` really does is more than that. It does not decide which branch wins after finishing the whole match, but follows the [longest-token matching (LTM) strategy](https://github.com/Raku/old-design-docs/blob/master/S05-regex.pod#Longest-token_matching).
Briefly, what `|` does is this:
* First, select the branch which has the longest declarative prefix.
```raku
say "abc" ~~ /ab | a.* /; # OUTPUT: «⌜abc⌟»
say "abc" ~~ /ab | a {} .* /; # OUTPUT: «⌜ab⌟»
say "if else" ~~ / if | if <.ws> else /; # OUTPUT: «「if」»
say "if else" ~~ / if | if \s+ else /; # OUTPUT: «「if else」»
```
As is shown above, `a.*` is a declarative prefix, while `a {} .*` terminates at `{}`, then its declarative prefix is `a`. Note that non-declarative atoms terminate declarative prefix. This is quite important if you want to apply `|` in a `rule`, which automatically enables `:s`, and `<.ws>` accidentally terminates declarative prefix.
* If it's a tie, select the match with the highest specificity.
```raku
say "abc" ~~ /a. | ab { print "win" } /; # OUTPUT: «win「ab」»
```
When two alternatives match at the same length, the tie is broken by specificity. That is, `ab`, as an exact match, counts as closer than `a.`, which uses character classes.
* If it's still a tie, use additional tie-breakers.
```raku
say "abc" ~~ /a\w| a. { print "lose" } /; # OUTPUT: «⌜ab⌟»
```
If the tie breaker above doesn't work, then the textually earlier alternative takes precedence.
For more details, see [the LTM strategy](https://github.com/Raku/old-design-docs/blob/master/S05-regex.pod#Longest-token_matching).
## [Quoted lists are LTM matches](#Regexes "go to top of document")[§](#Quoted_lists_are_LTM_matches "direct link")
Using a quoted list in a regex is equivalent to specifying the longest-match alternation of the list's elements. So, the following match:
```raku
say 'food' ~~ /< f fo foo food >/; # OUTPUT: «「food」»
```
is equivalent to:
```raku
say 'food' ~~ / f | fo | foo | food /; # OUTPUT: «「food」»
```
Note that the space after the first `<` is significant here: `<food>` calls the named rule `food` while `< food >` and `< food>` specify quoted lists with a single element, `'food'`.
If the first branch is an empty string, it is ignored. This allows you to format your regexes consistently:
```raku
/
| f
| fo
| foo
| food
/
```
Arrays can also be interpolated into a regex to achieve the same effect:
```raku
my @increasingly-edible = <f fo foo food>;
say 'food' ~~ /@increasingly-edible/; # OUTPUT: «「food」»
```
This is documented further under [Regex Interpolation](#Regex_interpolation), below.
# [Conjunction: `&&`](#Regexes "go to top of document")[§](#Conjunction:_&& "direct link")
Matches successfully if all `&&`-delimited segments match the same substring of the target string. The segments are evaluated left to right.
This can be useful for augmenting an existing regex. For example if you have a regex `quoted` that matches a quoted string, then `/ <quoted> && <-[x]>* /` matches a quoted string that does not contain the character `x`.
Note that you cannot easily obtain the same behavior with a lookahead, that is, a regex doesn't consume characters, because a lookahead doesn't stop looking when the quoted string stops matching.
```raku
say 'abc' ~~ / <?before a> && . /; # OUTPUT: «Nil»
say 'abc' ~~ / <?before a> . && . /; # OUTPUT: «「a」»
say 'abc' ~~ / <?before a> . /; # OUTPUT: «「a」»
say 'abc' ~~ / <?before a> .. /; # OUTPUT: «「ab」»
```
Just like with `||`, empty first branches are ignored.
# [Conjunction: `&`](#Regexes "go to top of document")[§](#Conjunction:_& "direct link")
Much like `&&` in a Regexes, it matches successfully if all segments separated by `&` match the same part of the target string.
`&` (unlike `&&`) is considered declarative, and notionally all the segments can be evaluated in parallel, or in any order the compiler chooses.
Just like with `||` and `&`, empty first branches are ignored.
# [Anchors](#Regexes "go to top of document")[§](#Anchors "direct link")
Regexes search an entire string for matches. Sometimes this is not what you want. Anchors match only at certain positions in the string, thereby anchoring the regex match to that position.
## [Start of string and end of string](#Regexes "go to top of document")[§](#Start_of_string_and_end_of_string "direct link")
The `^` anchor only matches at the start of the string:
```raku
say so 'karakul' ~~ / raku/; # OUTPUT: «True»
say so 'karakul' ~~ /^ raku/; # OUTPUT: «False»
say so 'rakuy' ~~ /^ raku/; # OUTPUT: «True»
say so 'raku' ~~ /^ raku/; # OUTPUT: «True»
```
The `$` anchor only matches at the end of the string:
```raku
say so 'use raku' ~~ / raku /; # OUTPUT: «True»
say so 'use raku' ~~ / raku $/; # OUTPUT: «True»
say so 'rakuy' ~~ / raku $/; # OUTPUT: «False»
```
You can combine both anchors:
```raku
say so 'use raku' ~~ /^ raku $/; # OUTPUT: «False»
say so 'raku' ~~ /^ raku $/; # OUTPUT: «True»
```
Keep in mind that `^` matches the start of a **string**, not the start of a **line**. Likewise, `$` matches the end of a **string**, not the end of a **line**.
The following is a multi-line string:
```raku
my $str = chomp q:to/EOS/;
Keep it secret
and keep it safe
EOS
# 'safe' is at the end of the string
say so $str ~~ /safe $/; # OUTPUT: «True»
# 'secret' is at the end of a line, not the string
say so $str ~~ /secret $/; # OUTPUT: «False»
# 'Keep' is at the start of the string
say so $str ~~ /^Keep /; # OUTPUT: «True»
# 'and' is at the start of a line -- not the string
say so $str ~~ /^and /; # OUTPUT: «False»
```
## [Start of line and end of line](#Regexes "go to top of document")[§](#Start_of_line_and_end_of_line "direct link")
The `^^` anchor matches at the start of a logical line. That is, either at the start of the string, or after a newline character. However, it does not match at the end of the string, even if it ends with a newline character.
The `$$` anchor matches at the end of a logical line. That is, before a newline character, or at the end of the string when the last character is not a newline character.
To understand the following example, it's important to know that the `q:to/EOS/...EOS` [heredoc](/language/quoting#Heredocs:_:to) syntax removes leading indention to the same level as the `EOS` marker, so that the first, second and last lines have no leading space and the third and fourth lines have two leading spaces each.
```raku
my $str = q:to/EOS/;
There was a young man of Japan
Whose limericks never would scan.
When asked why this was,
He replied "It's because I always try to fit
as many syllables into the last line as ever I possibly can."
EOS
# 'There' is at the start of string
say so $str ~~ /^^ There/; # OUTPUT: «True»
# 'limericks' is not at the start of a line
say so $str ~~ /^^ limericks/; # OUTPUT: «False»
# 'as' is at start of the last line
say so $str ~~ /^^ as/; # OUTPUT: «True»
# there are blanks between start of line and the "When"
say so $str ~~ /^^ When/; # OUTPUT: «False»
# 'Japan' is at end of first line
say so $str ~~ / Japan $$/; # OUTPUT: «True»
# there's a . between "scan" and the end of line
say so $str ~~ / scan $$/; # OUTPUT: «False»
# matched at the last line
say so $str ~~ / '."' $$/; # OUTPUT: «True»
```
## [Word boundary](#Regexes "go to top of document")[§](#Word_boundary "direct link")
To match any word boundary, use `<?wb>`. This is similar to `\b` in other languages. To match the opposite, any character that is not bounding a word, use `<!wb>`. This is similar to `\B` in other languages; `\b` and `\B` will throw an [`X::Obsolete`](/type/X/Obsolete) exception from version 6.d of Raku.
These are both zero-width regex elements.
```raku
say "two-words" ~~ / two<?wb>\-<?wb>words /; # OUTPUT: «「two-words」»
say "twowords" ~~ / two<!wb><!wb>words /; # OUTPUT: «「twowords」»
```
## [Left and right word boundary](#Regexes "go to top of document")[§](#Left_and_right_word_boundary "direct link")
`<<` matches a left word boundary. It matches positions where there is a non-word character at the left, or the start of the string, and a word character to the right.
`>>` matches a right word boundary. It matches positions where there is a word character at the left and a non-word character at the right, or the end of the string.
These are both zero-width regex elements.
```raku
my $str = 'The quick brown fox';
say so ' ' ~~ /\W/; # OUTPUT: «True»
say so $str ~~ /br/; # OUTPUT: «True»
say so $str ~~ /<< br/; # OUTPUT: «True»
say so $str ~~ /br >>/; # OUTPUT: «False»
say so $str ~~ /own/; # OUTPUT: «True»
say so $str ~~ /<< own/; # OUTPUT: «False»
say so $str ~~ /own >>/; # OUTPUT: «True»
say so $str ~~ /<< The/; # OUTPUT: «True»
say so $str ~~ /fox >>/; # OUTPUT: «True»
```
You can also use the variants `«` and `»` :
```raku
my $str = 'The quick brown fox';
say so $str ~~ /« own/; # OUTPUT: «False»
say so $str ~~ /own »/; # OUTPUT: «True»
```
To see the difference between `<?wb>` and `«`, `»`:
```raku
say "stuff here!!!".subst(:g, />>/, '|'); # OUTPUT: «stuff| here|!!!»
say "stuff here!!!".subst(:g, /<</, '|'); # OUTPUT: «|stuff |here!!!»
say "stuff here!!!".subst(:g, /<?wb>/, '|'); # OUTPUT: «|stuff| |here|!!!»
```
## [Summary of anchors](#Regexes "go to top of document")[§](#Summary_of_anchors "direct link")
Anchors are zero-width regex elements. Hence they do not use up a character of the input string, that is, they do not advance the current position at which the regex engine tries to match. A good mental model is that they match between two characters of an input string, or before the first, or after the last character of an input string.
| Anchor | Description | Examples |
| --- | --- | --- |
| ^ | Start of string | "⏏two\nlines" |
| ^^ | Start of line | "⏏two\n⏏lines" |
| $ | End of string | "two\nlines⏏" |
| $$ | End of line | "two⏏\nlines⏏" |
| << or « | Left word boundary | "⏏two ⏏words" |
| >> or » | Right word boundary | "two⏏ words⏏" |
| <?wb> | Any word boundary | "⏏two⏏ ⏏words⏏~!" |
| <!wb> | Not a word boundary | "t⏏w⏏o w⏏o⏏r⏏d⏏s~⏏!" |
| <?ww> | Within word | "t⏏w⏏o w⏏o⏏r⏏d⏏s~!" |
| <!ww> | Not within word | "⏏two⏏ ⏏words⏏~⏏!⏏" |
# [Zero-width assertions](#Regexes "go to top of document")[§](#Zero-width_assertions "direct link")
Zero-Width assertions can help you implement your own anchor: it turns another regex into an anchor, making them consume no characters of the input string. There are two variants: lookahead and lookbehind assertions.
Technically, anchors are also zero-width assertions, and they can look both ahead and behind.
## [Lookaround assertions](#Regexes "go to top of document")[§](#Lookaround_assertions "direct link")
Lookaround assertions, which need a character class in its simpler form, work both ways. They match, but they don't consume a character.
```raku
my regex key {^^ <![#-]> \d+ }
say "333" ~~ &key; # OUTPUT: «「333」»
say '333$' ~~ m/ \d+ <?[$]>/; # OUTPUT: «「333」»
say '$333' ~~ m/^^ <?[$]> . \d+ /; # OUTPUT: «「$333」»
```
They can be positive or negative: `![]` is negative, while `?[]` is positive; the square brackets will contain the characters or backslashed character classes that are going to be matched.
You can use predefined character classes and Unicode properties directly preceded by the exclamation or interrogation mark to convert them into lookaround assertions.:
```raku
say '333' ~~ m/^^ <?alnum> \d+ /; # OUTPUT: «「333」»
say '333' ~~ m/^^ <?:Nd> \d+ /; # OUTPUT: «「333」»
say '333' ~~ m/^^ <!:L> \d+ /; # OUTPUT: «「333」»
say '333' ~~ m/^^ \d+ <!:Script<Tamil>> /; # OUTPUT: «「33」»
```
In the first two cases, the corresponding character class matches, but does not consume, the first digit, which is then consumed by the expression; in the third, the negative lookaround assertion behaves in the same way. In the fourth statement the last digit is matched but not consumed, thus the match includes only the first two digits.
## [Lookahead assertions](#Regexes "go to top of document")[§](#Lookahead_assertions "direct link")
To check that a pattern appears before another pattern, use a lookahead assertion via the `before` assertion. This has the form:
```raku
<?before pattern>
```
Thus, to search for the string `foo` which is immediately followed by the string `bar`, use the following regexp:
```raku
/ foo <?before bar> /
```
For example:
```raku
say "foobar" ~~ / foo <?before bar> /; # OUTPUT: «foo»
```
However, if you want to search for a pattern which is **not** immediately followed by some pattern, then you need to use a negative lookahead assertion, this has the form:
```raku
<!before pattern>
```
In the following example, all occurrences of `foo` which is not before `bar` would match with
```raku
say "foobaz" ~~ / foo <!before bar> /; # OUTPUT: «foo»
```
Lookahead assertions can be used also with other patterns, like characters ranges, interpolated variables subscripts and so on. In such cases it does suffice to use a `?`, or a `!` for the negate form. For instance, the following lines all produce the very same result:
```raku
say 'abcdefg' ~~ rx{ abc <?before def> }; # OUTPUT: «「abc」»
say 'abcdefg' ~~ rx{ abc <?[ d..f ]> }; # OUTPUT: «「abc」»
my @ending_letters = <d e f>;
say 'abcdefg' ~~ rx{ abc <?@ending_letters> }; # OUTPUT: «「abc」»
```
Metacharacters can also be used in lookahead or -behind assertions.
```raku
say "First. Second" ~~ m:g/ <?after ^^ | "." \s+> <:Lu>\S+ /
# OUTPUT: «(「First.」 「Second」)»
```
A practical use of lookahead assertions is in substitutions, where you only want to substitute regex matches that are in a certain context. For example, you might want to substitute only numbers that are followed by a unit (like *kg*), but not other numbers:
```raku
my @units = <kg m km mm s h>;
$_ = "Please buy 2 packs of sugar, 1 kg each";
s:g[\d+ <?before \s* @units>] = 5 * $/;
say $_; # OUTPUT: «Please buy 2 packs of sugar, 5 kg each»
```
Since the lookahead is not part of the match object, the unit is not substituted.
## [Lookbehind assertions](#Regexes "go to top of document")[§](#Lookbehind_assertions "direct link")
To check that a pattern appears after another pattern, use a lookbehind assertion via the `after` assertion. This has the form:
```raku
<?after pattern>
```
Therefore, to search for the string `bar` immediately preceded by the string `foo`, use the following regexp:
```raku
/ <?after foo> bar /
```
For example:
```raku
say "foobar" ~~ / <?after foo> bar /; # OUTPUT: «bar»
```
However, if you want to search for a pattern which is **not** immediately preceded by some pattern, then you need to use a negative lookbehind assertion, this has the form:
```raku
<!after pattern>
```
Hence all occurrences of `bar` which do not have `foo` before them would be matched by
```raku
say "fotbar" ~~ / <!after foo> bar /; # OUTPUT: «bar»
```
These are, as in the case of lookahead, zero-width assertions which do not *consume* characters, like here:
```raku
say "atfoobar" ~~ / (.**3) .**2 <?after foo> bar /;
# OUTPUT: «「atfoobar」 0 => 「atf」»
```
where we capture the first 3 of the 5 characters before bar, but only if `bar` is preceded by `foo`. The fact that the assertion is zero-width allows us to use part of the characters in the assertion for capture.
# [Grouping and capturing](#Regexes "go to top of document")[§](#Grouping_and_capturing "direct link")
In regular (non-regex) Raku, you can use parentheses to group things together, usually to override operator precedence:
```raku
say 1 + 4 * 2; # OUTPUT: «9», parsed as 1 + (4 * 2)
say (1 + 4) * 2; # OUTPUT: «10»
```
The same grouping facility is available in regexes:
```raku
/ a || b c /; # matches 'a' or 'bc'
/ ( a || b ) c /; # matches 'ac' or 'bc'
```
The same grouping applies to quantifiers:
```raku
/ a b+ /; # matches an 'a' followed by one or more 'b's
/ (a b)+ /; # matches one or more sequences of 'ab'
/ (a || b)+ /; # matches a string of 'a's and 'b's, except empty string
```
An unquantified capture produces a [`Match`](/type/Match) object. When a capture is quantified (except with the `?` quantifier) the capture becomes a list of [`Match`](/type/Match) objects instead.
## [Capturing](#Regexes "go to top of document")[§](#Capturing "direct link")
The round parentheses don't just group, they also *capture*; that is, they make the string matched within the group available as a variable, and also as an element of the resulting [`Match`](/type/Match) object:
```raku
my $str = 'number 42';
if $str ~~ /'number ' (\d+) / {
say "The number is $0"; # OUTPUT: «The number is 42»
# or
say "The number is $/[0]"; # OUTPUT: «The number is 42»
}
```
Pairs of parentheses are numbered left to right, starting from zero.
```raku
if 'abc' ~~ /(a) b (c)/ {
say "0: $0; 1: $1"; # OUTPUT: «0: a; 1: c»
}
```
The `$0` and `$1` etc. syntax is shorthand. These captures are canonically available from the match object `$/` by using it as a list, so `$0` is actually syntactic sugar for `$/[0]`.
Coercing the match object to a list gives an easy way to programmatically access all elements:
```raku
if 'abc' ~~ /(a) b (c)/ {
say $/.list.join: ', ' # OUTPUT: «a, c»
}
```
## [Non-capturing grouping](#Regexes "go to top of document")[§](#Non-capturing_grouping "direct link")
The parentheses in regexes perform a double role: they group the regex elements inside and they capture what is matched by the sub-regex inside.
To get only the grouping behavior, you can use square brackets `[ ... ]` which, by default, don't capture.
```raku
if 'abc' ~~ / [a||b] (c) / {
|
## regexes.md
## Chunk 3 of 5
say ~$0; # OUTPUT: «c»
}
```
If you do not need the captures, using non-capturing `[ ... ]` groups provides the following benefits:
* they more cleanly communicate the regex intent,
* they make it easier to count the capturing groups that do match, and
* they make matching a bit faster.
## [Capture numbers](#Regexes "go to top of document")[§](#Capture_numbers "direct link")
It is stated above that captures are numbered from left to right. While true in principle, this is also an over simplification.
The following rules are listed for the sake of completeness. When you find yourself using them regularly, it's worth considering named captures (and possibly subrules) instead.
Alternations reset the capture count:
```raku
/ (x) (y) || (a) (.) (.) /
# $0 $1 $0 $1 $2
```
Example:
```raku
if 'abc' ~~ /(x)(y) || (a)(.)(.)/ {
say ~$1; # OUTPUT: «b»
}
```
If two (or more) alternations have a different number of captures, the one with the most captures determines the index of the next capture:
```raku
if 'abcd' ~~ / a [ b (.) || (x) (y) ] (.) / {
# $0 $0 $1 $2
say ~$2; # OUTPUT: «d»
}
```
Captures can be nested, in which case they are numbered per level; level 0 gets to use the capture variables, but it will become a list with the rest of the levels behaving as elements of that list
```raku
if 'abc' ~~ / ( a (.) (.) ) / {
say "Outer: $0"; # OUTPUT: «Outer: abc»
say "Inner: $0[0] and $0[1]"; # OUTPUT: «Inner: b and c»
}
```
These capture variables are only available outside the regex.
```raku
# !!WRONG!! The $0 refers to a capture *inside* the second capture
say "11" ~~ /(\d) ($0)/; # OUTPUT: «Nil»
```
In order to make them available inside the Regexes, you need to insert a code block behind the match; this code block may be empty if there's nothing meaningful to do:
```raku
# CORRECT: $0 is saved into a variable outside the second capture
# before it is used inside
say "11" ~~ /(\d) {} :my $c = $0; ($c)/; # OUTPUT: «「11」 0 => 「1」 1 => 「1」»
say "Matched $c"; # OUTPUT: «Matched 1»
```
This code block *publishes* the capture inside the regex, so that it can be assigned to other variables or used for subsequent matches
```raku
say "11" ~~ /(\d) {} $0/; # OUTPUT: «「11」 0 => 「1」»
```
`:my` helps scoping the `$c` variable within the regex and beyond; in this case we can use it in the next sentence to show what has been matched inside the regex. This can be used for debugging inside regular expressions, for instance:
```raku
my $paragraph="line\nline2\nline3";
$paragraph ~~ rx| :my $counter = 0; ( \V* { ++$counter } ) *%% \n |;
say "Matched $counter lines"; # OUTPUT: «Matched 3 lines»
```
Since `:my` blocks are simply declarations, the match variable `$/` or numbered matches such as `$0` will not be available in them unless they are previously *published* by inserting the empty block (or any block):
```raku
"aba" ~~ / (a) b {} :my $c = $/; /;
say $c; # OUTPUT: «「ab」 0 => 「a」»
```
Any other code block will also reveal the variables and make them available in declarations:
```raku
"aba" ~~ / (a) {say "Check so far ", ~$/} b :my $c = ~$0; /;
# OUTPUT: «Check so far a»
say "Capture $c"; # OUTPUT: «Capture a»
```
The `:our`, similarly to [`our`](/syntax/our) in classes, can be used in [`Grammar`](/type/Grammar)s to declare variables that can be accessed, via its fully qualified name, from outside the grammar:
```raku
grammar HasOur {
token TOP {
:our $our = 'Þor';
$our \s+ is \s+ mighty
}
}
say HasOur.parse('Þor is mighty'); # OUTPUT: «「Þor is mighty」»
say $HasOur::our; # OUTPUT: «Þor»
```
Once the parsing has been done successfully, we use the FQN name of the `$our` variable to access its value, that can be none other than `Þor`.
## [Named captures](#Regexes "go to top of document")[§](#Named_captures "direct link")
Instead of numbering captures, you can also give them names. The generic, and slightly verbose, way of naming captures is like this:
```raku
if 'abc' ~~ / $<myname> = [ \w+ ] / {
say ~$<myname> # OUTPUT: «abc»
}
```
The square brackets in the above example, which don't usually capture, will now capture its grouping with the given name.
The access to the named capture, `$<myname>`, is a shorthand for indexing the match object as a hash, in other words: `$/{ 'myname' }` or `$/<myname>`.
We can also use parentheses in the above example, but they will work exactly the same as square brackets. The captured group will only be accessible by its name as a key from the match object and not from its position in the list with `$/[0]` or `$0`.
Named captures can also be nested using regular capture group syntax:
```raku
if 'abc-abc-abc' ~~ / $<string>=( [ $<part>=[abc] ]* % '-' ) / {
say ~$<string>; # OUTPUT: «abc-abc-abc»
say ~$<string><part>; # OUTPUT: «abc abc abc»
say ~$<string><part>[0]; # OUTPUT: «abc»
}
```
Coercing the match object to a hash gives you easy programmatic access to all named captures:
```raku
if 'count=23' ~~ / $<variable>=\w+ '=' $<value>=\w+ / {
my %h = $/.hash;
say %h.keys.sort.join: ', '; # OUTPUT: «value, variable»
say %h.values.sort.join: ', '; # OUTPUT: «23, count»
for %h.kv -> $k, $v {
say "Found value '$v' with key '$k'";
# outputs two lines:
# Found value 'count' with key 'variable'
# Found value '23' with key 'value'
}
}
```
A more convenient way to get named captures is by using named regex as discussed in the [Subrules](/language/regexes#Subrules) section.
## [Capture markers: `<( )>`](#Regexes "go to top of document")[§](#Capture_markers:_<(_)> "direct link")
A `<(` token indicates the start of the match's overall capture, while the corresponding `)>` token indicates its endpoint. The `<(` is similar to other languages \K to discard any matches found before the `\K`.
```raku
say 'abc' ~~ / a <( b )> c/; # OUTPUT: «「b」»
say 'abc' ~~ / <(a <( b )> c)>/; # OUTPUT: «「bc」»
```
As in the example above, you can see `<(` sets the start point and `)>` sets the endpoint; since they are actually independent of each other, the inner-most start point wins (the one attached to `b`) and the outer-most end wins (the one attached to `c`).
# [Substitution](#Regexes "go to top of document")[§](#Substitution "direct link")
Regular expressions can also be used to substitute one piece of text for another. You can use this for anything, from correcting a spelling error (e.g., replacing 'Perl Jam' with 'Pearl Jam'), to reformatting an ISO8601 date from `yyyy-mm-ddThh:mm:ssZ` to `mm-dd-yy h:m {AM,PM}` and beyond.
Just like the search-and-replace editor's dialog box, the `s/ / /` operator has two sides, a left and right side. The left side is where your matching expression goes, and the right side is what you want to replace it with.
## [Lexical conventions](#Regexes "go to top of document")[§](#Lexical_conventions_0 "direct link")
Substitutions are written similarly to matching, but the substitution operator has both an area for the regex to match, and the text to substitute:
```raku
s/replace/with/; # a substitution that is applied to $_
$str ~~ s/replace/with/; # a substitution applied to a scalar
```
The substitution operator allows delimiters other than the slash:
```raku
s|replace|with|;
s!replace!with!;
s,replace,with,;
```
Note that neither the colon `:` nor balancing delimiters such as `{}` or `()` can be substitution delimiters. Colons clash with adverbs such as `s:i/Foo/bar/` and the other delimiters are used for other purposes.
If you use balancing curly braces, square brackets, or parentheses, the substitution works like this instead:
```raku
s[replace] = 'with';
```
The right-hand side is now a (not quoted) Raku expression, in which `$/` is available as the current match:
```raku
$_ = 'some 11 words 21';
s:g[ \d+ ] = 2 * $/;
.say; # OUTPUT: «some 22 words 42»
```
Like the `m//` operator, whitespace is ignored in the regex part of a substitution.
## [Replacing string literals](#Regexes "go to top of document")[§](#Replacing_string_literals "direct link")
The simplest thing to replace is a string literal. The string you want to replace goes on the left-hand side of the substitution operator, and the string you want to replace it with goes on the right-hand side; for example:
```raku
$_ = 'The Replacements';
s/Replace/Entrap/;
.say; # OUTPUT: «The Entrapments»
```
Alphanumeric characters and the underscore are literal matches, just as in its cousin the `m//` operator. All other characters must be escaped with a backslash `\` or included in quotes:
```raku
$_ = 'Space: 1999';
s/Space\:/Party like it's/;
.say # OUTPUT: «Party like it's 1999»
```
Note that the matching restrictions generally only apply to the left-hand side of the substitution expression, but some special characters or combinations of them may need to be escaped in the right-hand side (RHS). For example
```raku
$_ = 'foo';
s/foo/\%(/;
.say # OUTPUT: «%(»
```
or escape the '(' instead for the same result
```raku
s/foo/%\(/;
.say # OUTPUT: «%(»
```
but using either character alone does not require escaping. Forward slashes will need to be escaped, but escaping alphanumeric characters will cause them to be ignored. (NOTE: This RHS limitation was only recently noticed and this is not yet an exhaustive list of all characters or character pairs that require escapes for the RHS.)
By default, substitutions are only done on the first match:
```raku
$_ = 'There can be twly two';
s/tw/on/; # replace 'tw' with 'on' once
.say; # OUTPUT: «There can be only two»
```
## [Wildcards and character classes](#Regexes "go to top of document")[§](#Wildcards_and_character_classes "direct link")
Anything that can go into the `m//` operator can go into the left-hand side of the substitution operator, including wildcards and character classes. This is handy when the text you're matching isn't static, such as trying to match a number in the middle of a string:
```raku
$_ = "Blake's 9";
s/\d+/7/; # replace any sequence of digits with '7'
.say; # OUTPUT: «Blake's 7»
```
Of course, you can use any of the `+`, `*` and `?` modifiers, and they'll behave just as they would in the `m//` operator's context.
## [Capturing groups](#Regexes "go to top of document")[§](#Capturing_groups "direct link")
Just as in the match operator, capturing groups are allowed on the left-hand side, and the matched contents populate the `$0`..`$n` variables and the `$/` object:
```raku
$_ = '2016-01-23 18:09:00';
s/ (\d+)\-(\d+)\-(\d+) /today/; # replace YYYY-MM-DD with 'today'
.say; # OUTPUT: «today 18:09:00»
"$1-$2-$0".say; # OUTPUT: «01-23-2016»
"$/[1]-$/[2]-$/[0]".say; # OUTPUT: «01-23-2016»
```
Any of these variables `$0`, `$1`, `$/` can be used on the right-hand side of the operator as well, so you can manipulate what you've just matched. This way you can separate out the `YYYY`, `MM` and `DD` parts of a date and reformat them into `MM-DD-YYYY` order:
```raku
$_ = '2016-01-23 18:09:00';
s/ (\d+)\-(\d+)\-(\d+) /$1-$2-$0/; # transform YYYY-MM-DD to MM-DD-YYYY
.say; # OUTPUT: «01-23-2016 18:09:00»
```
Named capture can be used too:
```raku
$_ = '2016-01-23 18:09:00';
s/ $<y>=(\d+)\-$<m>=(\d+)\-$<d>=(\d+) /$<m>-$<d>-$<y>/;
.say; # OUTPUT: «01-23-2016 18:09:00»
```
Since the right-hand side is effectively a regular Raku interpolated string, you can reformat the time from `HH:MM` to `h:MM {AM,PM}` like so:
```raku
$_ = '18:38';
s/(\d+)\:(\d+)/{$0 % 12}\:$1 {$0 < 12 ?? 'AM' !! 'PM'}/;
.say; # OUTPUT: «6:38 PM»
```
Using the modulo `%` operator above keeps the sample code under 80 characters, but is otherwise the same as `$0 < 12 ?? $0 !! $0 - 12`. When combined with the power of the Parser Expression Grammars that **really** underlies what you're seeing here, you can use "regular expressions" to parse pretty much any text out there.
## [Common adverbs](#Regexes "go to top of document")[§](#Common_adverbs "direct link")
The full list of adverbs that you can apply to regular expressions can be found elsewhere in this document ([section Adverbs](#Adverbs)), but the most common are probably `:g` and `:i`.
* Global adverb `:g`
Ordinarily, matches are only made once in a given string, but adding the `:g` modifier overrides that behavior, so that substitutions are made everywhere possible. Substitutions are non-recursive; for example:
```raku
$_ = q{I can say "banana" but I don't know when to stop};
s:g/na/nana,/; # substitute 'nana,' for 'na'
.say; # OUTPUT: «I can say "banana,nana," but I don't ...»
```
Here, `na` was found twice in the original string and each time there was a substitution. The substitution only applied to the original string, though. The resulting string was not impacted.
* Insensitive adverb `:i`
Ordinarily, matches are case-sensitive. `s/foo/bar/` will only match `'foo'` and not `'Foo'`. If the adverb `:i` is used, though, matches become case-insensitive.
```raku
$_ = 'Fruit';
s/fruit/vegetable/;
.say; # OUTPUT: «Fruit»
s:i/fruit/vegetable/;
.say; # OUTPUT: «vegetable»
```
For more information on what these adverbs are actually doing, refer to the [section Adverbs](#Adverbs) section of this document.
These are just a few of the transformations you can apply with the substitution operator. Some of the simpler uses in the real world include removing personal data from log files, editing MySQL timestamps into PostgreSQL format, changing copyright information in HTML files and sanitizing form fields in a web application.
As an aside, novices to regular expressions often get overwhelmed and think that their regular expression needs to match every piece of data in the line, including what they want to match. Write just enough to match the data you're looking for, no more, no less.
## [`S///` non-destructive substitution](#Regexes "go to top of document")[§](#S///_non-destructive_substitution "direct link")
```raku
say S/o .+ d/new/ with 'old string'; # OUTPUT: «new string»
S:g/« (.)/$0.uc()/.say for <foo bar ber>; # OUTPUT: «FooBarBer»
```
`S///` uses the same semantics as the `s///` operator, except it leaves the original string intact and *returns the resultant string* instead of `$/` (`$/` still being set to the same values as with `s///`).
**Note:** since the result is obtained as a return value, using this operator with the `~~` smartmatch operator is a mistake and will issue a warning. To execute the substitution on a variable that isn't the `$_` this operator uses, alias it to `$_` with `given`, `with`, or any other way. Alternatively, use the [`.subst` method](/routine/subst).
# [Tilde for nesting structures](#Regexes "go to top of document")[§](#Tilde_for_nesting_structures "direct link")
The `~` operator is a helper for matching nested subrules with a specific terminator as the goal. It is designed to be placed between an opening and closing delimiter pair, like so:
```raku
/ '(' ~ ')' <expression> /
```
However, it mostly ignores the left argument, and operates on the next two atoms (which may be quantified). Its operation on those next two atoms is to "twiddle" them so that they are actually matched in reverse order. Hence the expression above, at first blush, is merely another way of writing:
```raku
/ '(' <expression> ')' /
```
Using `~` keeps the separators closer together but beyond that, when it rewrites the atoms it also inserts the apparatus that will set up the inner expression to recognize the terminator, and to produce an appropriate error message if the inner expression does not terminate on the required closing atom. So it really does pay attention to the left delimiter as well, and it actually rewrites our example to something more like:
```raku
$<OPEN> = '(' <SETGOAL: ')'> <expression> [ $GOAL || <FAILGOAL> ]
```
FAILGOAL is a special method that can be defined by the user and it will be called on parse failure:
```raku
grammar A { token TOP { '[' ~ ']' \w+ };
method FAILGOAL($goal) {
die "Cannot find $goal near position {self.pos}"
}
}
say A.parse: '[good]'; # OUTPUT: «「[good]」»
A.parse: '[bad'; # will throw FAILGOAL exception
CATCH { default { put .^name, ': ', .Str } };
# OUTPUT: «X::AdHoc: Cannot find ']' near position 4»
```
Note that you can use this construct to set up expectations for a closing construct even when there's no opening delimiter:
```raku
"3)" ~~ / <?> ~ ')' \d+ /; # OUTPUT: «「3)」»
"(3)" ~~ / <?> ~ ')' \d+ /; # OUTPUT: «「3)」»
```
Here `<?>` successfully matches the null string.
The order of the regex capture is original:
```raku
"abc" ~~ /a ~ (c) (b)/;
say $0; # OUTPUT: «「c」»
say $1; # OUTPUT: «「b」»
```
# [Recursive Regexes](#Regexes "go to top of document")[§](#Recursive_Regexes "direct link")
You can use `<~~>` to recursively invoke the current Regex from within the Regex. This can be extremely helpful for matching nested data structures. For example, consider this Regex:
```raku
/ '(' <-[()]>* ')' || '('[ <-[()]>* <~~> <-[()]>* ]* ')' /
```
This says "match **either** an open parentheses, followed by zero or more non-parentheses characters, followed by a close parentheses **or** an open parentheses followed by zero or more non-parentheses characters, followed by *another match for this Regex*, followed by zero or more non-parentheses characters, followed by a close parentheses." This Regex allows you to match arbitrarily many nested parentheses, as show below:
```raku
my $paren = rx/ '(' <-[()]>* ')' || '('[ <-[()]>* <~~> <-[()]>* ]* ')' /;
say 'text' ~~ $paren; # OUTPUT: «Nil»
say '(1 + 1) = 2' ~~ $paren; # OUTPUT: «「(1 + 1)」»
say '(1 + (2 × 3)) = 7' ~~ $paren; # OUTPUT: «「(1 + (2 × 3))」»
say '((5 + 2) × 6) = 42 (the answer)' ~~ $paren # OUTPUT: «「((5 + 2) × 6)」»
```
Note that the last expression shown above does *not* match all the way to the final `)`, as would have happened with `/'('.*')'/`, nor does it match only to the first `)`. Instead, it correctly matches to the close parentheses paired with the first opening parentheses, an effect that is very difficult to duplicate without recursive regexes.
When using recursive regexes (as with any other recursive data structure) you should be careful to avoid infinite recursion, which will cause your program to hang or crash.
# [Subrules](#Regexes "go to top of document")[§](#Subrules "direct link")
Just like you can put pieces of code into subroutines, you can also put pieces of regex into named rules.
```raku
my regex line { \N*\n }
if "abc\ndef" ~~ /<line> def/ {
say "First line: ", $<line>.chomp; # OUTPUT: «First line: abc»
}
```
A named regex can be declared with `my regex named-regex { body here }`, and called with `<named-regex>`. At the same time, calling a named regex installs a named capture with the same name.
To give the capture a different name from the regex, use the syntax `<capture-name=named-regex>`. If no capture is desired, a leading dot or ampersand will suppress it: `<.named-regex>` if it is a method declared in the same class or grammar, `<&named-regex>` for a regex declared in the same lexical context.
Here's more complete code for parsing `ini` files:
```raku
my regex header { \s* '[' (\w+) ']' \h* \n+ }
my regex identifier { \w+ }
my regex kvpair { \s* <key=identifier> '=' <value=identifier> \n+ }
my regex section {
<header>
<kvpair>*
}
my $contents = q:to/EOI/;
[passwords]
jack=password1
joy=muchmoresecure123
[quotas]
jack=123
joy=42
EOI
my %config;
if $contents ~~ /<section>*/ {
for $<section>.list -> $section {
my %section;
for $section<kvpair>.list -> $p {
%section{ $p<key> } = ~$p<value>;
}
%config{ $section<header>[0] } = %section;
}
}
say %config.raku;
# OUTPUT: «{:passwords(${:jack("password1"), :joy("muchmoresecure123")}),
# :quotas(${:jack("123"), :joy("42")})}»
```
Named regexes can and should be grouped in [grammars](/language/grammars). A list of predefined subrules is [here](#Predefined_character_classes).
# [Regex interpolation](#Regexes "go to top of document")[§](#Regex_interpolation "direct link")
Instead of using a literal pattern for a regex match, you can use a variable that holds that pattern. This variable can then be 'interpolated' into a regex, such that its appearance in the regex is replaced with the pattern that it holds. The advantage of using interpolation this way, is that the pattern need not be hardcoded in the source of your Raku program, but may instead be variable and generated at runtime.
There are four different ways of interpolating a variable into a regex as a pattern, which may be summarized as follows:
| Syntax | Description |
| --- | --- |
| $variable | Interpolates stringified contents of variable literally. |
| $(code) | Runs Raku code inside the regex, and interpolates the stringified return value literally. |
| <$variable> | Interpolates stringified contents of variable as a regex. |
| <{code}> | Runs Raku code inside the regex, and interpolates the stringified return value as a regex. |
Instead of the `$` sigil, you may use the `@` sigil for array interpolation. See below for how this works.
Let's start with the first two syntactical forms: `$variable` and `$(code)`. These forms will interpolate the stringified value of the variable or the stringified return value of the code literally, provided that the respective value isn't a [`Regex`](/type/Regex) object. If the value is a [`Regex`](/type/Regex), it will not be stringified, but instead be interpolated as such. 'Literally' means *strictly literally*, that is: as if the respective stringified value is quoted with a basic `Q` string [`Q[...]`](/language/quoting#Literal_strings:_Q). Consequently, the stringified value will not itself undergo any further interpolation.
For `$variable` this means the following:
```raku
my $string = 'Is this a regex or a string: 123\w+False$pattern1 ?';
my $pattern1 = 'string';
my $pattern2 = '\w+';
my $number = 123;
my $regex = /\w+/;
say $string.match: / 'string' /; # [1] OUTPUT: «「string」»
say $string.match: / $pattern1 /; # [2] OUTPUT: «「string」»
say $string.match: / $pattern2 /; # [3] OUTPUT: «「\w+」»
say $string.match: / $regex /; # [4] OUTPUT: «「Is」»
say $string.match: / $number /; # [5] OUTPUT: «「123」»
```
In this example, the statements `[1]` and `[2]` are equivalent and meant to illustrate a plain case of regex interpolation. Since unescaped/unquoted alphabetic characters in a regex match literally, the single quotes in the regex of statement `[1]` are functionally redundant; they have merely been included to emphasize the correspondence between the first two statements. Statement `[3]` unambiguously shows that the string pattern held by `$pattern2` is interpreted literally, and not as a regex. In case it would have been interpreted as a regex, it would have matched the first word of `$string`, i.e. `「Is」`, as can be seen in statement `[4]`. Statement `[5]` shows how the stringified number is used as a match pattern.
This code exemplifies the use of the `$(code)` syntax:
```raku
my $string = 'Is this a regex or a string: 123\w+False$pattern1 ?';
my $pattern1 = 'string';
my $pattern3 = 'gnirts';
my $pattern4 = '$pattern1';
my $bool = True;
my sub f1 { return Q[$pattern1] };
say $string.match: / $pattern3.flip /; # [6] OUTPUT: «Nil»
say $string.match: / "$pattern3.flip()" /; # [7] OUTPUT: «「string」»
say $string.match: / $($pattern3.flip) /; # [8] OUTPUT: «「string」»
say $string.match: / $([~] $pattern3.comb.reverse) /; # [9] OUTPUT: «「string」»
say $string.match: / $(!$bool) /; # [10] OUTPUT: «「False」»
say $string.match: / $pattern4 /; # [11] OUTPUT: «「$pattern1」»
say $string.match: / $(f1) /; # [12] OUTPUT: «「$pattern1」»
```
Statement `[6]` does not work as probably intended. To the human reader, the dot `.` may seem to represent the [method call operator](/language/operators#methodop_.), but since a dot is not a valid character for an [ordinary identifier](/language/syntax#Ordinary_identifiers), and given the regex context, the compiler will parse it as the regex wildcard [.](/language/regexes#Wildcards) that matches any character. The apparent ambiguity may be resolved in various ways, for instance through the use of straightforward [string interpolation](/language/quoting#Interpolation:_qq) from the regex as in statement `[7]` (note that the inclusion of the call operator `()` is key here), or by using the second syntax form from the above table as in statement `[8]`, in which case the match pattern `string` first emerges as the return value of the `flip` method call. Since general Raku code may be run from within the parentheses of `$( )`, the same effect can also be achieved with a bit more effort, like in statement `[9]`. Statement `[10]` illustrates how the stringified version of the code's return value (the Boolean value `False`) is matched literally.
Finally, statements `[11]` and `[12]` show how the value of `$pattern4` and the return value of `f1` are *not* subject to a further round of interpolation. Hence, in general, after possible stringification, `$variable` and `$(code)` provide for a strictly literal match of the variable or return value.
Now consider the second two syntactical forms from the table above: `<$variable>` and `<{code}>`. These forms will stringify the value of the variable or the return value of the code and interpolate it as a regex. If the respective value is a [`Regex`](/type/Regex), it is interpolated as such:
```raku
my $string = 'Is this a regex or a string: 123\w+$x ?';
my $pattern1 = '\w+';
my $number = 123;
my sub f1 { return /s\w+/ };
say $string.match: / <$pattern1> /; # OUTPUT: «「Is」»
say $string.match: / <$number> /; # OUTPUT: «「123」»
say $string.match: / <{ f1 }> /; # OUTPUT: «「string」»
```
Importantly, 'to interpolate as a regex' means to interpolate/insert into the target regex without protective quoting. Consequently, if the value of the variable `$variable1` is itself of the form `$variable2`, evaluation of `<$variable1>` or `<{ $variable1 }>` inside a target regex `/.../` will cause the target regex to assume the form `/$variable2/`. As described above, the evaluation of this regex will then trigger further interpolation of `$variable2`:
```raku
my $string = Q[Mindless \w+ $variable1 $variable2];
my $variable1 = Q[\w+];
my $variable2 = Q[$variable1];
my sub f1 { return Q[$variable2] };
# /<{ f1 }>/ ==> /$variable2/ ==> / '$variable1' /
say $string.match: / <{ f1 }> /; # OUTPUT: «「$variable1」»
# /<$variable2>/ ==> /$variable1/ ==> / '\w+' /
say $string.match: /<$variable2>/; # OUTPUT: «「\w+」»
# /<$variable1>/ ==> /\w+/
say $string.match: /<$variable1>/; # OUTPUT: «「Mindless」»
```
When an array variable is interpolated into a regex, the regex engine handles it like a `|` alternative of the regex elements (see the documentation on [embedded lists](/language/regexes#Quoted_lists_are_LTM_matches), above). The interpolation rules for individual elements are the same as for scalars, so strings and numbers match literally, and [`Regex`](/type/Regex) objects match as regexes. Just as with ordinary `|` interpolation, the longest match succeeds:
```raku
my @a = '2', 23, rx/a.+/;
say ('b235' ~~ / b @a /).Str; # OUTPUT: «b23»
```
If you have an expression that evaluates to a list, but you do not want to assign it to an @-sigiled variable first, you can interpolate it with `@(code)`. In this example, both regexes are equivalent:
```raku
my %h = a => 1, b => 2;
my @a = %h.keys;
say S:g/@(%h.keys)/%h{$/}/ given 'abc'; # OUTPUT: «12c>
say S:g/@a/%h{$/}/ given 'abc'; # OUTPUT: «12c>
```
The use of hashes in regexes is reserved.
## [Regex Boolean condition check](#Regexes "go to top of document")[§](#Regex_Boolean_condition_check "direct link")
The special operator `<?{}>` allows the evaluation of a Boolean expression that can perform a semantic evaluation of the match before the regular expression continues. In other words, it is possible to check in a Boolean context a part of a regular expression and therefore invalidate the whole match (or allow it to continue) even if the match succeeds from a syntactic point of |
## regexes.md
## Chunk 4 of 5
view.
In particular the `<?{}>` operator requires a `True` value in order to allow the regular expression to match, while its negated form `<!{}>` requires a `False` value.
In order to demonstrate the above operator, please consider the following example that involves a simple IPv4 address matching:
```raku
my $localhost = '127.0.0.1';
my regex ipv4-octet { \d ** 1..3 <?{ True }> }
$localhost ~~ / ^ <ipv4-octet> ** 4 % "." $ /;
say $/<ipv4-octet>; # OUTPUT: «[「127」 「0」 「0」 「1」]»
```
The `octet` regular expression matches against a number made by one up to three digits. Each match is driven by the result of the `<?{}>`, that being the fixed value of `True` means that the regular expression match has to be always considered as good. As a counter-example, using the special constant value `False` will invalidate the match even if the regular expression matches from a syntactic point of view:
```raku
my $localhost = '127.0.0.1';
my regex ipv4-octet { \d ** 1..3 <?{ False }> }
$localhost ~~ / ^ <ipv4-octet> ** 4 % "." $ /;
say $/<ipv4-octet>; # OUTPUT: «Nil»
```
From the above examples, it should be clear that it is possible to improve the semantic check, for instance ensuring that each *octet* is really a valid IPv4 octet:
```raku
my $localhost = '127.0.0.1';
my regex ipv4-octet { \d ** 1..3 <?{ 0 <= $/.Int <= 255 }> }
$localhost ~~ / ^ <ipv4-octet> ** 4 % "." $ /;
say $/<ipv4-octet>; # OUTPUT: «[「127」 「0」 「0」 「1」]»
```
Please note that it is not required to evaluate the regular expression in-line, but also a regular method can be called to get the Boolean value:
```raku
my $localhost = '127.0.0.1';
sub check-octet ( Int $o ){ 0 <= $o <= 255 }
my regex ipv4-octet { \d ** 1..3 <?{ &check-octet( $/.Int ) }> }
$localhost ~~ / ^ <ipv4-octet> ** 4 % "." $ /;
say $/<ipv4-octet>; # OUTPUT: «[「127」 「0」 「0」 「1」]»
```
Of course, being `<!{}>` the negation form of `<?{}>` the same Boolean evaluation can be rewritten in a negated form:
```raku
my $localhost = '127.0.0.1';
sub invalid-octet( Int $o ){ $o < 0 || $o > 255 }
my regex ipv4-octet { \d ** 1..3 <!{ &invalid-octet( $/.Int ) }> }
$localhost ~~ / ^ <ipv4-octet> ** 4 % "." $ /;
say $/<ipv4-octet>; # OUTPUT: «[「127」 「0」 「0」 「1」]»
```
# [Adverbs](#Regexes "go to top of document")[§](#Adverbs "direct link")
Adverbs, which modify how regexes work and provide convenient shortcuts for certain kinds of recurring tasks, are combinations of one or more letters preceded by a colon `:`.
The so-called *regex* adverbs apply at the point where a regex is defined; additionally, *matching* adverbs apply at the point that a regex matches against a string and *substitution* adverbs are applied exclusively in substitutions.
This distinction often blurs, because matching and declaration are often textually close but using the method form of matching, that is, `.match`, makes the distinction clear.
```raku
say "Abra abra CADABRA" ~~ m:exhaustive/:i a \w+ a/;
# OUTPUT: «(「Abra」 「abra」 「ADABRA」 「ADA」 「ABRA」)»
my $regex = /:i a \w+ a /;
say "Abra abra CADABRA".match($regex,:ex);
# OUTPUT: «(「Abra」 「abra」 「ADABRA」 「ADA」 「ABRA」)»
```
In the first example, the matching adverb (`:exhaustive`) is contiguous to the regex adverb (`:i`), and as a matter of fact, the "definition" and the "matching" go together; however, by using `match` it becomes clear that `:i` is only used when defining the `$regex` variable, and `:ex` (short for `:exhaustive`) as an argument when matching. As a matter of fact, matching adverbs cannot even be used in the definition of a regex:
```raku
my $regex = rx:ex/:i a \w+ a /;
# ===SORRY!=== Error while compiling (...)Adverb ex not allowed on rx
```
Regex adverbs like `:i` go into the definition line and matching adverbs like `:overlap` (which can be abbreviated to `:ov`) are appended to the match call:
```raku
my $regex = /:i . a/;
for 'baA'.match($regex, :overlap) -> $m {
say ~$m;
}
# OUTPUT: «baaA»
```
## [Regex adverbs](#Regexes "go to top of document")[§](#Regex_adverbs "direct link")
The adverbs that appear at the time of a regex declaration are part of the actual regex and influence how the Raku compiler translates the regex into binary code.
For example, the `:ignorecase` (`:i`) adverb tells the compiler to ignore the distinction between uppercase, lowercase, and titlecase letters.
So `'a' ~~ /A/` is false, but `'a' ~~ /:i A/` is a successful match.
Regex adverbs can come before or inside a regex declaration and only affect the part of the regex that comes afterwards, lexically. Note that regex adverbs appearing before the regex must appear after something that introduces the regex to the parser, like 'rx' or 'm' or a bare '/'. This is NOT valid:
```raku
my $rx1 = :i/a/; # adverb is before the regex is recognized => exception
```
but these are valid:
```raku
my $rx1 = rx:i/a/; # before
my $rx2 = m:i/a/; # before
my $rx3 = /:i a/; # inside
```
These two regexes are equivalent:
```raku
my $rx1 = rx:i/a/; # before
my $rx2 = rx/:i a/; # inside
```
Whereas these two are not:
```raku
my $rx3 = rx/a :i b/; # matches only the b case insensitively
my $rx4 = rx/:i a b/; # matches completely case insensitively
```
Square brackets and parentheses limit the scope of an adverb:
```raku
/ (:i a b) c /; # matches 'ABc' but not 'ABC'
/ [:i a b] c /; # matches 'ABc' but not 'ABC'
```
Alternations and conjunctions, and their branches, have no impact on the scope of an adverb:
/ :i a | b c /; # matches 'a', 'A', 'bc', 'Bc', 'bC' or 'BC' / [:i a | b] c /; # matches 'ac', 'Ac', 'bc', or 'Bc' but not 'aC', 'AC', 'bC' or 'BC'
When two adverbs are used together, they keep their colon at the front
```raku
"þor is Þor" ~~ m:g:i/þ/; # OUTPUT: «(「þ」 「Þ」)»
```
That implies that when there are multiple characters together after a `:`, they correspond to the same adverb, as in `:ov` or `:P5`.
### [Ignorecase](#Regexes "go to top of document")[§](#Ignorecase "direct link")
The `:ignorecase` or `:i` adverb instructs the regex engine to ignore the distinction between uppercase, lowercase, and titlecase letters.
See the [section Regex adverbs](/language/regexes#Regex_adverbs) for examples.
### [Ignoremark](#Regexes "go to top of document")[§](#Ignoremark "direct link")
The `:ignoremark` or `:m` adverb instructs the regex engine to only compare base characters, and ignore additional marks such as combining accents:
```raku
say so 'a' ~~ rx/ä/; # OUTPUT: «False»
say so 'a' ~~ rx:ignoremark /ä/; # OUTPUT: «True»
say so 'ỡ' ~~ rx:ignoremark /o/; # OUTPUT: «True»
```
### [Ratchet](#Regexes "go to top of document")[§](#Ratchet "direct link")
The `:ratchet` or `:r` adverb causes the regex engine to not backtrack (see [backtracking](/language/regexes#Backtracking)). Mnemonic: a [ratchet](https://en.wikipedia.org/wiki/Ratchet_%28device%29) only moves in one direction and can't backtrack.
Without this adverb, parts of a regex will try different ways to match a string in order to make it possible for other parts of the regex to match. For example, in `'abc' ~~ /\w+ ./`, the `\w+` first eats up the whole string, `abc` but then the `.` fails. Thus `\w+` gives up a character, matching only `ab`, and the `.` can successfully match the string `c`. This process of giving up characters (or in the case of alternations, trying a different branch) is known as backtracking.
```raku
say so 'abc' ~~ / \w+ . /; # OUTPUT: «True»
say so 'abc' ~~ / :r \w+ . /; # OUTPUT: «False»
```
Ratcheting can be an optimization, because backtracking is costly. But more importantly, it closely corresponds to how humans parse a text. If you have a regex `my regex identifier { \w+ }` and `my regex keyword { if | else | endif }`, you intuitively expect the `identifier` to gobble up a whole word and not have it give up its end to the next rule, if the next rule otherwise fails.
For example, you don't expect the word `motif` to be parsed as the identifier `mot` followed by the keyword `if`. Instead, you expect `motif` to be parsed as one identifier; and if the parser expects an `if` afterwards, best that it should fail than have it parse the input in a way you don't expect.
Since ratcheting behavior is often desirable in parsers, there's a shortcut to declaring a ratcheting regex:
```raku
my token thing { ... };
# short for
my regex thing { :r ... };
```
### [Sigspace](#Regexes "go to top of document")[§](#Sigspace "direct link")
The **`:sigspace`** or **`:s`** adverb changes the behavior of unquoted whitespace in a regex.
Without `:sigspace`, unquoted whitespace in a regex is generally ignored, to make regexes more readable by programmers. When `:sigspace` is present, unquoted whitespace may be converted into `<.ws>` subrule calls depending on where it occurs in the regex.
```raku
say so "I used Photoshop®" ~~ m:i/ photo shop /; # OUTPUT: «True»
say so "I used a photo shop" ~~ m:i:s/ photo shop /; # OUTPUT: «True»
say so "I used Photoshop®" ~~ m:i:s/ photo shop /; # OUTPUT: «False»
```
`m:s/ photo shop /` acts the same as `m/ photo <.ws> shop <.ws> /`. By default, `<.ws>` makes sure that words are separated, so `a b` and `^&` will match `<.ws>` in the middle, but `ab` won't:
```raku
say so "ab" ~~ m:s/a <.ws> b/; # OUTPUT: «False»
say so "a b" ~~ m:s/a <.ws> b/; # OUTPUT: «True»
say so "^&" ~~ m:s/'^' <.ws> '&'/; # OUTPUT: «True»
```
The third line is matched, because `^&` is not a word. For more clarification on how `<.ws>` rule works, refer to [WS rule description](/language/grammars#ws).
Where whitespace in a regex turns into `<.ws>` depends on what comes before the whitespace. In the above example, whitespace in the beginning of a regex doesn't turn into `<.ws>`, but whitespace after characters does. In general, the rule is that if a term might match something, whitespace after it will turn into `<.ws>`.
In addition, if whitespace comes after a term but *before* a quantifier (`+`, `*`, or `?`), `<.ws>` will be matched after every match of the term. So, `foo +` becomes `[ foo <.ws> ]+`. On the other hand, whitespace *after* a quantifier acts as normal significant whitespace; e.g., "`foo+` " becomes `foo+ <.ws>`. On the other hand, whitespace between a quantifier and the `%` or `%%` quantifier modifier is not significant. Thus `foo+ % ,` does *not* become `foo+ <.ws>% ,` (which would be invalid anyway); instead, neither of the spaces are significant.
In all, this code:
```raku
rx :s {
^^
{
say "No sigspace after this";
}
<.assertion_and_then_ws>
characters_with_ws_after+
ws_separated_characters *
[
| some "stuff" .. .
| $$
]
:my $foo = "no ws after this";
$foo
}
```
Becomes:
```raku
rx {
^^ <.ws>
{
say "No space after this";
}
<.assertion_and_then_ws> <.ws>
characters_with_ws_after+ <.ws>
[ws_separated_characters <.ws>]* <.ws>
[
| some <.ws> "stuff" <.ws> .. <.ws> . <.ws>
| $$ <.ws>
] <.ws>
:my $foo = "no ws after this";
$foo <.ws>
}
```
If a regex is declared with the `rule` keyword, both the `:sigspace` and `:ratchet` adverbs are implied.
Grammars provide an easy way to override what `<.ws>` matches:
```raku
grammar Demo {
token ws {
<!ww> # only match when not within a word
\h* # only match horizontal whitespace
}
rule TOP { # called by Demo.parse;
a b '.'
}
}
# doesn't parse, whitespace required between a and b
say so Demo.parse("ab."); # OUTPUT: «False»
say so Demo.parse("a b."); # OUTPUT: «True»
say so Demo.parse("a\tb ."); # OUTPUT: «True»
# \n is vertical whitespace, so no match
say so Demo.parse("a\tb\n."); # OUTPUT: «False»
```
When parsing file formats where some whitespace (for example, vertical whitespace) is significant, it's advisable to override `ws`.
### [Perl compatibility adverb](#Regexes "go to top of document")[§](#Perl_compatibility_adverb "direct link")
The **`:Perl5`** or **`:P5`** adverb switch the Regex parsing and matching to the way Perl regexes behave:
```raku
so 'hello world' ~~ m:Perl5/^hello (world)/; # OUTPUT: «True»
so 'hello world' ~~ m/^hello (world)/; # OUTPUT: «False»
so 'hello world' ~~ m/^ 'hello ' ('world')/; # OUTPUT: «True»
```
The regular behavior is recommended and more idiomatic in Raku of course, but the **`:Perl5`** adverb can be useful when compatibility with Perl is required.
## [Matching adverbs](#Regexes "go to top of document")[§](#Matching_adverbs "direct link")
In contrast to regex adverbs, which are tied to the declaration of a regex, matching adverbs only make sense when matching a string against a regex.
They can never appear inside a regex, only on the outside – either as part of an `m/.../` match or as arguments to a match method.
### [Positional adverbs](#Regexes "go to top of document")[§](#Positional_adverbs "direct link")
Positional adverbs make the expression match only the string in the indicated position:
```raku
my $data = "f fo foo fooo foooo fooooo foooooo";
say $data ~~ m:nth(4)/fo+/; # OUTPUT: «「foooo」»
say $data ~~ m:1st/fo+/; # OUTPUT: «「fo」»
say $data ~~ m:3rd/fo+/; # OUTPUT: «「fooo」»
say $data ~~ m:nth(1,3)/fo+/; # OUTPUT: «(「fo」 「fooo」)»
```
As you can see, the adverb argument can also be a list. There's actually no difference between the `:nth` adverb and the rest. You choose them only based on legibility. From 6.d, you can also use [`Junction`](/type/Junction)s, [`Seq`](/type/Seq)s and [`Range`](/type/Range)s, even infinite ones, as arguments.
```raku
my $data = "f fo foo fooo foooo fooooo foooooo";
say $data ~~ m:st(1|8)/fo+/; # OUTPUT: «True»
```
In this case, one of them exists (1), so it returns True. Observe that we have used `:st`. As said above, it's functionally equivalent, although obviously less legible than using `:nth`, so this last form is advised.
### [Counting](#Regexes "go to top of document")[§](#Counting "direct link")
The `:x` counting adverb makes the expression match many times, like the `:g` adverb, but only up to the limit given by the adverb expression, stopping once the specified number of matches has been reached. The value must be a [`Numeric`](/type/Numeric) or a [`Range`](/type/Range).
```raku
my $data = "f fo foo fooo foooo fooooo foooooo";
$data ~~ s:x(8)/o/X/; # f fX fXX fXXX fXXoo fooooo foooooo
```
### [Continue](#Regexes "go to top of document")[§](#Continue "direct link")
The `:continue` or short `:c` adverb takes an argument. The argument is the position where the regex should start to search. By default, it searches from the start of the string, but `:c` overrides that. If no position is specified for `:c`, it will default to `0` unless `$/` is set, in which case, it defaults to `$/.to`.
```raku
given 'a1xa2' {
say ~m/a./; # OUTPUT: «a1»
say ~m:c(2)/a./; # OUTPUT: «a2»
}
```
*Note:* unlike `:pos`, a match with :continue() will attempt to match further in the string, instead of failing:
```raku
say "abcdefg" ~~ m:c(3)/e.+/; # OUTPUT: «「efg」»
say "abcdefg" ~~ m:p(3)/e.+/; # OUTPUT: «False»
```
### [Exhaustive](#Regexes "go to top of document")[§](#Exhaustive "direct link")
To find all possible matches of a regex – including overlapping ones – and several ones that start at the same position, use the `:exhaustive` (short `:ex`) adverb.
```raku
given 'abracadabra' {
for m:exhaustive/ a .* a / -> $match {
say ' ' x $match.from, ~$match;
}
}
```
The above code produces this output:
「text」 without highlighting
```
```
abracadabra
abracada
abraca
abra
acadabra
acada
aca
adabra
ada
abra
```
```
### [Global](#Regexes "go to top of document")[§](#Global "direct link")
Instead of searching for just one match and returning a [`Match`](/type/Match), search for every non-overlapping match and return them in a [`List`](/type/List). In order to do this, use the `:global` adverb:
```raku
given 'several words here' {
my @matches = m:global/\w+/;
say @matches.elems; # OUTPUT: «3»
say ~@matches[2]; # OUTPUT: «here»
}
```
`:g` is shorthand for `:global`.
### [Pos](#Regexes "go to top of document")[§](#Pos "direct link")
Anchor the match at a specific position in the string:
```raku
given 'abcdef' {
my $match = m:pos(2)/.*/;
say $match.from; # OUTPUT: «2»
say ~$match; # OUTPUT: «cdef»
}
```
`:p` is shorthand for `:pos`.
*Note:* unlike `:continue`, a match anchored with :pos() will fail, instead of attempting to match further down the string:
```raku
say "abcdefg" ~~ m:c(3)/e.+/; # OUTPUT: «「efg」»
say "abcdefg" ~~ m:p(3)/e.+/; # OUTPUT: «False»
```
### [Overlap](#Regexes "go to top of document")[§](#Overlap "direct link")
To get several matches, including overlapping matches, but only one (the longest) from each starting position, specify the `:overlap` (short `:ov`) adverb:
```raku
given 'abracadabra' {
for m:overlap/ a .* a / -> $match {
say ' ' x $match.from, ~$match;
}
}
```
produces
「text」 without highlighting
```
```
abracadabra
acadabra
adabra
abra
```
```
## [Substitution adverbs](#Regexes "go to top of document")[§](#Substitution_adverbs "direct link")
You can apply matching adverbs (such as `:global`, `:pos` etc.) to substitutions. In addition, there are adverbs that only make sense for substitutions, because they transfer a property from the matched string to the replacement string.
### [Samecase](#Regexes "go to top of document")[§](#Samecase "direct link")
The `:samecase` or `:ii` substitution adverb implies the `:ignorecase` adverb for the regex part of the substitution, and in addition carries the case information to the replacement string:
```raku
$_ = 'The cat chases the dog';
s:global:samecase[the] = 'a';
say $_; # OUTPUT: «A cat chases a dog»
```
Here you can see that the first replacement string `a` got capitalized, because the first string of the matched string was also a capital letter.
### [Samemark](#Regexes "go to top of document")[§](#Samemark "direct link")
The `:samemark` or `:mm` adverb implies `:ignoremark` for the regex, and in addition, copies the markings from the matched characters to the replacement string:
```raku
given 'äộñ' {
say S:mm/ a .+ /uia/; # OUTPUT: «üị̂ã»
}
```
### [Samespace](#Regexes "go to top of document")[§](#Samespace "direct link")
The `:samespace` or `:ss` substitution modifier implies the `:sigspace` modifier for the regex, and in addition, copies the whitespace from the matched string to the replacement string:
```raku
say S:samespace/a ./c d/.raku given "a b"; # OUTPUT: «"c d"»
say S:samespace/a ./c d/.raku given "a\tb"; # OUTPUT: «"c\td"»
say S:samespace/a ./c d/.raku given "a\nb"; # OUTPUT: «"c\nd"»
```
The `ss/.../.../` syntactic form is a shorthand for `s:samespace/.../.../`.
# [Backtracking](#Regexes "go to top of document")[§](#Backtracking "direct link")
Raku defaults to [backtracking](/language/glossary#Backtracking) when evaluating regular expressions. Backtracking is a technique that allows the engine to try different matching in order to allow every part of a regular expression to succeed. This is costly, because it requires the engine to usually eat up as much as possible in the first match and then adjust going backwards in order to ensure all regular expression parts have a chance to match.
## [Understanding backtracking](#Regexes "go to top of document")[§](#Understanding_backtracking "direct link")
In order to better understand backtracking, consider the following example:
```raku
my $string = 'PostgreSQL is a SQL database!';
say $string ~~ /(.+)(SQL) (.+) $1/; # OUTPUT: «「PostgreSQL is a SQL」»
```
What happens in the above example is that the string has to be matched against the second occurrence of the word *SQL*, eating all characters before and leaving out the rest.
Since it is possible to execute a piece of code within a regular expression, it is also possible to inspect the [`Match`](/type/Match) object within the regular expression itself:
```raku
my $iteration = 0;
sub show-captures( Match $m ){
my Str $result_split;
say "\n=== Iteration {++$iteration} ===";
for $m.list.kv -> $i, $capture {
say "Capture $i = $capture";
$result_split ~= '[' ~ $capture ~ ']';
}
say $result_split;
}
$string ~~ /(.+)(SQL) (.+) $1 .+ { show-captures( $/ ); }/;
```
The `show-captures` method will dump all the elements of `$/` producing the following output:
「text」 without highlighting
```
```
=== Iteration 1 ===
Capture 0 = Postgre
Capture 1 = SQL
Capture 2 = is a
[Postgre][SQL][ is a ]
```
```
showing that the string has been split around the second occurrence of *SQL*, that is the repetition of the first capture (`$/[1]`).
With that in place, it is now possible to see how the engine backtracks to find the above match: it does suffice to move the `show-captures` in the middle of the regular expression, in particular before the repetition of the first capture `$1` to see it in action:
```raku
my $iteration = 0;
sub show-captures( Match $m ){
my Str $result-split;
say "\n=== Iteration {++$iteration} ===";
for $m.list.kv -> $i, $capture {
say "Capture $i = $capture";
$result-split ~= '[' ~ $capture ~ ']';
}
say $result-split;
}
$string ~~ / (.+)(SQL) (.+) { show-captures( $/ ); } $1 /;
```
The output will be much more verbose and will show several iterations, with the last one being the *winning*. The following is an excerpt of the output:
「text」 without highlighting
```
```
=== Iteration 1 ===
Capture 0 = PostgreSQL is a
Capture 1 = SQL
Capture 2 = database!
[PostgreSQL is a ][SQL][ database!]
=== Iteration 2 ===
Capture 0 = PostgreSQL is a
Capture 1 = SQL
Capture 2 = database
[PostgreSQL is a ][SQL][ database]
...
=== Iteration 24 ===
Capture 0 = Postgre
Capture 1 = SQL
Capture 2 = is a
[Postgre][SQL][ is a ]
```
```
In the first iteration the *SQL* part of *PostgreSQL* is kept within the word: that is not what the regular expression asks for, so there's the need for another iteration. The second iteration will move back, in particular one character back (removing thus the final *!*) and try to match again, resulting in a fail since again the *SQL* is still kept within *PostgreSQL*. After several iterations, the final result is match.
It is worth noting that the final iteration is number *24*, and that such number is exactly the distance, in number of chars, from the end of the string to the first *SQL* occurrence:
```raku
say $string.chars - $string.index: 'SQL'; # OUTPUT: «23»
```
Since there are 23 chars from the very end of the string to the very first *S* of *SQL* the backtracking engine will need 23 "useless" matches to find the right one, that is, it will need 24 steps to get the final result.
Backtracking is a costly machinery, therefore it is possible to disable it in those cases where the matching can be found *forward* only.
With regards to the above example, disabling backtracking means the regular expression will not have any chance to match:
```raku
say $string ~~ /(.+)(SQL) (.+) $1/; # OUTPUT: «「PostgreSQL is a SQL」»
say $string ~~ / :r (.+)(SQL) (.+) $1/; # OUTPUT: «Nil»
```
The fact is that, as shown in the *iteration 1* output, the first match of the regular expression engine will be `PostgreSQL is a` , `SQL`, `database` that does not leave out any room for matching another occurrence of the word *SQL* (as `$1` in the regular expression). Since the engine is not able to get backward and change the path to match, the regular expression fails.
It is worth noting that disabling backtracking will not prevent the engine to try several ways to match the regular expression. Consider the following slightly changed example:
```raku
my $string = 'PostgreSQL is a SQL database!';
say $string ~~ / (SQL) (.+) $1 /; # OUTPUT: «Nil»
```
Since there is no specification for a character before the word *SQL*, the engine will match against the rightmost word *SQL* and go forward from there. Since there is no repetition of *SQL* remaining, the match fails. It is possible, again, to inspect what the engine performs introducing a dumping piece of code within the regular expression:
```raku
my $iteration = 0;
sub show-captures( Match $m ){
my Str $result-split;
say "\n=== Iteration {++$iteration} ===";
for $m.list.kv -> $i, $capture {
say "Capture $i = $capture";
$result-split ~= '[' ~ $capture ~ ']';
}
say $result-split;
}
$string ~~ / (SQL) (.+) { show-captures( $/ ); } $1 /;
```
that produces a rather simple output:
「text」 without highlighting
```
```
=== Iteration 1 ===
Capture 0 = SQL
Capture 1 = is a SQL database!
[SQL][ is a SQL database!]
=== Iteration 2 ===
Capture 0 = SQL
Capture 1 = database!
[SQL][ database!]
```
```
Even using the [:r](/language/regexes#Ratchet) adverb to prevent backtracking will not change things:
```raku
my $iteration = 0;
sub show-captures( Match $m ){
my Str $result-split;
say "\n=== Iteration {++$iteration} ===";
for $m.list.kv -> $i, $capture {
say "Capture $i = $capture";
$result-split ~= '[' ~ $capture ~ ']';
}
say $result-split;
}
$string ~~ / :r (SQL) (.+) { show-captures( $/ ); } $1 /;
```
and the output will remain the same:
「text」 without highlighting
```
```
=== Iteration 1 ===
Capture 0 = SQL
Capture 1 = is a SQL database!
[SQL][ is a SQL database!]
=== Iteration 2 ===
Capture 0 = SQL
Capture 1 = database!
[SQL][ database!]
```
```
This demonstrates that disabling backtracking does not mean disabling possible multiple iterations of the matching engine, but rather disabling the backward matching tuning.
## [Backtracking control](#Regexes "go to top of document")[§](#Backtracking_control "direct link")
Raku offers several tools for controlling backtracking. First, you can use the `:ratchet` regex adverb to turn ratcheting on (or `:!ratchet` to turn it off). See [backtracking](/language/regexes#Ratchet) for details. Note that, as with all regex adverbs, you can limit the scope of `:ratchet` using square brackets. Thus, in the following code, backtracking is enabled for the first quantifier (`\S+`), disabled for the second quantifier (`\s+`), and re-enabled for the third (`\d+`).
```raku
'A 42' ~~ rx/\S+ [:r \s+ [:!r \d+ ] ] . / # OUTPUT: «「A 42」»
```
`:ratchet` is enabled by default in `token`s and `rule`s; see [grammars](/language/grammars) for more details.
Raku also offers three regex metacharacters to control backtracking at for an individual atom.
### [Disable backtracking: `:`](#Regexes "go to top of document")[§](#Disable_backtracking:_: "direct link")
The `:` metacharacter disables backtracking for the previous atom. Thus, `/ .*: a/` does not match `" a"` because the `.*` matches the entire string, leaving nothing for the `a` to match without backtracking.
### [Enable greedy backtracking: `:!`](#Regexes "go to top of document")[§](#Enable_greedy_backtracking:_:! "direct link")
The `:!` metacharacter enables greedy backtracking for the previous atom – that is, provides the backtracking behavior that's used when `:ratchet` is not in effect. `:!` is closely related to the `!` [greedy quantifier modifier](/language/regexes#Greedy_versus_frugal_quantifiers:_?); however – unlike `!`, which can only be used after a quantifier – `:!` can be used after any atom. For example, `:!` can be used after an alternation:
```raku
'abcd' ~~ /:ratchet [ab | abc] cd/; # OUTPUT: «Nil»
'abcd' ~~ |
## regexes.md
## Chunk 5 of 5
/:ratchet [ab | abc]:! cd/; # OUTPUT: «「abcd」»
```
### [Enable frugal backtracking: `:?`](#Regexes "go to top of document")[§](#Enable_frugal_backtracking:_:? "direct link")
The `:?` metacharacter works exactly like `:!`, except that it enables frugal backtracking. It is thus closely related to `?` [frugal quantifier modifier](/language/regexes#Greedy_versus_frugal_quantifiers:_?); again, however `:?` can be used after non-quantifier atoms. This includes contexts in which `?` would be the [zero or one](#Zero_or_one:_?) quantifier (instead of providing backtracking control):
```raku
my regex numbers { \d* }
'4247' ~~ /:ratchet <numbers>? 47/; # OUTPUT: «Nil»
'4247' ~~ /:ratchet <numbers>:? 47/; # OUTPUT: «「4247」»
```
## [A note on backtracking with sub-regexes](#Regexes "go to top of document")[§](#A_note_on_backtracking_with_sub-regexes "direct link")
`:`, `:!`, and `:?` control the backtracking behavior in their current regex – that is, they cause an atom to behave as though `:ratchet` were set differently in the current regex. However, neither these metacharacters nor `:!ratchet` can cause a non-backtracking sub-regex (including rules or tokens) to backtrack; the sub-regex has already failed to backtrack. On the other hand, they *can* prevent the sub-regex from backtracking. To expand on our previous example:
```raku
my regex numbers { \d* }
# By default <numbers> backtracks
'4247' ~~ / <numbers> 47/; # OUTPUT: «「4247」»
# : can disable backtracking over <numbers>
'4247' ~~ / <numbers>: 47/; # OUTPUT: «Nil»
my regex numbers-ratchet {:ratchet \d* }
# <numbers-ratchet> never backtracks
'4247' ~~ / <numbers-ratchet> 47/; # OUTPUT: «Nil»
# :! can't make it
'4247' ~~ / <numbers-ratchet>:! 47/; # OUTPUT: «Nil»
# Neither can setting :!ratchet
'4247' ~~ /:!r <numbers-ratchet> 47/; # OUTPUT: «Nil»
```
# [`$/` changes each time a regular expression is matched](#Regexes "go to top of document")[§](#$/_changes_each_time_a_regular_expression_is_matched "direct link")
It is worth noting that each time a regular expression is used, the returned [`Match`](/type/Match) (i.e., `$/`) is reset. In other words, `$/` always refers to the very last regular expression matched:
```raku
my $answer = 'a lot of Stuff';
say 'Hit a capital letter!' if $answer ~~ / <[A..Z>]> /;
say $/; # OUTPUT: «「S」»
say 'hit an x!' if $answer ~~ / x /;
say $/; # OUTPUT: «Nil»
```
The reset of `$/` applies independently from the scope where the regular expression is matched:
```raku
my $answer = 'a lot of Stuff';
if $answer ~~ / <[A..Z>]> / {
say 'Hit a capital letter';
say $/; # OUTPUT: «「S」»
}
say $/; # OUTPUT: «「S」»
if True {
say 'hit an x!' if $answer ~~ / x /;
say $/; # OUTPUT: «Nil»
}
say $/; # OUTPUT: «Nil»
```
The very same concept applies to named captures:
```raku
my $answer = 'a lot of Stuff';
if $answer ~~ / $<capital>=<[A..Z>]> / {
say 'Hit a capital letter';
say $/<capital>; # OUTPUT: «「S」»
}
say $/<capital>; # OUTPUT: «「S」»
say 'hit an x!' if $answer ~~ / $<x>=x /;
say $/<x>; # OUTPUT: «Nil»
say $/<capital>; # OUTPUT: «Nil»
```
# [Best practices and gotchas](#Regexes "go to top of document")[§](#Best_practices_and_gotchas "direct link")
The [Regexes: Best practices and gotchas](/language/regexes-best-practices) provides useful information on how to avoid common pitfalls when writing regexes and grammars.
|
## dist_zef-antononcube-Markup-Calendar.md
# Markup::Calendar
Raku package with Markup (HTML, Markdown) calendar functions for displaying monthly, yearly, and custom calendars.
### Motivation
The package
["Text::Calendar"](https://raku.land/zef:antononcube/Text::Calendar), [AAp1],
provides the core functions for making the calendars in this package.
The packages
["Data::Translators"](https://raku.land/zef:antononcube/Data::Translators), [AAp2], and
["Pretty::Table"](https://raku.land/cpan:ANTONOV/Pretty::Table), [ULp1],
provide additional formatting functionalities.
I want to keep "Text::Calendar" lightweight, without any dependencies. Hence I made this separate
package, "Markup::Calendar", that has more involved dependencies and use-cases.
An "involved use case" is calendar in which some of the days have tooltips and hyperlinks.
---
## Installation
From [Zef ecosystem](https://raku.land):
```
zef install Markup::Calendar
```
From GitHub:
```
zef install https://github.com/antononcube/Raku-Markup-Calendar.git
```
---
## Examples
### Basic HTML calendar
```
use Markup::Calendar;
use Text::Calendar;
calendar():html
```
| | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | |
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
| January 2024 | Mo | Tu | We | Th | Fr | Sa | Su | | --- | --- | --- | --- | --- | --- | --- | | 1 | 2 | 3 | 4 | 5 | 6 | 7 | | 8 | 9 | 10 | 11 | 12 | 13 | 14 | | 15 | 16 | 17 | 18 | 19 | 20 | 21 | | 22 | 23 | 24 | 25 | 26 | 27 | 28 | | 29 | 30 | 31 | | | | | | February 2024 | Mo | Tu | We | Th | Fr | Sa | Su | | --- | --- | --- | --- | --- | --- | --- | | | | | 1 | 2 | 3 | 4 | | 5 | 6 | 7 | 8 | 9 | 10 | 11 | | 12 | 13 | 14 | 15 | 16 | 17 | 18 | | 19 | 20 | 21 | 22 | 23 | 24 | 25 | | 26 | 27 | 28 | 29 | | | | | March 2024 | Mo | Tu | We | Th | Fr | Sa | Su | | --- | --- | --- | --- | --- | --- | --- | | | | | | 1 | 2 | 3 | | 4 | 5 | 6 | 7 | 8 | 9 | 10 | | 11 | 12 | 13 | 14 | 15 | 16 | 17 | | 18 | 19 | 20 | 21 | 22 | 23 | 24 | | 25 | 26 | 27 | 28 | 29 | 30 | 31 | |
### HTML yearly calendar with highlights
Here is an HTML calendar that weekend days are highlighted and with larger font:
```
calendar-year(
per-row => 4,
highlight => (Date.new(2024,1,1)...Date.new(2024,12,31)).grep({ $_.day-of-week ≥ 6 }),
highlight-style => 'color:orange; font-size:14pt'
):html
```
## 2024
| | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | |
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
| January | Mo | Tu | We | Th | Fr | Sa | Su | | --- | --- | --- | --- | --- | --- | --- | | 1 | 2 | 3 | 4 | 5 | 6 | 7 | | 8 | 9 | 10 | 11 | 12 | 13 | 14 | | 15 | 16 | 17 | 18 | 19 | 20 | 21 | | 22 | 23 | 24 | 25 | 26 | 27 | 28 | | 29 | 30 | 31 | | | | | | February | Mo | Tu | We | Th | Fr | Sa | Su | | --- | --- | --- | --- | --- | --- | --- | | | | | 1 | 2 | 3 | 4 | | 5 | 6 | 7 | 8 | 9 | 10 | 11 | | 12 | 13 | 14 | 15 | 16 | 17 | 18 | | 19 | 20 | 21 | 22 | 23 | 24 | 25 | | 26 | 27 | 28 | 29 | | | | | March | Mo | Tu | We | Th | Fr | Sa | Su | | --- | --- | --- | --- | --- | --- | --- | | | | | | 1 | 2 | 3 | | 4 | 5 | 6 | 7 | 8 | 9 | 10 | | 11 | 12 | 13 | 14 | 15 | 16 | 17 | | 18 | 19 | 20 | 21 | 22 | 23 | 24 | | 25 | 26 | 27 | 28 | 29 | 30 | 31 | | April | Mo | Tu | We | Th | Fr | Sa | Su | | --- | --- | --- | --- | --- | --- | --- | | 1 | 2 | 3 | 4 | 5 | 6 | 7 | | 8 | 9 | 10 | 11 | 12 | 13 | 14 | | 15 | 16 | 17 | 18 | 19 | 20 | 21 | | 22 | 23 | 24 | 25 | 26 | 27 | 28 | | 29 | 30 | | | | | | |
| May | Mo | Tu | We | Th | Fr | Sa | Su | | --- | --- | --- | --- | --- | --- | --- | | | | 1 | 2 | 3 | 4 | 5 | | 6 | 7 | 8 | 9 | 10 | 11 | 12 | | 13 | 14 | 15 | 16 | 17 | 18 | 19 | | 20 | 21 | 22 | 23 | 24 | 25 | 26 | | 27 | 28 | 29 | 30 | 31 | | | | June | Mo | Tu | We | Th | Fr | Sa | Su | | --- | --- | --- | --- | --- | --- | --- | | | | | | | 1 | 2 | | 3 | 4 | 5 | 6 | 7 | 8 | 9 | | 10 | 11 | 12 | 13 | 14 | 15 | 16 | | 17 | 18 | 19 | 20 | 21 | 22 | 23 | | 24 | 25 | 26 | 27 | 28 | 29 | 30 | | July | Mo | Tu | We | Th | Fr | Sa | Su | | --- | --- | --- | --- | --- | --- | --- | | 1 | 2 | 3 | 4 | 5 | 6 | 7 | | 8 | 9 | 10 | 11 | 12 | 13 | 14 | | 15 | 16 | 17 | 18 | 19 | 20 | 21 | | 22 | 23 | 24 | 25 | 26 | 27 | 28 | | 29 | 30 | 31 | | | | | | August | Mo | Tu | We | Th | Fr | Sa | Su | | --- | --- | --- | --- | --- | --- | --- | | | | | 1 | 2 | 3 | 4 | | 5 | 6 | 7 | 8 | 9 | 10 | 11 | | 12 | 13 | 14 | 15 | 16 | 17 | 18 | | 19 | 20 | 21 | 22 | 23 | 24 | 25 | | 26 | 27 | 28 | 29 | 30 | 31 | | |
| September | Mo | Tu | We | Th | Fr | Sa | Su | | --- | --- | --- | --- | --- | --- | --- | | | | | | | | 1 | | 2 | 3 | 4 | 5 | 6 | 7 | 8 | | 9 | 10 | 11 | 12 | 13 | 14 | 15 | | 16 | 17 | 18 | 19 | 20 | 21 | 22 | | 23 | 24 | 25 | 26 | 27 | 28 | 29 | | 30 | | | | | | | | October | Mo | Tu | We | Th | Fr | Sa | Su | | --- | --- | --- | --- | --- | --- | --- | | | 1 | 2 | 3 | 4 | 5 | 6 | | 7 | 8 | 9 | 10 | 11 | 12 | 13 | | 14 | 15 | 16 | 17 | 18 | 19 | 20 | | 21 | 22 | 23 | 24 | 25 | 26 | 27 | | 28 | 29 | 30 | 31 | | | | | November | Mo | Tu | We | Th | Fr | Sa | Su | | --- | --- | --- | --- | --- | --- | --- | | | | | | 1 | 2 | 3 | | 4 | 5 | 6 | 7 | 8 | 9 | 10 | | 11 | 12 | 13 | 14 | 15 | 16 | 17 | | 18 | 19 | 20 | 21 | 22 | 23 | 24 | | 25 | 26 | 27 | 28 | 29 | 30 | | | December | Mo | Tu | We | Th | Fr | Sa | Su | | --- | --- | --- | --- | --- | --- | --- | | | | | | | | 1 | | 2 | 3 | 4 | 5 | 6 | 7 | 8 | | 9 | 10 | 11 | 12 | 13 | 14 | 15 | | 16 | 17 | 18 | 19 | 20 | 21 | 22 | | 23 | 24 | 25 | 26 | 27 | 28 | 29 | | 30 | 31 | | | | | | |
### Standalone calendar file
Here we make a standalone calendar file:
```
spurt('example.html', calendar-year(year => 2024, highlight => [3=>3, 5=>24, 9=>9], highlight-style=>'color:red', format=>'html'))
```
```
# True
```
---
## TODO
* TODO Features
* DONE HTML
* DONE Full HTML calendar
* DONE Partial HTML calendar (e.g. equivalent of `cal -3`)
* DONE Highlighted days
* DONE Tooltips for days
* DONE Hyperlinks for days
* TODO Markdown
* TODO Full Markdown calendar
* TODO Partial Markdown calendar
* TODO Highlighted days
* TODO Tooltips for days
* TODO Hyperlinks for days
* Unit tests
* DONE Basic usage
* DONE Equivalence using different signatures
* TODO Correctness
* Documentation
* DONE Basic README
* TODO Diagrams
* TODO Comparisons
---
## References
[AAp1] Anton Antonov,
[Text::Calendar Raku package](https://github.com/antononcube/Raku-Text-Calendar),
(2024),
[GitHub/antononcube](https://github.com/antononcube).
[AAp2] Anton Antonov,
[Data::Translators Raku package](https://github.com/antononcube/Raku-Data-Translators),
(2023),
[GitHub/antononcube](https://github.com/antononcube).
[LUp1] Luis F. Uceta,
[Pretty::Table Raku package](https://gitlab.com/uzluisf/raku-pretty-table/),
(2020),
[GitLab/uzluisf](https://gitlab.com/uzluisf/).
|
## dist_zef-qorg11-Pleroma.md
[](https://github.com/dimethyltriptamine/pleroma-raku/actions)
|
## head.md
head
Combined from primary sources listed below.
# [In List](#___top "go to top of document")[§](#(List)_method_head "direct link")
See primary documentation
[in context](/type/List#method_head)
for **method head**.
```raku
multi method head(Any:D:) is raw
multi method head(Any:D: Callable:D $w)
multi method head(Any:D: $n)
```
This method is directly inherited from [`Any`](/type/Any), and it returns the **first** `$n` items of the list, an empty list if `$n` <= 0, or the first element with no argument. The version that takes a [`Callable`](/type/Callable) uses a [`WhateverCode`](/type/WhateverCode) to specify all elements, starting from the first, but the last ones.
Examples:
```raku
say <a b c d e>.head ; # OUTPUT: «a»
say <a b c d e>.head(2); # OUTPUT: «(a b)»
say <a b c d e>.head(*-3); # OUTPUT: «(a b)»
```
# [In Any](#___top "go to top of document")[§](#(Any)_routine_head "direct link")
See primary documentation
[in context](/type/Any#routine_head)
for **routine head**.
```raku
multi method head(Any:D:) is raw
multi method head(Any:D: Callable:D $w)
multi method head(Any:D: $n)
```
Returns either the first element in the object, or the first `$n` if that's used.
```raku
"aaabbc".comb.head.put; # OUTPUT: «a»
say ^10 .head(5); # OUTPUT: «(0 1 2 3 4)»
say ^∞ .head(5); # OUTPUT: «(0 1 2 3 4)»
say ^10 .head; # OUTPUT: «0»
say ^∞ .head; # OUTPUT: «0»
```
In the first two cases, the results are different since there's no defined order in [`Mix`](/type/Mix)es. In the other cases, it returns a [`Seq`](/type/Seq). A [`Callable`](/type/Callable) can be used to return all but the last elements:
```raku
say (^10).head( * - 3 );# OUTPUT: «(0 1 2 3 4 5 6)»
```
As of release 2022.07 of the Rakudo compiler, there is also a "sub" version of `head`.
```raku
multi head(\specifier, +values)
```
It **must** have the head specifier as the first argument. The rest of the arguments are turned into a [`Seq`](/type/Seq) and then have the `head` method called on it.
# [In Supply](#___top "go to top of document")[§](#(Supply)_method_head "direct link")
See primary documentation
[in context](/type/Supply#method_head)
for **method head**.
```raku
multi method head(Supply:D:)
multi method head(Supply:D: Callable:D $limit)
multi method head(Supply:D: \limit)
```
Creates a "head" supply with the same semantics as [List.head](/type/List#method_head).
```raku
my $s = Supply.from-list(4, 10, 3, 2);
my $hs = $s.head(2);
$hs.tap(&say); # OUTPUT: «410»
```
Since release 2020.07, A [`WhateverCode`](/type/WhateverCode) can be used also, again with the same semantics as `List.head`
```raku
my $s = Supply.from-list(4, 10, 3, 2, 1);
my $hs = $s.head( * - 2);
$hs.tap(&say); # OUTPUT: «4103»
```
|
## typeobject.md
class X::Does::TypeObject
Error due to mixing into a type object
```raku
class X::Does::TypeObject is Exception {}
```
When you try to add one or more roles to a type object with `does` after it has been composed, an error of type `X::Does::TypeObject` is thrown:
```raku
Mu does Numeric; # Cannot use 'does' operator with a type object.
```
The correct way to apply roles to a type is at declaration time:
```raku
class GrassmannNumber does Numeric { ... };
role AlgebraDebugger does IO { ... };
grammar IntegralParser does AlgebraParser { ... };
```
Roles may only be runtime-mixed into defined object instances:
```raku
GrassmannNumber.new does AlgebraDebugger;
```
(This restriction may be worked around by using [augment or supersede](/language/variables#The_augment_declarator), or with dark Metamodel magics, but this will likely result in a significant performance penalty.)
# [Methods](#class_X::Does::TypeObject "go to top of document")[§](#Methods "direct link")
## [method type](#class_X::Does::TypeObject "go to top of document")[§](#method_type "direct link")
```raku
method type(X::Does::TypeObject:D: --> Mu:U)
```
Returns the type object into which the code tried to mix in a role.
|
## dist_zef-gugod-RSV.md
```
This is an implementation of RSV decoder + encodder.
For the details of RSV, see:: https://github.com/Stenway/RSV-Specification
```
|
## numeric.md
Numeric
Combined from primary sources listed below.
# [In List](#___top "go to top of document")[§](#(List)_method_Numeric "direct link")
See primary documentation
[in context](/type/List#method_Numeric)
for **method Numeric**.
```raku
method Numeric(List:D: --> Int:D)
```
Returns the number of elements in the list (same as `.elems`).
```raku
say (1,2,3,4,5).Numeric; # OUTPUT: «5»
```
# [In role Sequence](#___top "go to top of document")[§](#(role_Sequence)_method_Numeric "direct link")
See primary documentation
[in context](/type/Sequence#method_Numeric)
for **method Numeric**.
```raku
method Numeric(::?CLASS:D:)
```
Returns the number of elements in the [cached](/type/PositionalBindFailover#method_cache) sequence.
# [In Capture](#___top "go to top of document")[§](#(Capture)_method_Numeric "direct link")
See primary documentation
[in context](/type/Capture#method_Numeric)
for **method Numeric**.
```raku
method Numeric(Capture:D: --> Int:D)
```
Returns the number of positional elements in the `Capture`.
```raku
say \(1,2,3, apples => 2).Numeric; # OUTPUT: «3»
```
# [In enum Bool](#___top "go to top of document")[§](#(enum_Bool)_routine_Numeric "direct link")
See primary documentation
[in context](/type/Bool#routine_Numeric)
for **routine Numeric**.
```raku
multi method Numeric(Bool:D --> Int:D)
```
Returns the value part of the `enum` pair.
```raku
say False.Numeric; # OUTPUT: «0»
say True.Numeric; # OUTPUT: «1»
```
# [In X::AdHoc](#___top "go to top of document")[§](#(X::AdHoc)_method_Numeric "direct link")
See primary documentation
[in context](/type/X/AdHoc#method_Numeric)
for **method Numeric**.
```raku
method Numeric()
```
Converts the payload to [`Numeric`](/type/Numeric) and returns it
# [In IntStr](#___top "go to top of document")[§](#(IntStr)_method_Numeric "direct link")
See primary documentation
[in context](/type/IntStr#method_Numeric)
for **method Numeric**.
```raku
multi method Numeric(IntStr:D: --> Int:D)
multi method Numeric(IntStr:U: --> Int:D)
```
The `:D` variant returns the numeric portion of the invocant. The `:U` variant issues a warning about using an uninitialized value in numeric context and then returns value `0`.
# [In Str](#___top "go to top of document")[§](#(Str)_method_Numeric "direct link")
See primary documentation
[in context](/type/Str#method_Numeric)
for **method Numeric**.
```raku
method Numeric(Str:D: --> Numeric:D)
```
Coerces the string to [`Numeric`](/type/Numeric) using semantics equivalent to [val](/routine/val) routine. [Fails](/routine/fail) with [`X::Str::Numeric`](/type/X/Str/Numeric) if the coercion to a number cannot be done.
Only Unicode characters with property `Nd`, as well as leading and trailing whitespace are allowed, with the special case of the empty string being coerced to `0`. Synthetic codepoints (e.g. `"7\x[308]"`) are forbidden.
While `Nl` and `No` characters can be used as numeric literals in the language, their conversion via `Str.Numeric` will fail, by design; the same will happen with synthetic numerics (composed of numbers and diacritic marks). See [unival](/routine/unival) if you need to coerce such characters to [`Numeric`](/type/Numeric). +, - and the Unicode MINUS SIGN − are all allowed.
```raku
" −33".Numeric; # OUTPUT: «-33»
```
# [In role Enumeration](#___top "go to top of document")[§](#(role_Enumeration)_method_Numeric "direct link")
See primary documentation
[in context](/type/Enumeration#method_Numeric)
for **method Numeric**.
```raku
multi method Numeric(::?CLASS:D:)
```
Takes a value of an enum and returns it after coercion to [`Numeric`](/type/Numeric):
```raku
enum Numbers ( cool => '42', almost-pi => '3.14', sqrt-n-one => 'i' );
say cool.Numeric; # OUTPUT: «42»
say almost-pi.Numeric; # OUTPUT: «3.14»
say sqrt-n-one.Numeric; # OUTPUT: «0+1i»
```
Note that if the value cannot be coerced to [`Numeric`](/type/Numeric), an exception will be thrown.
# [In NumStr](#___top "go to top of document")[§](#(NumStr)_method_Numeric "direct link")
See primary documentation
[in context](/type/NumStr#method_Numeric)
for **method Numeric**.
```raku
multi method Numeric(NumStr:D: --> Num:D)
multi method Numeric(NumStr:U: --> Num:D)
```
The `:D` variant returns the numeric portion of the invocant. The `:U` variant issues a warning about using an uninitialized value in numeric context and then returns value `0e0`.
# [In StrDistance](#___top "go to top of document")[§](#(StrDistance)_method_Numeric "direct link")
See primary documentation
[in context](/type/StrDistance#method_Numeric)
for **method Numeric**.
Returns the distance as a number.
# [In Map](#___top "go to top of document")[§](#(Map)_method_Numeric "direct link")
See primary documentation
[in context](/type/Map#method_Numeric)
for **method Numeric**.
```raku
method Numeric(Map:D: --> Int:D)
```
Returns the number of pairs stored in the `Map` (same as `.elems`).
```raku
my $m = Map.new('a' => 2, 'b' => 17);
say $m.Numeric; # OUTPUT: «2»
```
# [In Nil](#___top "go to top of document")[§](#(Nil)_method_Numeric "direct link")
See primary documentation
[in context](/type/Nil#method_Numeric)
for **method Numeric**.
```raku
method Numeric()
```
Warns the user that they tried to numify a `Nil`.
# [In enum Endian](#___top "go to top of document")[§](#(enum_Endian)_routine_Numeric "direct link")
See primary documentation
[in context](/type/Endian#routine_Numeric)
for **routine Numeric**.
```raku
multi method Numeric(Endian:D --> Int:D)
```
Returns the value part of the `enum` pair.
```raku
say NativeEndian.Numeric; # OUTPUT: «0»
say LittleEndian.Numeric; # OUTPUT: «1»
say BigEndian.Numeric; # OUTPUT: «2»
```
Note that the actual numeric values are subject to change. So please use the named values instead.
# [In IO::Path](#___top "go to top of document")[§](#(IO::Path)_method_Numeric "direct link")
See primary documentation
[in context](/type/IO/Path#method_Numeric)
for **method Numeric**.
```raku
method Numeric(IO::Path:D: --> Numeric:D)
```
Coerces [`.basename`](/routine/basename) to [`Numeric`](/type/Numeric). [Fails](/routine/fail) with [`X::Str::Numeric`](/type/X/Str/Numeric) if base name is not numerical.
# [In Thread](#___top "go to top of document")[§](#(Thread)_method_Numeric "direct link")
See primary documentation
[in context](/type/Thread#method_Numeric)
for **method Numeric**.
```raku
method Numeric(Thread:D: --> Int:D)
```
Returns a numeric, unique thread identifier, i.e. the same as [id](#method_id).
# [In role Numeric](#___top "go to top of document")[§](#(role_Numeric)_method_Numeric "direct link")
See primary documentation
[in context](/type/Numeric#method_Numeric)
for **method Numeric**.
```raku
multi method Numeric(Numeric:D: --> Numeric:D)
multi method Numeric(Numeric:U: --> Numeric:D)
```
The `:D` variant simply returns the invocant. The `:U` variant issues a warning about using an uninitialized value in numeric context and then returns `self.new`.
# [In DateTime](#___top "go to top of document")[§](#(DateTime)_method_Numeric "direct link")
See primary documentation
[in context](/type/DateTime#method_Numeric)
for **method Numeric**.
```raku
multi method Numeric(DateTime:D: --> Instant:D)
```
Available as of the 2021.09 release of the Rakudo compiler.
Converts the invocant to [`Instant`](/type/Instant). The same value can be obtained with the [`Instant`](/type/Instant) method. This allows `DateTime` objects to be used directly in arithmetic operations.
# [In ComplexStr](#___top "go to top of document")[§](#(ComplexStr)_method_Numeric "direct link")
See primary documentation
[in context](/type/ComplexStr#method_Numeric)
for **method Numeric**.
```raku
multi method Numeric(ComplexStr:D: --> Complex:D)
multi method Numeric(ComplexStr:U: --> Complex:D)
```
The `:D` variant returns the numeric portion of the invocant. The `:U` variant issues a warning about using an uninitialized value in numeric context and then returns value `<0+0i>`.
# [In RatStr](#___top "go to top of document")[§](#(RatStr)_method_Numeric "direct link")
See primary documentation
[in context](/type/RatStr#method_Numeric)
for **method Numeric**.
```raku
multi method Numeric(RatStr:D: --> Rat:D)
multi method Numeric(RatStr:U: --> Rat:D)
```
The `:D` variant returns the numeric portion of the invocant. The `:U` variant issues a warning about using an uninitialized value in numeric context and then returns value `0.0`.
# [In Date](#___top "go to top of document")[§](#(Date)_method_Numeric "direct link")
See primary documentation
[in context](/type/Date#method_Numeric)
for **method Numeric**.
```raku
multi method Numeric(Date:D: --> Int:D)
```
Converts the invocant to [`Int`](/type/Int). The same value can be obtained with the `daycount` method. This allows `Date` objects to be used directly in arithmetic operations.
Available as of release 2023.02 of the Rakudo compiler.
|
## dist_zef-frithnanth-Math-Libgsl-Interpolation.md
[](https://github.com/frithnanth/raku-Math-Libgsl-Interpolation/actions)

# NAME
Math::Libgsl::Interpolation - An interface to libgsl, the Gnu Scientific Library - Interpolation
# SYNOPSIS
```
use Math::Libgsl::Constants;
use Math::Libgsl::Interpolation;
my constant \N = 4;
my Num @x = 0e0, .1e0, .27e0, .3e0;
my Num @y = .15e0, .7e0, -.1e0, .15e0;
my $s = Math::Libgsl::Interpolation::OneD.new(:type(CSPLINE_PERIODIC), :size(N), :spline).init(@x, @y);
for ^100 -> $i {
my Num $xi = (1 - $i / 100) * @x[0] + ($i / 100) * @x[N - 1];
my Num $yi = $s.eval: $xi;
printf "%g %g\n", $xi, $yi;
}
```
# DESCRIPTION
Math::Libgsl::Interpolation is an interface to the interpolation functions of libgsl, the Gnu Scientific Library. This module exports two classes:
* Math::Libgsl::Interpolation::OneD
* Math::Libgsl::Interpolation::TwoD
## Math::Libgsl::Interpolation::OneD
### new(Int $type!, Int $size!)
### new(Int :$type!, Int :$size!)
This **multi method** constructor requires two simple or named arguments, the type of interpolation and the size of the array of data points.
### init(Num() @xarray where ([<] @xarray), Num() @yarray --> Math::Libgsl::Interpolation::OneD)
This method initializes the interpolation internal data using the X and Y coordinate arrays. It must be called each time one wants to use the object to evaluate interpolation points on another data set. The X array has to be strictly ordered, with increasing x values. This method returns **self**, so it may be chained.
### min-size(--> UInt)
This method returns the minimum number of points required by the interpolation object.
### name(--> Str)
This method returns the name of the interpolation type.
### find(Num() @xarray, Num() $x --> UInt)
This method performs a lookup action on the data array **@xarray** and returns the index i such that @xarray[i] <= $x < @xarray[i+1].
### reset(--> Math::Libgsl::Interpolation::OneD)
This method reinitializes the internal data structure and deletes the cache. It should be used when switching to a new dataset. This method returns **self**, so it may be chained.
### eval(Num() $x where $!spline.interp.xmin ≤ \* ≤ $!spline.interp.xmax --> Num)
This method returns the interpolated value of y for a given point x, which is inside the range of the x data set.
### eval-deriv(Num() $x where $!spline.interp.xmin ≤ \* ≤ $!spline.interp.xmax --> Num)
This method returns the derivative of an interpolated function for a given point x, which is inside the range of the x data set.
### eval-deriv2(Num() $x where $!spline.interp.xmin ≤ \* ≤ $!spline.interp.xmax --> Num)
This method returns the second derivative of an interpolated function for a given point x, which is inside the range of the x data set.
### eval-integ(Num() $a where $!spline.interp.xmin ≤ \*, Num() $b where { $b ≤ $!spline.interp.xmax && $b ≥ $a } --> Num)
This method returns the numerical integral result of an interpolated function over the range [$a, $b], two points inside the x data set.
## Math::Libgsl::Interpolation::TwoD
### new(Int $type!, Int $xsize!, Int $ysize!)
### new(Int :$type!, Int :$xsize!, Int :$ysize!)
This **multi method** constructor requires three simple or named arguments, the type of interpolation and the size of the arrays of the x and y data points.
### init(Num() @xarray where ([<] @xarray), Num() @yarray where ([<] @yarray), Num() @zarray where \*.elems == @xarray.elems \* @yarray.elems --> Math::Libgsl::Interpolation::TwoD)
This method initializes the interpolation internal data using the X, Y, and Z coordinate arrays. It must be called each time one wants to use the object to evaluate interpolation points on another data set. The X and Y arrays have to be strictly ordered, with increasing values. The Z array, which represents a grid, must have a dimension of size xsize \* ysize. The position of grid point (x, y) is given by y \* xsize + x (see also the zidx method). This method returns **self**, so it may be chained.
### zidx(UInt $x, UInt $y --> UInt)
This method returns the index of the Z array element corresponding to grid coordinates (x, y).
### min-size(--> UInt)
This method returns the minimum number of points required by the interpolation object.
### name(--> Str)
This method returns the name of the interpolation type.
### eval(Num() $x where $!spline.interp.xmin ≤ \* ≤ $!spline.interp.xmax, Num() $y where $!spline.interp.ymin ≤ \* ≤ $!spline.interp.ymax --> Num)
This method returns the interpolated value of z for a given point (x, y), which is inside the range of the x and y data sets.
### extrap(Num() $x, Num() $y --> Num)
This method returns the interpolated value of z for a given point (x, y), with no bounds checking, so when the point (x, y) is outside the range, an extrapolation is performed.
### deriv-x(Num() $x where $!spline.interp.xmin ≤ \* ≤ $!spline.interp.xmax, Num() $y where $!spline.interp.ymin ≤ \* ≤ $!spline.interp.ymax --> Num)
This method returns the interpolated value of ∂z/∂x for a given point (x, y), which is inside the range of the x and y data sets.
### deriv-y(Num() $x where $!spline.interp.xmin ≤ \* ≤ $!spline.interp.xmax, Num() $y where $!spline.interp.ymin ≤ \* ≤ $!spline.interp.ymax --> Num)
This method returns the interpolated value of ∂z/∂y for a given point (x, y), which is inside the range of the x and y data sets.
### deriv-xx(Num() $x where $!spline.interp.xmin ≤ \* ≤ $!spline.interp.xmax, Num() $y where $!spline.interp.ymin ≤ \* ≤ $!spline.interp.ymax --> Num)
This method returns the interpolated value of ∂²z/∂²x for a given point (x, y), which is inside the range of the x and y data sets.
### deriv-yy(Num() $x where $!spline.interp.xmin ≤ \* ≤ $!spline.interp.xmax, Num() $y where $!spline.interp.ymin ≤ \* ≤ $!spline.interp.ymax --> Num)
This method returns the interpolated value of ∂²z/∂²y for a given point (x, y), which is inside the range of the x and y data sets.
### deriv-xy(Num() $x where $!spline.interp.xmin ≤ \* ≤ $!spline.interp.xmax, Num() $y where $!spline.interp.ymin ≤ \* ≤ $!spline.interp.ymax --> Num)
This method returns the interpolated value of ∂²z/∂x∂y for a given point (x, y), which is inside the range of the x and y data sets.
## Accessory subroutines
### bsearch(Num() @xarray, Num() $x, UInt $idx-lo = 0, UInt $idx-hi = @xarray.elems - 1 --> UInt)
This sub returns the index i of the array @xarray such that @xarray[i] <= $x < @xarray[i+1]. The index is searched for in the range [$idx-lo, $idx-hi].
### min-size(Int $type --> UInt)
### min-size1d(Int $type --> UInt)
### min-size2d(Int $type --> UInt)
These subs return the minimum number of points required by the interpolation object, without the need to create an object. min-size is an alias for min-size1d.
# C Library Documentation
For more details on libgsl see <https://www.gnu.org/software/gsl/>. The excellent C Library manual is available here <https://www.gnu.org/software/gsl/doc/html/index.html>, or here <https://www.gnu.org/software/gsl/doc/latex/gsl-ref.pdf> in PDF format.
# Prerequisites
This module requires the libgsl library to be installed. Please follow the instructions below based on your platform:
## Debian Linux and Ubuntu 20.04
```
sudo apt install libgsl23 libgsl-dev libgslcblas0
```
That command will install libgslcblas0 as well, since it's used by the GSL.
## Ubuntu 18.04
libgsl23 and libgslcblas0 have a missing symbol on Ubuntu 18.04. I solved the issue installing the Debian Buster version of those three libraries:
* <http://http.us.debian.org/debian/pool/main/g/gsl/libgslcblas0_2.5+dfsg-6_amd64.deb>
* <http://http.us.debian.org/debian/pool/main/g/gsl/libgsl23_2.5+dfsg-6_amd64.deb>
* <http://http.us.debian.org/debian/pool/main/g/gsl/libgsl-dev_2.5+dfsg-6_amd64.deb>
# Installation
To install it using zef (a module management tool):
```
$ zef install Math::Libgsl::Interpolation
```
# AUTHOR
Fernando Santagata [nando.santagata@gmail.com](mailto:nando.santagata@gmail.com)
# COPYRIGHT AND LICENSE
Copyright 2021 Fernando Santagata
This library is free software; you can redistribute it and/or modify it under the Artistic License 2.0.
|
## dist_cpan-MORITZ-JSON-Tiny.md
# Example
A simple Perl 6 module for serializing and deserializing JSON.
```
use JSON::Tiny;
say from-json('{ "a": 42 }').perl;
say to-json { a => [1, 2, 'b'] };
```
# Supported Standards
JSON::Tiny implements RFC7159, which is a superset of ECMA-404, in that it
permits any value as a top-level JSON string, not just arrays and objects.
# License
All files (unless noted otherwise) can be used, modified and redistributed
under the terms of the Artistic License Version 2. Examples (in the
documentation, in tests or distributed as separate files) can be considered
public domain.
# Installation and Tests
To install this module, please use zef from <https://github.com/ugexe/zef> and
type
```
zef install JSON::Tiny
```
or from a checkout of this source tree,
```
zef install .
```
You can run the test suite locally like this:
```
prove -e 'perl6 -Ilib' t/
```
|
## dist_zef-FCO-Functional-Stack.md
[](https://github.com/FCO/Functional-Stack/actions)
# NAME
Functional::Stack - Functional Stack
# SYNOPSIS
```
use Functional::Stack;
Functional::Stack.mutate: {
for ^10 -> $value { say .push: $value }
say .peek;
say .pop while .elems;
}
```
# DESCRIPTION
Functional::Stack is a implementation of a functional data structure stack. It's immutable and thread-safe.
It has a `mutate` method that topicalise the object and will always topicalise the new generated stack. And that's gives the impression of mutating and makes it easier to interact with those objects.
# AUTHOR
Fernando Corrêa de Oliveira [fco@cpan.org](mailto:fco@cpan.org)
# COPYRIGHT AND LICENSE
Copyright 2024 Fernando Corrêa de Oliveira
This library is free software; you can redistribute it and/or modify it under the Artistic License 2.0.
|
## dist_zef-jjmerelo-Dist-META.md
# Dist::META [Test-install distro](https://github.com/JJ/raku-dist-meta/actions/workflows/test.yaml)
The main intention of this module is to offer an uniform API for data that
might be spread over different keys in the
[`META6.json` file](https://docs.raku.org/language/modules#index-entry-META6.json-META6.json).
This initial version, however, will focus on getting dependencies right, in a
single array.
## Installing
The usual
```
zef install Dist::META
```
## Running
`Dist::META` subclasses [`META6`](https://github.com/jonathanstowe/META6); please check out that distribution for its common API. It adds a class
attribute, `.dependencies`. Over this META6.json
```
{
"name" : "JSON::Marshal",
"tags" : [ "object", "serialisation", "JSON" ],
"authors" : [ "Jonathan Stowe <jns+git@gellyfish.co.uk>" ],
"author" : "Jonathan Stowe <jns+git@gellyfish.co.uk>",
"auth" : "github:jonathanstowe",
"support" : {
"source" : "git://github.com/jonathanstowe/JSON-Marshal.git"
},
"source-url" : "git://github.com/jonathanstowe/JSON-Marshal.git",
"perl" : "6",
"build-depends" : [ ],
"provides" : {
"JSON::Marshal" : "lib/JSON/Marshal.pm"
},
"depends" : [ "JSON::Tiny" ],
"test-depends" : [
"Test"
],
"description" : "Simple serialisation of objects to JSON",
"version" : "0.0.1"
}
```
You can run this program
```
use Dist::META;
my $obj = Dist::META.new(file => $meta-path); # Use path to above file
say $obj.dependencies[0]; # Prints JSON::Tiny
say $obj.dependencies[0].DependencyType; # RUNTIMEDEP
say $obj.dependencies[1].DependencyType; # TESTDEP;
```
`.dependencies` is an array with all dependencies, "tagged" (using mix-ins
) with `RUNTIMEDEP`,`BUILDDEP` or `TESTDEP`, depending on where they have
been defined (independently of the META6.json key they have used).
## See also
[Test::META](https://github.com/jonathanstowe/Test-META/) tests that
specifications are correct. [`Pakku::Spec`](https://github.com/hythm7/Pakku-Spec), part of the Pakku package manager, also contains a parser for
`META6.json that is closer to the current spec.
## License
This module will be licensed under the Artistic 2.0 License.
|
## dist_zef-Altai-man-Config-Netrc.md
# NAME
Config::Netrc - module for parsing of Netrc configuration files.
# SYNOPSIS
```
use Config::Netrc;
say Config::Netrc::parse-file('my-example.netrc');
```
# DESCRIPTION
There are basically two main functions: parse and parse-file. First function takes a string of netrc-file content and returns to you a hash with some signature or Nil value if parser failed.
This hash contains of two arrays: `comments` and `entries`. In the section comments you will get all comment strings(without leading `#`) and in the entries section you get array of hashes with this structure:
```
machine => {value => val, comment => my-comment},
login => {value => val, comment => my-comment},
password => {value => val, comment => my-comment}
```
Of course, login or password lines are optional and comment entry for lines like following:
```
machine val # my-comment
```
is also optional.
You will be able to use this hash to determine state of user's Netrc file state.
# TODO
* Detection of user's config file at his `home` directory
# COPYRIGHT
This library is free software; you can redistribute it and/or modify it under the terms of the [Artistic License 2.0](http://www.perlfoundation.org/artistic_license_2_0)
|
## dist_zef-thundergnat-App-pixelpick.md
# NAME pixelpick
Get the color of any screen pixel in an X11 environment.
Simple command-line app to allow you to get the RGB color of ***any*** screen pixel in an X11 environment, even those controlled by another application.
### Install
```
zef install App::pixelpick
```
Needs to have the `import` utility available. Installed part of the `MagickWand` package. Most Linuxes have it already, if not, install `libmagickwand`. May want to install `libmagickwand-dev` as well, though it isn't strictly necessary for this app.
```
sudo apt-get install libmagickwand-dev
```
For Debian based distributions.
Uses the `X11::libxdo` module for mouse interaction so will only run in an X11 environment.
## Use
### Interactive:
```
pixelpick <--distance=Int> <--list=COLOR,LISTS>
```
If invoked with no positional parameters, runs in interactive mode. Will get the color of the pixel under the mouse pointer and show the RGB values in both decimal and hexadecimal formats and will display a small block colored to that value. Will also display colored blocks of "Named colors", along with their RGB values, that are "near" the selected color.
Will accept an Integer "distance" parameter at the command line to fine tune the cutoff for what is "near". (Defaults to 20. More than about 80 or so is not recommended. You'll get unusefully large numbers of matches.) Will always return at least one "nearest" color, no matter what the threshold is. The colors may not be exact, they are just the nearest found in the list.
Uses the XKCD CSS3 and X11 color name lists from the Color::Names module by default as its list of known colors.
See [XKCD color blocks](https://www.w3schools.com/colors/colors_xkcd.asp), [W3 CSS 3 standard web colors](https://www.w3schools.com/cssref/css_colors.asp), and [X11 color blocks](https://www.w3schools.com/colors/colors_x11.asp).
If different color lists are desired, pass in a comma joined list of names. Any of the lists supported by `Color::Names:api<2>` may be used.
```
X11 XKCD CSS3 X11-Grey NCS NBS Crayola Resene RAL-CL RAL-DSP FS595B FS595C
```
as of this writing. The (case-sensitive) names must be in one contiuous string joined by commas. E.G.
```
pixelpick --list=Crayola,XKCD
```
Updates moderately slowly as the mouse is moved. There is some delay just to slow down the busy loop of checking to see if the mouse has moved. Will not attempt to update if the mouse has not moved. Uses the `X11::xdo` module to capture mouse motion so will only work in an X11 environment.
Note that screen sub-pixel dithering may lead to some unexpected values being returned, especially around small text. The utility returns what the pixel color ***is***, not what it is perceived to be.
When in interactive mode, you need to send an abort signal to exit the utility. Control-C will reset your terminal to its previous settings and do a full clean-up. If you want to keep the color block and values around, do Control-Z instead. That will also reset the terminal, but will not clean up as much, effectively leaving the last values displayed.
### Non-interactive: (Get the color of the pixel at 100, 200)
```
pixelpick 100 200 (--distance=Int)
```
If invoked with X, Y coordinates, (--distance parameter optional) runs non-interactive. Gets the pixel color at that coordinate and exits immediately, doing the partial cleanup as you would get from Control-Z.
### Non-interactive, quiet: (Get the RGB values of the pixel at 100, 200)
```
pixelpick 100 200 q
```
Add a truthy value as a "quiet" parameter to not return the standard color parameters and block. Only returns the RGB values in base 10 separated by colons. EG. `RRR:GGG:BBB`
If you would prefer to receive hex values, use an 'h' as the quiet parameter. Returns the RGB values in hexadecimal, separated by colons; `RR:GG:BB`.
```
pixelpick 100 200 h
```
# Author
2019 thundergnat (Steve Schulze)
This package is free software and is provided "as is" without express or implied warranty. You can redistribute it and/or modify it under the same terms as Perl itself.
# License
Licensed under The Artistic 2.0; see LICENSE.
|
## c3mro.md
role Metamodel::C3MRO
Metaobject that supports the C3 method resolution order
```raku
role Metamodel::C3MRO { }
```
*Warning*: this role is part of the Rakudo implementation, and is not a part of the language specification.
[Metamodel](/language/mop) role for the [*C3* method resolution order (MRO)](https://en.wikipedia.org/wiki/C3_linearization). *Note*: this method, along with almost the whole metamodel, is part of the Rakudo implementation.
The *method resolution order* for a type is a flat list of types including the type itself, and (recursively) all super classes. It determines in which order the types will be visited for determining which method to call with a given name, or for finding the next method in a chain with [nextsame](/language/functions#sub_nextsame), [callsame](/language/functions#sub_callsame), [nextwith](/language/functions#sub_nextwith) or [callwith](/language/functions#sub_callwith).
```raku
class CommonAncestor { }; # implicitly inherits from Any
class Child1 is CommonAncestor { }
class Child2 is CommonAncestor { }
class GrandChild2 is Child2 { }
class Weird is Child1 is GrandChild2 { };
say Weird.^mro; # OUTPUT: «(Weird) (Child1) (GrandChild2) (Child2) (CommonAncestor) (Any) (Mu)»
```
C3 is the default resolution order for classes and grammars in Raku. Note that roles generally do not appear in the method resolution order (unless they are punned into a class, from which another type inherits), because methods are copied into classes at role application time.
# [Methods](#role_Metamodel::C3MRO "go to top of document")[§](#Methods "direct link")
## [method compute\_mro](#role_Metamodel::C3MRO "go to top of document")[§](#method_compute_mro "direct link")
```raku
method compute_mro($type)
```
Computes the method resolution order.
## [method mro](#role_Metamodel::C3MRO "go to top of document")[§](#method_mro "direct link")
```raku
method mro($type)
```
Returns a list of types in the method resolution order, even those that are marked `is hidden`.
```raku
say Int.^mro; # OUTPUT: «((Int) (Cool) (Any) (Mu))»
```
## [method mro\_unhidden](#role_Metamodel::C3MRO "go to top of document")[§](#method_mro_unhidden "direct link")
```raku
method mro_unhidden($type)
```
Returns a list of types in method resolution order, excluding those that are marked with `is hidden`.
|
## sub.md
sub
Combined from primary sources listed below.
# [In Functions](#___top "go to top of document")[§](#(Functions)_sub_sub "direct link")
See primary documentation
[in context](/language/functions#Subroutines)
for **Subroutines**.
The basic way to create a subroutine is to use the `sub` declarator followed by an optional [identifier](/language/syntax#Identifiers):
```raku
sub my-func { say "Look ma, no args!" }
my-func;
```
The sub declarator returns a value of type [`Sub`](/type/Sub) that can be stored in any container:
```raku
my &c = sub { say "Look ma, no name!" }
c; # OUTPUT: «Look ma, no name!»
my Any:D $f = sub { say 'Still nameless...' }
$f(); # OUTPUT: «Still nameless...»
my Code \a = sub { say ‚raw containers don't implement postcircumfix:<( )>‘ };
a.(); # OUTPUT: «raw containers don't implement postcircumfix:<( )>»
```
The declarator `sub` will declare a new name in the current scope at compile time. As such, any indirection has to be resolved at compile time:
```raku
constant aname = 'foo';
sub ::(aname) { say 'oi‽' };
foo;
```
This will become more useful once macros are added to Raku.
To have the subroutine take arguments, a [`Signature`](/type/Signature) goes between the subroutine's name and its body, in parentheses:
```raku
sub exclaim ($phrase) {
say $phrase ~ "!!!!"
}
exclaim "Howdy, World";
```
By default, subroutines are [lexically scoped](/syntax/my). That is, `sub foo {...}` is the same as `my sub foo {...}` and is only defined within the current scope.
```raku
sub escape($str) {
# Puts a slash before non-alphanumeric characters
S:g[<-alpha -digit>] = "\\$/" given $str
}
say escape 'foo#bar?'; # OUTPUT: «foo\#bar\?»
{
sub escape($str) {
# Writes each non-alphanumeric character in its hexadecimal escape
S:g[<-alpha -digit>] = "\\x[{ $/.ord.base(16) }]" given $str
}
say escape 'foo#bar?' # OUTPUT: «foo\x[23]bar\x[3F]»
}
# Back to original escape function
say escape 'foo#bar?'; # OUTPUT: «foo\#bar\?»
```
Subroutines don't have to be named. If unnamed, they're called *anonymous* subroutines.
```raku
say sub ($a, $b) { $a ** 2 + $b ** 2 }(3, 4) # OUTPUT: «25»
```
But in this case, it's often desirable to use the more succinct [`Block`](/type/Block) syntax. Subroutines and blocks can be called in place, as in the example above.
```raku
say -> $a, $b { $a ** 2 + $b ** 2 }(3, 4) # OUTPUT: «25»
```
Or even
```raku
say { $^a ** 2 + $^b ** 2 }(3, 4) # OUTPUT: «25»
```
|
## is-dynamic.md
is dynamic
Combined from primary sources listed below.
# [In Variable](#___top "go to top of document")[§](#(Variable)_trait_is_dynamic "direct link")
See primary documentation
[in context](/type/Variable#trait_is_dynamic)
for **trait is dynamic**.
```raku
multi trait_mod:<is>(Variable:D, :$dynamic)
```
Marks a variable as dynamic, that is, accessible from inner dynamic scopes without being in an inner lexical scope.
```raku
sub introspect() {
say $CALLER::x;
}
my $x is dynamic = 23;
introspect; # OUTPUT: «23»
{
# not dynamic
my $x;
introspect() # dies with an exception of X::Caller::NotDynamic
}
```
The `is dynamic` trait is a rather cumbersome way of creating and accessing dynamic variables. A much easier way is to use the `* twigil`:
```raku
sub introspect() {
say $*x;
}
my $*x = 23;
introspect; # OUTPUT: «23»
{
# not dynamic
my $x;
introspect() # dies with an exception of X::Dynamic::NotFound
}
```
|
## dist_zef-lizmat-Needle-Compile.md
[](https://github.com/lizmat/Needle-Compile/actions) [](https://github.com/lizmat/Needle-Compile/actions) [](https://github.com/lizmat/Needle-Compile/actions)
# NAME
Needle::Compile - compile a search needle specification
# SYNOPSIS
```
use Needle::Compile;
my &basic = compile-needle("bar");
say basic("foo bar baz"); # True
say basic("Huey, Dewey, and Louie"); # False
my &capitals-ok = compile-needle("bar", :ignorecase);
say capitals-ok("foo bar baz"); # True
say capitals-ok("FOO BAR BAZ"); # True
say capitals-ok("Huey, Dewey, and Louie"); # False
my ®ex-ok = compile-needle("regex" => '\w+');
say regex-ok("foo"); # True
say regex-ok(":;+"); # False
my ®ex-matches = compile-needle("regex" => '\w+', :matches);
say regex-matches(":foo:"); # (foo)
say regex-matches(":;+"); # False
```
# DESCRIPTION
Needle::Compile exports a subroutine "compile-needle" that takes a number of arguments that specify a search query needle, and returns a `Callable` that can be called with a given haystack to see if there is a match.
It can as such be used as the argument to the `rak` subroutine provided by the [`rak`](https://raku.land/zef:lizmat/rak) distribution.
# SEARCH QUERY SPECIFICATION
A query can consist of multiple needles of different types. A type of needle can be specified in 3 ways:
### implicitely
```
# accept haystack if "bar" as word is found
my &needle = compile-needle("§bar");
```
By using textual markers at the start and end of the given string needle (see: type is "auto").
### explicitely
```
# accept haystack if "bar" as word is found
my &needle = compile-needle("words" => "bar");
```
By specifying a needle as a `Pair`, with the key being a string describing the type.
### mixed in
```
use Needle::Compile "Type";
# accept haystack if "bar" as word is found
my &needle = compile-needle("bar" but Type("words"));
```
If the specified needle supports a `.type` method, then that method will be called to determine the type. This can be done with the `Type` role that is optionally exported.
If you specify `"Type"` in the `use` statement, a `Type` role will be exported that allows you to mixin a type with a given string. The `Type` role will only allow known types in its specification. If that is too restrictive for your application, you can define your own `Type` role. Which can be as simple as:
```
my role Type { $.type }
```
If you want to be able to dispatch on strings that have a `but Type` mixed in, you can also import the `StrType` class:
```
use Needle::Compile <Type StrType>;
say "foo" but Type<words> ~~ Str; # True
say "foo" but Type<words> ~~ StrType; # True
say "foo" ~~ StrType; # False
```
Furthermore, you can call the `.ACCEPTS` method on the `StrTtype` class to check whether a given type string is valid:
```
use Needle::Compile <Type StrType>;
say StrType.ACCEPTS("contains"); # True
say StrType.ACCEPTS("frobnicate"); # False
```
## Modifiers
Many types of matching support `ignorecase` and `ignoremark` semantics. These can be specified explicitely (with the `:ignorecase` and `:ignoremark` named arguments), or implicitely with the `:smartcase` and `:smartmark` named arguments.
The same types also support the <:match> named argument, to return the string that actually matched, rather than `True`.
### ignorecase
```
# accept haystack if "bar" is found, regardless of case
my &needle = compile-needle("bar", :ignorecase);
```
Allow characters to match even if they are of mixed case.
### smartcase
```
# accept haystack if "bar" is found, regardless of case
my &anycase = compile-needle("bar", :smartcase);
# accept haystack if "Bar" is found
my &exactcase = compile-needle("Bar", :smartcase);
```
If the needle is a string and does **not** contain any uppercase characters, then `ignorecase` semantics will be assumed.
### ignoremark
```
# accept haystack if "bar" is found, regardless of any accents
my &anycase = compile-needle("bar", :ignoremark);
```
Allow characters to match even if they have accents (or not).
### smartmark
```
# accept haystack if "bar" is found, regardless of any accents
my &anymark = compile-needle("bar", :smartmark);
# accept haystack if "bår" is found
my &exactmark = compile-needle("bår", :smartmark);
```
If the needle is a string and does **not** contain any characters with accents, then `ignoremark` semantics will be assumed.
### matches
```
my ®ex-matches = compile-needle("regex" => '\w+', :matches);
say regex-matches(":foo:"); # (foo)
say regex-matches(":;+"); # False
```
Return all the strings that matched as a `Slip`, rather than `True`. Will still return `False` if no matches were found.
## Types of matchers
### auto
This is the default type of matcher. It looks at the given string for a number of markers, and adjust the type of match and the string accordingly. The following markers are recognized:
#### starts with !
```
# accept haystack if "bar" is NOT found
my &needle = compile-needle('!bar');
```
This is a meta-marker. Assumes the string given (without the `!`) should be processed, and its result negated (see: type is "not").
#### starts with &
```
# accept haystack if "foo" and "bar" are found
my &needle = compile-needle('foo', '&bar');
```
This is a meta-marker. Marks the needle produced for the given string (without the `&`) as needing an `&&` infix with its predecessor be processed, rather than the default `||` infix (see: type is "and").
#### starts with §
```
# accept haystack if "bar" is found as a word
my &needle = compile-needle('§bar');
```
Assumes the string given (without the `§`) should match with word-boundary semantics applied (see: type is "words").
#### starts with \*
```
# accept haystack if alphabetically before "bar"
my &is-before = compile-needle('* before "bar"');
# return every haystack uppercased
my &uppercased = compile-needle('*.uc');
```
Assumes the given string is a valid `WhateverCode` specification and attempts to produce that specification accordingly (see: type is "code").
#### starts with ^
```
# accept haystack if it starts with "bar"
my &needle = compile-needle('^bar');
```
Assumes the string given (without the `^`) should match with `.starts-with` semantics applied (see: type is "starts-with").
#### starts with file:
```
# accept matching patterns in file "always"
my &needle = compile-needle('file:always');
```
Assumes the given string (without the `file:` prefix) is a valid path specification, pointing to a file containing the patterns to be used (see: type is "file").
#### starts with jp:
```
# return result of JSON::Path query "auth"
my &needle = compile-needle('jp:auth');
```
Assumes the given string (without the `jp:` prefix) is a valid [`JSON Path`](https://en.wikipedia.org/wiki/JSONPath) specification (see: type is "json-path").
#### starts with s:
```
# accept if string contains "foo" *and* "bar"
my &needle = compile-needle('s:foo &bar');
```
Splits the given string (without the `s:` prefix) on whitespace and interpretes the result as a list of needles (see: type is "split").
#### starts with url:
```
# accept if any of the needles at given URL matches
my &domain = compile-needle('url:raku.org/robots.txt'); # assumes https://
my &url = compile-needle('url:https://raku.org/robots.txt');
```
Interpretes the given string (without the `url:` prefix) as a URL from which to obtain the needles from (see: type is "url").
#### ends with $
```
# accept haystack if it ends with "bar"
my &needle = compile-needle('bar$');
```
Assumes the string given (without the `$`) should match with `.ends-with` semantics applied (see: type is "ends-with").
#### starts with ^ and ends with $
```
# accept haystack if it is equal to "bar"
my &needle = compile-needle('^bar$');
```
Assumes the string given (without the `^` and `$`) should match exactly (see: type is "equal").
#### starts with / and ends with /
```
# accept haystack if it matches "bar" as a regular expression
my &needle = compile-needle('/bar/');
```
Assumes the string given (without the `/`'s) is a regex and attempts to produce a `Regex` object and wraps that in a call to `.contains` (see: type is "regex").
#### starts with { and ends with }
```
# return the lowercased, whitespace trimmed haystack
my &needle = compile-needle('{.trim.lc}');
```
Assumes the string given (without the `{` and `}`) is an expression and attempts to produce the code (see: type is "code").
#### none of the above
```
# accept haystack if it contains "bar"
my &needle = compile-needle("bar");
```
Assumes the string given should match with `.contains` semantics applied (see: type is "contains").
### and
```
# accept haystack if "foo" and "bar" are found
my &needle = compile-needle('foo', "and" => 'bar');
```
This is a meta-marker. Marks the needle produced for the given string as needing an `&&` infix with its predecessor be processed, rather than the default `||` infix. Has no meaning on the first (or only) needle in a list of needles.
### code
```
# return uppercase version of the haystack
my &needle = compile-needle("code" => ".uc");
```
Assumes the string is an expression and attempts to produce that code, with the haystack being presented as the topic (`$_`).
To facilitate the use of libraries that wish to access that topic, it is also available as the `$*_` dynamic variable.
Furthermore, the "code" type also accepts two named arguments:
#### :repo
```
# look for modules in "lib" subdirectory as well
my &needle = compile-needle("code" => '.uc', :repo<lib>);
```
Specifies location(s) in which loadable modules should be searched. It is the equivalent of Raku's `-I` command line option, and the `use lib` pragma.
#### :module
```
# Load the "Test" module
my &needle = compile-needle("code" => 'is $_, 42', :module<Test>);
```
Specifies module(s) that should be loaded. It is the equivalent of Raku's `-M` command line option, and the `use` statement.
### contains
```
# accept haystack if it contains "bar"
my &needle = compile-needle("contains" => "bar");
```
Assumes the string is a needle in a call to `.contains`.
### ends-with
```
# accept haystack if it ends with "bar"
my &needle = compile-needle("ends-with" => "bar");
```
Assumes the string is a needle in a call to `.ends-with`.
### equal
```
# accept haystack if it is equal to "bar"
my &needle = compile-needle("equal" => "bar");
```
Assumes the string is a needle to compare with the haystack using infix `eq` semantics.
### file
```
# return result of matching patterns in file "always"
my &needle = compile-needle("file" => 'always');
```
Assumes the given string is a valid path specification, pointing to a file containing the patterns to be used.
The following types of lines will be ignored:
* empty lines
* lines consisting of whitespace only
* lines starting with "#"
Note that the filename `"-"` will be interpreted as "read from STDIN".
### json-path
```
# return result of JSON::Path query "auth"
my &needle = compile-needle("json-path" => 'auth');
```
Assumes the given string is a valid [`JSON Path`](https://en.wikipedia.org/wiki/JSONPath) specification.
Must have the [`JSON::Path`](https://raku.land/cpan:JNTHN/JSON::Path) module installed.
The generated `Callable` will expect an `Associative` haystack (aka, a ) to be passed, and will return a `Slip` with any results.
```
# return result of JSON::Path query "auth"
my &needle = compile-needle({ jp('auth').Slip });
```
Alternately, you can also the `jp()` function. This returns a specialized `JP` object. Note that simply specifying a call to the `jp` function is not enough: one must do something with it. In the above example calling `.Slip` will cause the actual querying to happen.
See "Doing JSON path queries in code needles" for more information.
### not
```
# accept haystack if "bar" is NOT found
my &needle = compile-needle("not" => "bar");
```
This is a meta-type: it inverts the result of the result of matching of the given needle (which can be anything otherwise acceptable).
### regex
```
# accept haystack if "bar" is found
my &needle = compile-needle("regex" => "bar");
```
Assumes the string is a regex specification to be used as a needle in a call to `.contains`.
### split
```
# accept if string contains "foo" *and* "bar"
my &needle = compile-needle("split" => 'foo &bar');
```
This is a meta-type: it splits the given string on whitespace and interpretes the result as a list of needles.
### starts-with
```
# accept haystack if it starts with "bar"
my &needle = compile-needle("starts-with" => "bar");
```
Assumes the string is a needle in a call to `.starts-with`.
### url
```
# accept if any of the needles at given URL matches
my &domain = compile-needle("url" => 'raku.org/robots.txt');
my &url = compile-needle("url" => 'http://example.com/patterns');
```
Interpretes the given string as a URL from which to obtain the needles from. Assumes `https://` if no protocol is specified.
Requires the `curl` program to be installed and runnable. All protocols supported by `curl` can be used in the URL specification.
### words
```
# accept haystack if "bar" is found as a word
my &needle = compile-needle("words" => "bar");
```
Assumes the string is a needle that will match if the needle is found with word boundaries on either side of the needle.
## Doing JSON path queries in code needles
```
# return result of JSON::Path query "auth"
my &needle = compile-needle("code" => 'jp("auth").Slip');
```
The initial call to the `jp` function will attempt to load the `JSON::Path` module, and fail if it cannot. If the load is successful, it will create an object of the (internal) `JP` class with the giveni pattern.
If the `JSON::Path` module was already loaded, it will either produce the `JP` object from a cache, or create a new `JP` object.
The object as such, does nothing. It needs to have a method called on it **within the scope of the code needle** to properly function.
If you're using the (implicit) `"json-path"` type for your needle, this is done automatically for you, by calling the `.Slip` method on it.
The following methods can be called on the `JP` object:
| method | selected |
| --- | --- |
| .value | The first selected value |
| .values | All selected values as a Seq |
| .paths | The paths of all selected values as a Seq |
| .paths-and-values | Interleaved selected paths and values |
| .words | All words in selected values as a Slip |
| .head | The first N selected values as a Slip |
| .tail | The last N selected values as a Slip |
| .skip | Skip N selected values, produce rest as a Slip |
| .Seq | All selected values as a Seq |
| .Bool | True if any values selected, else False |
| .List | All selected values as a List |
| .Slip | All selected values as a Slip |
| .gist | All selected values stringified as a gist |
| .Str | All selected values stringified |
```
# return first and third result of JSON::Path query "auth" as a Slip
my &needle = compile-needle({ jp('auth')[0,2] });
```
Furthermore, you can use postcircumfix `[ ]` on the `JP` object to select values from the result.
# HELPER SUBROUTINES
## implicit2explicit
```
use Needle::Compile "implicit2explicit";
dd implicit2explicit('foo'); # :contains("foo")
dd implicit2explicit('§bar'); # :words("bar")
dd implicit2explicit('!baz$'); # :not(:ends-with("baz"))
```
The `implicit2explicit` subroutine converts an implicit query specification into an explicit one (expressed as a `Pair` with the key as the type, and the value as the actual string for which to create a needle).
# THEORY OF OPERATION
This module uses the new `RakuAST` classes as much as possible to create an executable `Callable`. This means that until RakuAST supports the complete Raku Programming Language features, it **is** possible that some code will not actually produce a `Callable` needle.
There is not a lot of documentation about RakuAST yet, but there are some blog posts, e.g. [RakuAST for early adopters](https://dev.to/lizmat/rakuast-for-early-adopters-576n).
# AUTHOR
Elizabeth Mattijsen [liz@raku.rocks](mailto:liz@raku.rocks)
Source can be located at: <https://github.com/lizmat/Needle-Compile> . Comments and Pull Requests are welcome.
If you like this module, or what I’m doing more generally, committing to a [small sponsorship](https://github.com/sponsors/lizmat/) would mean a great deal to me!
# COPYRIGHT AND LICENSE
Copyright 2024 Elizabeth Mattijsen
This library is free software; you can redistribute it and/or modify it under the Artistic License 2.0.
|
## causeonlyvalidonbroken.md
class X::Promise::CauseOnlyValidOnBroken
Error due to asking why an unbroken promise has been broken.
```raku
class X::Promise::CauseOnlyValidOnBroken is Exception { }
```
This exception is thrown when code expects a Promise to be broken, and asks why it has been broken, but the Promise has in fact, not yet been broken.
# [Methods](#class_X::Promise::CauseOnlyValidOnBroken "go to top of document")[§](#Methods "direct link")
## [method promise](#class_X::Promise::CauseOnlyValidOnBroken "go to top of document")[§](#method_promise "direct link")
```raku
method promise()
```
Returns the Promise that was asked about.
## [method status](#class_X::Promise::CauseOnlyValidOnBroken "go to top of document")[§](#method_status "direct link")
```raku
method status()
```
Returns the status the Promise had at that time.
|
## dist_github-ugexe-Distribution-Common-Remote.md
## Distribution::Common::Remote
Create an installable Distribution from remote sources using the `Distribution::Common` interface
See [Distribution::Common](https://github.com/ugexe/Raku-Distribution--Common) for more information.
This is kept as a separate repo as it requires additional dependencies.
## Synopsis
```
BEGIN %*ENV<GITHUB_ACCESS_TOKEN> = "..."; # optional, but useful due to api rate limiting
use Distribution::Common::Remote::Github;
# Distribution::Common::Remote:auth<github:ugexe>
my $dist = Distribution::Common::Remote::Github.new(
user => "ugexe",
repo => "Raku-Distribution--Common--Remote",
branch => "main"
);
say $dist.meta;
say $dist.content('lib/Distribution/Common/Remote.rakumod').open.slurp-rest;
```
## Classes
### Distribution::Common::Remote::Github
Installable `Distribution` from a github repository
## Roles
### Distribution::IO::Remote::Github
Fetch a single raw file from a distribution's github to memory. When `CompUnitRepository::Installation::Install.install`
accesses such files they are written directly to their install location instead of first using an intermediate temporary
location
|
## dist_zef-lizmat-P5getprotobyname.md
[](https://github.com/lizmat/P5getprotobyname/actions)
# NAME
Raku port of Perl's getprotobyname() and associated built-ins
# SYNOPSIS
```
use P5getprotobyname;
# exports getprotobyname, getprotobyport, getprotoent, setprotoent, endprotoent
say getprotobynumber(0, :scalar); # "ip"
my @result_byname = getprotobyname("ip");
my @result_bynumber = getprotobynumber(@result_byname[2]);
```
# DESCRIPTION
This module tries to mimic the behaviour of Perl's `getprotobyname` and associated built-ins as closely as possible in the Raku Programing Language.
It exports by default:
```
endprotoent getprotobyname getprotobynumber getprotoent setprotoent
```
# ORIGINAL PERL 5 DOCUMENTATION
```
getprotobyname NAME
getprotobynumber NUMBER
getprotoent
setprotoent STAYOPEN
endprotoent
These routines are the same as their counterparts in the system C
library. In list context, the return values from the various get
routines are as follows:
# 0 1 2 3 4
( $name, $aliases, $proto ) = getproto*
In scalar context, you get the name, unless the function was a
lookup by name, in which case you get the other thing, whatever it
is. (If the entry doesn't exist you get the undefined value.)
The "getprotobynumber" function, even though it only takes one
argument, has the precedence of a list operator, so beware:
getprotobynumber $number eq 'icmp' # WRONG
getprotobynumber($number eq 'icmp') # actually means this
getprotobynumber($number) eq 'icmp' # better this way
```
# PORTING CAVEATS
This module depends on the availability of POSIX semantics. This is generally not available on Windows, so this module will probably not work on Windows.
# AUTHOR
Elizabeth Mattijsen [liz@raku.rocks](mailto:liz@raku.rocks)
If you like this module, or what I’m doing more generally, committing to a [small sponsorship](https://github.com/sponsors/lizmat/) would mean a great deal to me!
Source can be located at: <https://github.com/lizmat/P5getprotobyname> . Comments and Pull Requests are welcome.
# COPYRIGHT AND LICENSE
Copyright 2018, 2019, 2020, 2021, 2023 Elizabeth Mattijsen
Re-imagined from Perl as part of the CPAN Butterfly Plan.
This library is free software; you can redistribute it and/or modify it under the Artistic License 2.0.
|
## dist_cpan-ALOREN-Canoe.md
An simple thread-safe plug-in framework for Perl 6
# Description
Canoe is an simple plug-in framework for Perl 6. It is thread-safe and
process-safe. The configuration file is base on the JSON format.
# Reference
## Canoe
* e(--> Bool)
Return True if the configuration file is existed.
* create(--> Promise)
Create the configuration file with default configuration `{ "plugins": [ ]}`. The `Promise` will kept with True when the file
created successfully.
* load(--> Promise)
Return an `Promise` which will kept with all the plug-in.
* Supply(--> Supply)
Return an `Supply` which will emit every plug-in.
* register(Str $name, Bool $enable --> Promise)
Register the module `$name` to the current configuration file. The
`Promise` will kept with True if successfully.
* unregister(Str $name --> Promise)
Remove the module `$name` from the current configuration file. The
`Promise` will kept with True if successfully.
* enable(Str $name, --> Promise)
Enable the plug-in.
* disable(Str $name, --> Promise)
Disable the plug-in.
## PlugInfo
* has $.enable
Is True if the plug-in is enabled.
* has $.plugin;
The type object of current plug-in.
* has $.installed
Is True if perl6 can find the plug-in in the repository.
* has $.name;
The name of current plug-in.
* get-instance(\*%\_)
Create an instance of current plug-in.
# License
```
The MIT License (MIT)
```
# Author
```
araraloren
```
|
## dist_github-labster-File-Compare.md
# perl6-File-Compare
Compare files, byte-by-byte
Determines if two files are alike or if they differ.
Usage:
```
use File::Compare;
say files_are_equal("file1.txt", "file2.txt");
files_are_different("foo", "bar") ?? say "diff" !! say "same";
say "we match" if files_are_equal("x.png", "y.png",
chunk_size=> 4*1024*1024);
```
See the pod in Compare.pm for more details.
|
## lock.md
class Lock
A low-level, re-entrant, mutual exclusion lock
```raku
class Lock {}
```
A `Lock` is a low-level concurrency control construct. It provides mutual exclusion, meaning that only one thread may hold the lock at a time. Once the lock is unlocked, another thread may then lock it.
A `Lock` is typically used to protect access to one or more pieces of state. For example, in this program:
```raku
my $x = 0;
my $l = Lock.new;
await (^10).map: {
start {
$l.protect({ $x++ });
}
}
say $x; # OUTPUT: «10»
```
The `Lock` is used to protect operations on `$x`. An increment is not an atomic operation; without the lock, it would be possible for two threads to both read the number 5 and then both store back the number 6, thus losing an update. With the use of the `Lock`, only one thread may be running the increment at a time.
A `Lock` is re-entrant, meaning that a thread that holds the lock can lock it again without blocking. That thread must unlock the same number of times before the lock can be obtained by another thread (it works by keeping a recursion count).
It's important to understand that there is no direct connection between a `Lock` and any particular piece of data; it is up to the programmer to ensure that the `Lock` is held during all operations that involve the data in question. The `OO::Monitors` module, while not a complete solution to this problem, does provide a way to avoid dealing with the lock explicitly and encourage a more structured approach.
The `Lock` class is backed by operating-system provided constructs, and so a thread that is waiting to acquire a lock is, from the point of view of the operating system, blocked.
Code using high-level Raku concurrency constructs should avoid using `Lock`. Waiting to acquire a `Lock` blocks a real [`Thread`](/type/Thread), meaning that the thread pool (used by numerous higher-level Raku concurrency mechanisms) cannot use that thread in the meantime for anything else.
Any `await` performed while a `Lock` is held will behave in a blocking manner; the standard non-blocking behavior of `await` relies on the code following the `await` resuming on a different [`Thread`](/type/Thread) from the pool, which is incompatible with the requirement that a `Lock` be unlocked by the same thread that locked it. See [`Lock::Async`](/type/Lock/Async) for an alternative mechanism that does not have this shortcoming. Other than that, the main difference is that `Lock` mainly maps to operating system mechanisms, while [`Lock::Async`](/type/Lock/Async) uses Raku primitives to achieve similar effects. If you're doing low-level stuff (native bindings) and/or actually want to block real OS threads, use `Lock`. However, if you want a non-blocking mutual exclusion and don't need recursion and are running code on the Raku thread pool, use Lock::Async.
By their nature, `Lock`s are not composable, and it is possible to end up with hangs should circular dependencies on locks occur. Prefer to structure concurrent programs such that they communicate results rather than modify shared data structures, using mechanisms like [`Promise`](/type/Promise), [`Channel`](/type/Channel) and [`Supply`](/type/Supply).
# [Methods](#class_Lock "go to top of document")[§](#Methods "direct link")
## [method protect](#class_Lock "go to top of document")[§](#method_protect "direct link")
```raku
multi method protect(Lock:D: &code)
```
Obtains the lock, runs `&code`, and releases the lock afterwards. Care is taken to make sure the lock is released even if the code is left through an exception.
Note that the `Lock` itself needs to be created outside the portion of the code that gets threaded and it needs to protect. In the first example below, `Lock` is first created and assigned to `$lock`, which is then used *inside* the [`Promise`](/type/Promise)s to protect the sensitive code. In the second example, a mistake is made: the `Lock` is created right inside the [`Promise`](/type/Promise), so the code ends up with a bunch of separate locks, created in a bunch of threads, and thus they don't actually protect the code we want to protect.
```raku
# Right: $lock is instantiated outside the portion of the
# code that will get threaded and be in need of protection
my $lock = Lock.new;
await ^20 .map: {
start {
$lock.protect: {
print "Foo";
sleep rand;
say "Bar";
}
}
}
# !!! WRONG !!! Lock is created inside threaded area!
await ^20 .map: {
start {
Lock.new.protect: {
print "Foo"; sleep rand; say "Bar";
}
}
}
```
## [method lock](#class_Lock "go to top of document")[§](#method_lock "direct link")
```raku
method lock(Lock:D:)
```
Acquires the lock. If it is currently not available, waits for it.
```raku
my $l = Lock.new;
$l.lock;
```
Since a `Lock` is implemented using OS-provided facilities, a thread waiting for the lock will not be scheduled until the lock is available for it. Since `Lock` is re-entrant, if the current thread already holds the lock, calling `lock` will simply bump a recursion count.
While it's easy enough to use the `lock` method, it's more difficult to correctly use [`unlock`](/type/Lock#method_unlock). Instead, prefer to use the [`protect`](/type/Lock#method_protect) method instead, which takes care of making sure the `lock`/`unlock` calls always both occur.
## [method unlock](#class_Lock "go to top of document")[§](#method_unlock "direct link")
```raku
method unlock(Lock:D:)
```
Releases the lock.
```raku
my $l = Lock.new;
$l.lock;
$l.unlock;
```
It is important to make sure the `Lock` is always released, even if an exception is thrown. The safest way to ensure this is to use the [`protect`](/type/Lock#method_protect) method, instead of explicitly calling `lock` and `unlock`. Failing that, use a `LEAVE` phaser.
```raku
my $l = Lock.new;
{
$l.lock;
LEAVE $l.unlock;
}
```
## [method condition](#class_Lock "go to top of document")[§](#method_condition "direct link")
```raku
method condition(Lock:D: )
```
Returns a condition variable as a [`Lock::ConditionVariable`](/type/Lock/ConditionVariable) object. Check [this article](https://web.stanford.edu/~ouster/cgi-bin/cs140-spring14/lecture.php?topic=locks) or [the Wikipedia](https://en.wikipedia.org/wiki/Monitor_%28synchronization%29) for background on condition variables and how they relate to locks and mutexes.
```raku
my $l = Lock.new;
$l.condition;
```
You should use a condition over a lock when you want an interaction with it that is a bit more complex than simply acquiring or releasing the lock.
```raku
constant ITEMS = 100;
my $lock = Lock.new;
my $cond = $lock.condition;
my $todo = 0;
my $done = 0;
my @in = 1..ITEMS;
my @out = 0 xx ITEMS;
loop ( my $i = 0; $i < @in; $i++ ) {
my $in := @in[$i];
my $out := @out[$i];
Thread.start( {
my $partial = $in² +1;
if $partial.is-prime {
$out = $partial but "Prime";
} else {
$out = $partial;
}
$lock.protect( {
$done++;
$cond.signal if $done == $todo;
} );
} );
$todo++;
}
$lock.protect( {
$cond.wait({ $done == $todo } );
});
say @out.map: { $_.^roles > 2 ?? $_.Num ~ "*" !! $_ };
# OUTPUT: «2* 5* 10 17* 26 37* 50 65 82 101* … »
```
In this case, we use the condition variable `$cond` to wait until all numbers have been generated and checked and also to `.signal` to another thread to wake up when the particular thread is done.
# [Typegraph](# "go to top of document")[§](#typegraphrelations "direct link")
Type relations for `Lock`
raku-type-graph
Lock
Lock
Any
Any
Lock->Any
Mu
Mu
Any->Mu
[Expand chart above](/assets/typegraphs/Lock.svg)
|
## dist_cpan-JNTHN-OpenAPI-Model.md
# OpenAPI::Model [Build Status](https://travis-ci.org/croservices/openapi-model)
OpenAPI::Model - work with OpenAPI documents in terms of a set of Perl 6 objects.
# SYNOPSIS
```
# Just fully qualified names available (OpenAPI::Model::Operation)
use OpenAPI::Model;
# Or get short names for model objects imported (Operation)
use OpenAPI::Model :elements;
# Load an existing document from YAML (returns OpenAPI::Model::OpenAPI):
my $api = OpenAPI::Model.from-yaml($yaml-doc);
# Or from JSON:
my $api = OpenAPI::Model.from-json($json-doc);
# Dig into the document (automatically resolves references within the
# document):
for $api.paths.kv -> $path, $object {
say "At $path you can:";
for <get post put delete> -> $method {
with $object."$method"() {
say " - do a $method.uc() request";
}
}
}
# References to external schemas are also possible (we won't go trying
# to download anything for you, and expect an `OpenAPI::Model::OpenAPI`
# instance for each one). These are used to resolve external references.
my %external = 'http://some.organization/schema/foobar' =>
OpenAPI::Model.from-yaml(slurp('foobar.yaml'));
my $api = OpenAPI::Model.from-yaml($yaml-doc, :%external);
```
# DESCRIPTION
OpenAPI::Model is a library that provides Perl 6 object layers upon OpenAPI documents.
# AUTHOR
Alexander Kiryuhin [alexander.kiryuhin@gmail.com](mailto:alexander.kiryuhin@gmail.com)
# COPYRIGHT AND LICENSE
Copyright 2018 Edument Central Europe sro.
This library is free software; you can redistribute it and/or modify it under the Artistic License 2.0.
|
## dist_zef-martimm-Gnome-GdkPixbuf.md

# Gnome GdkPixbuf

# Description
## Documentation
* [🔗 Website, entry point for all documents and blogs](https://martimm.github.io/)
* [🔗 License document](https://www.perlfoundation.org/artistic_license_2_0)
* [🔗 Release notes of all the packages in `:api<2>`](https://github.com/MARTIMM/gnome-source-skim-tool/blob/main/CHANGES.md)
* [🔗 Issues of all the packages in `:api<2>`](https://github.com/MARTIMM/gnome-source-skim-tool/issues)
# Installation
Do not install this package on its own. Instead install `Gnome::Gtk4` newest api.
`zef install Gnome::Gtk4:api<2>`
# Author
Name: **Marcel Timmerman**
Github account name: **MARTIMM**
# Issues
There are always some problems! If you find one please help by filing an issue at [my github project](https://github.com/MARTIMM/gnome-source-skim-tool/issues).
# Attribution
* The inventors of Raku, formerly known as Perl 6, of course and the writers of the documentation which helped me out every time again and again.
* The builders of all the Gnome libraries and the documentation.
* Other helpful modules for their insight and use.
|
## dist_zef-lizmat-Random-Names.md
[](https://github.com/lizmat/Random-Names/actions) [](https://github.com/lizmat/Random-Names/actions) [](https://github.com/lizmat/Random-Names/actions)
# NAME
Random::Names - Create random names to be used as identifiers
# SYNOPSIS
```
use Random::Names;
# procedural interface
say docker-name; # e.g. epic-engelbart
say class-name; # e.g. Mendeleev
say identifier-name; # e.g. dhawan
my @dn = docker-name(10); # get array with 10 unique docker-names
my @cn = class-name(10); # get array with 10 unique class-names
my @in = identifier-name(10); # get array with 10 unique identifiers
# object interface
my $rn = Random::Names.new; # set up unique pool of names
say $rn.docker-name;
say $rn.class-name;
say $rn.identifier-name;
```
# DESCRIPTION
Sometimes you need some placeholder names for things that do not have a name yet. This module provides a way to create names for things that are both fun and interesting. The names from which it selects, are the surnames of individuals that are famous in the history of scientific exploration and engineering.
It offers 3 types of random names:
* docker-name
Similar to how Docker names unnamed containers.
* class-name
Title-cased names used for classes in Raku.
* identifier-name
Just a random name that can be used as an identifier.
This module also installs a `rn` script that allows you to generate one or more names, accepting a named argument `--docker` for docker names, `--class` for class names, or just identifiers if not specified. Also optionally takes a named argument `--verbose` to also show the `WHY` and `LINK` information.
# ADDITIONAL INFORMATION
Each string that is being returned by this module, also has a `.WHY` method attached to it that will give additional information about the person to which the name is attached. E.g.;
```
my $name = identifier-name;
say $name; # einstein
my $why = $name.WHY;
say $why; # Albert Einstein invented the general theory of relativity.
```
And that string has a `.LINK` method that produces a link to a page that will show you more information about that person:
```
say $why.LINK; # https://en.wikipedia.org/wiki/Albert_Einstein
```
# FUNCTIONS
## docker-name
Return a random string similar to how Docker names unnamed containers, such as: `interesting-mendeleev`, `epic-engelbart`, `lucid-dhawan`, `recursing-cori`, `ecstatic-liskov` and `busy-ardinghelli`. These are made from a random selection of an adjective and a surname.
Optionally takes the number of docker-names to be returned.
```
say docker-name; # e.g. epic-engelbart
.say for docker-name(5); # 5 different docker names
```
## class-name
Return a random string that can be used as a name of a class, such as *Mendeleev*.
Optionally takes the number of class names to be returned.
```
say class-name; # e.g. Engelbart
.say for class-name(5); # 5 different class names
```
## identifier-name
Return a random string that can be used as an identifier, such as *dhawan*.
Optionally takes the number of identifiers to be returned.
```
say identifier-name; # e.g. cori
.say for identifier-name(5); # 5 different identifiers
```
# METHODS
The method interface has two different modes of operation. When called as a class method, the semantics are exactly the same as the functional interface.
When called on a `Random::Names` instance, it will only produce each adjective and each surname **only once**. This means that any mix of calls to `docker-name`, `class-name` or `identifier-name`, the returned strings will always be unique.
## new
```
my $rn = Random::Names.new:
adjectives => <pretty awful>, # default: standard set of adjectives
surnames => <mattijsen kasik>, # default: standard set of surnames
;
```
## docker-name
Return a random string similar to how Docker names unnamed containers. These are made from a random selection of an adjective and a surname.
Optionally takes the number of docker-names to be returned.
```
my $rn = Random::Names.new;
say $rn.docker-name; # e.g. epic-engelbart
.say for $rn.docker-name(5); # 5 different docker names
```
## class-name
Return a random string that can be used as a name of a class, such as *Mendeleev*.
Optionally takes the number of class names to be returned.
```
my $rn = Random::Names.new;
say $rn.class-name; # e.g. Engelbart
.say for $rn.class-name(5); # 5 different class names
```
## identifier-name
Return a random string that can be used as an identifier, such as *dhawan*.
Optionally takes the number of identifiers to be returned.
```
my $rn = Random::Names.new;
say $rn.identifier-name; # e.g. cori
.say for $rn.identifier-name(5); # 5 different identifiers
```
## adjectives
```
.say for Random::Names.new.adjectives;
```
Return an array of possible adjectives, alphabetically sorted.
## surnames
```
.say for Random::Names.new.surnames;
```
Return an array of possible surnames, alphabetically sorted.
# AUTHOR
Elizabeth Mattijsen [liz@raku.rocks](mailto:liz@raku.rocks), inspired by the Perl module `Data::Docker::Names` by Mikko Johannes Koivunalho [mikko.koivunalho@iki.fi](mailto:mikko.koivunalho@iki.fi).
Source can be located at: <https://github.com/lizmat/Random-Names> . Comments and Pull Requests are welcome.
If you like this module, or what I’m doing more generally, committing to a [small sponsorship](https://github.com/sponsors/lizmat/) would mean a great deal to me!
# COPYRIGHT AND LICENSE
Copyright 2020, 2021, 2022, 2025 Elizabeth Mattijsen
This library is free software; you can redistribute it and/or modify it under the Artistic License 2.0.
|
## dist_zef-dwarring-CSS-Grammar.md
[[Raku CSS Project]](https://css-raku.github.io)
/ [[CSS-Grammar Module]](https://css-raku.github.io/CSS-Grammar-raku)
# CSS-Grammar-raku
CSS::Grammar is a set of Raku grammars for the W3C family of CSS standards.
It aims to implement a reasonable portion of the base grammars with an
emphasis on:
* support for CSS1, CSS2.1 and CSS3
* forward compatibility rules, scanning and error recovery
This module performs generic parsing of declarations in style-sheet rules.
# Contents
## Base Grammars
* `CSS::Grammar::CSS1` - CSS 1.0 compatible grammar
* `CSS::Grammar::CSS21` - CSS 2.1 compatible grammar
* `CSS::Grammar::CSS3` - CSS 3.0 (core) compatible grammar
The CSS 3.0 core grammar, `CSS::Grammar::CSS3`, is based on CSS2.1; it understands:
* `#hex` and `rgb(...)` colors; but not `rgba(..)`, `hsl(...)`, `hsla(...)` or named colors
* basic `@media` at-rules; but not advanced media queries, resolutions or embedded `@page` rules.
* basic `@page` page description rules
* basic css3 level selectors
## Parser Actions
`CSS::Grammar::Actions` can be used with in conjunction with any of the CSS1
CSS21 or CSS3 base grammars. It produces an abstract syntax tree (AST), plus
warnings for any unexpected input.
```
use v6;
use CSS::Grammar::CSS3;
use CSS::Grammar::Actions;
my $css = 'H1 { color: blue; gunk }';
my $actions = CSS::Grammar::Actions.new;
my $p = CSS::Grammar::CSS3.parse($css, :actions($actions));
.note for $actions.warnings;
say "H1: " ~ $p.ast<stylesheet>[0]<ruleset><selectors>;
# output:
# dropping term: gunk
# H1: selector simple-selector qname element-name h1
```
## Actions Options
* **`:lax`** Pass back, don't drop, quantities with unknown dimensions.
## Installation
You can use the Raku `zef` module installer to test and install `CSS::Grammar`:
```
% zef install CSS::Grammar
```
To try parsing some content:
```
% raku -MCSS::Grammar::CSS3 -e"say CSS::Grammar::CSS3.parse('H1 {color:blue}')"
```
## See Also
* [CSS::Properties](https://css-raku.github.io/CSS-Properties-raku) CSS Propery-list manipulation library.
* [CSS](https://css-raku.github.io/CSS-raku) CSS Stylesheets and processing.
* [CSS::Module::CSS3::Selectors](https://css-raku.github.io/CSS-Module-CSS3-Selectors-raku) extends CSS::Grammar::CSS3 to fully implement CSS Level 3 Selectors.
* [CSS::Module](https://css-raku.github.io/CSS-Module-raku) further extends CSS::Grammar levels 1, 2.1 and 3. It understands named colors and is able to perform property-specific parsing and validation.
* [CSS::Writer](https://css-raku.github.io/CSS-Writer-raku) - AST reserializer
* [CSSGrammar.pm](https://github.com/Raku/examples/blob/master/categories/parsers/CSSGrammar.pm) from [Raku/examples](https://github.com/Raku/examples) gives an introductory Raku grammar for CSS 2.1.
## References
This module been built from the W3C CSS Specifications. In particular:
* CSS 1.0 Grammar - <http://www.w3.org/TR/2008/REC-CSS1-20080411/#appendix-b>
* CSS 2.1 Grammar - <http://www.w3.org/TR/CSS21/grammar.html>
* CSS3 module: Syntax - <http://www.w3.org/TR/2014/CR-css-syntax-3-20140220/>
* CSS Style Attributes - <http://www.w3.org/TR/2010/CR-css-style-attr-20101012/#syntax>
|
## dist_cpan-TIMOTIMO-JSON-Fast.md
[](https://travis-ci.org/timo/json_fast)
# JSON::Fast
A naive imperative JSON parser in pure Raku (but with direct access to `nqp::` ops), to evaluate performance against `JSON::Tiny`. It is a drop-in replacement for `JSON::Tiny`’s from-json and to-json subs, but it offers a few extra features.
Currently it seems to be about 4x faster and uses up about a quarter of the RAM JSON::Tiny would use.
This module also includes a very fast to-json function that tony-o created and lizmat later completely refactored.
## Exported subroutines
### to-json
```
my $*JSON_NAN_INF_SUPPORT = 1; # allow NaN, Inf, and -Inf to be serialized.
say to-json [<my Raku data structure>];
say to-json [<my Raku data structure>], :!pretty;
say to-json [<my Raku data structure>], :spacing(4);
enum Blerp <Hello Goodbye>;
say to-json [Hello, Goodbye]; # ["Hello", "Goodbye"]
say to-json [Hello, Goodbye], :enums-as-value; # [0, 1]
```
Encode a Raku data structure into JSON. Takes one positional argument, which is a thing you want to encode into JSON. Takes these optional named arguments:
#### pretty
`Bool`. Defaults to `True`. Specifies whether the output should be "pretty", human-readable JSON. When set to false, will output json in a single line.
#### spacing
`Int`. Defaults to `2`. Applies only when `pretty` is `True`. Controls how much spacing there is between each nested level of the output.
#### sorted-keys
Specifies whether keys from objects should be sorted before serializing them to a string or if `$obj.keys` is good enough. Defaults to `False`. Can also be specified as a `Callable` with the same type of argument that the `.sort` method accepts to provide alternate sorting methods.
#### enum-as-value
`Bool`, defaults to `False`. Specifies whether `enum`s should be json-ified as their underlying values, instead of as the name of the `enum`.
### from-json
```
my $x = from-json '["foo", "bar", {"ber": "bor"}]';
say $x.perl;
# outputs: $["foo", "bar", {:ber("bor")}]
```
Takes one positional argument that is coerced into a `Str` type and represents a JSON text to decode. Returns a Raku datastructure representing that JSON.
#### immutable
`Bool`. Defaults to `False`. Specifies whether `Hash`es and `Array`s should be rendered as immutable datastructures instead (as `Map` / `List`. Creating an immutable data structures is mostly saving on memory usage, and a little bit on CPU (typically around 5%).
This also has the side effect that elements from the returned structure can now be iterated over directly because they are not containerized.
#### allow-jsonc
`BOOL`. Defaults to `False`. Specifies whether commmands adhering to the [JSONC standard](https://changelog.com/news/jsonc-is-a-superset-of-json-which-supports-comments-6LwR) are allowed.
```
my %hash := from-json "META6.json".IO.slurp, :immutable;
say "Provides:";
.say for %hash<provides>;
```
## Additional features
### Adapting defaults of "from-json"
In the `use` statement, you can add the string `"immutable"` to make the default of the `immutable` parameter to the `from-json` subroutine `True`, rather than False.
```
use JSON::Fast <immutable>; # create immutable data structures by default
```
### Adapting defaults of "to-json"
In the `use` statement, you can add the strings `"!pretty"`, `"sorted-keys"` and/or `"enums-as-value"` to change the associated defaults of the `to-json` subroutine.
```
use JSON::FAST <!pretty sorted-keys enums-as-value>;
```
### Strings containing multiple json pieces
When the document contains additional non-whitespace after the first successfully parsed JSON object, JSON::Fast will throw the exception `X::JSON::AdditionalContent`. If you expect multiple objects, you can catch that exception, retrieve the parse result from its `parsed` attribute, and remove the first `rest-position` characters off of the string and restart parsing from there.
|
## bless.md
bless
Combined from primary sources listed below.
# [In Mu](#___top "go to top of document")[§](#(Mu)_method_bless "direct link")
See primary documentation
[in context](/type/Mu#method_bless)
for **method bless**.
```raku
method bless(*%attrinit --> Mu:D)
```
Low-level object construction method, usually called from within `new`, implicitly from the default constructor, or explicitly if you create your own constructor. `bless` creates a new object of the same type as the invocant, using the named arguments to initialize attributes and returns the created object.
It is usually invoked within custom `new` method implementations:
```raku
class Point {
has $.x;
has $.y;
multi method new($x, $y) {
self.bless(:$x, :$y);
}
}
my $p = Point.new(-1, 1);
```
In this example we are declaring this `new` method to avoid the extra syntax of using pairs when creating the object. `self.bless` returns the object, which is in turn returned by `new`. `new` is declared as a `multi method` so that we can still use the default constructor like this: `Point.new( x => 3, y => 8 )`.
For more details see [the documentation on object construction](/language/objects#Object_construction).
|
## dist_zef-thundergnat-Rat-Precise.md
[](https://github.com/thundergnat/Rat-Precise/actions)
# NAME
Rat::Precise
# SYNOPSIS
Stringify Rats to a configurable precision.
Provides a Rational method .precise. Pass in a positive integer to set places of precision. Pass in a boolean flag :z to preserve trailing zeros.
```
use Rat::Precise;
my $rat = 2213445/437231;
say $rat; # 5.0624155
say $rat.precise; # 5.0624155194851234
say $rat.FatRat.precise; # 5.06241551948512342445983930691099
say $rat.precise(37); # 5.06241551948512342445983930691099213
say $rat.precise(37, :z); # 5.0624155194851234244598393069109921300
say $rat.precise(0); # 5
# terminating Rats
say (1.5**63).Str; # 124093581919.64894769782737365038
say (1.5**63).precise; # 124093581919.648947697827373650380188008224280338254175148904323577880859375
```
# DESCRIPTION
The default Rat stringification routines are a fairly conservative tradeoff between speed and precision. This module shifts hard to the precision side at the expense of speed.
Augments Rat and FatRat classes with a .precise method. Stringifies configurably to a more precise representation than default .Str methods.
The .precise method can accept two parameters. A positive integer to specify the number of places of precision after the decimal, and/or a boolean flag to control whether non-significant zeros are trimmed.
In base 10, Rational fractions with denominators that are a power of 2 or 5 will terminate.
By default, the precise method stringifies terminating fractions completely. If the fraction is non-terminating, Rats return at least 16 places of precision, FatRats return at least 32 places. Any trailing zeros are trimmed.
If an integer parameter is passed, the fractional portion will be calculated to that many digits, but may have non-significant digits trimmed. The integer must be non negative. Negative integers will be ignored. It can be zero, and it will return zero fractional digits, but it would be much more efficient to just Int the Rat.
If a :z flag is passed, trailing (non-significant) zeros will be preserved.
Parameters can be in any order and combination.
Note that the .precise method only affects stringification. It doesn't change the internal representations of the Rationals, nor does it make calculations any more precise. It is merely a shortcut to express Rational strings to a configurable specified precision.
The :z flag is mostly intended to be used in combination with a digits parameter. It may be used on its own, but may return slightly non-intuitive results. In order to save unnecessary calculations (and speed up the overall process) the .precise method only checks for terminating fractions that are multiples of 2 & 5 less than 10. To avoid lots of pointless checks and general slowdown, any terminating fraction that is a multiple of 10 or above will be calculated out to the default precision (16 digits for Rats, 32 for FatRats or the number of characters in the denominator if that is greater) since it will terminate within that precision.
The point is, if you want to keep trailing zeros, you are better off specifying digits of precision also.
# AUTHOR
2018 Steve Schulze aka thundergnat
This package is free software and is provided "as is" without express or implied warranty. You can redistribute it and/or modify it under the same terms as Perl itself.
# LICENSE
Licensed under The Artistic 2.0; see LICENSE.
|
## dist_cpan-GARLANDG-Universal-errno.md
# NAME
Universal::errno - Wrapper for errno modules for Unix and Windows
# SYNOPSIS
```
use Universal::errno;
set_errno(2);
say errno;
say "failed: {errno}";
say +errno; #2
```
# DESCRIPTION
Universal::errno is an extension of and wrapper around lizmat's `Unix::errno`, and exports the same `errno` and `set_errno` interface. It works on Linux, Windows, and Macos. BSD support is untested, but should work.
One added feature is the `strerror` method, which gets the string for the error in a thread-safe way. On platforms that support it, it uses POSIX `strerror_l`. This allows getting the error string that corresponds to the user's set locale. On platforms that don't support it, strerror\_r (XSI) is used. On Windows, this is done using `GetLastError()` and `FormatMessageW`. Windows also has a `SetLastError` function which is used instead of masking the value.
This module provides an Exception class, X::errno. To check the type of error in a portable way, use the `symbol` method and smartmatch against an entry in the Errno enum.
It also provides a trait: error-model. Mark a sub or method with `is error-model<errno>` and the trait will automatically box the errno for you and reset errno to 0.
Important note: With a native sub, the `is native` trait must come before `is error-model`.
For calls that return `-errno`, there is also the trait `is error-model<neg-errno>`.
If high-performance is needed for a native sub that can return errno, use the `check-errno` and/or `check-neg-errno` subs. These subs are interchangeable with the traits, but cannot be directly applied to a nativecall subroutine.
As an example of a real-world scenario, this code sets up a socket using socket(2) and handles the errors with a CATCH block.
```
use NativeCall;
use Constants::Sys::Socket;
sub socket(int32, int32, int32) returns int32 is native is error-model<errno> { ... }
my int32 $socket;
try {
$socket = socket(AF::INET, SOCK_DGRAM, 0);
# Do something with $socket
CATCH {
when X::errno {
given .symbol {
when Errno::EINVAL {
die "Invalid socket type"
}
when Errno::EACCES {
die "Permission denied"
}
...
}
}
}
}
```
## class X::errno
Exception class for errno
### method message
```
method message() returns Mu
```
Get the Str message for this errno value.
### method symbol
```
method symbol() returns Mu
```
Get the symbol of this errno value.
### method Int
```
method Int() returns Mu
```
Get the integer that corresponds to this errno value.
# Subs
### sub check-neg-errno
```
sub check-neg-errno(
Int $result
) returns Mu
```
Check the result against the negative errno form.
### sub check-errno
```
sub check-errno(
Int $result
) returns Mu
```
Check the result against the errno() form.
# AUTHOR
Travis Gibson [TGib.Travis@protonmail.com](mailto:TGib.Travis@protonmail.com)
## CREDIT
Uses a heavily-modified `Unix::errno` module for Unix-like OSes, and uses `Windows::errno` (also based on lizmat's `Unix::errno`) for Windows OSes.
Universal::errno::Unix contains all of the modified code, and this README also borrows the SYNOPSIS example above. The original README and COPYRIGHT information for lizmat's `Unix::errno` has been preserved in `Universal::errno::Unix`.
lizmat's `Unix::errno` can be found at <https://github.com/lizmat/Unix-errno>
# COPYRIGHT AND LICENSE
Copyright 2020 Travis Gibson
This library is free software; you can redistribute it and/or modify it under the Artistic License 2.0.
|
## dist_zef-raku-community-modules-Git-Log.md
[](https://github.com/raku-community-modules/Git-Log/actions) [](https://github.com/raku-community-modules/Git-Log/actions) [](https://github.com/raku-community-modules/Git-Log/actions)
# NAME
Git::Log - Gets the git log as a Raku object
# SYNOPSIS
Gets the git log as a Raku object
# DESCRIPTION
The first argument is the command line args wanted to be passed into `git log`. Optionally you can also get the files changes as well as the number of lines added or deleted.
Returns an array of hashes in the following format: `ID => "df0c229ad6ba293c67724379bcd3d55af6ea47a0", AuthorName => "Author's Name", AuthorEmail => "sample.email@not-a.url" ...`
If the option :get-changes is used (off by default) it will also add a 'changes' key in the following format: `changes => { $[ { filename => 'myfile.txt', added => 10, deleted => 5 }, ... ] }`
If there is a field that you need that is not offered, then you can supply an array, :@fields. Format is an array of pairs: `ID => '%H', AuthorName => '%an' ...` you can look for more [here](https://git-scm.com/docs/pretty-formats).
These are the default fields:
```
my @fields-default =
ID => '%H',
AuthorName => '%an',
AuthorEmail => '%ae',
AuthorDate => '%aI',
Subject => '%s',
Body => '%b'
;
```
# EXAMPLES
```
# Gets the git log for the specified repository,
# from versions 2018.06 to main
git-log(:path($path.IO), '2018.06..main')
# Gets the git log for the current directory, and does I<not> get the files
# changed in that commit
git-log(:!get-changes)
```
### sub git-log
```
sub git-log(
*@args,
:@fields = Code.new,
IO::Path :$path,
Bool:D :$get-changes = Bool::False,
Bool:D :$date-time = Bool::False
) returns Mu
```
git-log's first argument is an array that is passed to C and optionally you can provide a path so a directory other than the current are used.
# AUTHOR
Samantha McVey
Source can be located at: <https://github.com/raku-community-modules/Git-Log> . Comments and Pull Requests are welcome.
# COPYRIGHT AND LICENSE
Copyright 2018 Samantha McVey
Copyright 2024 The Raku Community
This library is free software; you can redistribute it and/or modify it under the Artistic License 2.0.
|
## elems.md
elems
Combined from primary sources listed below.
# [In Uni](#___top "go to top of document")[§](#(Uni)_method_elems "direct link")
See primary documentation
[in context](/type/Uni#method_elems)
for **method elems**.
```raku
method elems(Uni:D: --> Int:D)
```
Returns the number of codepoints in the invocant.
# [In List](#___top "go to top of document")[§](#(List)_routine_elems "direct link")
See primary documentation
[in context](/type/List#routine_elems)
for **routine elems**.
```raku
sub elems($list --> Int:D)
method elems(List:D: --> Int:D)
```
Returns the number of elements in the list.
```raku
say (1,2,3,4).elems; # OUTPUT: «4»
```
# [In IterationBuffer](#___top "go to top of document")[§](#(IterationBuffer)_method_elems "direct link")
See primary documentation
[in context](/type/IterationBuffer#method_elems)
for **method elems**.
```raku
method elems(IterationBuffer:D: --> Int:D)
```
Returns the number of elements in the `IterationBuffer`.
# [In role Baggy](#___top "go to top of document")[§](#(role_Baggy)_method_elems "direct link")
See primary documentation
[in context](/type/Baggy#method_elems)
for **method elems**.
```raku
method elems(Baggy:D: --> Int:D)
```
Returns the number of elements in the `Baggy` object without taking the individual elements' weight into account.
```raku
my $breakfast = bag <eggs spam spam spam>;
say $breakfast.elems; # OUTPUT: «2»
my $n = ("b" => 9.4, "b" => 2).MixHash;
say $n.elems; # OUTPUT: «1»
```
# [In Capture](#___top "go to top of document")[§](#(Capture)_method_elems "direct link")
See primary documentation
[in context](/type/Capture#method_elems)
for **method elems**.
```raku
method elems(Capture:D: --> Int:D)
```
Returns the number of positional elements in the `Capture`.
```raku
my Capture $c = \(2, 3, 5, apples => (red => 2));
say $c.elems; # OUTPUT: «3»
```
# [In Seq](#___top "go to top of document")[§](#(Seq)_method_elems "direct link")
See primary documentation
[in context](/type/Seq#method_elems)
for **method elems**.
```raku
method elems(Seq:D:)
```
Returns the number of values in the sequence. If this number cannot be predicted, the `Seq` is cached and evaluated till the end.
Because an infinite sequence cannot be evaluated till the end, such a sequence *should* be declared lazy. Calling `.elems` on a lazy `Seq` [fail](/routine/fail)s with [`X::Cannot::Lazy`](/type/X/Cannot/Lazy).
# [In Range](#___top "go to top of document")[§](#(Range)_method_elems "direct link")
See primary documentation
[in context](/type/Range#method_elems)
for **method elems**.
```raku
method elems(Range:D: --> Numeric:D)
```
Returns the number of elements in the range, e.g. when being iterated over, or when used as a [`List`](/type/List). Returns 0 if the start point is larger than the end point, including when the start point was specified as `∞`. Fails when the Range is lazy, including when the end point was specified as `∞` or either end point was specified as `*`.
```raku
say (1..5).elems; # OUTPUT: «5»
say (1^..^5).elems; # OUTPUT: «3»
```
# [In Map](#___top "go to top of document")[§](#(Map)_method_elems "direct link")
See primary documentation
[in context](/type/Map#method_elems)
for **method elems**.
```raku
method elems(Map:D: --> Int:D)
```
Returns the number of pairs stored in the Map.
```raku
my %map = Map.new('a', 1, 'b', 2);
say %map.elems; # OUTPUT: «2»
```
# [In Subscripts](#___top "go to top of document")[§](#(Subscripts)_method_elems "direct link")
See primary documentation
[in context](/language/subscripts#method_elems)
for **method elems**.
```raku
multi method elems(::?CLASS:D:)
```
Expected to return a number indicating how many subscriptable elements there are in the object. May be called by users directly, and is also called by [`postcircumfix [ ]`](/language/operators#postcircumfix_[_]) when indexing elements from the end, as in `@foo[*-1]`.
If not implemented, your type will inherit the default implementation from [`Any`](/type/Any) that always returns `1` for defined invocants - which is most likely not what you want. So if the number of elements cannot be known for your positional type, add an implementation that [fail](/routine/fail)s or [die](/routine/die)s, to avoid silently doing the wrong thing.
# [In Array](#___top "go to top of document")[§](#(Array)_method_elems "direct link")
See primary documentation
[in context](/type/Array#method_elems)
for **method elems**.
```raku
method elems(Array:D: --> Int:D)
```
Returns the number of elements in the invocant. Throws [`X::Cannot::Lazy`](/type/X/Cannot/Lazy) exception if the invocant [is lazy](/routine/is-lazy). For shaped arrays, returns the outer dimension; see [shape](/routine/shape) if you need information for all dimensions.
```raku
say [<foo bar ber>] .elems; # OUTPUT: «3»
say (my @a[42;3;70]).elems; # OUTPUT: «42»
try [-∞...∞].elems;
say $!.^name; # OUTPUT: «X::Cannot::Lazy»
```
# [In role Positional](#___top "go to top of document")[§](#(role_Positional)_method_elems "direct link")
See primary documentation
[in context](/type/Positional#method_elems)
for **method elems**.
```raku
method elems()
```
Should return the number of available elements in the instantiated object.
# [In Any](#___top "go to top of document")[§](#(Any)_method_elems "direct link")
See primary documentation
[in context](/type/Any#method_elems)
for **method elems**.
```raku
multi method elems(Any:U: --> 1)
multi method elems(Any:D:)
```
Interprets the invocant as a list, and returns the number of elements in the list.
```raku
say 42.elems; # OUTPUT: «1»
say <a b c>.elems; # OUTPUT: «3»
say Whatever.elems ; # OUTPUT: «1»
```
It will also return 1 for classes.
# [In role Blob](#___top "go to top of document")[§](#(role_Blob)_method_elems "direct link")
See primary documentation
[in context](/type/Blob#method_elems)
for **method elems**.
```raku
multi method elems(Blob:D:)
```
Returns the number of elements of the buffer.
```raku
my $blob = Blob.new([1, 2, 3]);
say $blob.elems; # OUTPUT: «3»
```
# [In Metamodel::EnumHOW](#___top "go to top of document")[§](#(Metamodel::EnumHOW)_method_elems "direct link")
See primary documentation
[in context](/type/Metamodel/EnumHOW#method_elems)
for **method elems**.
```raku
method elems($obj)
```
Returns the number of values.
```raku
enum Numbers <10 20>;
say Numbers.^elems; # OUTPUT: 2
```
# [In role Setty](#___top "go to top of document")[§](#(role_Setty)_method_elems "direct link")
See primary documentation
[in context](/type/Setty#method_elems)
for **method elems**.
```raku
method elems(Setty:D: --> Int)
```
The number of elements of the set.
# [In Supply](#___top "go to top of document")[§](#(Supply)_method_elems "direct link")
See primary documentation
[in context](/type/Supply#method_elems)
for **method elems**.
```raku
method elems(Supply:D: $seconds? --> Supply:D)
```
Creates a new supply in which changes to the number of values seen are emitted. It optionally also takes an interval (in seconds) if you only want to be updated every so many seconds.
|
## dist_zef-lucs-File-TreeBuilder_1.md
[](https://github.com/lucs/File-TreeBuilder/actions)
# NAME
```
File::TreeBuilder - Build text-scripted trees of files
```
## SYNOPSIS
```
use File::TreeBuilder;
#`{
Note that this example heredoc string is literal ('Q'), so
no interpolation occurs at all. The program will replace
the literal '\n', '\t', '\s' (representing a space), and
'\\' by the correct characters.
Also, empty lines and lines starting with '#'
will be discarded and ignored.
It is invalid for any real tab characters to appear in
this string, so indentation must be accomplished with
spaces only. And the indentation must be coherent (bad
examples are shown later).
This is an example of an actual tree of files and
directories that one might want to build. It has examples
of pretty much all the features the program supports,
described in detail later.
}
my $tree-desc = Q:to/EoDesc/;
/ D1
. F1
. F2 . File\n\twith tab, newlines and 2 trailing space.\n\s\s
/_ D_2
.x Fx3
/600 D3
. F4 % f4-key
.755é Fé5
. F6 . \sLine continued, \
and backslash and 't': \\t.
EoDesc
my %file-contents = (
f4-key => "File contents from hash.".uc,
);
my $parent-dir = '/home/lucs/File-TreeBuilder.demo';
build-tree(
$parent-dir,
$tree-desc,
%file-contents,
);
```
The example code would create the following directories and files under the parent directory, which must already exist:
```
D1/
F1
F2
D 2/
F 3
D3/
F4
F 5
F6
Note that:
The 'D1' directory will have default permissions.
The 'F1' file will be empty and have default permissions.
The 'F2' file will contain :
"File\n\twith tab, newlines and 2 trailing spaces.\n ".
The 'D 2' directory has a space in its name.
The 'F 3' file has a space in its name.
The 'D3' directory will have permissions 0o600.
The 'F4' file will contain "FILE CONTENTS FROM HASH.".
The 'F 5' file has a space in its name and will have permissions
0o755.
The 'F6' file will contain " Line continued, and backslash and 't': \\t."
```
## DESCRIPTION
This module exports the `build-tree` function, used for building and populating simple trees of files and directories. I have found this useful to build test data for programs that need such things. Invoke the function like this:
```
build-tree(
Str $parent-dir,
Str $tree-desc,
%file-contents?,
)
```
`$parent-dir` is the directory under which the needed files and directories will be created. It must already exist and have write permission.
`$tree-desc` is a multiline string describing a hierarchy of needed directories and files and their contents.
The optional `%file-contents` argument can be used to specify arbitrary file contents, as will be explained below.
### The tree description
Within the `$tree-desc` string, blank or empty lines are ignored. The string must also not contain any tab characters. The first non-blank character of each remaining line must be one of:
```
# : Comment line, will be ignored.
/ : The line describes a wanted directory.
. : The line describes a wanted file.
```
Any other first non-blank is invalid.
#### Directory descriptions
Directory descriptions must mention a directory name. The leading ‹/› can optionally be immmediately followed by a three-digit octal representation of the desired permissions of the directory and/or by a space-representing character to be used if the directory name is to contain spaces, and must then be followed by whitespace and the directory name. For example:
```
/ d : Directory 'd'.
/X dXc : Directory 'd c'; spaces in its name are represented by 'X'.
/600 e : Directory 'e', permissions 600 (octal always).
/755_ a_b : Directory 'a b', permissions 755.
/ : Error: Missing directory name.
/644 : Error: Missing directory name.
/ abc de : Error: unexpected data (here, 'de').
```
#### File descriptions
File descriptions must mention a file name. The leading ‹.› can optionally be immmediately followed by a three-digit octal representation of the desired permissions of the file and/or by a space-representing character to be used if the file name is to contain spaces, and must then be followed by whitespace and the file name, and then optionally be followed by whitespace and by a specification of their wanted contents, as one of either:
```
. ‹literal contents›
% ‹key of contents to be retrieved from the %file-contents argument›
```
A ‹.› means to place the trimmed rest of the line into the created file. The program will replace `\t`, `\n`, `\s`, and `\\` with actual tabs, newlines, spaces, and backslashes in the file inserted content. If a line ends with a single ‹\›, the line that follows it will be concatenated to it, having its leading spaces removed.
A ‹%› means to take the trimmed rest of the line as a key into the instance's `%file-contents` and to use the corresponding found value as the file contents.
For example:
```
. f : File "f", contents empty (default), default permissions.
._ f_a : File "f a": spaces in its name are represented by '_'.
.444Z fZb : File "f b", permission 444.
. f . me ow : File "f", literal contents: "me ow".
. f % k9 : File "f", contents retrieved from %file-contents<k9>.
. f . This line \
continues.\n
: File "f", contents are "This line continues.\n".
. : Error: missing filename.
. f x : Error: unrecognized ‹x›.
. f % baz : Error if %file-contents wasn't specified
or if key ‹baz› is missing from it.
. f % : Error: No key specified.
```
#### Hierarchy
Directories are created hierarchically, according to the indentation. Files are created in the directory hierarchically above them. In the hierarchy then, these are okay:
```
Directories and files intermixed on the same level.
/ d1
/ d2
. f1
. f2
/ d3
A directory holding a subdirectory or a file.
/ d1
/ d2
. f1
Returning to a previously established level, here at ‹. f2›.
/ d1
/ d2
/ d3
. f1
. f2
```
But these are not:
```
A file cannot hold a file.
. f1
. f2
Nor can it hold a directory.
. f1
/ d1
‹/ d3›'s indentation conflicts with those of ‹/ d1› and ‹/ d2›.
/ d1
/ d2
/ d3
‹/ d5›'s indentation conflicts with those of ‹/ d2› and ‹/ d3›.
/ d1
/ d2
/ d3
/ d4
/ d5
```
## AUTHOR
Luc St-Louis [lucs@pobox.com](mailto:lucs@pobox.com)
## COPYRIGHT AND LICENSE
Copyright 2023
This library is free software; you can redistribute it and/or modify it under the Artistic License 2.0.
|
## dist_zef-antononcube-DSL-English-QuantileRegressionWorkflows.md
# Quantile Regression Workflows
## In brief
This Raku Perl 6 package has grammar classes and action classes.
These are used for the parsing and interpretation of spoken commands that specify Quantile Regression (QR) workflows.
It is envisioned that the interpreters (actions) target different
programming languages: R, Mathematica, Python, etc.
The generated pipelines are for the software monads
[`QRMon-R`](https://github.com/antononcube/QRMon-R)
and
[`QRMon-WL`](https://github.com/antononcube/MathematicaForPrediction/blob/master/MonadicProgramming/MonadicQuantileRegression.m),
[AA1, AA2].
## Installation
**1.** Install Raku (Perl 6) : <https://raku.org/downloads> .
**2.** You should make sure you have the Zef Module Installer.
* Type in `zef --version` in the command line.
* Zef Module Installer can be installed from : <https://github.com/ugexe/zef> .
**3.** Open a command line program. (E.g. Terminal on Mac OS X.)
**4.** Run the commands:
```
zef install https://github.com/antononcube/Raku-DSL-Shared.git
zef install https://github.com/antononcube/Raku-DSL-English-QuantileRegressionWorkflows.git
```
## Examples
Open a Raku IDE or type `raku` in the command line program. Try this Raku code:
```
use DSL::English::QuantileRegressionWorkflows;
say ToQuantileRegressionWorkflowCode(
"compute quantile regression with 16 knots and probabilities 0.25, 0.5 and 0.75",
"R-QRMon");
# QRMonQuantileRegression(df = 16, probabilities = c(0.25, 0.5, 0.75))
```
Here is a more complicated pipeline specification:
```
say ToQuantileRegressionWorkflowCode(
"create from dfTemperatureData;
compute quantile regression with 16 knots and probability 0.5;
show date list plot with date origin 1900-01-01;
show absolute errors plot;
echo text anomalies finding follows;
find anomalies by the threshold 5;
take pipeline value;", "R-QRMon")
```
The command above should print out R code for the R package `QRMon-R`, [AA1]:
```
QRMonUnit( data = dfTemperatureData) %>%
QRMonQuantileRegression(df = 16, probabilities = c(0.5)) %>%
QRMonPlot( datePlotQ = TRUE, dateOrigin = '1900-01-01') %>%
QRMonErrorsPlot( relativeErrorsQ = FALSE) %>%
QRMonEcho( "anomalies finding follows" ) %>%
QRMonFindAnomaliesByResiduals( threshold = 5) %>%
QRMonTakeValue
```
## Versions
The original version of this Raku package was developed and hosted at
[ [AA3](https://github.com/antononcube/ConversationalAgents/tree/master/Packages/Perl6/QuantileRegressionWorkflows) ].
A dedicated GitHub repository was made in order to make the installation with Raku's `zef` more direct.
(As shown above.)
## References
### Packages
[AA1] Anton Antonov,
[Quantile Regression Monad in R](https://github.com/antononcube/QRMon-R),
(2019),
[QRMon-R at GitHub](https://github.com/antononcube/QRMon-R).
[AA2] Anton Antonov,
[Monadic Quantile Regression Mathematica package](https://github.com/antononcube/MathematicaForPrediction/blob/master/MonadicProgramming/MonadicQuantileRegression.m),
(2018),
[MathematicaForPrediction at GitHub](https://github.com/antononcube/MathematicaForPrediction).
[AA3] Anton Antonov,
[Quantile Regression Workflows](https://github.com/antononcube/ConversationalAgents/tree/master/Packages/Perl6/QuantileRegressionWorkflows),
(2019),
[ConversationalAgents at GitHub](https://github.com/antononcube/ConversationalAgents).
### Videos
[AAv1] Anton Antonov,
["Simplified Machine Learning Workflows Overview"](https://www.youtube.com/watch?v=Xy7eV8wRLbE), (WTC-2022),
(2022),
[YouTube/Wolfram](https://www.youtube.com/@WolframResearch).
[AAv2] Anton Antonov,
["Natural Language Processing Template Engine"](https://www.youtube.com/watch?v=IrIW9dB5sRM), (WTC-2022),
(2022),
[YouTube/Wolfram](https://www.youtube.com/@WolframResearch).
|
## dist_github-supernovus-Hinges.md
# Hinges
## Introduction
Hinges is a Genshi-like template engine for Perl 6.
It's a modular system based on XML SAX streams, it allows for combining
(X)HTML and Perl 6 code in the same template.
## Authors
[Carl Mäsak](https://github.com/masak/)
|
## dist_zef-jjatria-Game-Entities.md
# NAME
Game::Entities
# SYNOPSIS
```
given Game::Entities.new {
# Create an entity with a possibly empty set of components
$guid = .create:
Collidable.new,
Drawable.new,
Consumable.new;
# CRUD operations on an entity's components
.add: $guid, Equipable.new;
.delete: $guid, Consumable;
$item = .get: $guid, Equipable;
# A system operates on sets of entities in a number of possible ways
.view( Drawable, Equipable ).each: {
draw-equipment $^draw, $^item
}
# This is the same as above
for .view: Drawable, Equipable {
my ( $draw, $item ) = |.value;
draw-equipment $draw, $item;
}
# The block can also receive the entity if you need it
.view( Drawable, Equipable ) -> $guid, $draw, $item {
with .get: $guid, Consumable {
say 'This is equipment you can eat!';
}
...
}
# Delete the entity and all its components
.delete: $guid;
.clear; # Delete all entities and components
}
```
# DESCRIPTION
Game::Entities is a minimalistic entity manager designed for applications using an ECS architecture.
If you don't know what this means, Mick West's [Evolve Your Hierarchy](http://cowboyprogramming.com/2007/01/05/evolve-your-heirachy) might be a good place to start.
## On Stability
This distribution is currently **experimental**, and as such, its API might still change without warning. Any change, breaking or not, will be noted in the change log, so if you wish to use it, please pin your dependencies and make sure to check the change log before upgrading.
# CONCEPTS
Throughout this documentation, there are a couple of key concepts that will be used repeatedly:
## GUID
Entities are represented by an opaque global unique identifier: a GUID. GUIDs used by Game::Entities are stored as `Int` objects, and represent a particular version of an entity which will remain valid as long as that entity is not deleted (with `delete` or `clear`).
Each Game::Entities registry supports up to 1,048,575 (2^20 - 1) simultaneous valid entity GUIDs. From version 0.0.4, they are guaranteed to always be truthy values.
## Valid entities
An entity's GUID is valid from the time it is created with `create` until the time it is deleted. An entity's GUID can be stored and used as an identifier anywhere in the program at any point during this time, but must not be used outside it.
## Components
As far as Game::Entities is concerned, any object of any type can be used as a component and added to an entity. This includes built-in types like `Int` and `Str` and those defined by the user with keywords like `class` or `role`.
Entities can have any number of components attached to them, but they will only ever have one component of any one type (as reported by `.WHAT`).
## Views
A group of components defines a view, which is composed of all entities that have all of that view's components. This means that all the entities for the view for components `A`, `B`, and `C` will have *at least* all those components, but could of course have any others as well.
The main purpose of views is to make it possible to iterate as fast as possible over any group of entities that have a set of common components.
# METHODS
## new
```
method new () returns Game::Entities
```
Creates a new entity registry. The constructor takes no arguments.
## create
```
method create (
*@components,
) returns Int
```
Creates a new entity and returns its GUID. If called with a list of components, these will be added to the entity before returning.
## add
```
multi method add (
Int() $guid,
$component,
) returns Nil
multi method add (
Int() $guid,
*@components,
) returns Nil
```
Takes an entity's GUID and a component, and adds that component to the specified entity. If the entity already had a component of that type, calling this method will silently overwrite it.
Multiple components can be specified, and they will all be added in the order they were provided.
## get
```
multi method get (
Int() $guid,
$component,
)
multi method get (
Int() $guid,
*@components,
)
```
Takes an entity's GUID and a component, and retrieves the component of that type from the specified entity, if it exists. If the entity had no component of that type, a type object of the component's type will be returned.
Multiple components can be specified, and they will all be retrieved and returned in the order they were provided.
## delete
```
multi method delete (
Int() $guid,
) returns Nil
multi method delete (
Int() $guid,
$component,
) returns Nil
multi method delete (
Int() $guid,
*@components,
)
```
When called with only an entity's GUID, it deletes all components from the entity, and marks that entity's GUID as invalid.
When called with an additional component or more, components of those types will be removed from the specified entity in that order. Deleting a component from an entity is an idempotent process.
## check
```
method check (
Int() $guid,
$component,
) returns Bool
```
Takes an entity's GUID and a component and returns `True` if the specified entity has a component of that type, or `False` otherwise.
## valid
```
method valid (
Int() $guid,
) returns Bool
```
Takes an entity's GUID and returns `True` if the specified entity is valid, or `False` otherwise. An entity is valid if it has been created and not yet deleted.
## created
```
method created () returns Int
```
Returns the number of entities that have been created. Calling `clear` resets this number.
## alive
```
method alive () returns Int
```
Returns the number of created entities that are still valid. That is: entities that have been created and not yet deleted.
## clear
```
method clear () returns Nil
```
Resets the internal storage of the registry. Calling this method leaves no trace from the previous state.
## sort
```
method sort( $component, $parent );
method sort( $component, { ... } );
```
*Since version 0.1.0*.
Under normal circumstances, the order in which a particular set of components is stored is not guaranteed, and will depend entirely on the additions and deletions of that component type.
However, it will sometimes be useful to impose an order on a component set. This will be the case for example when renderable components need to be drawn back to front, etc.
This method accommodates this use case.
Given a single component, and a `Callable` to use as a comparator, the specified component will be sorted accordingly. The comparator behaves just like the one used for the regular [sort](https://docs.raku.org/routine/sort), and can take one or two parameters. The arguments to the comparator will be the components being compared.
Alternatively, if given another component (`B`) to use as a parent instead of a comparator, the order of the first component (`A`) will follow that of `B`. After this, iterating over the entities that have `A` will return
* all of the entities that also have `B`, according to the order in `B`
* all of the entities that *do not* have `B`, in no particular order
Sorting a component pool invalidates any cached views that use that component.
The imposed order for this component is guaranteed to be stable as long as no components of this type are added or removed.
## view
```
multi method view (
Whatever,
) returns Game::Entities::View
multi method view (
$component,
) returns Game::Entities::View
multi method view (
*@components,
) returns Game::Entities::View
```
Takes a set of one or more components, and returns an internal object representing a *view* for that specific set of components. Entities in the view are in no specific order, and this order is not guaranteed to remain the same.
As a special case, calling this method with a `Whatever` will generate a view which is guaranteed to always have all valid entities.
Once a view has been created, it should remain valid as long as none of the components in the view's set are added or deleted from any entity. Once this is done, the data returned by the view object is no longer guaranteed to be accurate. For this reason, it is not recommended to keep hold of view objects for longer than it takes to run an iteration.
The view object implements an `iterator` method which returns a list of `Pair` objects with the GUID of each entity in the view as the key, and a `List` of components as the value. This means that using the view in eg. a `for` loop should behave as expected, as illustrated below:
```
for $registry.view: |@components {
my $guid = .key;
my @components = .value;
# Do something with the GUID and components
}
```
Apart from this, the interface for this object is documented below:
### each
```
method each ( &cb ) returns Nil
```
Takes a block of code which will be called once per entity in the view.
The block of code will be called with a flat list with the GUID for the current entity as an `Int`, and the components in the requested set in the order they were specified. If the block cannot be called with these parameters, the GUID will be skipped and only the list of components will be used. Using a block that does not accept either of these is an error.
As the block of code is called within a loop, using control flow statements like `last`, `next`, and `redo` is supported and should behave as expected.
If the view was created with a `Whatever`, the view will be considered to have an empty component list, which means the block of code will *always* be called with the GUID of the current entity.
Within the callback, it is safe to add or delete entities, as well as to add or remove components from those entities.
### entities
```
method entities () returns List
```
Returns a list of only the GUIDs of the entities in this view.
### components
```
method components () returns List
```
Returns a list of `List` objects, each of which will hold the list of components for a single entity in the view. The components will be in the order provided when the view was created.
Useful for iterating like
```
for $registry.view( A, B, C ).components -> ( $a, $b, $c ) {
...
}
```
# PERFORMANCE
Game::Entities aims to implement a simple entity that is as fast as possible. Specifically, this means tht it needs to be fast enough to be used in game development, which is the natural use case for ECS designs.
To this end, the library caches component iterators which are invalidated every time one of the components relevant to that iterator is either added or removed from any entity. This should make the common case of systems operating over sets of components that tend to be relatively stable (eg. across game frames) as fast as possible.
The distribution includes two tests in its extended suite to test the performance with iterations over large number of entities (`xt/short-loops.t`), and many iterations over small numbers of entities (`xt/long-loops.t`). Please refer to these files for accurate estimations.
# SEE ALSO
* [EnTT](https://skypjack.github.io/entt)
Much of the design and API of this distribution is based on that of the entity registry in EnTT (famously used in Minecraft). A significant part of the credit for the algorithms and data structures used by Game::Entities falls on the EnTT developers and [the blog posts](https://skypjack.github.io) they've made to explain how they work.
# COPYRIGHT AND LICENSE
Copyright 2021 José Joaquín Atria
This library is free software; you can redistribute it and/or modify it under the Artistic License 2.0.
|
## dist_zef-tbrowder-File-Copy.md
[](https://github.com/tbrowder/File-Copy/actions) [](https://github.com/tbrowder/File-Copy/actions) [](https://github.com/tbrowder/File-Copy/actions)
# TITLE
**File::Copy** - Provides the essential functions of the POSIX `cp` command
# SYNOPSIS
```
use File::Copy; # exports routine 'cp'
cp "/usr/share/fonts/", "/home/fonts"; # the trailing slash is not required
```
# DESCRIPTION
Exported function `cp` copies files and directories from one location to another. Its behavior is intended to be very similar to the POSIX `cp` utility program.
If the `$from` location is a directory, it and all its top-level files will copied to the `$to` location. A fatal error will be thrown if `$from` is a directory and `$to` is a file. If the recursive option (`:r`) is used, all below the `from` path will be copied.
Errors will also be thrown if the permissions in either location are not appropriate for the selected operation.
Existing files **will** be overwritten unless the `:createonly` option is selected.
Current named options:
* `:i` (or `:interactive`) - Asks permission to overwrite an existing file.
* `:r` (or `:recursive`) - When the source (`$from`) is a directory, copy recursively.
* `:c` (or `:createonly`) - Existing files will be overwritten, but notice will be given.
* `:v` (or `:verbose`) - Informs the user about copying details.
See an example Raku program using this module in the module package repository at <examples>.
# AUTHOR
Tom Browder [tbrowder@acm.org](mailto:tbrowder@acm.org)
# COPYRIGHT AND LICENSE
© 2023 Tom Browder
This library is free software; you may redistribute it or modify it under the Artistic License 2.0.
|
## cmp.md
cmp
Combined from primary sources listed below.
# [In List](#___top "go to top of document")[§](#(List)_infix_cmp "direct link")
See primary documentation
[in context](/type/List#infix_cmp)
for **infix cmp**.
```raku
multi infix:<cmp>(List @a, List @b)
```
Evaluates `Lists` by comparing element `@a[$i]` with `@b[$i]` (for some `Int $i`, beginning at 0) and returning `Order::Less`, `Order::Same`, or `Order::More` depending on if and how the values differ. If the operation evaluates to `Order::Same`, `@a[$i + 1]` is compared with `@b[$i + 1]`. This is repeated until one is greater than the other or all elements are exhausted.
If the `List`s are of different lengths, at most only `$n` comparisons will be made (where `$n = @a.elems min @b.elems`). If all of those comparisons evaluate to `Order::Same`, the final value is selected based upon which `List` is longer.
```raku
say (1, 2, 3) cmp (1, 2, 3); # OUTPUT: «Same»
say (4, 5, 6) cmp (4, 5, 7); # OUTPUT: «Less»
say (7, 8, 9) cmp (7, 8, 8); # OUTPUT: «More»
say (1, 2) cmp (1, 2, 3); # OUTPUT: «Less»
say (1, 2, 3) cmp (1, 2); # OUTPUT: «More»
say (9).List cmp (^10).List; # OUTPUT: «More»
```
# [In Pair](#___top "go to top of document")[§](#(Pair)_infix_cmp "direct link")
See primary documentation
[in context](/type/Pair#infix_cmp)
for **infix cmp**.
```raku
multi infix:<cmp>(Pair:D, Pair:D)
```
The type-agnostic comparator; compares two `Pair`s. Compares first their *key* parts, and then compares the *value* parts if the keys are equal.
```raku
my $a = (Apple => 1);
my $b = (Apple => 2);
say $a cmp $b; # OUTPUT: «Less»
```
# [In Operators](#___top "go to top of document")[§](#(Operators)_infix_cmp "direct link")
See primary documentation
[in context](/language/operators#infix_cmp)
for **infix cmp**.
```raku
multi infix:<cmp>(Any, Any)
multi infix:<cmp>(Real:D, Real:D)
multi infix:<cmp>(Str:D, Str:D)
multi infix:<cmp>(Version:D, Version:D)
```
Generic, "smart" three-way comparator.
Compares strings with string semantics, numbers with number semantics, [`Pair`](/type/Pair) objects first by key and then by value etc.
if `$a eqv $b`, then `$a cmp $b` always returns `Order::Same`.
```raku
say (a => 3) cmp (a => 4); # OUTPUT: «Less»
say 4 cmp 4.0; # OUTPUT: «Same»
say 'b' cmp 'a'; # OUTPUT: «More»
```
Strings are compared codepoint by codepoint; if leading codepoints are the same, the result of comparing the first differing codepoint is returned or the longer string if their lengths differ.
```raku
"abcd" cmp "abcde"; # OUTPUT: «Less»
"abcd " cmp "abcde"; # OUTPUT: «Less»
'A' cmp 'Ẳ'; # OUTPUT: «Less»
```
# [In enum Order](#___top "go to top of document")[§](#(enum_Order)_infix_cmp "direct link")
See primary documentation
[in context](/type/Order#infix_cmp)
for **infix cmp**.
```raku
multi infix:<cmp>(\a, \b --> Order:D)
```
`cmp` will first try to compare operands as strings (via coercion to [`Stringy`](/type/Stringy)), and, failing that, will try to compare numerically via the `<=>` operator or any other type-appropriate comparison operator. See also [the documentation for the `cmp` operator](/routine/cmp#(Operators)_infix_cmp).
# [In Allomorph](#___top "go to top of document")[§](#(Allomorph)_infix_cmp "direct link")
See primary documentation
[in context](/type/Allomorph#infix_cmp)
for **infix cmp**.
```raku
multi infix:<cmp>(Allomorph:D $a, Allomorph:D $b)
```
Compare two `Allomorph` objects. The comparison is done on the [`Numeric`](/type/Numeric) value first and then on the [`Str`](/type/Str) value. If you want to compare in a different order then you would coerce to a [`Numeric`](/type/Numeric) or [`Str`](/type/Str) value first:
```raku
my $f = IntStr.new(42, "smaller");
my $g = IntStr.new(43, "larger");
say $f cmp $g; # OUTPUT: «Less»
say $f.Str cmp $g.Str; # OUTPUT: «More»
```
|
## iterating.md
Iterating
Functionalities available for visiting all items in a complex data structure
# [The](#Iterating "go to top of document") [`Iterator`](/type/Iterator) and [`Iterable`](/type/Iterable) roles[§](#The_Iterator_and_Iterable_roles "direct link")
Raku is a functional language, but functions need something to hold on to when working on complex data structures. In particular, they need a uniform interface that can be applied to all data structures in the same way. One of these kind of interfaces is provided by the [`Iterator`](/type/Iterator) and [`Iterable`](/type/Iterable) roles.
The [`Iterable`](/type/Iterable) role is relatively simple. It provides a stub for the `iterator` method, which is the one actually used by statements such as `for`. `for` will call `.iterator` on the variable it precedes, and then run a block once for every item. Other methods, such as array assignment, will make the [`Iterable`](/type/Iterable) class behave in the same way.
```raku
class DNA does Iterable {
has $.chain;
method new ($chain where {
$chain ~~ /^^ <[ACGT]>+ $$ / and
$chain.chars %% 3 } ) {
self.bless( :$chain );
}
method iterator(DNA:D:){ $.chain.comb.rotor(3).iterator }
};
my @longer-chain = DNA.new('ACGTACGTT');
say @longer-chain.raku;
# OUTPUT: «[("A", "C", "G"), ("T", "A", "C"), ("G", "T", "T")]»
say @longer-chain».join("").join("|"); # OUTPUT: «ACG|TAC|GTT»
```
In this example, which is an extension of the [example in `Iterable` that shows how `for` calls `.iterator`](/type/Iterable), the `iterator` method will be called in the appropriate context only when the created object is assigned to a [`Positional`](/type/Positional) variable, `@longer-chain`; this variable is an [`Array`](/type/Array) and we operate on it as such in the last example.
The (maybe a bit confusingly named) [`Iterator`](/type/Iterator) role is a bit more complex than [`Iterable`](/type/Iterable). First, it provides a constant, `IterationEnd`. Then, it also provides a series of [methods](/type/Iterator#Methods) such as `.pull-one`, which allows for a finer operation of iteration in several contexts: adding or eliminating items, or skipping over them to access other items. In fact, the role provides a default implementation for all the other methods, so the only one that has to be defined is precisely `pull-one`, of which only a stub is provided by the role. While [`Iterable`](/type/Iterable) provides the high-level interface loops will be working with, [`Iterator`](/type/Iterator) provides the lower-level functions that will be called in every iteration of the loop. Let's extend the previous example with this role.
```raku
class DNA does Iterable does Iterator {
has $.chain;
has Int $!index = 0;
method new ($chain where {
$chain ~~ /^^ <[ACGT]>+ $$ / and
$chain.chars %% 3 } ) {
self.bless( :$chain );
}
method iterator( ){ self }
method pull-one( --> Mu){
if $!index < $.chain.chars {
my $codon = $.chain.comb.rotor(3)[$!index div 3];
$!index += 3;
return $codon;
} else {
return IterationEnd;
}
}
};
my $a := DNA.new('GAATCC');
.say for $a; # OUTPUT: «(G A A)(T C C)»
```
We declare a `DNA` class which does the two roles, [`Iterator`](/type/Iterator) and [`Iterable`](/type/Iterable); the class will include a string that will be constrained to have a length that is a multiple of 3 and composed only of ACGT.
Let us look at the `pull-one` method. This one is going to be called every time a new iteration occurs, so it must keep the state of the last one. An `$.index` attribute will hold that state across invocations; `pull-one` will check if the end of the chain has been reached and will return the `IterationEnd` constant provided by the role. Implementing this low-level interface, in fact, simplifies the implementation of the [`Iterable`](/type/Iterable) interface. Now the iterator will be the object itself, since we can call `pull-one` on it to access every member in turn; `.iterator` will thus return just `self`; this is possible since the object will be, at the same time, [`Iterable`](/type/Iterable) and [`Iterator`](/type/Iterator).
This need not always be the case, and in most cases `.iterator` will have to build an iterator type to be returned (that will, for instance, keep track of the iteration state, which we are doing now in the main class), such as we did in the previous example; however, this example shows the minimal code needed to build a class that fulfills the iterator and iterable roles.
# [How to iterate: contextualizing and topic variables](#Iterating "go to top of document")[§](#How_to_iterate:_contextualizing_and_topic_variables "direct link")
`for` and other loops place the item produced in every iteration into the [topic variable `$_`](/language/variables#index-entry-topic_variable), or capture them into the variables that are declared along with the block. These variables can be directly used inside the loop, without needing to declare them, by using the [`^` twigil](/syntax/$CIRCUMFLEX_ACCENT#(Traps_to_avoid)_twigil_^).
Implicit iteration occurs when using the [sequence operator](/language/operators#infix_...).
```raku
say 1,1,1, { $^a²+2*$^b+$^c } … * > 300; # OUTPUT: «(1 1 1 4 7 16 46 127 475)
```
The generating block is being run once while the condition to finish the sequence, in this case the term being bigger than 300, is not met. This has the side effect of running a loop, but also creating a list that is output.
This can be done more systematically through the use of the [`gather/take` blocks](/syntax/gather take), which are a different kind of iterating construct that instead of running in sink context, returns an item every iteration. This [Advent Calendar tutorial](https://perl6advent.wordpress.com/2009/12/23/day-23-lazy-fruits-from-the-gather-of-eden/) explains use cases for this kind of loops; in fact, gather is not so much a looping construct, but a statement prefix that collects the items produced by `take` and creates a list out of them.
# [`Classic` loops and why we do not like them](#Iterating "go to top of document")[§](#Classic_loops_and_why_we_do_not_like_them "direct link")
Classic `for` loops, with a loop variable being incremented, can be done in Raku through the [`loop` keyword](/language/control#loop). Other [repeat](/language/control#repeat/while,_repeat/until) and [while](/language/control#while,_until) loops are also possible.
However, in general, they are discouraged. Raku is a functional and concurrent language; when coding in Raku, you should look at loops in a functional way: processing, one by one, the items produced by an iterator, that is, feeding an item to a block without any kind of secondary effects. This functional view allows also easy parallelization of the operation via the [`hyper`](/routine/hyper) or [`race`](/routine/race) auto-threading methods.
If you feel more comfortable with your good old loops, the language allows you to use them. However, it is considered better practice in Raku to try and use, whenever possible, functional and concurrent iterating constructs.
*Note:* Since version 6.d loops can produce a list of values from the values of last statements.
|
## dist_cpan-AZAWAWI-SDL2.md
# SDL2
[](https://travis-ci.org/azawawi/perl6-sdl2) [](https://ci.appveyor.com/project/azawawi/perl6-sdl2/branch/master)
This module adds some OO-sugar on top of [`SDL2::Raw`](https://github.com/timo/SDL2_raw-p6/).
**Note: This is currently experimental and API may change. Please DO NOT use in
a production environment.**
## Example
```
use v6;
use SDL2::Raw;
use SDL2;
die "couldn't initialize SDL2: { SDL_GetError }" if SDL_Init(VIDEO) != 0;
LEAVE SDL_Quit;
my $window = SDL2::Window.new(:title("Hello, world!"), :flags(OPENGL));
LEAVE $window.destroy;
my $render = SDL2::Renderer.new($window);
LEAVE $render.destroy;
my $event = SDL_Event.new;
main: loop {
$render.draw-color(0, 0, 0, 0);
$render.clear;
while SDL_PollEvent($event) {
last main if $event.type == QUIT;
}
$render.draw-color(255, 255, 255, 255);
$render.fill-rect(
SDL_Rect.new(
2 * min(now * 300 % 800, -now * 300 % 800),
2 * min(now * 470 % 600, -now * 470 % 600),
sin(3 * now) * 50 + 80, cos(4 * now) * 50 + 60));
$render.present;
}
```
More examples can be found in [`examples`](examples/) folder.
## Installation
Please see [`SDL2::Raw`](https://github.com/timo/SDL2_raw-p6/) for `libsdl2` platform dependencies.
```
$ zef install sdl2
```
## Testing
* To run tests:
```
$ prove -ve "perl6 -Ilib"
```
* To run all tests including author tests (Please make sure
[Test::Meta](https://github.com/jonathanstowe/Test-META) is installed):
```
$ zef install Test::META
$ AUTHOR_TESTING=1 prove -e "perl6 -Ilib"
```
## Author
Ahmad M. Zawawi, [azawawi](https://github.com/azawawi/) on #perl6
## License
MIT License
|
## dist_zef-raku-community-modules-Pod-EOD.md
[](https://github.com/raku-community-modules/Pod-EOD/actions) [](https://github.com/raku-community-modules/Pod-EOD/actions) [](https://github.com/raku-community-modules/Pod-EOD/actions)
# NAME
Pod::EOD - Moves declarative POD blocks to the end of the POD
# SYNOPSIS
```
#| Example sub!
my sub example {}
DOC INIT {
use Pod::EOD;
move-declarations-to-end($=pod);
}
=head1 OTHER POD
...
# Now the "Example sub" POD appears after
# the "OTHER POD" POD!
```
# DESCRIPTION
Many authors from a Perl background (like myself) write POD in a "all POD at the end" style; this keeps it out of the way when you're looking at the code, but in the same file. However, POD blocks are inserted into `$=pod` in the order they occur in the code, and I would rather not give up the advantages of declarative POD blocks. So this module simply moves declative POD blocks to the end of the POD document, so that the developer can keep their POD at the end, and the user can read the high-level overview of the module before encountering the reference section provided by declarative blocks.
# AUTHORS
* Rob Hoelz
* Raku Community
# COPYRIGHT AND LICENSE
Copyright (c) 2016 - 2017 Rob Hoelz
Copyright (c) 2024 Raku Community
Permission is hereby granted, free of charge, to any person obtaining a copy of this software and associated documentation files (the "Software"), to deal in the Software without restriction, including without limitation the rights to use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies of the Software, and to permit persons to whom the Software is furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
# REFERENCE
### sub move-declarations-to-end
```
sub move-declarations-to-end(
$pod
) returns Mu
```
Rearranges the POD blocks in C<$pod> (you will almost always pass your module's C<$=pod> to this sub) so that declarative POD blocks (like this one) are moved to the end of the document. Note that this happens I, so your original array is modified!
|
## stringy.md
role Stringy
String or object that can act as a string
```raku
role Stringy { ... }
```
Common role for string types (such as Str).
# [Typegraph](# "go to top of document")[§](#typegraphrelations "direct link")
Type relations for `Stringy`
raku-type-graph
Stringy
Stringy
Positional
Positional
Blob
Blob
Blob->Stringy
Blob->Positional
Mu
Mu
Any
Any
Any->Mu
Cool
Cool
Cool->Any
Str
Str
Str->Stringy
Str->Cool
Uni
Uni
Uni->Stringy
Uni->Positional
Uni->Any
Allomorph
Allomorph
Allomorph->Str
NFKC
NFKC
NFKC->Uni
NFD
NFD
NFD->Uni
NFC
NFC
NFC->Uni
NFKD
NFKD
NFKD->Uni
Buf
Buf
Buf->Blob
utf8
utf8
utf8->Blob
utf8->Any
Numeric
Numeric
Real
Real
Real->Numeric
Int
Int
Int->Cool
Int->Real
IntStr
IntStr
IntStr->Allomorph
IntStr->Int
Num
Num
Num->Cool
Num->Real
NumStr
NumStr
NumStr->Allomorph
NumStr->Num
Complex
Complex
Complex->Cool
Complex->Numeric
ComplexStr
ComplexStr
ComplexStr->Allomorph
ComplexStr->Complex
Rational
Rational
Rational->Real
Rat
Rat
Rat->Cool
Rat->Rational
RatStr
RatStr
RatStr->Allomorph
RatStr->Rat
[Expand chart above](/assets/typegraphs/Stringy.svg)
|
## dist_zef-jonathanstowe-Chronic.md
# Chronic
Scheduling thingy for Raku

## Synopsis
```
# Static configuration;
use Chronic;
react {
# Every minute
whenever Chronic.every() -> $v {
say "One: $v";
}
# Every five minutes
whenever Chronic.every(minute => '*/5') -> $v {
say "Five: $v";
}
# At 21:31 every day
whenever Chronic.every(minute => 31, hour => 21) -> $v {
say "21:31 $v";
}
}
# Dynamic configuration
use Chronic;
my @events = (
{
schedule => {},
code => sub ($v) { say "One: $v" },
},
{
schedule => { minute => '*/2' },
code => sub ($v) { say "Two: $v" },
},
{
schedule => { minute => '*/5' },
code => sub ($v) { say "Five: $v" },
},
{
schedule => { minute => 31, hour => 21 },
code => sub ($v) { say "21:31 $v"; },
},
);
for @events -> $event {
Chronic.every(|$event<schedule>).tap($event<code>);
}
# This has the effect of waiting forever
Chronic.supply.wait;
```
## Description
This module provides a low-level scheduling mechanism, that be used to
create cron-like schedules, the specifications can be provided as cron
expression strings, lists of integer values or [Junctions](https://docs.raku.org/type/Junction) of values.
There is a class method `every` that takes a schedule specification
and returns a `Supply` that will emit a value (a `DateTime`) on
the schedule specified. There is also a method `at` (also a class
method) that returns a Promise that will be kept at a specified point
in time (as opposed to `Promise.in` which will return a Promise that
will be kept after a specified number of seconds.)
This can be used to build custom scheduling services like `cron`
with additional code to read the specification from a file and arrange
the execution of the required thing or it could be used in a larger
program that may require to execute some code asynchronously periodically.
There is a single base Supply that emits an event at a 1 second frequency
in order to preserve the accuracy of the timings (in testing it may drift
by up to 59 seconds on a long run due to system latency if it didn't match
the seconds too,) so this may be a problem on a heavily loaded single core
computer. The sub-minute granularity isn't provided for in the interface
as it is easily achieved anyway with a basic supply, it isn't supported by
a standard `cron` and I think most code that would want to be executed
with that frequency would be more highly optimised then this may allow.
## Installation
If you have a working Rakudo you can install directly with *zef*:
```
# From the source directory
zef install .
# Remote installation
zef install Chronic
```
## Support
Suggestions/patches are welcomed via github at <https://github.com/jonathanstowe/Chronic>
## Licence
This is free software.
Please see the <LICENCE> file in the distribution.
© Jonathan Stowe 2015, 2016, 2017, 2019, 2020
|
## ro.md
class X::Assignment::RO
Exception thrown when trying to assign to something read-only
```raku
class X::Assignment::RO is Exception {}
```
Code like
```raku
sub f() { 42 };
f() = 'new value'; # throws an X::Assignment::RO
CATCH { default { put .^name, ': ', .Str } };
# OUTPUT: «X::Assignment::RO: Cannot modify an immutable Any»
```
throws an exception of type `X::Assignment::RO`.
# [Methods](#class_X::Assignment::RO "go to top of document")[§](#Methods "direct link")
## [method typename](#class_X::Assignment::RO "go to top of document")[§](#method_typename "direct link")
```raku
method typename(X::Assignment::RO:D: --> Str)
```
Returns the type name of the value on the left-hand side
|
## dist_github-jaffa4-String-Stream.md
# String::Stream
Stream into a string or from a string. Use print, say to direct output into a string.
## Usage
```
my $t = String::Stream.new(); # for both input and output
print $t: "something";
say $t: "something else";
$*IN = Stream.new("puccini");
my $out = say prompt "composer> "; # $out will contain puccini.
print $t.buffer;
somethingsomething else
```
## Similar module
```
https://github.com/sergot/IO-Capture-Simple
```
|
## dist_cpan-AVUSEROW-Audio-TagLib.md
[](https://github.com/avuserow/raku-audio-taglib/actions)
# NAME
Audio::TagLib - Read ID3 and other audio metadata with TagLib
# SYNOPSIS
```
use Audio::TagLib;
my $taglib = Audio::TagLib.new($path);
# Abstract API - aliases for simple fields
say $taglib.title ~ " by " ~ $taglib.artist;
say "$path has no album field set" unless $taglib.album.defined;
# Raw access to all tags in the file (as a list of pairs)
.say for $taglib.propertymap.grep(*.key eq 'ALBUMARTIST' | 'ALBUM ARTIST');
```
# DESCRIPTION
Audio::TagLib provides Raku bindings to the TagLib audio metadata library, providing a fast way to read metadata from many audio file formats: mp3, m4a, ogg, flac, opus, and more. See <https://taglib.org> for more details.
# Audio::TagLib vs Audio::Taglib::Simple
This module uses the C++ interface to TagLib rather than the C bindings. This means installation requires a C++ compiler, but provides the full API rather than the "abstract only" API.
This module is newer than Simple and does not yet provide tag writing functions.
This module does not keep a taglib object open and reads everything into memory initially, meaning there is no `free` method needed (unlike Simple).
`Audio::Taglib::Simple` has a lowercase 'l' in its name, where this module uses `TagLib` (as does the official website). I thought adjusting the case was a good idea at the time.
### Abstract API
TagLib provides what is known as the "abstract API", which provides an easy interface to common tags without having to know the format-specific identifier for a given tag. This module provides these as attributes of `Audio::TagLib`. The following fields are available as strings (Str):
* title
* artist
* album
* comment
* genre
The following are provided as integers (Int):
* year
* track
* length - length of the file, in seconds
These attributes will be undefined if they are not present in the file.
### @.propertymap
The raw tag values are available in the propertymap attribute as a List of Pairs. It is possible to have duplicate keys (otherwise this would be a hash).
If you are looking for a tag that is not available in the abstract interface, you can find it here. O
## Album Art
Album art can be extracted from most types of audio files. This module provides access to the first picture data in the file. Most files only have a single picture attached, so this is usually the album art.
* album-art-size - the size of the album art in bytes
* album-art-mime - the mime type of the album art, such as 'image/png'
The data can be retrieved by calling one of the following methods:
* get-album-art - returns the data as a Blob[uint8]
* get-album-art-raw - returns the data as a CArray (call .elems to get the size)
The raw variant is much faster if you are passing the data to another function that uses a CArray. If speed is important, consider using NativeHelpers::Blob to convert the raw variant.
Note that the mime type is stored in the file, and not determined from the image, so it may be inaccurate.
# SEE ALSO
Audio::Taglib::Simple
<https://taglib.org>
# AUTHOR
Adrian Kreher [avuserow@gmail.com](mailto:avuserow@gmail.com)
# COPYRIGHT AND LICENSE
Copyright 2021-2022 Adrian Kreher
This library is free software; you can redistribute it and/or modify it under the Artistic License 2.0.
|
## frame.md
class Backtrace::Frame
Single frame of a Backtrace
```raku
class Backtrace::Frame { }
```
A single backtrace frame. It identifies a location in the source code.
# [Methods](#class_Backtrace::Frame "go to top of document")[§](#Methods "direct link")
## [method file](#class_Backtrace::Frame "go to top of document")[§](#method_file "direct link")
```raku
method file(Backtrace::Frame:D --> Str)
```
Returns the file name.
```raku
my $bt = Backtrace.new;
my $btf = $bt[0];
say $btf.file;
```
## [method line](#class_Backtrace::Frame "go to top of document")[§](#method_line "direct link")
```raku
method line(Backtrace::Frame:D --> Int)
```
Returns the line number (line numbers start counting from 1).
```raku
my $bt = Backtrace.new;
my $btf = $bt[0];
say $btf.line;
```
## [method code](#class_Backtrace::Frame "go to top of document")[§](#method_code "direct link")
```raku
method code(Backtrace::Frame:D)
```
Returns the code object into which `.file` and `.line` point, if available.
```raku
my $bt = Backtrace.new;
my $btf = $bt[0];
say $btf.code;
```
## [method subname](#class_Backtrace::Frame "go to top of document")[§](#method_subname "direct link")
```raku
method subname(Backtrace::Frame:D --> Str)
```
Returns the name of the enclosing subroutine.
```raku
my $bt = Backtrace.new;
my $btf = $bt[0];
say $btf.subname;
```
## [method is-hidden](#class_Backtrace::Frame "go to top of document")[§](#method_is-hidden "direct link")
```raku
method is-hidden(Backtrace::Frame:D: --> Bool:D)
```
Returns `True` if the frame is marked as hidden with the `is hidden-from-backtrace` trait.
```raku
my $bt = Backtrace.new;
my $btf = $bt[0];
say $btf.is-hidden;
```
## [method is-routine](#class_Backtrace::Frame "go to top of document")[§](#method_is-routine "direct link")
```raku
method is-routine(Backtrace::Frame:D: --> Bool:D)
```
Return `True` if the frame points into a routine (and not into a mere [`Block`](/type/Block)).
```raku
my $bt = Backtrace.new;
my $btf = $bt[0];
say $btf.is-routine;
```
## [method is-setting](#class_Backtrace::Frame "go to top of document")[§](#method_is-setting "direct link")
```raku
method is-setting(Backtrace::Frame:D: --> Bool:D)
```
Returns `True` if the frame is part of a setting.
```raku
my $bt = Backtrace.new;
my $btf = $bt[0];
say $btf.is-setting; # OUTPUT: «True»
```
|
## dist_zef-l10n-L10N-PT.md
# NAME
L10N::PT - Portuguese localization of Raku
# SYNOPSIS
```
use L10N::PT;
diga "Hello World";
```
# DESCRIPTION
L10N::PT contains the logic to provide a Portuguese localization of the Raku Programming Language.
# AUTHORS
Fernando Corrêa de Oliveira
# COPYRIGHT AND LICENSE
Copyright 2023 Raku Localization Team
This library is free software; you can redistribute it and/or modify it under the Artistic License 2.0.
|
## dist_zef-raku-community-modules-Games-BubbleBreaker.md
## Games::BubbleBreaker – a mouse based logic game
### Installation
This game requires `libSDL`, `libSDL_image` and `libSDL_mixer`. On Debian-based systems
you can install these with:
```
sudo apt install libsdl1.2-dev libsdl-mixer1.2-dev libsdl-image1.2-dev
```
### Running
The script can be ran from the sources by
```
raku bin/bubble-breaker.raku
```
after installation, it can be executed as simply as
```
bubble-breaker.raku
```
|
## dist_zef-librasteve-Net-Google-Sheets.md
[](https://opensource.org/licenses/Artistic-2.0)
# Net::Google::Sheets
Simple API access to Google Sheets, using [OAuth2::Client::Google](https://github.com/bduggan/p6-oauth2-client-google)
## Install
```
zef install Net::Google::Sheets
```
Follow the [HOW-TO](https://raku.land/cpan:BDUGGAN/OAuth2::Client::Google#quick-how-to) to make a client\_id.json in your script dir (eg. /bin for /bin/synopsis)
## Synopsis
```
#!/usr/bin/env raku
use Net::Google::Sheets;
my $session = Session.new;
my %sheets = $session.sheets;
my $id = %sheets<AWS_EC2_Sizes_test>;
# get values from Sheet1
my $sheet1 = Sheet.new(:$session, :$id, range => 'Sheet1');
my @vals = $sheet1.values;
dd @vals;
# put values into Sheet2
my $sheet2 = Sheet.new(:$session, :$id, range => 'Sheet2');
$sheet2.values: @vals;
# clear Sheet2
$sheet2.clear;
```
### Copyright
copyright(c) 2023-2024 Henley Cloud Consulting Ltd.
|
## dist_zef-jjmerelo-Math-Constants.md
# Math::Constants [.github/workflows/test.yaml](https://github.com/JJ/p6-math-constants/actions/workflows/test.yaml)
Math::Constants - A few constants defined in Raku
# SYNOPSIS
```
#!/usr/bin/env raku
use Math::Constants;
say "We have ", phi, " ", plancks-h, " ", plancks-reduced-h, " ",
c, " ", G, " and ", fine-structure-constant, " plus ",
elementary-charge, " and ", vacuum-permittivity ;
say "And also φ ", φ, " α ", α, " ℎ ", ℎ, " and ℏ ", ℏ,
" with e ", e, " and ε0 ", ε0;
say "We are flying at speed ", .1c;
```
# DESCRIPTION
Math::Constants is a collection of Math and Physics constants that will save you the trouble of defining them.
## Constants included
### Physical constants
All the physical constants have the [CODATA 2018](https://www.nist.gov/publications/codata-recommended-values-fundamental-physical-constants-2018) recommended values. These
reflect the new definitions of the kilogram and ampere as of 2019-05-20.
* [Gravitational constant](https://en.wikipedia.org/wiki/Gravitational_constant) as `gravitation-constant` and `G`.
* [Speed of light](https://en.wikipedia.org/wiki/Speed_of_light) as `speed-of-light-vacuum` and `c`. It works also as a suffix for expressing speeds, as in `3c` for 3 times the speed of light.
* [Planck constant and reduced constant](https://en.wikipedia.org/wiki/Planck_constant) in J/s as `plancks-h` or `ℎ` and `plancks-reduced-h` or `ℏ`.
* [Boltzmann constant](https://en.wikipedia.org/wiki/Boltzmann_constant) as `boltzmann-constant` or `k`. Previous versions of Math::Constants had this in eV. The value is now in standard SI units. The eV postfix operator can be used to get the previous value if needed.
* [Coulomb constant](https://en.wikipedia.org/wiki/Coulomb_constant) as `coulomb-constant` or `K0`.
* [Mass of an electron](https://en.wikipedia.org/wiki/Electron) as `electron-mass`.
* [Electron volt](https://en.wikipedia.org/wiki/Electronvolt) as `electron-volt` and `eV` or as an operator.
* [Elementary charge](https://en.wikipedia.org/wiki/Elementary_charge) as `elementary-charge` or `q`.
* [Faraday constant](https://en.wikipedia.org/wiki/Faraday_constant) as `faraday-constant` or `F`.
* [The fine structure constant](https://en.wikipedia.org/wiki/Fine_structure) as `fine-structure-constant` or `α`.
* [Gas constant](https://en.wikipedia.org/wiki/Gas_constant) as `gas-constant` or `R`.
* [Avogadro's constant](https://en.wikipedia.org/wiki/Avogadro_constant) as `avogadro-constant` or `L`.
* [Vacuum magnetic permeability](https://en.wikipedia.org/wiki/Vacuum_permeability) as `magnetic-permeability` or `μ0`.
* [Mass of a neutron](https://en.wikipedia.org/wiki/Neutron) as `neutron-mass`.
* [Planck length](https://en.wikipedia.org/wiki/Planck_length) as `planck-length` or `lp`.
* [Planck mass](https://en.wikipedia.org/wiki/Planck_mass) as `planck-mass` or `mp`.
* [Planck temperature](https://en.wikipedia.org/wiki/Planck_temperature) as `planck-temperature` or `Tp`.
* [Planck time](https://en.wikipedia.org/wiki/Planck_time) as `planck-time` or `tp`.
* [Mass of a proton](https://en.wikipedia.org/wiki/Proton) as `proton-mass`.
* The quantum ratio (elementary charge / Planck constant) as `quantum-ratio`.
* [Standard acceleration due to gravity](https://en.wikipedia.org/wiki/Standard_gravity) as `standard-acceleration-gravity` or `g`.
* [Vacuum electrical permittivity](https://en.wikipedia.org/wiki/Vacuum_permittivity) as `vacuum-permittivity` or `ε0`.
### Mathematical constants
* [Golden ratio](https://en.wikipedia.org/wiki/Golden_ratio) as `phi` or `φ`.
* [Feigenbaum constants](https://en.wikipedia.org/wiki/Feigenbaum_constants) as `alpha-feigenbaum-constant` and `delta-feigenbaum-constant` or `δ`.
* [Apéry's constant](https://en.wikipedia.org/wiki/Ap%C3%A9ry%27s_constant) as `apery-constant`.
* [Conway's constant](https://en.wikipedia.org/wiki/Look-and-say_sequence#Growth_in_length) as `conway-constant` and `λ`.
* [Khinchin's constant](https://en.wikipedia.org/wiki/Khinchin%27s_constant) as `khinchin-constant` and `k0`.
* [Glaisher–Kinkelin constant](https://en.wikipedia.org/wiki/Glaisher%E2%80%93Kinkelin_constant) as `glaisher-kinkelin-constant` and `A`.
* [Golomb–Dickman constant](https://en.wikipedia.org/wiki/Golomb%E2%80%93Dickman_constant) as `golomb-dickman-constant`.
* [Catalan's constant](https://en.wikipedia.org/wiki/Catalan%27s_constant) as `catalan-constant`.
* [Mill's constant](https://en.wikipedia.org/wiki/Mills%27_constant) as `mill-constant`.
* [Gauss's constant](https://en.wikipedia.org/wiki/Gauss%27s_constant) as `gauss-constant`.
* [Euler–Mascheroni constant](https://en.wikipedia.org/wiki/Euler%E2%80%93Mascheroni_constant) as `euler-mascheroni-gamma` and `γ`.
* [Sierpiński's constant](https://en.wikipedia.org/wiki/Sierpi%C5%84ski%27s_constant) as `sierpinski-gamma` and `K`.
* [iⁱ](https://oeis.org/A049006)
* [ζ(2)](https://oeis.org/A013661)
### Units
"Units" can be used as suffix; the number will be multiplied by its value
* `eV`, or electron-volts; `1.3eV` is 1.3 divided by the `eV` constant value.
* `c`, speed of light.
* `g`, gravitational constant.
# Issues and suggestions
Please post them [in GitHub](https://github.com/JJ/p6-math-constants/issues). Pull requests are also welcome.
# AUTHOR
* JJ Merelo [jjmerelo@gmail.com](mailto:jjmerelo@gmail.com)
* Kevin Pye [Kevin.Pye@gmail.com](mailto:Kevin.Pye@gmail.com)
* [`librasteve`](https://github.com/librasteve)
# COPYRIGHT AND LICENSE
Copyright 2016-2023 JJ Merelo
Copyright 2019 Kevin Pye
This library is free software; you can redistribute it and/or modify it under the GPL 3.0.
|
## iterationbuffer.md
class IterationBuffer
Low level storage of positional values
```raku
my class IterationBuffer { }
```
An `IterationBuffer` is used when the implementation of an [`Iterator`](/type/Iterator) class needs a lightweight way to store/transmit values. It doesn't make [`Scalar`](/type/Scalar) containers, and only supports mutation through the `BIND-POS` method, only supports adding values with the `push` and `unshift` methods, supports merging of two `IterationBuffer` objects with the `append` and `prepend` methods, and supports resetting with the `clear` method.
It can be coerced into a [`List`](/type/List), [`Slip`](/type/Slip), or [`Seq`](/type/Seq).
Values will be stored "as is", which means that [Junctions](/type/Junction) will be stored as such and will **not** [autothread](/language/glossary#Autothreading).
As of release 2021.12 of the Rakudo compiler, the `new` method also accepts an [`Iterable`](/type/Iterable) as an optional argument which will be used to fill the `IterationBuffer`.
# [Methods](#class_IterationBuffer "go to top of document")[§](#Methods "direct link")
## [method push](#class_IterationBuffer "go to top of document")[§](#method_push "direct link")
```raku
method push(IterationBuffer:D: Mu \value)
```
Adds the given value at the end of the `IterationBuffer` and returns the given value.
## [method unshift](#class_IterationBuffer "go to top of document")[§](#method_unshift "direct link")
```raku
method unshift(IterationBuffer:D: Mu \value)
```
Adds the given value at the beginning of the `IterationBuffer` and returns the given value. Available as of the 2021.12 release of the Rakudo compiler.
## [method append](#class_IterationBuffer "go to top of document")[§](#method_append "direct link")
```raku
method append(IterationBuffer:D: IterationBuffer:D $other --> IterationBuffer:D)
```
Adds the contents of the other `IterationBuffer` at the end of the `IterationBuffer`, and returns the updated invocant.
## [method prepend](#class_IterationBuffer "go to top of document")[§](#method_prepend "direct link")
```raku
method prepend(IterationBuffer:D: IterationBuffer:D $other --> IterationBuffer:D)
```
Adds the contents of the other `IterationBuffer` at the beginning of the `IterationBuffer`, and returns the updated invocant. Available as of the 2021.12 release of the Rakudo compiler.
## [method clear](#class_IterationBuffer "go to top of document")[§](#method_clear "direct link")
```raku
method clear(IterationBuffer:D: --> Nil)
```
Resets the number of elements in the `IterationBuffer` to zero, effectively removing all data from it, and returns [`Nil`](/type/Nil).
## [method elems](#class_IterationBuffer "go to top of document")[§](#method_elems "direct link")
```raku
method elems(IterationBuffer:D: --> Int:D)
```
Returns the number of elements in the `IterationBuffer`.
## [method AT-POS](#class_IterationBuffer "go to top of document")[§](#method_AT-POS "direct link")
```raku
multi method AT-POS(IterationBuffer:D: int $pos)
multi method AT-POS(IterationBuffer:D: Int:D $pos)
```
Returns the value at the given element position, or [`Mu`](/type/Mu) if the element position is beyond the length of the `IterationBuffer`, or an error will be thrown indicating the index is out of bounds (for negative position values).
## [method BIND-POS](#class_IterationBuffer "go to top of document")[§](#method_BIND-POS "direct link")
```raku
multi method BIND-POS(IterationBuffer:D: int $pos, Mu \value)
multi method BIND-POS(IterationBuffer:D: Int:D $pos, Mu \value)
```
Binds the given value at the given element position and returns it. The `IterationBuffer` is automatically lengthened if the given element position is beyond the length of the `IterationBuffer`. An error indicating the index is out of bounds will be thrown for negative position values.
## [method Slip](#class_IterationBuffer "go to top of document")[§](#method_Slip "direct link")
```raku
method Slip(IterationBuffer:D: --> Slip:D)
```
Coerces the `IterationBuffer` to a [`Slip`](/type/Slip).
## [method List](#class_IterationBuffer "go to top of document")[§](#method_List "direct link")
```raku
method List(IterationBuffer:D: --> List:D)
```
Coerces the `IterationBuffer` to a [`List`](/type/List).
## [method Seq](#class_IterationBuffer "go to top of document")[§](#method_Seq "direct link")
```raku
method Seq(IterationBuffer:D: --> Seq:D)
```
Coerces the `IterationBuffer` to a [`Seq`](/type/Seq).
## [method raku](#class_IterationBuffer "go to top of document")[§](#method_raku "direct link")
```raku
method raku(IterationBuffer:D: --> Str)
```
Produces a representation of the `IterationBuffer` as a [`List`](/type/List) postfixed with ".IterationBuffer" to make it different from an ordinary list. Does **not** roundtrip. Intended for debugging uses only, specifically for use with [dd](/programs/01-debugging#Dumper_function_(dd)).
|
## dist_cpan-BDUGGAN-Duckie.md
[](https://github.com/bduggan/raku-duckie/actions/workflows/linux.yml)
[](https://github.com/bduggan/raku-duckie/actions/workflows/macos.yml)
# NAME
Duckie - A wrapper and native bindings for DuckDB
# SYNOPSIS
```
use Duckie;
Duckie.new.query('select name from META6.json').rows[0]
# {name => Duckie}
my $db = Duckie.new;
say $db.query("select 1 as the_loneliest_number").column-data(0);
# [1]
with $db.query("select 1 as the_loneliest_number") -> $result {
say $result.column-data('the_loneliest_number'); # [1]
} else {
# Errors are soft failures
say "Failed to run query: $_";
}
# DuckDB can query or import data from CSV or JSON files, HTTP URLs,
# PostgreSQL, MySQL, SQLite databases and more.
my @cols = $db.query('select * from data.csv').columns;
my @rows = $db.query('select * from data.json').rows;
$db.query: q[ attach 'postgres://secret:pw@localhost/dbname' as pg (type postgres)]
$res = $db.query: "select * from pg.my_table"
$db.query("install httpfs");
$db.query("load httpfs");
$res = $db.query: "select * from 'http://example.com/data.csv'";
# Joins between different types are also possible.
$res = $db.query: q:to/SQL/
select *
from pg.my_table one
inner join 'http://example.com/data.csv' csv_data on one.id = csv_data.id
inner join 'data.json' json_data on one.id = json_data.id
SQL
```
# DESCRIPTION
This module provides Raku bindings for [DuckDB](https://duckdb.org/). DuckDB is a "fast in-process analytical database". It provides an SQL interface for a variety of data sources. Result sets are column-oriented, with a rich set of types that are either inferred, preserved, or explicitly defined. `Duckie` also provides a row-oriented API.
This module provides two sets of classes.
* `Duckie::DuckDB::Native` is a low-level interface that directly maps to the [C API](https://duckdb.org/docs/api/c/api.html). Note that a number of the function calls there are either deprecated or scheduled for deprecation, so the implementation of the Raku interface favors the more recent mechanisms where possible.
* `Duckie` provides a high level interface that handles things like memory management and native typecasting. While the Raku language supports native types, the results from `Duckie` do not currently expose them, preferring, for instance to return Integers instead of uint8s, int64s, etc, and using Rats for decimals, and Nums for floats. A future interface may expose native types.
# METHODS
### method new
```
method new(
:$file = ':memory:'
) returns Duckie
```
Create a new Duckie object. The optional `:file` parameter specifies the path to a file to use as a database. If not specified, an in-memory database is used. The database is opened and connected to when the object is created.
### method query
```
method query(
Str $sql
) returns Duckie::Result
```
Run a query and return a result. If the query fails, a soft failure is thrown.
### method DESTROY
```
method DESTROY() returns Mu
```
Close the database connection and free resources.
# SEE ALSO
* [Duckie::Result](https://github.com/bduggan/raku-duckie/blob/main/docs/lib/Duckie/Result.md)
* [Duckie::DuckDB::Native](https://github.com/bduggan/raku-duckie/blob/main/docs/lib/Duckie/DuckDB/Native.md)
# ENVIRONMENT
Set `DUCKIE_DEBUG` to a true value to enable logging to `STDERR`.
# AUTHOR
Brian Duggan
|
## dist_zef-lizmat-P5getnetbyname.md
[](https://github.com/lizmat/P5getnetbyname/actions)
# NAME
Raku port of Perl's getnetbyname() and associated built-ins
# SYNOPSIS
```
use P5getnetbyname;
# exports getnetbyname, getnetbyaddr, getnetent, setnetent, endnetent
say getnetbyaddr(Scalar, 127, 2); # something akin to loopback
my @result_byname = getnetbyname("loopback");
my @result_byaddr = getnetbyaddr(|@result_byname[4,3]);
```
# DESCRIPTION
This module tries to mimic the behaviour of Perl's `getnetbyname` and associated built-ins as closely as possible in the Raku Programming Language.
It exports by default:
```
endnetent getnetbyname getnetbyaddr getnetent setnetent
```
# ORIGINAL PERL 5 DOCUMENTATION
```
getnetbyname NAME
getnetbyaddr ADDR,ADDRTYPE
getnetent
setnetent STAYOPEN
endnetent
These routines are the same as their counterparts in the system C
library. In list context, the return values from the various get
routines are as follows:
# 0 1 2 3 4
( $name, $aliases, $addrtype, $net ) = getnet*
In scalar context, you get the name, unless the function was a
lookup by name, in which case you get the other thing, whatever it
is. (If the entry doesn't exist you get the undefined value.)
```
# PORTING CAVEATS
This module depends on the availability of POSIX semantics. This is generally not available on Windows, so this module will probably not work on Windows.
# AUTHOR
Elizabeth Mattijsen [liz@raku.rocks](mailto:liz@raku.rocks)
If you like this module, or what I’m doing more generally, committing to a [small sponsorship](https://github.com/sponsors/lizmat/) would mean a great deal to me!
Source can be located at: <https://github.com/lizmat/P5getnetbyname> . Comments and Pull Requests are welcome.
# COPYRIGHT AND LICENSE
Copyright 2018, 2019, 2020, 2021, 2022, 2023 Elizabeth Mattijsen
Re-imagined from Perl as part of the CPAN Butterfly Plan.
This library is free software; you can redistribute it and/or modify it under the Artistic License 2.0.
|
## dist_zef-jjmerelo-kazmath.md
# kazmath
This is an embryo of a NativeCall port of the [kazmath
library](https://github.com/Kazade/kazmath), which is a low-level library for
manipulation of graphics primitives. It's similar to others graphics
libraries such as OpenGL, but it's simpler and, in some cases, faster.
## Installing
You need to install kazmath from source (URL above), compiling it. Follow the
instructions to create a shared library.
Then you xan install this from this source or via
```
zef install kazmath
```
## Running
Since only some functions have been ported, basically you can rotate a vector
, like this:
```
my mat4 $one-mat .= new;
my mat4 $turn-pi = kmMat4RotationY($one-mat, pi/2);
say $turn-pi;
my vec4 $out .= new;
my vec4 $in .= new(1.Num, 0.Num, 0.Num, 1.Num);
my vec4 $result = kmVec4Transform( $out, $in, $turn-pi);
say $result;
```
## See also
Tutorial for [NativeCall](https://docs.raku.org/language/nativecall)
Also, this has been built mainly to be used as a recipe in the upcoming Raku
Recipes book by APress. Check out all [Raku titles in Apress such as this one.](https://www.apress.com/gp/book/9781484249550)
If you want to create a Dockerfile with `kazmath`, check out also the [`download -and-compile-kazmath.sh`](download-and-compile-kazmath.sh) included in this
repo, which can be useful to create the image.
## License
(c) JJ Merelo `jj@raku.org`, 2021-2022
This module is licensed under the Artistic 2.0 License (the same as Raku itself
)
|
## dist_zef-samy-App-Ebread.md
# ebread
**ebread** (**eb**ook **read**er) is a program that dumps the contents of an EPUB ebook to plain text. It accomplishes this via the HTML dump feature found in many text-mode web browsers, like `lynx`. The outputted text should be suitable for reading and piping into other programs for further processing.
## Installing
**ebread** should be able to run on most Unix-like operating systems, as long as they support the dependencies below. There is currently no plan to support Windows.
**ebread** requires the [rakudo](https://rakudoc.org/) compiler.
**ebread** depends on the following Raku modules, which can be installed via the [zef](https://github.com/ugexe/zef)) package manager.
* `File::Temp`
* `File::Which`
* `XML`
**ebread** also depends on the following system binaries to be installed:
* `unzip`
and at least one of the following text browsers:
* `elinks`
* `links`/`links2`
* `lynx`
* `w3m`
Once all of the necessary dependencies are installed, **ebread** can be installed via zef.
```
zef install .
```
## Usage
```
ebread [options] epub
```
By default, **ebread** will dump the text contents of a given EPUB to *stdout*. For more extensive documentation on the usage of **ebread**, you should consult the manual, which can be read either via [rakudoc](https://github.com/Raku/rakudoc) or **ebread**'s `--man` option.
```
rakudoc App::Ebread
ebread --man
```
## Copyright
Copyright 2024-2025, Samuel Young
This program is free software; you can redistribute it and/or modify it under the terms of the Artistic License 2.0.
|
## dist_zef-raku-community-modules-Math-Trig.md
[](https://github.com/raku-community-modules/Math-Trig/actions)
# NAME
Math::Trig - Trigonometric routines not already built-in
# SYNOPSIS
```
use Math::Trig;
```
# DESCRIPTION
Subroutines for coverting between degrees, radians, and gradians; converting between different coordinate systems (cartesian, spherical, cylindrical); and great circle formulas.
# SUBROUTINES
Available with `use Math::Trig`;
* sub rad2rad($rad)
* sub deg2deg($deg)
* sub grad2grad($grad)
* sub rad2deg($rad)
* sub deg2rad($deg)
* sub grad2deg($grad)
* sub deg2grad($deg)
* sub rad2grad($rad)
* sub grad2rad($grad)
* sub cartesian-to-spherical($x,$y,$z)
Available with `use Math::Trig :radial`;
* sub spherical-to-cartesian($rho, $theta, $phi)
* sub spherical-to-cylindrical($rho, $theta, $phi)
* sub cartesian-to-cylindrical($x,$y,$z)
* sub cylindrical-to-cartesian($rho, $theta, $z)
* sub cylindrical-to-spherical($rho, $theta, $phi)
Available with `use Math::Trig :great-circle`;
* sub great-circle-distance($theta0, $phi0, $theta1, $phi1, $rho = 1)
* sub great-circle-direction($theta0, $phi0, $theta1, $phi1)
* sub great-circle-bearing($theta0, $phi0, $theta1, $phi1)
* sub great-circle-waypoint($theta0, $phi0, $theta1, $phi1, $point = 0.5)
* sub great-circle-midpoint($theta0, $phi0, $theta1, $phi1)
* sub great-circle-destination($theta0, $phi0, $dir0, $dst)
# BUGS
* This is a work in progress. Caveat emptor.
* Perhaps rename this module since it's less about trigonometry and more about angular conversions and great circles?
# AUTHOR
Jonathan Scott Duff
Source can be located at: <https://github.com/raku-community-modules/Math-Trig> . Comments and Pull Requests are welcome.
# ACKNOWLEDGEMENTS
This module is shamelessly based on the [Perl module](https://metacpan.org/pod/Math::Trig) of the same name. Without the authors and maintainers of *that* module, this module wouldn't exist in this form.
# COPYRIGHT AND LICENSE
Copyright 2015 - 2017 Jonathan Scott Duff
Copyright 2018 - 2022 Raku Community
This library is free software; you can redistribute it and/or modify it under the Artistic License 2.0.
|
## dist_zef-antononcube-Proc-ZMQed.md
# Raku Proc::ZMQed
This package, "Proc::ZMQed", provides external evaluators (Julia, Mathematica, Python, R, etc.) via
[ZeroMQ (ZMQ)](https://zeromq.org).
Functionality-wise, a closely related Raku package is
["Text::CodeProcessing"](https://raku.land/zef:antononcube/Text::CodeProcessing),
[AAp1]. For example, Raku can be used in Mathematica sessions (i.e. notebooks) with [AAp1] and [AAp2]; see [AA1] for more details.
With this package, "Proc::ZMQed", we can use Mathematica in Raku sessions.
---
## Installation
From GitHub:
```
zef install https://github.com/antononcube/Raku-Proc-ZMQed.git
```
From [Zef ecosystem](https://raku.land):
```
zef install Proc::ZMQed
```
---
## Usage example: symbolic computation with Mathematica
*Mathematica is also known as Wolfram Language (WL).*
The following example shows:
* Establishing connection to [Wolfram Engine](https://www.wolfram.com/engine/) (which is free for developers.)
* Sending a formula for symbolic algebraic expansion.
* Getting the symbolic result and evaluating it as a Raku expression.
```
use Proc::ZMQed;
# Make object
my Proc::ZMQed::Mathematica $wlProc .= new(url => 'tcp://127.0.0.1', port => '5550');
# Start the process (i.e. Wolfram Engine)
$wlProc.start-proc;
my $cmd = 'Expand[(x+y)^4]';
my $wlRes = $wlProc.evaluate($cmd);
say "Sent : $cmd";
say "Got :\n $wlRes";
# Send computation to Wolfram Engine
# and get the result in Fortran form.
say '-' x 120;
$cmd = 'FortranForm[Expand[($x+$y)^4]]';
$wlRes = $wlProc.evaluate($cmd);
say "Sent : $cmd";
say "Got : $wlRes";
# Replace symbolic variables with concrete values
my $x = 5;
my $y = 3;
use MONKEY-SEE-NO-EVAL;
say 'EVAL($wlRes) : ', EVAL($wlRes);
# Terminate process
$wlProc.terminate;
```
```
# Sent : Expand[(x+y)^4]
# Got :
# 4 3 2 2 3 4
# x + 4 x y + 6 x y + 4 x y + y
# ------------------------------------------------------------------------------------------------------------------------
# Sent : FortranForm[Expand[($x+$y)^4]]
# Got : $x**4 + 4*$x**3*$y + 6*$x**2*$y**2 + 4*$x*$y**3 + $y**4
# EVAL($wlRes) : 4096
```
**Remark:** Mathematica can have variables that start with `$`, which is handy if we want to
treat WE results as Raku expressions.
Here is a corresponding flowchart:
```
graph TD
WE{{Wolfram Engine}}
Raku{{Raku}}
CO["Create connection object<br>(ZMQ sockets)"]
SC[Send symbolic computation<br>to Wolfram Engine]
AV[Assign values to symbols]
ES[Evaluate WE output string]
CO --> SC --> AV --> ES
SC -.- Raku
SC -.-> |ZMQ.send|WE
WE -.-> |ZMQ.recv|SC
CO -.- Raku
AV -.- Raku
ES -.- |EVAL|Raku
```
---
## Setup
In this section we outline setup for different programming languages as "servers."
Generally, there are two main elements to figure out:
* What is the concrete Command Line Interface (CLI) name to use?
* And related code option. E.g. `julia -e` or `wolframscript -code`.
* Is ZMQ installed on the server system?
The CLI names can be specified with the option `cli-name`.
The code options can be specified with `code-option`.
### Julia
In order to setup ZMQ computations with Julia start Julia and execute the commands:
```
using Pkg
Pkg.add("ZMQ")
Pkg.add("JSON")
```
(Also, see the instructions at ["Configure Julia for ExternalEvaluate"](https://reference.wolfram.com/language/workflow/ConfigureJuliaForExternalEvaluate.html).)
By default "Proc::ZMQed::Julia" uses the CLI name `julia`. Here is an alternative setup:
```
my Proc::ZMQed::Julia $juliaProc .= new(url => 'tcp://127.0.0.1',
port => '5560',
cli-name => '/Applications/Julia-1.8.app/Contents/Resources/julia/bin/julia');
```
### Mathematica
Install [Wolfram Engine (WE)](https://www.wolfram.com/engine/). (As it was mentioned above, WE is free for developers. WE has ZMQ functionalities "out of the box.")
Make sure `wolframscript` is installed. (This is the CLI name used with "Proc::ZMQed::Mathematica".)
### Python
Install the ZMQ library ["PyZMQ"](https://pypi.org/project/pyzmq/). For example, with:
```
python -m pip install --user pyzmq
```
By default "Proc::ZMQed::Python" uses the CLI name `python`.
Here we connect to a Python virtual environment (made and used with
[miniforge](https://github.com/conda-forge/miniforge)):
```
my Proc::ZMQed::Python $pythonProc .= new(url => 'tcp://127.0.0.1',
port => '5554',
cli-name => $*HOME ~ '/miniforge3/envs/SciPyCentric/bin/python');
```
---
## Implementation details
The package architecture is Object-Oriented Programming (OOP) based and it is a combination of the OOP design patterns
Builder, Template Method, and Strategy.
The package has a general role "Proc::ZMQed::Abstraction" that plays Abstract class in Template method.
The concrete programming language of the classes provide concrete operations for:
* ZMQ-server side code
* Processing of setup code lines
Here is the corresponding UML diagram:
```
use UML::Translators;
to-uml-spec(<Proc::ZMQed::Abstraction Proc::ZMQed::Julia Proc::ZMQed::Mathematica Proc::ZMQed::Python Proc::ZMQed::R Proc::ZMQed::Raku>, format=>'mermaid');
```
```
classDiagram
class Proc_ZMQed_Julia {
+$!cli-name
+$!code-option
+$!context
+$!port
+$!proc
+$!receiver
+$!url
+BUILD()
+BUILDALL()
+cli-name()
+code-option()
+context()
+evaluate()
+make-code()
+port()
+proc()
+process-setup-lines()
+receiver()
+start-proc()
+terminate()
+url()
}
Proc_ZMQed_Julia --|> Proc_ZMQed_Abstraction
class Proc_ZMQed_Mathematica {
+$!cli-name
+$!code-option
+$!context
+$!port
+$!proc
+$!receiver
+$!url
+BUILD()
+BUILDALL()
+cli-name()
+code-option()
+context()
+evaluate()
+make-code()
+port()
+proc()
+process-setup-lines()
+receiver()
+start-proc()
+terminate()
+url()
}
Proc_ZMQed_Mathematica --|> Proc_ZMQed_Abstraction
class Proc_ZMQed_Python {
+$!cli-name
+$!code-option
+$!context
+$!port
+$!proc
+$!receiver
+$!url
+BUILD()
+BUILDALL()
+cli-name()
+code-option()
+context()
+evaluate()
+make-code()
+port()
+proc()
+process-setup-lines()
+receiver()
+start-proc()
+terminate()
+url()
}
Proc_ZMQed_Python --|> Proc_ZMQed_Abstraction
class Proc_ZMQed_R {
+$!cli-name
+$!code-option
+$!context
+$!port
+$!proc
+$!receiver
+$!url
+BUILD()
+BUILDALL()
+cli-name()
+code-option()
+context()
+evaluate()
+make-code()
+port()
+proc()
+process-setup-lines()
+receiver()
+start-proc()
+terminate()
+url()
}
Proc_ZMQed_R --|> Proc_ZMQed_Abstraction
class Proc_ZMQed_Raku {
+$!cli-name
+$!code-option
+$!context
+$!port
+$!proc
+$!receiver
+$!url
+BUILD()
+BUILDALL()
+cli-name()
+code-option()
+context()
+evaluate()
+make-code()
+port()
+proc()
+process-setup-lines()
+receiver()
+start-proc()
+terminate()
+url()
}
Proc_ZMQed_Raku --|> Proc_ZMQed_Abstraction
```
(Originally, "Proc::ZMQed::Abstraction" was named "Proc::ZMQish", but the former seems a better fit for the role.)
The ZMQ connections are simple REP/REQ. It is envisioned that more complicated ZMQ patterns can be implemented in
subclasses. I have to say though, that my attempts to implement
["Lazy Pirate"](https://zguide.zeromq.org/docs/chapter4/)
were very unsuccessful because of the half-implemented (or missing) polling functionalities in [ASp1].
(See the comments [here](https://github.com/arnsholt/Net-ZMQ/blob/master/lib/Net/ZMQ4/Poll.pm6).)
---
## TODO
1. TODO Robust, comprehensive ZMQ-related failures handling.
2. TODO More robust ZMQ patterns.
* Like the "Lazy Pirate" mentioned above.
3. TODO Implement "Proc::ZMQed::Java".
4. TODO Better message processing in "Proc::ZMQed::R".
5. TODO Verify that "Proc::ZMQed::JavaScript" is working.
* Currently, I have problems install ZMQ in JavaScript.
---
## References
### Articles
[AA1] Anton Antonov,
["Connecting Mathematica and Raku"](https://rakuforprediction.wordpress.com/2021/12/30/connecting-mathematica-and-raku/),
(2021),
RakuForPrediction at WordPress.
### Packages
[AAp1] Anton Antonov
[Text::CodeProcessing Raku package](https://github.com/antononcube/Raku-Text-CodeProcessing),
(2021-2022),
[GitHub/antononcube](https://github.com/antononcube).
[AAp2] Anton Antonov,
[RakuMode Mathematica package](https://github.com/antononcube/ConversationalAgents/blob/master/Packages/WL/RakuMode.m),
(2020-2021),
[ConversationalAgents at GitHub/antononcube](https://github.com/antononcube/ConversationalAgents).
[ASp1] Arne Skjærholt,
[Net::ZMQ](https://github.com/arnsholt/Net-ZMQ),
(2017),
[GitHub/arnsholt](https://github.com/arnsholt).
|
## dist_zef-lizmat-P5shift.md
[](https://github.com/lizmat/P5shift/actions)
# NAME
Raku port of Perl's shift() / unshift() built-ins
# SYNOPSIS
```
use P5shift;
say shift; # shift from @*ARGS, if any
sub a { dd @_; dd shift; dd @_ }; a 1,2,3;
[1, 2, 3]
1
[2, 3]
my @a = 1,2,3;
say unshift @a, 42; # 4
```
# DESCRIPTION
This module tries to mimic the behaviour of Perl's `shift` and `unshift` built-ins as closely as possible in the Raku Programming Language.
# ORIGINAL PERL DOCUMENTATION
```
shift ARRAY
shift EXPR
shift Shifts the first value of the array off and returns it, shortening
the array by 1 and moving everything down. If there are no
elements in the array, returns the undefined value. If ARRAY is
omitted, shifts the @_ array within the lexical scope of
subroutines and formats, and the @ARGV array outside a subroutine
and also within the lexical scopes established by the "eval
STRING", "BEGIN {}", "INIT {}", "CHECK {}", "UNITCHECK {}", and
"END {}" constructs.
Starting with Perl 5.14, "shift" can take a scalar EXPR, which
must hold a reference to an unblessed array. The argument will be
dereferenced automatically. This aspect of "shift" is considered
highly experimental. The exact behaviour may change in a future
version of Perl.
To avoid confusing would-be users of your code who are running
earlier versions of Perl with mysterious syntax errors, put this
sort of thing at the top of your file to signal that your code
will work [4monly[m on Perls of a recent vintage:
use 5.014; # so push/pop/etc work on scalars (experimental)
See also "unshift", "push", and "pop". "shift" and "unshift" do
the same thing to the left end of an array that "pop" and "push"
do to the right end.
unshift ARRAY,LIST
unshift EXPR,LIST
Does the opposite of a "shift". Or the opposite of a "push",
depending on how you look at it. Prepends list to the front of the
array and returns the new number of elements in the array.
unshift(@ARGV, '-e') unless $ARGV[0] =~ /^-/;
Note the LIST is prepended whole, not one element at a time, so
the prepended elements stay in the same order. Use "reverse" to do
the reverse.
Starting with Perl 5.14, "unshift" can take a scalar EXPR, which
must hold a reference to an unblessed array. The argument will be
dereferenced automatically. This aspect of "unshift" is considered
highly experimental. The exact behaviour may change in a future
version of Perl.
To avoid confusing would-be users of your code who are running
earlier versions of Perl with mysterious syntax errors, put this
sort of thing at the top of your file to signal that your code
will work only on Perls of a recent vintage:
use 5.014; # so push/pop/etc work on scalars (experimental)
```
# PORTING CAVEATS
In future language versions of Raku, it will become impossible to access the `@_` variable of the caller's scope, because it will not have been marked as a dynamic variable. So please consider changing:
```
shift;
```
to:
```
shift(@_);
```
or, using the subroutine as a method syntax:
```
@_.&shift;
```
# AUTHOR
Elizabeth Mattijsen [liz@raku.rocks](mailto:liz@raku.rocks)
If you like this module, or what I’m doing more generally, committing to a [small sponsorship](https://github.com/sponsors/lizmat/) would mean a great deal to me!
Source can be located at: <https://github.com/lizmat/P5shift> . Comments and Pull Requests are welcome.
# COPYRIGHT AND LICENSE
Copyright 2018, 2019, 2020, 2021, 2023 Elizabeth Mattijsen
Re-imagined from Perl as part of the CPAN Butterfly Plan.
This library is free software; you can redistribute it and/or modify it under the Artistic License 2.0.
|
## nfkd.md
class NFKD
Codepoint string in Normal Form KD (compatibility decomposed)
```raku
class NFKD is Uni {}
```
A Codepoint string in Unicode Normalization Form KD. It is created by Compatibility Decomposition. For more information on what this means, see [Unicode TR15](https://www.unicode.org/reports/tr15/).
# [Typegraph](# "go to top of document")[§](#typegraphrelations "direct link")
Type relations for `NFKD`
raku-type-graph
NFKD
NFKD
Uni
Uni
NFKD->Uni
Mu
Mu
Any
Any
Any->Mu
Positional
Positional
Stringy
Stringy
Uni->Any
Uni->Positional
Uni->Stringy
[Expand chart above](/assets/typegraphs/NFKD.svg)
|
## dist_zef-hythm-Retry.md
# Name
Retry - Retry action
# Synopsis
```
use Retry;
retry { action }, :4max, :2delay;
retry { say 'trying!'; die }, :max(-1), :delay({ constant @fib = 0, 1, *+* ... *; @fib[$++] });
```
# Description
Retry is a module that exports `retry` sub which takes a `Block` to retry execute until success and return the result. or in case of `Exception`, rethrow after `max` retries.
`max` defaults to `4`. sets the max number of retries. Use `Inf`, `*` or integer smaller 0 to retry forever.
`delay` defaults to `0.2`. sets the delay between retries. The delay doubles with every retry. Use a `Code` object to provide your own stepping. Each call must return a `Real`.
# Acknowledgements
Thanks to gfldex for improving the module by allowing passing `Callable` to `delay`, also allow using `Inf` and `Whatever`. and improving tests as well.
# Author
Haytham Elganiny [elganiny.haytham@gmail.com](mailto:elganiny.haytham@gmail.com)
# Copyright and License
Copyright 2020 Haytham Elganiny
This library is free software; you can redistribute it and/or modify it under the Artistic License 2.0.
|
## dist_zef-raku-community-modules-Config-INI.md
[](https://github.com/raku-community-modules/Config-INI/actions) [](https://github.com/raku-community-modules/Config-INI/actions) [](https://github.com/raku-community-modules/Config-INI/actions)
# NAME
Config::INI - parse standard configuration files (.ini files)
# SYNOPSIS
```
use Config::INI;
my %hash = Config::INI::parse_file('config.ini');
#or
%hash = Config::INI::parse($file_contents);
say %hash<_><root_property_key>;
say %hash<section><in_section_key>;
```
# DESCRIPTION
This module provides 2 functions: parse() and parse\_file(), both taking one `Str` argument, where parse\_file is just parse(slurp $file). Both return a hash which keys are either toplevel keys or a section names. For example, the following config file:
```
foo=bar
[section]
another=thing
```
would result in the following hash:
```
{ '_' => { foo => "bar" }, section => { another => "thing" } }
```
# AUTHORS
Tadeusz Sośnierz
Nobuo Danjou
# COPYRIGHT AND LICENSE
Copyright 2010 - 2017 Tadeusz Sośnierz
Copyright 2024 Raku Community
This library is free software; you can redistribute it and/or modify it under the Artistic License 2.0.
|
## dist_zef-lizmat-JSON-Fast-Hyper.md
[](https://github.com/lizmat/JSON-Fast-Hyper/actions) [](https://github.com/lizmat/JSON-Fast-Hyper/actions) [](https://github.com/lizmat/JSON-Fast-Hyper/actions)
# NAME
JSON::Fast::Hyper - Read/Write hyperable JSON
# SYNOPSIS
```
use JSON::Fast::Hyper;
my $json = to-json(@array); # creates faster hyperable JSON
my $json = to-json(%hash); # normal JSON
my @array = from-json($json); # 2x faster if hyperable JSON
my %hash := from-json($json); # normal speed
```
# DESCRIPTION
JSON::Fast::Hyper is a drop-in wrapper for `JSON::Fast`. It provides the same interface as `JSON::Fast`, with two differences:
## CONVERTING A LIST TO JSON
```
my $json = to-json(@array); # creates faster hyperable JSON
```
When a list is converted to JSON, it will create a special hyperable version of JSON that is still completely valid JSON for all JSON parsers, but which can be interpreted in parallel when reading back. To allow this feature, the JSON will be created ignoring the `:pretty` named argument.
If your data structure is **not** a `Positional`, then it will just act as the normal `to-json` sub from `JSON::Fast`.
## CONVERTING JSON OF A LIST TO DATA STRUCTURE
```
my @array := from-json($json); # 2x faster if hyperable JSON
```
When the JSON was created hyperable, then reading such JSON with `from-json` will return the original `Positional` as a `List`. If the JSON was not hyperable, it will call the normal `from-json` sub from `JSON::Fast`.
# TECHNICAL BACKGROUND
This module makes the `to-json` and `from-json` exported subs of `JSON::Fast` into a multi. It adds a candidate taking a `Positional` to `to-json`, and it adds a candidate to `from-json` that takes the specially formatted string created by that extra `to-json` candidate.
The `Positional` candidate of `to-json` will create the JSON for each of the elements separately, and joins them together with an additional newline. And then adds a specially formatted header and footer to the result. The resulting string is still valid JSON, readable by any JSON decoder. But when run through the `from-json` sub provided by this module, will decode elements in parallel. Wallclock times are at about 45% (aka 2.2x as fast) for a 13MB JSON file, such as provided by the Raku Ecosystem Archive. While only adding `3 + number of elements` bytes to the resulting string.
A similar approach could be done for handling an `Associative` at the top level. But this makes generally a lot less sense, as the amount of information per key/value is usually vastly different, and JSON that consists of an `Associative` at the top, are usually not big enough to warrant the overhead of hypering.
# AUTHOR
Elizabeth Mattijsen [liz@raku.rocks](mailto:liz@raku.rocks)
Source can be located at: <https://github.com/lizmat/JSON-Fast-Hyper> . Comments and Pull Requests are welcome.
If you like this module, or what I’m doing more generally, committing to a [small sponsorship](https://github.com/sponsors/lizmat/) would mean a great deal to me!
# COPYRIGHT AND LICENSE
Copyright 2022, 2023, 2024, 2025 Elizabeth Mattijsen
This library is free software; you can redistribute it and/or modify it under the Artistic License 2.0.
|
## open.md
open
Combined from primary sources listed below.
# [In IO::Handle](#___top "go to top of document")[§](#(IO::Handle)_method_open "direct link")
See primary documentation
[in context](/type/IO/Handle#method_open)
for **method open**.
```raku
method open(IO::Handle:D:
:$r, :$w, :$x, :$a, :$update,
:$rw, :$rx, :$ra,
:$mode is copy,
:$create is copy,
:$append is copy,
:$truncate is copy,
:$exclusive is copy,
:$bin,
:$enc is copy,
:$chomp = $!chomp,
:$nl-in is copy = $!nl-in,
Str:D :$nl-out is copy = $!nl-out,
:$out-buffer is copy,
)
```
Opens the handle in one of the modes. [Fails](/routine/fail) with appropriate exception if the open fails.
See description of individual methods for the accepted values and behavior of [`:$chomp`](/type/IO/Handle#method_chomp), [`:$nl-in`](/type/IO/Handle#method_nl-in), [`:$nl-out`](/type/IO/Handle#method_nl-out), and [`:$enc`](/type/IO/Handle#method_encoding). The values for parameters default to the invocant's attributes and if any of them are provided, the attributes will be updated to the new values. Specify `:$bin` set to `True` instead of `:$enc` to indicate the handle should be opened in binary mode. Specifying undefined value as `:$enc` is equivalent to not specifying `:$enc` at all. Specifying both a defined encoding as `:$enc` and `:$bin` set to true will cause `X::IO::BinaryAndEncoding` exception to be thrown.
The open mode defaults to non-exclusive, read only (same as specifying `:r`) and can be controlled by a mix of the following arguments:
「text」 without highlighting
```
```
:r same as specifying :mode<ro> same as specifying nothing
:w same as specifying :mode<wo>, :create, :truncate
:a same as specifying :mode<wo>, :create, :append
:x same as specifying :mode<wo>, :create, :exclusive
:update same as specifying :mode<rw>
:rw same as specifying :mode<rw>, :create
:ra same as specifying :mode<rw>, :create, :append
:rx same as specifying :mode<rw>, :create, :exclusive
```
```
Argument `:r` along with `:w`, `:a`, `:x` are exactly the same as the combination of both letters, shown in the three last rows in the table above. Support for combinations of modes *other* than what is listed above is implementation-dependent and should be assumed unsupported. That is, specifying, for example, `.open(:r :create)` or `.open(:mode<wo> :append :truncate)` might work or might cause the Universe to implode, depending on a particular implementation. This applies to reads/writes to a handle opened in such unsupported modes as well.
The mode details are:
「text」 without highlighting
```
```
:mode<ro> means "read only"
:mode<wo> means "write only"
:mode<rw> means "read and write"
:create means the file will be created, if it does not exist
:truncate means the file will be emptied, if it exists
:exclusive means .open will fail if the file already exists
:append means writes will be done at the end of file's current contents
```
```
Attempts to open a directory, write to a handle opened in read-only mode or read from a handle opened in write-only mode, or using text-reading methods on a handle opened in binary mode will fail or throw.
In **6.c** language, it's possible to open path `'-'`, which will cause `open` to open (if `closed`) the `$*IN` handle if opening in read-only mode or to open the `$*OUT` handle if opening in write-only mode. All other modes in this case will result in exception being thrown.
As of **6.d** language version, the use of path `'-'` is deprecated and it will be removed in future language versions entirely.
The `:out-buffer` controls output buffering and by default behaves as if it were [`Nil`](/type/Nil). See method [out-buffer](/routine/out-buffer) for details.
**Note (Rakudo versions before 2017.09): Filehandles are NOT flushed or closed when they go out of scope**. While they *will* get closed when garbage collected, garbage collection isn't guaranteed to get run. This means *you should* use an explicit `close` on handles opened for writing, to avoid data loss, and an explicit `close` is *recommended* on handles opened for reading as well, so that your program does not open too many files at the same time, triggering exceptions on further `open` calls.
**Note (Rakudo versions 2017.09 and after):** Open filehandles are automatically closed on program exit, but it is still highly recommended that you `close` opened handles explicitly.
# [In IO::CatHandle](#___top "go to top of document")[§](#(IO::CatHandle)_method_open "direct link")
See primary documentation
[in context](/type/IO/CatHandle#method_open)
for **method open**.
```raku
method open(IO::CatHandle:D: --> IO::CatHandle:D)
```
Returns the invocant. The intent of this method is to merely make CatHandle workable with things that open [`IO::Handle`](/type/IO/Handle). You never have to call this method intentionally.
# [In IO::Path](#___top "go to top of document")[§](#(IO::Path)_method_open "direct link")
See primary documentation
[in context](/type/IO/Path#method_open)
for **method open**.
```raku
method open(IO::Path:D: *%opts)
```
Opens the path as a file; the named options control the mode, and are the same as the [open](/routine/open) function accepts.
# [In Independent routines](#___top "go to top of document")[§](#(Independent_routines)_sub_open "direct link")
See primary documentation
[in context](/type/independent-routines#sub_open)
for **sub open**.
```raku
multi open(IO() $path, |args --> IO::Handle:D)
```
Creates [a handle](/type/IO/Handle) with the given `$path`, and calls [`IO::Handle.open`](/type/IO/Handle#method_open), passing any of the remaining arguments to it. Note that [`IO::Path`](/type/IO/Path) type provides numerous methods for reading and writing from files, so in many common cases you do not need to `open` files or deal with [`IO::Handle`](/type/IO/Handle) type directly.
```raku
my $fh = open :w, '/tmp/some-file.txt';
$fh.say: 'I ♥ writing Raku code';
$fh.close;
$fh = open '/tmp/some-file.txt';
print $fh.readchars: 4;
$fh.seek: 7, SeekFromCurrent;
say $fh.readchars: 4;
$fh.close;
# OUTPUT: «I ♥ Raku»
```
|
## dist_cpan-MELEZHIK-Sparrowdo-Goss.md
# SYNOPSIS
Sparrowdo module to run goss scenarios.
# Travis build status
[](https://travis-ci.org/melezhik/sparrowdo-goss)
# INSTALL
```
$ zef install Sparrowdo::Goss
```
# USAGE
Here are few examples.
## Install goss binary
```
$ cat mysql.goss.yaml
module-run 'Goss', %( action => 'install' ); # will install into default location - /usr/bin/goss
module-run 'Goss', %( action => 'install', install_path => '/home/user' ); # will install into users location - /home/user/bin
```
## Runs goss scenarios
Pass goss yaml as is:
```
$ cat mysql.goss.yaml
module-run 'Goss', %( title => 'mysql checks', yaml => << q:to/HERE/);
port:
tcp:3306:
listening: true
ip:
- 127.0.0.1
service:
mysql:
enabled: true
running: true
process:
mysqld:
running: true
HERE
```
Use your favorite templater to populate goss yamls:
```
$ cat mysql.goss.yaml
port:
tcp:{{port}}:
listening: true
$ cat sparrowfile
use Template::Mustache;
module-run 'Goss', %(
title => 'mysql tcp port check',
yaml => Template::Mustache.render('mysql.goss.yaml'.IO.slurp, { port => '3306' })
);
```
Sets path to goss binary:
```
module-run 'Goss', %( install_path => '/home/user', yaml => '...', title => '...' );
```
# Author
Alexey Melezhik
# See also
[goss](https://github.com/aelsabbahy/goss)
|
## nyi.md
class X::NYI
Error due to use of an unimplemented feature
```raku
class X::NYI is Exception { }
```
Error class for unimplemented features. *NYI* stands for *Not Yet Implemented*.
If a Raku compiler is not yet feature complete, it may throw an `X::NYI` exception when a program uses a feature that it can detect and is somehow specified is not yet implemented.
A full-featured Raku compiler must not throw such exceptions, but still provide the `X::NYI` class for compatibility reasons.
A typical error message is
「text」 without highlighting
```
```
HyperWhatever is not yet implemented. Sorry.
```
```
# [Methods](#class_X::NYI "go to top of document")[§](#Methods "direct link")
## [method new](#class_X::NYI "go to top of document")[§](#method_new "direct link")
```raku
method new( :$feature, :$did-you-mean, :$workaround)
```
This is the default constructor for `X:NYI` which can take three parameters with obvious meanings.
```raku
class Nothing {
method ventured( $sub, **@args) {
X::NYI.new( feature => &?ROUTINE.name,
did-you-mean => "gained",
workaround => "Implement it yourself" ).throw;
}
}
my $nothing = Nothing.new;
$nothing.ventured("Nothing", "Gained");
```
In this case, we are throwing an exception that indicates that the `ventured` routine has not been implemented; we use the generic `&?ROUTINE.name` to not tie the exception to the method name in case it is changed later on. This code effectively throws this exception
```raku
# OUTPUT:
# ventured not yet implemented. Sorry.
# Did you mean: gained?
# Workaround: Implement it yourself
# in method ventured at NYI.raku line 6
# in block <unit> at NYI.raku line 14
```
Using the exception properties, it composes the message that we see there.
## [method feature](#class_X::NYI "go to top of document")[§](#method_feature "direct link")
Returns a [`Str`](/type/Str) describing the missing feature.
## [method did-you-mean](#class_X::NYI "go to top of document")[§](#method_did-you-mean "direct link")
Returns a [`Str`](/type/Str) indicating the optional feature that is already implemented.
## [method workaround](#class_X::NYI "go to top of document")[§](#method_workaround "direct link")
It helpfully shows a possible workaround for the missing feature, if it's been declared.
## [method message](#class_X::NYI "go to top of document")[§](#method_message "direct link")
Returns the message including the above properties.
|
## label.md
class Label
Tagged location in the source code
```raku
class Label {}
```
Labels are used in Raku to tag loops so that you can specify the specific one you want to jump to with [statements such as `last`](/language/control#LABELs). You can use it to jump out of loops and get to outer ones, instead of just exiting the current loop or going to the previous statement.
```raku
USERS: # the label
for @users -> $u {
for $u.pets -> $pet {
# usage of a label
next USERS if $pet.barks;
}
say "None of {$u}'s pets barks";
}
say USERS.^name; # OUTPUT: «Label»
```
Those labels are objects of type `Label`, as shown in the last statement. Labels can be used in any loop construct, as long as they appear right before the loop statement.
```raku
my $x = 0;
my $y = 0;
my $t = '';
A: while $x++ < 2 {
$t ~= "A$x";
B: while $y++ < 2 {
$t ~= "B$y";
redo A if $y++ == 1;
last A
}
}
say $t; # OUTPUT: «A1B1A1A2»
```
Putting them on the line before the loop or the same line is optional. `Label`s must follow the syntax of [ordinary identifiers](/language/syntax#Ordinary_identifiers), although traditionally we will use the latin alphabet in uppercase so that they stand out in the source. You can use, however, other alphabets like here:
```raku
駱駝道: while True {
say 駱駝道.name;
last 駱駝道;
} # OUTPUT: «駱駝道»
```
# [Methods](#class_Label "go to top of document")[§](#Methods "direct link")
## [method name](#class_Label "go to top of document")[§](#method_name "direct link")
Not terribly useful, returns the name of the defined label:
```raku
A: while True {
say A.name; # OUTPUT: «A»
last A;
}
```
## [method file](#class_Label "go to top of document")[§](#method_file "direct link")
Returns the file the label is defined in.
## [method line](#class_Label "go to top of document")[§](#method_line "direct link")
Returns the line where the label has been defined.
## [method Str](#class_Label "go to top of document")[§](#method_Str "direct link")
Converts to a string including the name, file and line it's been defined in.
## [method next](#class_Label "go to top of document")[§](#method_next "direct link")
```raku
method next(Label:)
```
Begin the next iteration of the loop associated with the label.
```raku
MY-LABEL:
for 1..10 {
next MY-LABEL if $_ < 5;
print "$_ ";
}
# OUTPUT: «5 6 7 8 9 10 »
```
## [method redo](#class_Label "go to top of document")[§](#method_redo "direct link")
```raku
method redo(Label:)
```
Repeat the same iteration of the loop associated with the label.
```raku
my $has-repeated = False;
MY-LABEL:
for 1..10 {
print "$_ ";
if $_ == 5 {
LEAVE $has-repeated = True;
redo MY-LABEL unless $has-repeated;
}
}
# OUTPUT: «1 2 3 4 5 5 6 7 8 9 10 »
```
## [method last](#class_Label "go to top of document")[§](#method_last "direct link")
```raku
method last(Label:)
```
Terminate the execution of the loop associated with the label.
```raku
MY-LABEL:
for 1..10 {
last MY-LABEL if $_ > 5;
print "$_ ";
}
# OUTPUT: «1 2 3 4 5 »
```
# [Typegraph](# "go to top of document")[§](#typegraphrelations "direct link")
Type relations for `Label`
raku-type-graph
Label
Label
Any
Any
Label->Any
Mu
Mu
Any->Mu
[Expand chart above](/assets/typegraphs/Label.svg)
|
## dist_zef-melezhik-SparrowCI-SandBox.md
# sparrowci-sandbox
The only purpose of this module is to demonstrate
usage of SparrowCI pipeline in Raku module automation.
# sparrow.yaml
This pipeline runs `zef test` and then
if a commit message contains `release!` string
uploads a module via `fez upload`.
Pipeline requires fez token set as secret
in user's account in SparrowCI.
```
image:
- melezhik/sparrow:debian
secrets:
- FEZ_TOKEN
tasks:
-
name: test
default: true
followup:
-
name: release
language: Bash
code: |
set -e
env|grep SCM
cd source
zef test .
-
name: release
if:
language: Raku
code: |
update_state %( status => 'skip' )
unless %*ENV<SCM_COMMIT_MESSAGE> ~~ /'release!'/;
language: Bash
code: |
set -e
cat << HERE > ~/.fez-config.json
{"groups":[],"un":"melezhik","key":"$FEZ_TOKEN"}
HERE
cd source/
zef install --/test fez
tom --clean
fez upload --unattended
```
# Author
Alexey Melezhik
|
## dist_github-MattOates-Math-FourierTransform.md
# Math--FourierTransform [Build Status](https://travis-ci.org/MattOates/Math--FourierTransform)
Discrete Fourier Transform for Perl 6
```
use Math::FourierTransform;
@spectrum = discrete-fourier-transform(@data);
```
|
## dist_cpan-JMERELO-Syslog-Parse.md
[](https://travis-ci.com/JJ/raku-syslog-parse)

# NAME
Syslog::Parse - Creates a supply out of syslog entries
# SYNOPSIS
```
use Syslog::Parse;
use Syslog::Parse;
my $parser = Syslog::Parse.new;
$parser.parsed.tap: -> $v {
say $v;
}
sleep( @*ARGS[0] // 120 );
```
Or
```
use Syslog::Parse;
my $parser = Syslog::Parse.new;
Promise.at(now+1).then: {
shell "logger logging $_" for ^10;
};
react {
whenever $parser.parsed -> %v {
say %v;
done(); # Just interested in the last one
}
}
```
Also, you can run
```
watch-syslog.p6
```
which is going ot be installed with the distribution.
# DESCRIPTION
Syslog::Parse is a parser that extracts information from every line in `/var/log/syslog`. Creates two objects of the kind `Supply`: one (simply called `.supply` that returns the raw lines, another, `.parsed`, which returns a structure with the following keys:
```
day # Day in the month
month # TLA of month
hour # String with hour
hostname # Hostname that produced it
actor # Who produced the message log
pid # Sometimes, it goes with a PID
message # Another data structure, with key message (the whole message) and
# user if one has been dentified
```
## PLATFORMS
It works on platforms that use `/var/log/syslog` as a syslog file,
with the same format. All Debian seem to be that way.
If you don't have that platform, you can still use the grammars on
files with that format.
# AUTHOR
JJ Merelo [jjmerelo@gmail.com](mailto:jjmerelo@gmail.com)
# COPYRIGHT AND LICENSE
Copyright 2020 JJ Merelo
This library is free software; you can redistribute it and/or modify it under the Artistic License 2.0.
|
## class.md
class
Combined from primary sources listed below.
# [In Object orientation](#___top "go to top of document")[§](#(Object_orientation)_class_class "direct link")
See primary documentation
[in context](/language/objects#Classes)
for **Classes**.
Classes are declared using the `class` keyword, typically followed by a name.
```raku
class Journey { }
```
This declaration results in a type object being created and installed in the current package and current lexical scope under the name `Journey`. You can also declare classes lexically:
```raku
my class Journey { }
```
This restricts their visibility to the current lexical scope, which can be useful if the class is an implementation detail nested inside a module or another class.
# [In Classes and objects](#___top "go to top of document")[§](#(Classes_and_objects)_class_class "direct link")
See primary documentation
[in context](/language/classtut#Class)
for **Class**.
Raku, like many other languages, uses the `class` keyword to define a class. The block that follows may contain arbitrary code, just as with any other block, but classes commonly contain state and behavior declarations. The example code includes attributes (state), introduced through the `has` keyword, and behaviors, introduced through the `method` keyword.
|
## dist_zef-colomon-ABC.md
```
This module is a set of tools for dealing with ABC music files in Raku (formerly known as Perl 6).
There are several scripts in bin/ built on the library:
* abc2ly: converts an ABC file to the Lilypond ly format, then invokes Lilypond on it to create high quality sheet music. If you install ABC using zef you should just be able to say
abc2ly wedding.abc
to convert wedding.abc to wedding.ly and then invoke Lilypond to convert it to
wedding.pdf.
NOTE: Lilypond also has an abc2ly script; last time I tried it it produced
hideous looking output from Lilypond. If you've got both installed, you will
have to make sure the Raku bin of abc2ly appears first in your PATH.
* abc2book: Given an ABC file and a “book” file, this makes a book PDF. This uses Lilypond for music formatting, LaTeX for table of contents and index of tunes, and qpdf to stitch the results together into one file.
* abctranspose: Does just what the name implies.
As of 7/6/2020, it works with every recent version of Raku I’ve tried.
```
|
## dist_zef-raku-community-modules-Dice-Roller.md
[](https://github.com/raku-community-modules/Dice-Roller/actions) [](https://github.com/raku-community-modules/Dice-Roller/actions) [](https://github.com/raku-community-modules/Dice-Roller/actions)
# NAME
Dice::Roller - Roll RPG-style polyhedral dice
# SYNOPSIS
```
use Dice::Roller;
my $dice = Dice::Roller.new("2d6 + 1");
$dice.roll;
say $dice.total; # 4. Chosen by fair dice roll.
$dice.set-max;
say $dice.total; # 13
```
# DESCRIPTION
Dice::Roller is the second of my forays into learning Raku. The aim is simple - take a "dice string" representing a series of RPG-style dice to be rolled, plus any modifiers, parse it, and get Raku to virtually roll the dice involved and report the total.
It is still under development, but in its present form supports varied dice expressions adding and subtracting fixed modifiers or additional dice, as well as the "keep highest *n*" notations.
# METHODS
## new
```
my $dice = Dice::Roller.new('3d6 + 6 + 1d4');
```
`.new` takes a single argument (a dice expression) and returns a `Dice::Roller` object representing that collection of dice.
The expression syntax used is the shorthand that is popular in RPG systems; rolls of a group of similar dice are expressed as d, so 3d6 is a set of 3 six-sided dice, numbered 1..6. Additional groups of dice with different face counts can be added and subtracted from the total, as well as fixed integer values.
Preliminary support for some "selectors" is being added, and are appended to the dice identifier; rolling '4d6:kh3' stands for roll 4 d6, then keep the highest 3 dice. Selectors supported are:
* **:kh** - keep the highest *n* dice from this group.
* **:kl** - keep the lowest *n* dice from this group.
* **:dh** - drop the highest *n* dice from this group.
* **:dl** - drop the lowest *n* dice from this group.
Selectors can be chained together, so rolling '4d6:dh1:dl1' will drop the highest and lowest value dice.
## roll
```
$dice.roll;
```
Sets all dice in the expression to new random face values. Returns the `Dice::Roller` object for convenience, so you can do:
```
say $dice.roll.total;
```
## total
```
my $persuade-roll = Dice::Roller.new('1d20 -2').roll;
my $persuade-check = $persuade-roll.total;
```
Evaluates the faces showing on rolled dice including any adjustments and returns an `Int` total for the roll.
# ERROR HANDLING
`Dice::Roller.new` throws an exception if the string failed to parse.
This behaviour might change in a future release.
# DEBUGGING
You can get the module to spew out a bit of debugging text by setting `Dice::Roller::debug = True`. You can also inspect the Match object ini a given roll: `say $roll.match.gist`;
# AUTHOR
James Clark
# COPYRIGHT AND LICENSE
Copyright 2016 - 2017 James Clark
Copyright 2024 Raku Community
This library is free software; you can redistribute it and/or modify it under the Artistic License 2.0.
|
## dist_github-codesections-Pod-Literate.md
[](https://github.com/codesections/pod-literate/actions)
# NAME
Pod::Literate - A library for parsing Raku files into Pod and Code
# SYNOPSIS
```
use Pod::Literate;
Pod::Literate.parsefile($filename.IO);
```
# DESCRIPTION
Pod::Literate is an extremely simple library for parsing Raku source files into Pod blocks and Code blocks (i.e., everything that isn't a Pod block). The goal of doing so is to support basic [literate programming](https://en.wikipedia.org/wiki/Literate_programming) in Raku. Pod::Literate is intended to be used with Pod::Weave::To::$format and/or Pod::Tangle.
For additional details, please see the announcement blog post: [www.codesections.com/blog/weaving-raku](https://www.codesections.com/blog/weaving-raku).
# AUTHOR
codesections [daniel@codesections.com](mailto:daniel@codesections.com)
# COPYRIGHT AND LICENSE
ⓒ 2020 Daniel Sockwell
This library is free software; you can redistribute it and/or modify it under the Artistic License 2.0.
|
## dist_cpan-FCO-JSON-Stream.md
[](https://travis-ci.org/FCO/JSON-Stream)
# JSON::Stream
A JSON stream parser
```
use JSON::Stream;
```
```
react whenever json-stream "a-big-json-file.json".IO.open.Supply, '$.employees.*' -> (:$key, :$value) {
say "$key => $value<name> - $value<age>"
}
# OUTPUT:
# $.employees.0 => John - 40
# $.employees.1 => Peter - 30
```
Having this as an example of 'a-big-json-file.json'
```
{
"employees": [
{ "name": "John", "age": 40 },
{ "name": "Peter", "age": 30 }
]
}
```
## Warning
It doesn't validate the JSON. That's good for cases where the JSON isn't properly terminated. Example:
```
react whenever json-stream Supply.from-list(< { "bla" : [1,2,3,4], >), '$.bla.*' -> (:key($), :$value) {
say $value
}
# OUTPUT:
# 1
# 2
# 3
# 4
```
### sub json-stream
```
sub json-stream(
Supply $supply,
+@subscribed
) returns Supply
```
Receives an supply and a list of simplified json-path strings
|
## dist_zef-rir-Touch.md
NAME
Touch -- set file modified and/or accessed time
SYNOPSIS
use Touch;
touch( $filename ); # update both to now
touch( $filename, $access, $modify ); # update both
touch( $filename, :$access!, :$modify! ); # update both
touch( $filename, :$access!, :only! ); # update access only
touch( $filename, :$access! ); # update access, set mtime to now
touch( $filename, :$modify!, :only! ); # update modify only
touch( $filename, :$modify! ); # update atime, set atime to now
DESCRIPTION
Touch is a wrapping of Cs utimensat call. It allows the
setting of file access and modify times.
The Instant type is used to express all time values seen
in Raku. Instants being passed to C representing
times in the years from 1939 to 2285 inclusive are valid.
The formal limits are in $MIN-POSIX and $MAX-POSIX as
posix time values.
When an access or modify argument is absent, its default is now.
Use the :only flag to leave the absent timestamp unchanged.
All given arguments must be defined. :ONLY is deprecated.
Exceptions have been added.
Symlinks are always followed. Acting on symlinks directly is not
supported. This mirrors Raku's behavior when when reading file
times.
CAVEATS
Alpha code. Run the tests. If tests fail, you may increase the
lag allowance for writing and reading back a timestamp. Set $TESTLAG
in the environment. 0.01 second is the default.
The calling interface is not to be considered stable yet. There
are no plans to change. Feedback is welcome, It is supposed to be
accomodating and easy.
AUTHOR
Robert Ransbottom
SEE ALSO
joy / the clouds / ride the zephyr / warm they smile / die crying
COPYRIGHT AND LICENSE
Copyright 2021-2023 Robert Ransbottom.
This library is free software; you can redistribute it and/or modify it
under the Artistic License 2.0.
|
## dist_zef-FCO-ASTQuery.md
[](https://github.com/FCO/ASTQuery/actions)
# NAME
ASTQuery - Query and manipulate Raku’s Abstract Syntax Trees (RakuAST) with an expressive syntax
# SYNOPSIS
```
use ASTQuery;
# Sample Raku code
my $code = q{
for ^10 {
if $_ %% 2 {
say $_ * 3;
}
}
};
# Generate the AST
my $ast = $code.AST;
# Example 1: Find 'apply-op' nodes where left operand is 1 and right operand is 3
my $result1 = $ast.&ast-query('.apply-op[left=1, right=3]');
say $result1.list; # Outputs matching nodes
```
## Output
```
[
RakuAST::ApplyInfix.new(
left => RakuAST::IntLiteral.new(1),
infix => RakuAST::Infix.new("*"),
right => RakuAST::IntLiteral.new(3)
)
]
```
# DESCRIPTION
ASTQuery simplifies querying and manipulating Raku’s ASTs using a powerful query language. It allows precise selection of nodes and relationships, enabling effective code analysis and transformation.
## Key Features
* Expressive Query Syntax: Define complex queries to match specific AST nodes.
* Node Relationships: Use operators to specify parent-child and ancestor-descendant relationships.
* Named Captures: Capture matched nodes for easy retrieval.
* AST Manipulation: Modify the AST for code transformations and refactoring.
# QUERY LANGUAGE SYNTAX
## Node Description
Format:
`RakuAST::Class::Name.group#id[attr1, attr2=attrvalue]$name`
Components:
* `RakuAST::Class::Name`: (Optional) Full class name.
* `.group`: (Optional) Node group (predefined).
* `#id`: (Optional) Identifier attribute.
* `[attributes]`: (Optional) Attributes to match.
* `$name`: (Optional) Capture name.
Note: Use only one $name per node.
## Operators
* `>` : Left node has the right node as a child.
* `<` : Right node is the parent of the left node.
* `>>>`: Left node has the right node as a descendant (any nodes can be between them).
* `>>`: Left node has the right node as a descendant, with only ignorable nodes in between.
* `<<<`: Right node is an ancestor of the left node (any nodes can be between them).
* `<<`: Right node is an ancestor of the left node, with only ignorable nodes in between.
Note: The space operator is no longer used.
## Ignorable Nodes
Nodes skipped by `>>` and `<<` operators:
* `RakuAST::Block`
* `RakuAST::Blockoid`
* `RakuAST::StatementList`
* `RakuAST::Statement::Expression`
* `RakuAST::ArgList`
# EXAMPLES
## Example 1: Matching Specific Infix Operations
```
# Sample Raku code
my $code = q{
for ^10 {
if $_ %% 2 {
say 1 * 3;
}
}
};
# Generate the AST
my $ast = $code.AST;
# Query to find 'apply-op' nodes where left=1 and right=3
my $result = $ast.&ast-query('.apply-op[left=1, right=3]');
say $result.list; # Outputs matching 'ApplyOp' nodes
```
### Output
```
[
RakuAST::ApplyInfix.new(
left => RakuAST::IntLiteral.new(1),
infix => RakuAST::Infix.new("*"),
right => RakuAST::IntLiteral.new(3)
)
]
```
Explanation:
* The query `.apply-op[left=1, right=3]` matches ApplyOp nodes with left operand 1 and right operand 3.
## Example 2: Using the Ancestor Operator `<<<` and Named Captures
```
# Sample Raku code
my $code = q{
for ^10 {
if $_ %% 2 {
say $_ * 3;
}
}
};
# Generate the AST
my $ast = $code.AST;
# Query to find 'Infix' nodes with any ancestor 'conditional', and capture 'IntLiteral' nodes with value 2
my $result = $ast.&ast-query('RakuAST::Infix <<< .conditional$cond .int#2$int');
say $result.list; # Outputs matching 'Infix' nodes
say $result.hash; # Outputs captured nodes under 'cond' and 'int'
```
### Output
```
[
RakuAST::Infix.new("%%"),
RakuAST::Infix.new("*")
]
{
cond => [
RakuAST::Statement::If.new(
condition => RakuAST::ApplyInfix.new(
left => RakuAST::Var::Lexical.new("$_"),
infix => RakuAST::Infix.new("%%"),
right => RakuAST::IntLiteral.new(2)
),
then => RakuAST::Block.new(...)
)
],
int => [
RakuAST::IntLiteral.new(2),
RakuAST::IntLiteral.new(2)
]
}
```
Explanation:
* The query `RakuAST::Infix <<< .conditional$cond .int#2$int`:
* Matches Infix nodes that have an ancestor matching `.conditional$cond`, regardless of intermediate nodes.
* Captures IntLiteral nodes with value 2 as $int.
* Access the captured nodes using $result and $result.
## Example 3: Using the Ancestor Operator `<<` with Ignorable Nodes
```
# Find 'Infix' nodes with an ancestor 'conditional', skipping only ignorable nodes
my $result = $ast.&ast-query('RakuAST::Infix << .conditional$cond');
say $result.list; # Outputs matching 'Infix' nodes
say $result.hash; # Outputs captured 'conditional' nodes
```
Explanation:
* The query RakuAST::Infix << .conditional$cond:
* Matches Infix nodes that have an ancestor .conditional$cond, with only ignorable nodes between them.
* Captures the conditional nodes as $cond.
## Example 4: Using the Parent Operator < and Capturing Nodes
```
# Sample Raku code
my $code = q{
for ^10 {
if $_ %% 2 {
say $_ * 2;
}
}
};
# Generate the AST
my $ast = $code.AST;
# Query to find 'ApplyInfix' nodes where right operand is 2 and capture them as '$op'
my $result = $ast.&ast-query('RakuAST::Infix < .apply-op[right=2]$op');
say $result<op>; # Captured 'ApplyInfix' nodes
```
### Output
```
[
RakuAST::ApplyInfix.new(
left => RakuAST::Var::Lexical.new("$_"),
infix => RakuAST::Infix.new("*"),
right => RakuAST::IntLiteral.new(2)
)
]
```
Explanation:
* The query `RakuAST::Infix < .apply-op[right=2]$op`:
* Matches ApplyOp nodes with right operand 2 whose parent is an Infix node.
* Captures the ApplyOp nodes as $op.
## Example 5: Using the Descendant Operator `>>>` and Capturing Variables
```
# Sample Raku code
my $code = q{
for ^10 {
if $_ %% 2 {
say $_;
}
}
};
# Generate the AST
my $ast = $code.AST;
# Query to find 'call' nodes that have a descendant 'Var' node and capture the 'Var' node as '$var'
my $result = $ast.&ast-query('.call >>> RakuAST::Var$var');
say $result.list; # Outputs matching 'call' nodes
say $result.hash; # Outputs the 'Var' node captured as 'var'
```
### Output
```
[
RakuAST::Call::Name::WithoutParentheses.new(
name => RakuAST::Name.from-identifier("say"),
args => RakuAST::ArgList.new(
RakuAST::Var::Lexical.new("$_")
)
)
]
{ var => RakuAST::Var::Lexical.new("$_") }
```
Explanation:
* The query `.call >>> RakuAST::Var$var`:
* Matches call nodes that have a descendant Var node, regardless of intermediate nodes.
* Captures the Var node as $var.
* Access the captured Var node using $result.
# RETRIEVING MATCHED NODES
The ast-query function returns an ASTQuery object with:
* `@.list`: Matched nodes.
* `%.hash`: Captured nodes.
Accessing captured nodes:
```
# Perform the query
my $result = $ast.&ast-query('.call#say$call');
# Access the captured node
my $call_node = $result<call>;
# Access all matched nodes
my @matched_nodes = $result.list;
```
# THE ast-query FUNCTION
Usage:
```
:lang<raku> my $result = $ast.&ast-query('query string');
```
Returns an ASTQuery object with matched nodes and captures.
# GET INVOLVED
Visit the [ASTQuery repository](https://github.com/FCO/ASTQuery) on GitHub for examples, updates, and contributions.
## How You Can Help
* Feedback: Share your thoughts on features and usability.
* Code Contributions: Add new features or fix bugs.
* Documentation: Improve tutorials and guides.
Note: ASTQuery is developed by Fernando Corrêa de Oliveira.
# DEBUG
For debugging, use the `ASTQUERY_DEBUG` env var.

# CONCLUSION
ASTQuery empowers developers to effectively query and manipulate Raku’s ASTs, enhancing code analysis and transformation capabilities.
# DESCRIPTION
ASTQuery is a way to match RakuAST
# AUTHOR
Fernando Corrêa de Oliveira [fernandocorrea@gmail.com](mailto:fernandocorrea@gmail.com)
# COPYRIGHT AND LICENSE
Copyright 2024 Fernando Corrêa de Oliveira
This library is free software; you can redistribute it and/or modify it under the Artistic License 2.0.
|
## dist_zef-tbrowder-Foo-Bar.md
[](https://github.com/tbrowder/Foo-Bar/actions) [](https://github.com/tbrowder/Foo-Bar/actions) [](https://github.com/tbrowder/Foo-Bar/actions)
# NAME
**Foo::Bar** is a dummy module for testing Mi6::Helper development
# SYNOPSIS
```
use Foo::Bar;
```
# DESCRIPTION
**Foo::Bar** is a test module with one file in the /resources directory, but no corresponding entry in the META6.json file.
# AUTHOR
Tom Browder [tbrowder@acm.org](mailto:tbrowder@acm.org)
# COPYRIGHT AND LICENSE
© 2024 Tom Browder
This library is free software; you may redistribute it or modify it under the Artistic License 2.0.
|
## dist_zef-vrurg-Log-Dispatch.md
# NAME
`Log::Dispatch` - Dispatching multi-source, multi-destination logging
# SYNOPSIS
```
use Log::Dispatch;
use Log::Dispatch::Destination;
use Log::Dispatch::Source;
class DBDestination does Log::Ddispatch::Destination {
method report(Log::Dispatch::Msg:D $message) {
... # Implement writing log messages to a database table
}
}
class MyApp does Log::Dispatch::Source {
has Log::Dispatch:D $!logger .= new;
has Str:D $.log-file is required;
submethod TWEAK {
$!logger.add: Log::Dispatch::TTY, :max-level(LOG-LEVEL::DEBUG);
$!logger.add: 'File', file => $!log-file;
$!logger.add: DBDestination;
}
method do-an-action {
my Bool $success;
my $diagnostics;
self.log: :debug, "Trying an action...";
... # Do something
if $success {
self.log: "All done";
}
else {
self.log: :critical, "Something is wrong! Cause: ", $diagnostics;
}
}
}
```
# DESCRIPTION
This module provide a means to have multiple log destinations withing single application with extra hassle but with easy support for concurrency.
## Model
The model this module is based upon is built around a single dispatcher, which can be considered as a minimalistic wrapper around a [`Supplier`](https://docs.raku.org/type/Supplier). The dispatcher accepts message objects from sources and dispatches them into destinations.
A source here is any instance of a class consuming [`Log::Dispatch::Source`](docs/md/Log/Dispatch/Source.md) role.
A destination is an instance of a class consuming [`Log::Dispatch::Destination`](docs/md/Log/Dispatch/Destination.md) role. It represented an endpoint where messages are to be submitted to.
For example, one may have an application and wants to log its messages into a file and on the console. This is as simple as adding `does Log::Dispatch::Source` to the declaration of our application class. And by having something like the following example anywhere in application code:
```
my $logger = Log::Dispatch.new;
$logger.add: 'File', :max-level(LOG-LEVEL::DEBUG), $log-file-name;
$logger.add: Log::Dispatch::TTY;
```
Note that the application would then log all messages into a log file, but only the essential ones to the console.
It worth to mention that each destination code is by default gets its own thread. For a source it is normally sufficient just to use `log` method provided by [`Log::Dispatch::Source`](docs/md/Log/Dispatch/Source.md) role.
## Processors
A *processor* is an end-point attached to the dispatcher. The module provides two kinds of processors: source and destination implemented, correspondingly, by [`Log::Dispatch::Source`](docs/md/Log/Dispatch/Source.md) and [`Log::Dispatch::Destination`](docs/md/Log/Dispatch/Destination.md) roles.
`Log::Dispatch::Processor` role is just an interface requiring `attach` method to be implemented.
## Destinations
Currently the module only provides two destination end-points: [`Log::Dispatch::TTY`](docs/md/Log/Dispatch/TTY.md) and [`Log::Dispatch::File`](docs/md/Log/Dispatch/File.md). Syslog support may be added later.
## Performance
The multi-destination concept with per-destination maximum log-level support implies that there is no way to optimize away some possibly unused calls to the method `log` because any message, no matter what log-level it is assigned with, must be accepted and emitted into dispatcher's [`Supply`](https://docs.raku.org/type/Supply).
## Log Levels
The number and names of log levels are taken from *syslog* standard exactly for the reason it is the most common logging standard existing around.
Levels are provided as `LOG-LEVEL` enum values declared by [`Log::Dispatch::Types`](docs/md/Log/Dispatch/Types.md) module. Here is the list in the ascending order:
* `EMERGENCY`, which is *0*
* `ALERT`
* `CRITICAL`
* `ERROR`
* `WARNING`
* `NOTICE`
* `INFO` – the per-destination default
* `DEBUG`
## Non-polluting
This module tries to reduce namespace pollution to the absolute minimum. The only symbol exported is `LOG-LEVEL` enumeration type for comparatively simple registration of a destination, as in the above example from the [Model](#Model) section.
# METHODS
### `multi method add(Log::Dispatch::Processor:D $processor --` Nil)>
Adds an end-point object `$processor` to the dispatcher.
Note that the `attach` method of a custom processor is expected to return a [`Promise`](https://docs.raku.org/type/Promise) which is to be kept only and only when the processor is ready. The meaning of being ready would then depend on the end-point type only.
### `multi method add(Log::Dispatch::Processor:U $processor, *%params)`
This method creates an instance of the `$processor` type using `%params` as constructor parameters. The resulting instance is then gets registered with the dispatcher.
### `multi method add(`[`Str`](https://docs.raku.org/type/Str)`:D $processor, *%params)`
This method determines processor type based on the name provided in `$processor` parameter and then instantiates it as described for the previous method candidate.
The following rules are used to resolve the type:
* if it contains a colon pair *::* then the name is used as-is
* otherwise the name is prefixed with *Log::Dispatch::* prefix
* the resulting name is used to load a module of the same name with `require`
See the example in the [Model](#Model) section above.
### `shutdown`
Can only be issued once on a dispatcher. Any subsequent call to the method is ignored.
Closes the dispatching supply by invoking method `done` on the [`Supplier`](https://docs.raku.org/type/Supplier).
The method can be invoked manually when absolutely necessary. But normally is it called inside an `END` phaser to ensure that the logging capabilities are available up until the complete stop of the application.
### `Supply`
Produces a new supply to be tapped upon
### `dispatch-msg(`[`Log::Dispatch::Msg:D`](docs/md/Log/Dispatch/Msg.md)`$msg)`
Emits [`Log::Dispatch::Msg`](docs/md/Log/Dispatch/Msg.md) object into the dispatching supply.
# SEE ALSO
[`Log::Dispatch::File`](docs/md/Log/Dispatch/File.md), [`Log::Dispatch::TTY`](docs/md/Log/Dispatch/TTY.md), [`Log::Dispatch::Types`](docs/md/Log/Dispatch/Types.md), [`Log::Dispatch::Source`](docs/md/Log/Dispatch/Source.md), [`Log::Dispatch::Destination`](docs/md/Log/Dispatch/Destination.md), [`Log::Dispatch::Msg`](docs/md/Log/Dispatch/Msg.md)
# AUTHOR
Vadim Belman [vrurg@cpan.org](mailto:vrurg@cpan.org)
# LICENSE
Atristic 2.0
|
## dist_zef-raku-community-modules-IO-MiddleMan.md
[](https://travis-ci.org/zoffixznet/perl6-IO-MiddleMan)
# NAME
IO::MiddleMan - hijack, capture, or mute writes to an IO::Handle
# TABLE OF CONTENTS
* [NAME](#name)
* [SYNOPSIS](#synopsis)
* [DESCRIPTION](#description)
* [ACCESSORS](#accessors)
* [`.data`](#data)
* [`.handle`](#handle)
* [`.mode`](#mode)
* [METHODS](#methods)
* [`.capture`](#capture)
* [`.hijack`](#hijack)
* [`.mute`](#mute)
* [`.normal`](#normal)
* [`.Str`](#str)
* [CAVEATS](#caveats)
* [REPOSITORY](#repository)
* [BUGS](#bugs)
* [AUTHOR](#author)
* [LICENSE](#license)
# SYNOPSIS
```
my $mm = IO::MiddleMan.hijack: $*OUT;
say "Can't see this yet!";
$mm.mode = 'normal';
say "Want to see what I said?";
say "Well, fine. I said $mm";
my $fh = 'some-file'.IO.open: :w;
my $mm = IO::MiddleMan.capture: $fh;
$fh.say: 'test', 42;
say "We wrote $mm into some-file";
IO::MiddleMan.mute: $*ERR;
note "you'll never see this!";
```
# DESCRIPTION
This module allows you to inject yourself in the middle between an `IO::Handle`
and things writing into it. You can completely hijack the data, merely capture
it, or discard it entirely.
# ACCESSORS
## `.data`
```
say Currently captured things are " $mm.data.join: '';
$mm.data = () unless $mm.data.grep: {/secrets/};
say "Haven't seen any secrets yet. Restarted the capture";
```
An array that contains data captured by [`.hijack`](#hijack) and
[`.capture`](#capture) methods. Each operation on the filehandle add one
element to `.data`; those operations are calls to `.print`, `.print-nl`,
`.say`, and `.put` methods on the original filehandle. Note that `.data`
added with `.say`/`.put` will have `\n` added to it already.
## `.handle`
```
my $mm = IO::MiddleMan.mute: $*OUT;
say "This is muted";
$mm.handle.say: "But this still works!";
```
The original `IO::Handle`. You can still successfully call data methods on it,
and no captures will be done, regardless of what the `IO::MiddleMan`
[`.mode`](#mode) is.
## `.mode`
```
my $mm = IO::MiddleMan.hijack: $*OUT;
say "I'm hijacked!";
$mm.mode = 'normal';
say "Now things are back to normal";
```
Sets operational mode for the `IO::MiddleMan`. Valid modes are
[`capture`](#capture), [`hijack`](#hijack), [`mute`](#mute), and
[`normal`](#normal). See methods of the corresponding name for the
description of the behavior these modes enable.
# METHODS
## `.capture`
```
my $mm = IO::MiddleMan.capture: $*OUT;
say "I'm watching you";
```
Creates and returns a new `IO::MiddleMan` object set to capture all the data
sent to the `IO::Handle` given as the positional argument. Any writes to the
original `IO::Handle` will proceed as normal, while also being stored in
[`.data` accessor](#data).
## `.hijack`
```
my $mm = IO::MiddleMan.hijack: $*OUT;
say "Can't see this yet!";
```
Creates and returns a new `IO::MiddleMan` object set to hijack all the data
sent to the `IO::Handle` given as the positional argument. Any writes to the
original `IO::Handle` will NOT reach it and instead will be stored in
[`.data` accessor](#data).
## `.mute`
```
my $mm = IO::MiddleMan.mute: $*OUT;
say "You'll never see this!";
```
Creates and returns a new `IO::MiddleMan` object set to ignore all the data
sent to the `IO::Handle` given as the positional argument.
## `.normal`
```
my $mm = IO::MiddleMan.normal: $*OUT;
say "Things look perfectly normal";
```
Creates and returns a new `IO::MiddleMan` object set to send all the data
sent to the `IO::Handle` given as the positional argument as it normally would
and no capturing of it is to be done.
## `.Str`
```
say "Captured $mm";
```
This module overrides the `.Str` method to return all the
[captured data](#data) as a string.
# CAVEATS
The module currently only operates on non-binary data (i.e. `write` method
is still native to `IO::Handle`). Patches are welcome.
The given filehandle must be a writable container and its contents will
be changed to the `IO::MiddleMan` object, thus possibly complicating some
operations.
# REPOSITORY
Fork this module on GitHub:
<https://github.com/raku-community-modules/IO-MiddleMan>
# BUGS
To report bugs or request features, please use
<https://github.com/raku-community-modules/IO-MiddleMan/issues>
# AUTHOR
Zoffix Znet (<http://zoffix.com/>)
# LICENSE
You can use and distribute this module under the terms of the
The Artistic License 2.0. See the `LICENSE` file included in this
distribution for complete details.
|
## dist_cpan-CTILMES-LibUUID.md
# LibUUID
[](https://travis-ci.org/CurtTilmes/perl6-libuuid)
Perl 6 bindings for [libuuid](https://libuuid.sourceforge.io/).
This library creates Universally Unique IDentifiers (UUID).
The uuid will be generated based on high-quality randomness from
/dev/urandom, if available. If it is not available, then it will use
an alternative algorithm which uses the current time, the local
ethernet MAC address (if available), and random data generated using a
pseudo-random generator.
# Installation
This module depends on [libuuid](https://libuuid.sourceforge.io/), so
it must be installed first.
For Linux ubuntu, try `sudo apt-get install uuid-dev`.
On Mac you can get hold of it via `brew install ossp-uuid`
Then install this module with `zef install LibUUID`.
# Usage
```
use LibUUID;
my $uuid = UUID.new; # Create a new UUID
$uuid = UUID.new($myblob); # From existing blob of 16 bytes
$uuid = UUID.new('39ed750e-a1bf-4792-81d6-e098f01152d3'); # From Str
say ~$uuid; # Stringify to hex digits with dashes
say $uuid.Blob; # Blobify to Blob of 16 bytes
```
# See Also
[UUID](https://github.com/retupmoca/P6-UUID) is a Perl 6 native UUID
generator which generates UUIDs from Perl's internal random number
generator.
On Linux machines, you can get UUIDs straight from the kernel:
```
cat /proc/sys/kernel/random/uuid
```
|
## dist_cpan-HANENKAMP-HTTP-Supply.md
# NAME
HTTP::Supply - modern HTTP/1.x message parser
# SYNOPSIS
```
use HTTP::Supply::Request;
react {
whenever IO::Socket::Async.listen('localhost', 8080) -> $conn {
my $envs = HTTP::Supply::Request.parse-http($conn);
whenever $envs -> %env {
my $res := await app(%env);
send-response($conn, $res);
}
}
}
use HTTP::Supply::Response;
react {
whenever IO::Socket::Async.connect('localhost', 8080) -> $conn {
send-request($conn);
whenever HTTP::Supply::Response.parse-http($conn) -> $res {
handle-response($res);
done unless send-request($conn);
}
}
}
```
# DESCRIPTION
**EXPERIMENTAL:** The API for these modules is experimental and may change.
This project provides asynchronous parsers for parsing HTTP request or response pipelines. As of this writing only HTTP/1.x is supported, but I hope to add HTTP/2 and HTTP/3 support as time allows.
# AUTHOR
Sterling Hanenkamp `<hanenkamp@cpan.org>`
# COPYRIGHT & LICENSE
Copyright 2016 Sterling Hanenkamp.
This software is licensed under the same terms as Raku.
|
## dist_zef-tony-o-Encoding-Huffman-PP6.md
# Huffman Encoding in pure perl6
What a joy.
## Subs provided + signatures
### Encoding
`sub huffman-encode(Str $string-to-encode, %table?)`
#### `$string-to-encode`
The string you wish to encode
#### `%table?`
The encoding table you'd like to use. Defaults to the HTTP2 spec's predefined huffman table found [here](https://http2.github.io/http2-spec/compression.html#huffman.code)
### Decoding
`sub huffman-decode(Buf[uint8] $buffer-to-decode, %table?)`
#### `$buffer-to-decode`
A `Buf[uint8]` that you wish to decode
#### `%table?`
Please reference above.
|
## dist_github-moznion-IO-Blob.md
[](https://travis-ci.org/moznion/p6-IO-Blob)
# NAME
IO::Blob - IO:: interface for reading/writing a Blob
# SYNOPSIS
```
use v6;
use IO::Blob;
my $data = "foo\nbar\n";
my IO::Blob $io = IO::Blob.new($data.encode);
$io.get; # => "foo\n"
$io.print('buz');
$io.seek(0); # rewind
$io.slurp-rest; # => "foo\nbar\nbuz"
```
# DESCRIPTION
`IO::` interface for reading/writing a Blob. This class inherited from IO::Handle.
The IO::Blob class implements objects which behave just like IO::Handle objects, except that you may use them to write to (or read from) Blobs.
This module is inspired by IO::Scalar of perl5.
# METHODS
## new(Blob $data = Buf.new)
Make a instance. This method is equivalent to `open`.
```
my $io = IO::Blob.new("foo\nbar\n".encode);
```
## open(Blob $data = Buf.new)
Make a instance. This method is equivalent to `new`.
```
my $io = IO::Blob.open("foo\nbar\n".encode);
```
## new(Str $str)
Make a instance. This method is equivalent to `open`.
```
my $io = IO::Blob.new("foo\nbar\n");
```
## open(Str $str)
Make a instance. This method is equivalent to `new`.
```
my $io = IO::Blob.open("foo\nbar\n");
```
## get(IO::Blob:D:)
Reads a single line from the Blob.
```
my $io = IO::Blob.open("foo\nbar\n".encode);
$io.get; # => "foo\n"
```
## getc(IO::Blob:D:)
Read a single character from the Blob.
```
my $io = IO::Blob.open("foo\nbar\n".encode);
$io.getc; # => "f\n"
```
## lines(IO::Blob:D: $limit = Inf)
Return a lazy list of the Blob's lines read via `get`, limited to `$limit` lines.
```
my $io = IO::Blob.open("foo\nbar\n".encode);
for $io.lines -> $line {
$line; # 1st: "foo\n", 2nd: "bar\n"
}
```
## word(IO::Blob:D:)
Read a single word (separated on whitespace) from the Blob.
```
my $io = IO::Blob.open("foo bar\tbuz\nqux".encode);
$io.word; # => "foo "
```
## words(IO::Blob:D: $count = Inf)
Return a lazy list of the Blob's words (separated on whitespace) read via `word`, limited to `$count` words.
```
my $io = IO::Blob.open("foo bar\tbuz\nqux".encode);
for $io.words -> $word {
$word; # 1st: "foo ", 2nd: "bar\t", 3rd: "buz\n", 4th: "qux"
}
```
## print(IO::Blob:D: \*@text) returns Bool
Text writing; writes the given `@text` to the Blob.
## say(IO::Blob:D: \*@text) returns Bool
Text writing; similar to print, but add a newline to end of the `@text`.
## read(IO::Blob:D: Int(Cool:D) $bytes)
Binary reading; reads and returns `$bytes` bytes from the Blob.
## write(IO::Blob:D: Blob:D $buf)
Binary writing; writes $buf to the Blob.
## seek(IO::Blob:D: int $offset, SeekType:D $whence = SeekFromBeginning)
Move the pointer (that is the position at which any subsequent read or write operations will begin,) to the byte position specified by `$offset` relative to the location specified by `$whence` which may be one of:
* SeekFromBeginning
The beginning of the file.
* SeekFromCurrent
The current position in the file.
* SeekFromEnd
The end of the file.
## tell(IO::Blob:D:) returns Int
Returns the current position of the pointer in bytes.
## ins(IO::Blob:D:) returns Int
Returns the number of lines read from the file.
## slurp-rest(IO::Blob:D: :$bin!) returns Buf
Return the remaining content of the Blob from the current position (which may have been set by previous reads or by seek.) If the adverb `:bin` is provided a Buf will be returned.
## slurp-rest(IO::Blob:D: :$enc = 'utf8') returns Str
Return the remaining content of the Blob from the current position (which may have been set by previous reads or by seek.) Return will be a Str with the optional encoding `:enc`.
## eof(IO::Blob:D:)
Returns Bool::True if the read operations have exhausted the content of the Blob;
## close(IO::Blob:D:)
Will close a previously opened Blob.
## is-closed(IO::Blob:D:)
Returns Bool::True if the Blob is closed.
## data(IO::Blob:D:)
Returns the current Blob.
# SEE ALSO
[IO::Scalar of perl5](https://metacpan.org/pod/IO::Scalar)
# AUTHOR
moznion [moznion@gmail.com](mailto:moznion@gmail.com)
# CONTRIBUTORS
* mattn
* shoichikaji
# LICENSE
Copyright 2015 moznion [moznion@gmail.com](mailto:moznion@gmail.com)
This library is free software; you can redistribute it and/or modify it under the Artistic License 2.0.
|
## dist_cpan-RBT-File-Temp.md
[](https://ci.appveyor.com/project/perlpilot/p6-File-Temps/branch/master)
# NAME
File::Temp
# SYNOPSIS
```
# Generate a temp file in a temp dir
my ($filename,$filehandle) = tempfile;
# specify a template for the filename
# * are replaced with random characters
my ($filename,$filehandle) = tempfile("******");
# Automatically unlink files at DESTROY (this is the default)
my ($filename,$filehandle) = tempfile("******", :unlink);
# Specify the directory where the tempfile will be created
my ($filename,$filehandle) = tempfile(:tempdir("/path/to/my/dir"));
# don't unlink this one
my ($filename,$filehandle) = tempfile(:tempdir('.'), :!unlink);
# specify a prefix and suffix for the filename
my ($filename,$filehandle) = tempfile(:prefix('foo'), :suffix(".txt"));
```
# DESCRIPTION
This module exports two routines:
* `tempfile` creates a temporary file and returns a filehandle to that file
opened for writing and the filename of that temporary file
* `tempdir` creates a temporary directory and returns the directory name.
# AUTHOR
Jonathan Scott Duff [duff@pobox.com](mailto:duff@pobox.com)
|
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.