
Dataset Viewer
txt
stringlengths 93
37.3k
|
|---|
## dist_zef-p6steve-Dan.md
# raku Dan
Top level raku **D**ata **AN**alysis Module that provides **a base set of raku-style** datatype roles, accessors & methods, primarily:
* DataSlices
* Series
* DataFrames
A common basis for bindings such as ... [Dan::Pandas](https://github.com/p6steve/raku-Dan-Pandas) (via Inline::Python), Dan::Polars(tbd) (via NativeCall / Rust FFI), etc.
It's rather a zen concept since raku contains many Data Analysis constructs & concepts natively anyway (see note 7 below)
Contributions via PR are very welcome - please see the backlog Issue, or just email [p6steve@furnival.net](mailto:p6steve@furnival.net) to share ideas!
# SYNOPOSIS
more examples in [bin/synopsis.raku](https://github.com/p6steve/raku-Dan/blob/main/bin/synopsis-dan.raku)
```
### Series ###
my \s = Series.new( [b=>1, a=>0, c=>2] ); #from Array of Pairs
# -or- Series.new( [rand xx 5], index => <a b c d e>);
# -or- Series.new( data => [1, 3, 5, NaN, 6, 8], index => <a b c d e f>, name => 'john' );
say ~s;
# Accessors
say s[1]; #2 (positional)
say s<b c>; #2 1 (associative with slice)
# Map/Reduce
say s.map(*+2); #(3 2 4)
say [+] s; #3
# Hyper
say s >>+>> 2; #(3 2 4)
say s >>+<< s; #(2 0 4)
# Update
s.data[1] = 1; # set value
s.splice(1,2,(j=>3)); # update index & value
# Combine
my \t = Series.new( [f=>1, e=>0, d=>2] );
s.concat: t; # concatenate
say "=============================================";
### DataFrames ###
my \dates = (Date.new("2022-01-01"), *+1 ... *)[^6];
my \df = DataFrame.new( [[rand xx 4] xx 6], index => dates, columns => <A B C D> );
# -or- DataFrame.new( [rand xx 5], columns => <A B C D>);
# -or- DataFrame.new( [rand xx 5] );
say ~df;
say "---------------------------------------------";
# Data Accessors [row;col]
say df[0;0];
df[0;0] = 3; # set value
# Cascading Accessors (ok to mix Positional and Associative)
say df[0][0];
say df[0]<A>;
say df{"2022-01-03"}[1];
# Object Accessors & Slices (see note 1)
say ~df[0]; # 1d Row 0 (DataSlice)
say ~df[*]<A>; # 1d Col A (Series)
say ~df[0..*-2][1..*-1]; # 2d DataFrame
say ~df{dates[0..1]}^; # the ^ postfix converts an Array of DataSlices into a new DataFrame
say "---------------------------------------------";
### DataFrame Operations ###
# 2d Map/Reduce
say df.map(*.map(*+2).eager);
say [+] df[*;1];
say [+] df[*;*];
# Hyper
say df >>+>> 2;
say df >>+<< df;
# Transpose
say ~df.T;
# Describe
say ~df[0..^3]^; # head
say ~df[(*-3..*-1)]^; # tail
say ~df.shape;
say ~df.describe;
# Sort
say ~df.sort: { .[1] }; # sort by 2nd col (ascending)
say ~df.sort: { -.[1] }; # sort by 2nd col (descending)
say ~df.sort: { df[$++]<C> }; # sort by col C
say ~df.sort: { df.ix[$++] }; # sort by index
# Grep (binary filter)
say ~df.grep( { .[1] < 0.5 } ); # by 2nd column
say ~df.grep( { df.ix[$++] eq <2022-01-02 2022-01-06>.any } ); # by index (multiple)
say "---------------------------------------------";
my \df2 = DataFrame.new([
A => 1.0,
B => Date.new("2022-01-01"),
C => Series.new(1, index => [0..^4], dtype => Num),
D => [3 xx 4],
E => Categorical.new(<test train test train>),
F => "foo",
]);
say ~df2;
say df2.data;
say df2.dtypes;
say df2.index; #Hash (name => row number) -or- df.ix; #Array
say df2.columns; #Hash (label => col number) -or- df.cx; #Array
say "---------------------------------------------";
### DataFrame Splicing ### (see notes 2 & 3)
# row-wise splice:
my $ds = df2[1]; # get a DataSlice
$ds.splice($ds.index<d>,1,7); # tweak it a bit
df2.splice( 1, 2, [j => $ds] ); # default
# column-wise splice:
my $se = df2.series: <a>; # get a Series
$se.splice(2,1,7); # tweak it a bit
df2.splice( :ax, 1, 2, [K => $se] ); # axis => 1
say "---------------------------------------------";
### DataFrame Concatenation ### (see notes 4 & 5)
my \dfa = DataFrame.new(
[['a', 1], ['b', 2]],
columns => <letter number>,
);
#`[
letter number
0 a 1
1 b 2
#]
my \dfc = DataFrame.new(
[['c', 3, 'cat'], ['d', 4, 'dog']],
columns => <animal letter number>,
);
#`[
letter number animal
0 c 3 cat
1 d 4 dog
#]
dfa.concat: dfc; # row-wise / outer join is default
#`[
letter number animal
0 a 1 NaN
1 b 2 NaN
0⋅1 c 3 cat
1⋅1 d 4 dog
#]
dfa.concat: dfc, join => 'inner';
#`[
letter number
0 a 1
1 b 2
0⋅1 c 3
1⋅1 d 4
#]
my \dfd = DataFrame.new( [['bird', 'polly'], ['monkey', 'george']],
columns=> <animal name>, );
dfb.concat: dfd, axis => 1; #column-wise
#`[
letter number animal name
0 a 1 bird polly
1 b 2 monkey george
#]
say "=============================================";
```
Notes:
[1] raku accessors may use any function that makes a List, e.g.
Positional slices: `[1,3,4], [0..3], [0..*-2], [*]`
Associative slices: `<A C D>, {'A'..'C'}`
viz. <https://docs.raku.org/language/subscripts>
[2] splice is the core update method
for all add, drop, move, delete, update & insert operations
viz. <https://docs.raku.org/routine/splice>
[3] named parameter 'axis' indicates if row(0) or col(1)
if omitted, default=0 (row) / 'ax' is an alias
use a Pair literal like `:!axis, :axis(1) or :ax`
[4] concat is the core combine method
for all join, merge & combine operations
duplicate labels are extended with `$mark ~ $i++`
`# $mark = '⋅'; # unicode Dot Operator U+22C5`
use `:ii (:ignore-index)` to reset the index (row or col)
[5] concat supports `join => outer|inner|right|left`
unknown values are set to NaN
default is outer, :jn is alias, and you can go :jn on first letter
set axis param (see splice above) for col-wise concatenation
[6] relies on hypers instead of overriding dyadic operators [+-\*/]
```
say ~my \quants = Series.new([100, 15, 50, 15, 25]);
say ~my \prices = Series.new([1.1, 4.3, 2.2, 7.41, 2.89]);
say ~my \costs = Series.new( quants >>*<< prices );
```
[7] what are we getting from raku core that others do in libraries?
* pipes & maps
* multi-dimensional arrays
* slicing & indexing
* references & views
* map, reduce, hyper operators
* operator overloading
* concurrency
* types (incl. NaN)
|
## -.md
.=
Combined from primary sources listed below.
# [In Operators](#___top "go to top of document")[§](#(Operators)_infix_.= "direct link")
See primary documentation
[in context](/language/operators#infix_.=)
for **infix .=**.
Calls the right-side method on the value in the left-side container, replacing the resulting value in the left-side container.
In most cases, this behaves identically to the postfix mutator, but the precedence is lower:
```raku
my $a = -5;
say ++$a.=abs;
# OUTPUT: «6»
```
```raku
say ++$a .= abs;
# OUTPUT: «Cannot modify an immutable Int
# in block <unit> at <tmp> line 1»
```
|
## dist_zef-lizmat-shorten-sub-commands.md
[](https://github.com/lizmat/shorten-sub-commands/actions) [](https://github.com/lizmat/shorten-sub-commands/actions) [](https://github.com/lizmat/shorten-sub-commands/actions)
# NAME
shorten-sub-commands - allow partial specification of sub-commands
# SYNOPSIS
```
# in script "frobnicate"
multi sub MAIN("foozle") { say "foozle" }
multi sub MAIN("barabas") { say "barabas" }
multi sub MAIN("bazzie") { say "bazzie" }
use shorten::sub::commands &MAIN;
```
```
$ raku frobnicate foo
foozle
$ raku frobnicate ba
'ba' is ambiguous, matches: barabas bazzie
$ raku frobnicate bar
barabas
```
# DESCRIPTION
The `shorten::sub::commands` distribution provides a helper module intended to be used for command-line applications that have a sub-command structure (in which the first positional parameter indicates what needs to be done, and there is a separate candidate to handle execution of that command).
When used **after** all `MAIN` candidates have been defined, it will add another candidate that will allow to shorten the command names to be as short as possible (e.g. just "foo" in the example above, or even just "f" as there is only one candidate that starts with "f". Numeric subcommands are also supported, but they will be matched as strings (so `4` on the command line will match `42` in the signature).
Special care has been taken to ensure that re-dispatch doesn't devolve into an infinite loop.
# AUTHOR
Elizabeth Mattijsen [liz@raku.rocks](mailto:liz@raku.rocks)
Source can be located at: <https://github.com/lizmat/shorten-sub-commands> . Comments and Pull Requests are welcome.
If you like this module, or what I'm doing more generally, committing to a [small sponsorship](https://github.com/sponsors/lizmat/) would mean a great deal to me!
# COPYRIGHT AND LICENSE
Copyright 2022, 2025 Elizabeth Mattijsen
This library is free software; you can redistribute it and/or modify it under the Artistic License 2.0.
|
## dist_zef-patrickb-Cro-HTTP-Middleware-GoatCounter.md
```
=begin pod
=head1 NAME
Cro::HTTP::Middleware::GoatCounter
=head1 SYNOPSIS
=begin code :lang
use Cro::HTTP::Server;
use Cro::HTTP::Middleware::GoatCounter;
my $gc-api-url = "https://MYCODE.goatcounter.com/api/v0";
my $gc-token = "hienaitkyvzjvriheac2402407538153tn7v53c520hihtaylei";
my Cro::Service $http = Cro::HTTP::Server.new(
:$host, :$port,
application => routes(),
before => [
Cro::HTTP::Middleware::GoatCounter.new(
api-url => $gc-api-url,
token => $gc-token
),
],
);
=end code
=head1 DESCRIPTION
This module provides a simple Cro to GoatCounter integration.
See the GoatCounter homepage L for more
information.
=head1 AUTHOR
Patrick Böker
=head1 COPYRIGHT AND LICENSE
Copyright 2020-2024 Patrick Böker
This library is free software; you can redistribute it and/or modify it under the Artistic License 2.0.
=end pod
```
|
## adhoc.md
class X::AdHoc
Error with a custom message
```raku
class X::AdHoc is Exception { }
```
`X::AdHoc` is the type into which objects are wrapped if they are thrown as exceptions, but don't inherit from [`Exception`](/type/Exception).
Its benefit over returning non-[`Exception`](/type/Exception) objects is that it gives access to all the methods from class [`Exception`](/type/Exception), like `backtrace` and `rethrow`.
You can obtain the original object with the `payload` method.
```raku
try {
die [404, 'File not found']; # throw non-exception object
}
print "Got HTTP code ",
$!.payload[0], # 404
" and backtrace ",
$!.backtrace.Str;
```
Note that young code will often be prototyped using `X::AdHoc` and then later be revised to use more specific subtypes of [`Exception`](/type/Exception). As such it is usually best not to explicitly rely on receiving an `X::AdHoc` – in many cases using the string returned by the `.message` method, which all [`Exception`](/type/Exception)s must have, is preferable. Please note that we need to explicitly call `.Str` to stringify the backtrace correctly.
# [Methods](#class_X::AdHoc "go to top of document")[§](#Methods "direct link")
## [method payload](#class_X::AdHoc "go to top of document")[§](#method_payload "direct link")
Returns the original object which was passed to `die`.
## [method Numeric](#class_X::AdHoc "go to top of document")[§](#method_Numeric "direct link")
```raku
method Numeric()
```
Converts the payload to [`Numeric`](/type/Numeric) and returns it
## [method from-slurpy](#class_X::AdHoc "go to top of document")[§](#method_from-slurpy "direct link")
```raku
method from-slurpy (|cap)
```
Creates a new exception from a capture and returns it. The capture will have the `SlurpySentry` role mixed in, so that the `.message` method behaves in a different when printing the message.
```raku
try {
X::AdHoc.from-slurpy( 3, False, "Not here" ).throw
};
print $!.payload.^name; # OUTPUT: «Capture+{X::AdHoc::SlurpySentry}»
print $!.message; # OUTPUT: «3FalseNot here»
```
The `SlurpySentry` role joins the elements of the payload, instead of directly converting them to a string.
|
## dist_zef-lizmat-Updown.md
[](https://github.com/lizmat/Updown/actions) [](https://github.com/lizmat/Updown/actions)
# NAME
Updown - provide basic API to Updown.io
# SYNOPSIS
```
use Updown;
my $ud = Updown.new; # assume API key in UPDOWN_API_KEY
my $ud = Updown.new(api-key => "secret-api-key");
for $ud.checks -> (:key($check-id), :value($check)) {
say "$check.apdex_t() $check.url()"
}
my $event = Updown::Event(%hash); # inside a webhook
```
# DESCRIPTION
Updown provides a simple object-oriented interface to the API as provided by <Updown.io>, a website monitoring service.
Access to functionality is provided through the `Updown` class, which has methods that perform the various functions and return objects in the `Updown::` hierarchy of classes.
The [Updown API](https://updown.io/api) is basically followed to the letter, with a little caching and some minor functional sugar added.
To be consistent with the names used in the API, all identifiers use underscores (snake\_case) in their names, rather then hyphens (kebab-case).
# CLI
This distribution also installs an `updown` command line interface. It (implicitely) takes an `--api-key` parameter (or if none specified, the one in the `UPDOWN_API_KEY` environment). It shows the status of all of the checks associated with that API key, and some more information about a check if a website is down.
# COMPARING
In order to allow you to compare the performance of "your" sites with other, more general sites, the methods accepting a `check_id` can also with one of these named arguments **instead** of a `check_id`:
```
:booking booking.com
:duckduckgo duckduckgo.com
:facebook facebook.com
:github github.com
:google google.com
:raku raku.org
```
# MAIN CLASSES
## Updown
The `Updown` object connects the code with all of the monitoring that has been configured for a user of the [Updown.io](https://updown.io) service.
### Parameters
The following parameters can be specified when creating the `Updown` object:
#### client
A `Cro::HTTP::Client` object that will be used to access the API of `Updown`. Defaults to a default `Cro::HTTP::Client` object.
#### api-key
The API key that should be used to authenticate requests with the `Updown` API. Defaults to the `UPDOWN_API_KEY` environment variable.
Any API key (implicitely) specified will be added to the headers of the `client` object used to facilitate authentication.
### Methods
The following methods are available on the `Updown` object:
#### check
Return the `Updown::Check` object associated with the given "check\_id". Takes an optional named boolean argument `:update` to indicate that the information should be refreshed if it was already obtained before.
#### check\_ids
Returns a list of "check\_id"s of the `Updown::Check`s that are being performed for the user associated with the given API key. Takes an optional named boolean argument `:update` to indicate that the information should be refreshed if it was already obtained before.
#### checks
Returns a `Hash` with `Updown::Check` objects, keyed to their "check\_id". Takes an optional named boolean argument `:update` to indicate that the information should be refreshed if it was already obtained before.
#### downtimes
Returns a list of up to 100 `Node::Downtime` objects for the given "check\_id". Takes an optional `:page` argument to indicate the "page": defaults to `1`.
#### hourly\_metrics
Returns an object `Hash` of `Updown::Metrics` objects for the given "check\_id" about overall metrics per hour, keyed to `DateTime` objects indicating the hour. Optionally takes two named arguments.
`:from`, a `DateTime` object indicating the **start** of the period for which to provide overall metrics. Defaults to `DateTime.now.earlier(:1month)`.
`:to`, a `DateTime` object indicating the **end** of the period for which to provide overal metrics. Defaults to `DateTime.now`.
#### node
Return the `Updown::Node` object associated with the given "node\_id". Takes an optional named boolean argument `:update` to indicate that the information should be refreshed if it was already obtained before.
#### node\_ids
Returns a list of "node\_id"s of the monitoring servers of the `Updown.io` network. Takes an optional named boolean argument `:update` to indicate that the information should be refreshed if it was already obtained before.
#### node\_metrics
Returns a `Hash` of `Updown::Metrics` objects for the given "check\_id" about overall metrics per monitoring server in the `Updown.io` network, keyed to "node\_id". Optionally takes two named arguments.
`:from`, a `DateTime` object indicating the **start** of the period for which to provide overall metrics. Defaults to `DateTime.now.earlier(:1month)`.
`:to`, a `DateTime` object indicating the **end** of the period for which to provide overal metrics. Defaults to `DateTime.now`.
#### nodes
Returns a `Hash` with `Updown::Node` objects, keyed to their "node\_id". Takes an optional named boolean argument `:update` to indicate that the information should be refreshed if it was already obtained before.
#### ipv4-nodes
Returns a list of strings with the IPv4 numbers of the nodes in the `Updown.io` network that are executing the monitoring checks. Takes an optional named boolean argument `:update` to indicate that the information should be refreshed if it was already obtained before.
#### ipv6-nodes
Returns a list of strings with the IPv6 numbers of the nodes in the `Updown.io` network that are executing the monitoring checks. Takes an optional named boolean argument `:update` to indicate that the information should be refreshed if it was already obtained before.
#### overall\_metrics
Returns a `Updown::Metric` object for the given "check\_id". Optionally takes two named arguments.
`:from`, a `DateTime` object indicating the **start** of the period for which to provide overall metrics. Defaults to `DateTime.now.earlier(:1month)`.
`:to`, a `DateTime` object indicating the **end** of the period for which to provide overal metrics. Defaults to `DateTime.now`.
## Updown::Event
Objects of this type are **not** created automatically, but need to be created **directly** with the hash of the JSON received by a server that handles a webhook (so no `Updown` object needs to have been created).
### event
A string indicating the type of event. Can be either "check.down" when a monitored website appears to be down, or "check.up" to indicate that a monitored website has become operational again.
### check
The associated `Updown::Check` object.
### downtime
The associated `Updown::Node` object.
# AUTOMATICALLY CREATED CLASSES
## Updown::Check
An object containing the configuration of the monitoring that the `Updown.io` network does for a given website.
### alias
A string that describes the check, usually a human readable name of the website being monitored.
### apdex\_t
A rational number indicating the [APDEX](https://updown.uservoice.com/knowledgebase/articles/915588) threshold.
### custom\_headers
A hash of custom headers that will be sent to the monitored website.
### disabled\_locations
An array of monitoring locations that have been disabled, indicated by `node_id`.
### down
A boolean that will be true if the website is currently considered to be down.
### down\_since
A `DateTime` object indicating when it was first discovered that the website was down, if down. Else, `Any`.
### enabled
A boolean indicating whether the monitoring is currently active.
### error
A string containing the error that was encountered if the website is considered down.
### favicon\_url
The URL of the favicon small icon representing the website, if any.
### http\_body
Unclear what the functionality is.
### http\_verb
A string describing the HTTP method that will be used to monitor the website. Is one of "GET/HEAD", "POST", "PUT", "PATCH", "DELETE", "OPTIONS".
### last\_check\_at
A `DateTime` object indicating when the last check was done.
### last\_status
An integer indicating the last HTTP status that was received.
### mute\_until
A string indicating until when notifications will be muted. Is either a string consisting of "recovery", "forever", or a `DateTime` object indicating until when notifications will be muted, or `Any` if no muting is in effect.
### next\_check\_at
A `DateTime` object indicating when the next monitoring check will be performed.
### period
An integer indicating the number of seconds between monitoring checks.
### published
A boolean indicating whether the monitoring page is publicly accessible or not.
### ssl
An `Updown::Check::SSL` object, indicating SSL certificate status of the monitored website.
### string\_match
A string that should occur in the first 1MB of the body returned by the monitored website. An empty string indicates no content checking is done.
#### title
Returns a string consisting of either the `.alias`, or the `.url` if there is no alias specified.
### token
A string indicating the identifier (check-id) of this monitoring check configuration.
### uptime
A rational number between 0 and 100 indicating the percentage uptime of the monitored website.
### url
A string consisting of the URL that will be fetched to assess whether the monitored website is up and running.
## Updown::Check::SSL
This object generally occurs as the `ssl` method in the `Updown::Check` object.
### tested\_at
A `DateTime` object indicating when the certificate of the monitored website was checked.
### expires\_at
A `DateTime` object indicating when the certificate of the monitored website will expire.
### valid
A boolean indicating whether the certificate of the monitored website was valid the last time it was checked.
### error
A string indicating the error encountered when checking the validity of the certificate of the monitored server, if any.
## Updown::Downtime
An object describing a downtime period as seen by at least one of the monitoring servers in the `Updown.io` network.
### duration
An integer indicating the number of seconds of downtime, or `Any` if the downtime is not ended yet.
### ended\_at
A `DateTime` object indicating the moment the downtime appeared to have ended, or `Any` if the downtime is not ended yet..
### error
A string describing the reason the website appeared to be down, e.g. a HTTP status code like "500".
### id
A string identifying this particular downtime.
### partial
A boolean indicating whether the downtime was partial or complete (e.g. not being reachable by IPv6, but operating normally with IPv4).
### started\_at
A `DateTime` object indicating the moment the downtime appeared to have started.
## Updown::Metrics
A collection of statistical data applicable for the current situation, or for a certain period, or for a certain `Updown::Node`.
### apdex
A rational number indicating the current [APDEX](https://updown.uservoice.com/knowledgebase/articles/915588) for this set of metrics.
### requests
The associated `Updown::Metrics::Requests` object.
### timings
The associated `Updown::Metrics::Timings` object.
## Updown::Metrics::Requests
This object is usually returned by the "requests" method of the `Updown::Metrics` object.
### by\_response\_time
The associated `Updown::Metrics::Timings::ByResponseTime` object.
### failures
An integer indicating the number of monitoring requests that failed.
### samples
An integer indicating the number of monitoring requests that were done.
### satisfied
An integer indicating the number of monitoring requests that were processed to the user's [APDEX](https://updown.uservoice.com/knowledgebase/articles/915588) satisfaction.
### tolerated
An integer indicating the number of monitoring requests that were processed to the user's [APDEX](https://updown.uservoice.com/knowledgebase/articles/915588) tolerance.
## Updown::Metrics::Requests::ByResponseTime
This object is usually returned by the "by\_response\_time" method of the `Updown::Metrics::Request` object.
### under125
An integer indicating the number of monitoring requests that were processed under 125 milliseconds.
### under250
An integer indicating the number of monitoring requests that were processed under 250 milliseconds.
### under500
An integer indicating the number of monitoring requests that were processed under 500 milliseconds.
### under1000
An integer indicating the number of monitoring requests that were processed under 1 second.
### under2000
An integer indicating the number of monitoring requests that were processed under 2 seconds.
### under4000
An integer indicating the number of monitoring requests that were processed under 4 seconds.
## Updown::Metrics::Timings
This object is usually returned by the "timings" method of the `Updown::Metrics` object.
### connection
An integer indicating the average number of milliseconds it took to set up a connection with the monitored website.
### handshake
An integer indicating the average number of milliseconds it took to do the TLS handshake with the monitored website.
### namelookup
An integer indicating the average number of milliseconds it took to look up the name of the monitored website.
### redirect
An integer indicating the average number of milliseconds it took to process any redirect that the monitored website did. Any value greater than 0 probably indicates a misconfigured URL of the monitored website.
### response
An integer indicating the average number of milliseconds it took for the monitored website to initiate a response.
### total
An integer indicating the average number of milliseconds it took for the monitored website to complete the monitoring request.
## Updown::Node
An object containing information about a monitoring node in the `Updown.io` network.
### city
A string with the name of the city where the monitoring node is located.
### country
A string with the name of the country where the monitoring node is located.
### country\_code
A string with the 2-letter code of the country where the monitoring node is located.
### ip
A string indicating the IPv4 number of the monitoring node.
### ip6
A string indicating the IPv6 number of the monitoring node.
### lat
A rational number indicating the latitude of the monitoring node.
### lng
A rational number indicating the longitude of the monitoring node.
### node\_id
A string indicating the ID with which the monitoring node can be indicated.
## Updown::Webhook
Objects returned by the `webhooks` method of the `Updown` object.
### id
A string identifying this webhook.
### url
A string with the URL to which any notifications should be sent.
# AUTHOR
Elizabeth Mattijsen [liz@raku.rocks](mailto:liz@raku.rocks)
Source can be located at: <https://github.com/lizmat/Updown> . Comments and Pull Requests are welcome.
If you like this module, or what I'm doing more generally, committing to a [small sponsorship](https://github.com/sponsors/lizmat/) would mean a great deal to me!
# COPYRIGHT AND LICENSE
Copyright 2021, 2022, 2024 Elizabeth Mattijsen
This library is free software; you can redistribute it and/or modify it under the Artistic License 2.0.
|
## dist_github-IanTayler-MinG.md
# MinG
A small module for working with Stabler's Minimalist Grammars in Perl6.
[](https://travis-ci.org/IanTayler/MinG)
# STRUCTURE
As of now there are five (sub)modules: MinG, MinG::S13, MinG::S13::Logic, MinG::EDMG and MinG::From::Text.
In MinG, you'll find the necessary classes and subroutines for creating descriptions of Minimalist Grammars. It's not of much use by itself unless you're planning to implement your own parser/etc. and want to save yourself the time of having to define classes and useful functions.
In MinG::S13, you'll find Stabler's (2013) "Two models of minimalist, incremental syntactic analysis" parser. Currently, this parser analyses all possibilities, while Stabler's parser discards low-probability derivations. There's a helper submodule called MinG::S13::Logic.
MinG::EDMG is currently under construction. To check what has been implemented already, you can view the milestone "EDMG Implementation".
Finally, in MinG::From::Text you'll find a parser that creates MinG::Grammar-s out of text descriptions of MGs.
More documentation can be found in HTML files inside the doc/ directory.
# INSTALLATION
If you have perl6 and panda or zef, the following should suffice:
```
zef update
zef install MinG
```
If you don't, the easiest is probably to install rakudobrew <https://github.com/tadzik/rakudobrew> and then run:
```
rakudobrew build moar --gen-moar --gen-nqp --backend=moar
rakudobrew build zef
```
and you should be ready to install this module with zef.
The best option may be to install Rakudo Star <http://rakudo.org/how-to-get-rakudo/> which comes with zef and some common modules. There's lots of tutorials about how to get perl6. Follow one of them and make sure you install zef (or panda).
# EXAMPLE USAGE
As of now, someone who isn't interested in the inner workings of the module but wants to try out some minimalist grammars can easily create their grammar following this template:
```
START=F
word1 :: =F =F -F F
word2 :: =F F
:: =F =F F
.
.
.
word23 :: =F F ...
```
Without the dots, and changing *wordi* for your phonetic word (and, of course, changing F for whatever features you want your grammars to have). For two example grammars, check the resources/ directory.
You can save that in a file and call it using `ming-analyser.p6` (you can use `ming-analyser.p6-j` to run it on the jvm if you have the jvm backend installed and you so wish). Assuming the file is in the directory `$HOME/grammars/` and it's called gr0.mg, you can run:
```
ming-analyser.p6 $HOME/grammars/gr0.mg
```
Each line you write of input will be parsed using your grammar. You can parse several sentences in a series by separating them with a ';'. You can modify gr0.mg at any point and restart `ming-analyser.p6` to have your new grammar working.
If you want to try out the example grammars, they can be accessed by passing the arguments `--eng0` for a very small grammar of something-like-English, copied from Stabler (2013), `--espa0` for a not-so-small (but small) grammar of Spanish written by myself, and --nihongo0 for a minimal grammar of japanese used to exemplify complement directionality in EDMGs. Like so:
```
ming-analyser.p6 --eng0
ming-analyser.p6 --espa0
ming-analyser.p6 --nihongo0
```
When inputting lines, pay attention *not* to put a final dot to your sentence. "dance." is a different word from "dance".
Default output is a list of derived tree descriptions in qtree format. If you have a latex distribution with pdflatex and qtree installed (under GNU/Linux) you can run `ming-analyser` with option `compile=<filename.tex>` to get a pdf with all derived trees for each sentence you input. For example:
```
ming-analyser.p6 --espa0 --compile=mytex.tex
```
Will compile a pdf named mytex.pdf with all derived trees each time you pass a sentence. Do note it will rewrite existing pdfs, so you have to restart the script if you want to get the trees of various sentences in pdf form.
If you want to call a grammar from a file, it should go after all flags (as of now, only the --compile flag can reasonable go with a file). For example:
```
ming-analyser.p6 --compile=mytex.tex $HOME/grammars/gr0.mg
```
# CURRENTLY
* Has classes that correctly describe MGs (MinG::Grammar), MG-LIs (MinG::LItem) and MG-style-features (MinG::Feature).
* Has a subroutine (feature\_from\_str) that takes a string description of a feature (e.g. "=D") and returns a MinG::Feature.
* Has lexical trees for Stabler's (2013) parsing method (MinG::Grammar.litem\_tree).
* Automatically generates LaTeX/qtree code for trees. (Node.qtree inside MinG)
* Has a working parser for MGs! (MinG::S13::Parser or MinG::S13.parse\_and\_spit())
* Has a parser that reads grammars from a file! (MinG::From::Text)
* Has an analyser script (ming-analyser.p6) that can be used to read grammars from files and analyse sentences from standard input.
# TODO
* Allow some useful expansions of MGs (EDMGs are being implemented).
* Make the parser more efficient by adding probabilistic rule-following.
# MAYDO
* Create a probabilistic trainer.
* Use annotated corpora to build lexical entries.
* Use a small subset of predefined lexical entries and a non-annotated corpus to "guess" the feature specification of unknown lexical items.
* Create a Montague-style semantics for MG trees.
* Create a world-model for a knowledgable AI using such semantics.
# AUTHOR
Ian G Tayler, `<iangtayler@gmail.com>`
# COPYRIGHT AND LICENSE
Copyright © 2017, Ian G Tayler [iangtayler@gmail.com](mailto:iangtayler@gmail.com). All rights reserved. This program is free software; you can redistribute it and/or modify it under the Artistic License 2.0.
|
## dist_zef-jonathanstowe-JSON-Marshal.md
# JSON::Marshal
Make JSON from an Object (the opposite of JSON::Unmarshal)

## Synopsis
```
use JSON::Marshal;
class SomeClass {
has Str $.string;
has Int $.int;
has Version $.version is marshalled-by('Str');
}
my $object = SomeClass.new(string => "string", int => 42, version => Version.new("0.0.1"));
my Str $json = marshal($object); # -> "{ "string" : "string", "int" : 42, "version" : "0.0.1" }'
```
Or with *opt-in* marshalling:
```
use JSON::Marshal;
use JSON::OptIn;
class SomeClass {
has Str $.string is json;
has Int $.int is json;
has Str $.secret;
has Version $.version is marshalled-by('Str');
}
my $object = SomeClass.new(secret => "secret", string => "string", int => 42, version => Version.new("0.0.1"));
my Str $json = marshal($object, :opt-in); # -> "{ "string" : "string", "int" : 42, "version" : "0.0.1" }'
```
## Description
This provides a single exported subroutine to create a JSON representation
of an object. It should round trip back into an object of the same class
using [JSON::Unmarshal](https://github.com/tadzik/JSON-Unmarshal).
It only outputs the "public" attributes (that is those with accessors
created by declaring them with the '.' twigil. Attributes without acccessors
are ignored.
If you want to ignore any attributes without a value you can use the
`:skip-null` adverb to `marshal`, which will supress the
marshalling of any undefined attributes. Additionally if you want a
finer-grained control over this behaviour there is a 'json-skip-null'
attribute trait which will cause the specific attribute to be skipped
if it isn't defined irrespective of the `skip-null`. If
you want to always explicitly suppress the marshalling of an attribute then
the the trait `json-skip` on an attribute will prevent it being output
in the JSON.
By default *all* public attributes will be candidates to be marshalled to JSON,
which may not be convenient for all applications (for example only a small
number of attributes should be marshalled in a large class,) so the `marshal`
provides an `:opt-in` adverb that inverts the behaviour so that only those
attributes which have one of the traits that control marshalling
(with the exception of `json-skip`,) will be candidates. The `is json` trait
from [JSON::OptIn](https://github.com/jonathanstowe/JSON-OptIn) can be supplied to
an attribute to mark it for marshalling explicitly, (it is implicit in all the
other traits bar `json-skip`.)
To allow a finer degree of control of how an attribute is marshalled an
attribute trait `is marshalled-by` is provided, this can take either
a Code object (an anonymous subroutine,) which should take as an argument
the value to be marshalled and should return a value that can be completely
represented as JSON, that is to say a string, number or boolean or a Hash
or Array who's values are those things. Alternatively the name of a method
that will be called on the value, the return value being constrained as
above.
By default the JSON produced is *pretty* (that is newlines and indentation,)
which is nice for humans to read but has a lot of superfluous characters in
it, this can be controlled by passing `:!pretty` to `marshal`.
## Installation
Assuming you have a working Rakudo installation, you can install this with `zef` :
```
# From the source directory
zef install .
# Remote installation
zef install JSON::Marshal
```
## Support
Suggestions/patches are welcomed via github at
<https://github.com/jonathanstowe/JSON-Marshal/issues>
## Licence
Please see the <LICENCE> file in the distribution
© Jonathan Stowe 2015, 2016, 2017, 2018, 2019, 2020, 2021
|
## dist_zef-bduggan-App-tmeta.md
# tmeta
A console for your console
[](https://travis-ci.org/bduggan/tmeta)
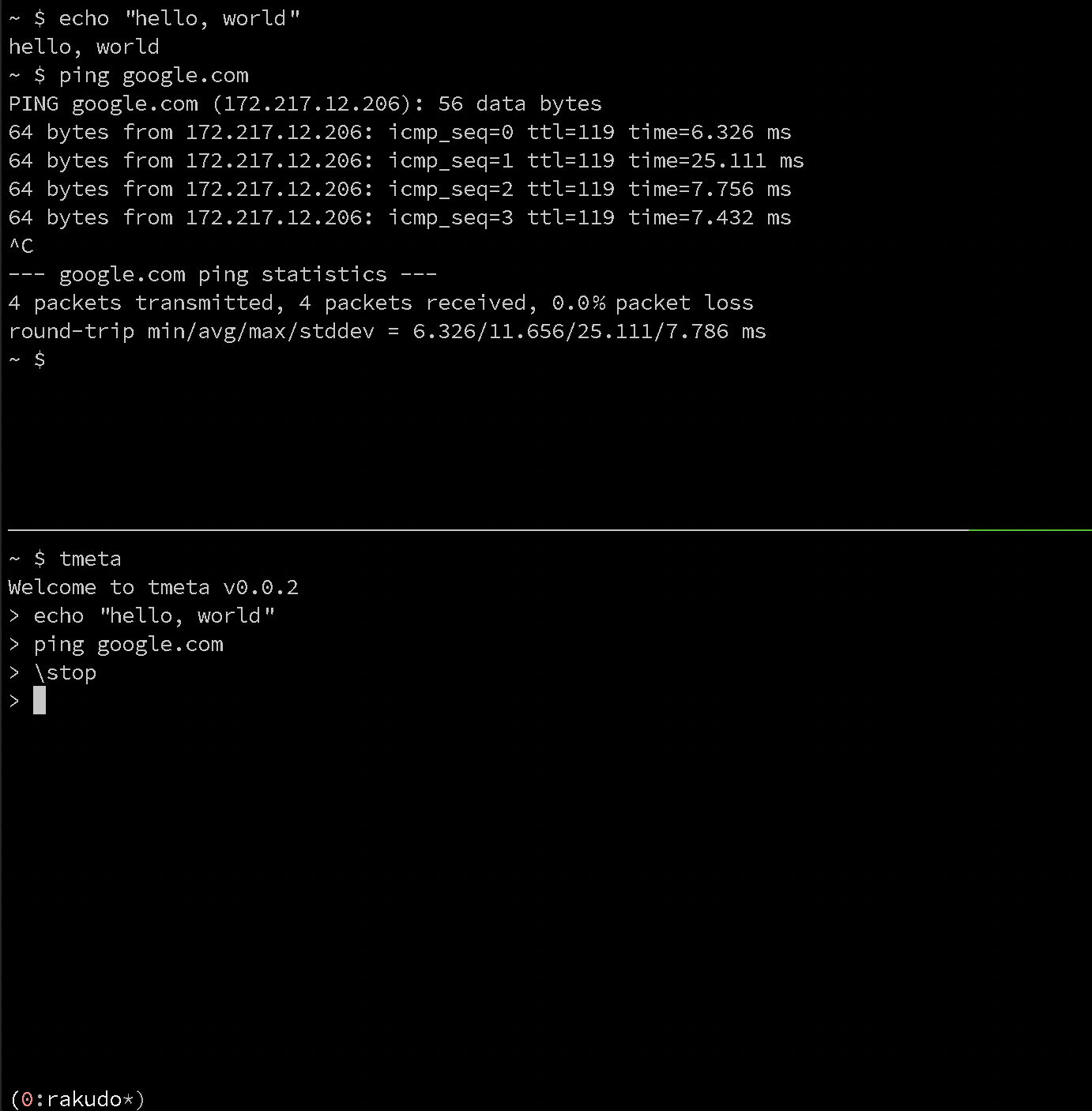
## Description
tmeta is a wrapper for tmux that supports
sending and receiving data to/from tmux panes.
Anything typed into the bottom pane is sent to the top one, but
lines that start with a backslash are commands for `tmeta`.
You can type `\help` to see all possible commands.
(To send a literal leading backslash, either start with a
space or start with a double backslash.)
## Why
Because you get:
* an uncluttered view of your commands separate from the output
* a local history for commands that are run remotely
* readline interface independent of the remote console
* scripting support for programs that require a TTY
* macros
* the ability to monitor or capture output
* other `expect`-like functionality
* controlled copy-and-paste operations into remote sessions
## Quick start
See below for installation.
There are a few different ways to start `tmeta`.
1. Start `tmux` yourself, then have `tmeta` split a window and
start up in its own pane:
```
$ tmux
$ tmeta
```
2. Let `tmeta` start tmux for you:
```
$ tmeta
```
1. Run a tmeta script. This will split and run in another pane.
```
$ tmux
$ tmeta script.tm
```
I use the `.tm` suffix for my `tmeta` scripts. If you do too, you
might like this [vim syntax file](syntax/tm.vim).
## What do I use it with
tmeta plays well with REPLs, or any console based
application that uses a tty. For instance, docker, rails
console, interactive ruby shell, the python debugger, the
jupyter console, psql, mysql, regular ssh sessions, local
terminal sessions, whatever
## More documentation
Please see the [documentation](https://github.com/bduggan/tmeta/blob/master/doc.md) for a complete list of commands.
## Examples
Show a list of commands.
```
> \help
```
Run `date` every 5 seconds until the output contains `02`
```
> date
> \repeat
> \await 02
```
Within a debugger session, send `next` every 2 seconds.
```
> next
> \repeat 2
```
Search the command history for the last occurrence of 'User' using [fzf](https://github.com/junegunn/fzf)
(readline command history works too)
```
> \find User
```
Search the output for "http"
```
> \grep http
```
Send a local file named `bigfile.rb` to a remote rails console
```
> \send bigfile.rb
```
Same thing, but throttle the copy-paste operation, sending 1 line per second:
```
> \delay 1
> \send bigfile.rb
```
Similar, but send it to an ssh console by first tarring and base64 encoding
and not echoing stdout, and note that 'something' can also be a directory:
```
> \xfer something
```
Run a command locally, sending each line of output to the remote console:
```
> \do echo date
```
Run a shell snippet locally, sending each line of output to the remote console:
```
> \dosh for i in `seq 5`; do echo "ping host-$i"; done
```
Start printing the numbers 1 through 100, one per second, but send a ctrl-c
when the number 10 is printed:
```
> \enq \stop
queue is now : \stop
> for i in `seq 100`; do echo $i; sleep 1; done
# .. starts running in other pane ...
> \await 10
Waiting for "10"
Then I will send:
\stop
Done: saw "10"
starting enqueued command: \stop
```
Add an alias `cat` which cats a local file
```
\alias cat \shell cat
```
Show a local file (do not send it to the other pane) using the above alias
```
\cat myfile
```
Edit a file named session.rb, in ~/.tmeta/scripts
```
\edit session.rb
```
After running the above, add this to session.rb:
```
irb
\expect irb(main):001:0>
"hello world"
\expect irb(main):002:0>
exit
```
Now running
```
\run session.rb
```
will start the interactive ruby console (irb) and the following
session should take place on the top panel:
```
$ irb
irb(main):001:0> "hello world"
=> "hello world"
irb(main):002:0> exit
$
```
## Installation
Prerequisites: fzf, tmux, libreadline, raku and a few modules
On OS/X
```
brew install fzf
brew install tmux
brew install rakudo
zef install https://github.com/bduggan/tmeta.git
```
You can also install raku with [rakubrew](https://rakubrew.org)
and then use `zef` to install tmeta.
## See also
* The [documentation](https://github.com/bduggan/tmeta/blob/master/doc.md), with links to the source
* The same [documentation](https://github.com/bduggan/tmeta/blob/master/help.md) as shown by the `\help` command
* This blog article: <https://blog.matatu.org/raku-tmeta>
|
## multipletypeconstraints.md
class X::Parameter::MultipleTypeConstraints
Compilation error due to a parameter with multiple type constraints
```raku
class X::Parameter::MultipleTypeConstraints does X::Comp { }
```
Compile time error thrown when a parameter has multiple type constraints. This is not allowed in Raku.0.
Example:
```raku
sub f(Cool Real $x) { }
```
dies with
「text」 without highlighting
```
```
Parameter $x may only have one prefix type constraint
```
```
# [Methods](#class_X::Parameter::MultipleTypeConstraints "go to top of document")[§](#Methods "direct link")
## [method parameter](#class_X::Parameter::MultipleTypeConstraints "go to top of document")[§](#method_parameter "direct link")
Returns the name of the offensive parameter.
|
## regexes.md
## Chunk 1 of 5
Regexes
Pattern matching against strings
A *regular expression* is a sequence of characters that defines a certain text pattern, typically one that one wishes to find in some large body of text.
In theoretical computer science and formal language theory, regular expressions are used to describe so-called [*regular languages*](https://en.wikipedia.org/wiki/Regular_language). Since their inception in the 1950's, practical implementations of regular expressions, for instance in the text search and replace functions of text editors, have outgrown their strict scientific definition. In acknowledgement of this, and in an attempt to disambiguate, a regular expression in Raku is normally referred to as a [`Regex`](/type/Regex) (from: *reg*ular *ex*pression), a term that is also in common use in other programming languages.
In Raku, regexes are written in a [*domain-specific language*](https://en.wikipedia.org/wiki/Domain-specific_language), i.e. a sublanguage or [*slang*](/language/slangs). This page describes this language, and explains how regexes can be used to search for text patterns in strings in a process called *pattern matching*.
# [Lexical conventions](#Regexes "go to top of document")[§](#Lexical_conventions "direct link")
Fundamentally, Raku regexes are very much like subroutines: both are code objects, and just as you can have anonymous subs and named subs, you can have anonymous and named regexes.
A regex, whether anonymous or named, is represented by a [`Regex`](/type/Regex) object. Yet, the syntax for constructing anonymous and named [`Regex`](/type/Regex) objects differs. We will therefore discuss them in turn.
## [Anonymous regex definition syntax](#Regexes "go to top of document")[§](#Anonymous_regex_definition_syntax "direct link")
An anonymous regex may be constructed in one of the following ways:
```raku
rx/pattern/; # an anonymous Regex object; 'rx' stands for 'regex'
/pattern/; # an anonymous Regex object; shorthand for 'rx/.../'
regex { pattern }; # keyword-declared anonymous regex; this form is
# intended for defining named regexes and is discussed
# in that context in the next section
```
The `rx/ /` form has two advantages over the bare shorthand form `/ /`.
Firstly, it enables the use of delimiters other than the slash, which may be used to improve the readability of the regex definition:
```raku
rx{ '/tmp/'.* }; # the use of curly braces as delimiters makes this first
rx/ '/tmp/'.* /; # definition somewhat easier on the eyes than the second
```
Although the choice is vast, not every character may be chosen as an alternative regex delimiter:
* You cannot use whitespace or alphanumeric characters as delimiters. Whitespace in regex definition syntax is generally optional, except where it is required to distinguish from function call syntax (discussed hereafter).
* Parentheses can be used as alternative regex delimiters, but only with a space between `rx` and the opening delimiter. This is because identifiers that are immediately followed by parentheses are always parsed as a subroutine call. For example, in `rx()` the [call operator](/language/operators#postcircumfix_(_)) `()` invokes the subroutine `rx`. The form `rx ( abc )`, however, *does* define a [`Regex`](/type/Regex) object.
* Use of a colon as a delimiter would clash with the use of [adverbs](/language/regexes#Adverbs), which take the form `:adverb`; accordingly, such use of the colon is forbidden.
* The hash character `#` is not available as a delimiter since it is parsed as the start of a [comment](/language/syntax#Single-line_comments) that runs until the end of the line.
Secondly, the `rx` form allows you to insert [regex adverbs](/language/regexes#Regex_adverbs) between `rx` and the opening delimiter to modify the definition of the entire regex. This is equivalent to inserting the adverb at the beginning of the regex, but may be clearer:
```raku
rx:r:s/pattern/; # :r (:ratchet) and :s (:sigspace) adverbs, defining
# a ratcheting regex in which whitespace is significant
rx/:r:s pattern/; # Same, but possibly less readable
```
Although anonymous regexes are not, as such, *named*, they may effectively be given a name by putting them inside a named variable, after which they can be referenced, both outside of an embedding regex and from within an embedding regex by means of [interpolation](/language/regexes#Regex_interpolation):
```raku
my $regex = / R \w+ /;
say "Zen Buddhists like Raku too" ~~ $regex; # OUTPUT: «「Raku」»
my $regex = /pottery/;
"Japanese pottery rocks!" ~~ / <$regex> /; # Interpolation of $regex into /.../
say $/; # OUTPUT: «「pottery」»
```
## [Named regex definition syntax](#Regexes "go to top of document")[§](#Named_regex_definition_syntax "direct link")
A named regex may be constructed using the `regex` declarator as follows:
```raku
regex R { pattern }; # a named Regex object, named 'R'
```
Unlike with the `rx` form, you cannot chose your preferred delimiter: curly braces are mandatory. In this regard it should be noted that the definition of a named regex using the `regex` form is syntactically similar to the definition of a subroutine:
```raku
my sub S { /pattern/ }; # definition of Sub object (returning a Regex)
my regex R { pattern }; # definition of Regex object
```
which emphasizes the fact that a [`Regex`](/type/Regex) object represents code rather than data:
```raku
&S ~~ Code; # OUTPUT: «True»
&R ~~ Code; # OUTPUT: «True»
&R ~~ Method; # OUTPUT: «True» (A Regex is really a Method!)
```
Also unlike with the `rx` form for defining an anonymous regex, the definition of a named regex using the `regex` keyword does not allow for adverbs to be inserted before the opening delimiter. Instead, adverbs that are to modify the entire regex pattern may be included first thing within the curly braces:
```raku
regex R { :i pattern }; # :i (:ignorecase), renders pattern case insensitive
```
Alternatively, by way of shorthand, it is also possible (and recommended) to use the `rule` and `token` variants of the `regex` declarator for defining a [`Regex`](/type/Regex) when the `:ratchet` and `:sigspace` adverbs are of interest:
```raku
regex R { :r pattern }; # apply :r (:ratchet) to entire pattern
```
and, alternatively
```raku
token R { pattern }; # same thing: 'token' implies ':r'
```
Or
```raku
regex R { :r :s pattern }; # apply :r (:ratchet) and :s (:sigspace) to pattern
```
with this alternative:
```raku
rule R { pattern }; # same thing: 'rule' implies ':r:s'
```
Named regexes may be used as building blocks for other regexes, as they are methods that may called from within other regexes using the `<regex-name>` syntax. When they are used this way, they are often referred to as *subrules*; see for more details on their use [here](/language/regexes#Subrules). [`Grammar`](/type/Grammar)s are the natural habitat of subrules, but many common predefined character classes are also implemented as named regexes.
## [Regex readability: whitespace and comments](#Regexes "go to top of document")[§](#Regex_readability:_whitespace_and_comments "direct link")
Whitespace in regexes is ignored unless the [`:sigspace`](/language/regexes#Sigspace) adverb is used to make whitespace syntactically significant.
In addition to whitespace, comments may be used inside of regexes to improve their comprehensibility just as in code in general. This is true for both [single line comments](/language/syntax#Single-line_comments) and [multi line/embedded comments](/language/syntax#Multi-line_/_embedded_comments):
```raku
my $regex = rx/ \d ** 4 #`(match the year YYYY)
'-'
\d ** 2 # ...the month MM
'-'
\d ** 2 /; # ...and the day DD
say '2015-12-25'.match($regex); # OUTPUT: «「2015-12-25」»
```
## [Match syntax](#Regexes "go to top of document")[§](#Match_syntax "direct link")
There are a variety of ways to match a string against a regex. Irrespective of the syntax chosen, a successful match results in a [`Match`](/type/Match) object. In case the match is unsuccessful, the result is [`Nil`](/type/Nil). In either case, the result of the match operation is available via the special match variable [`$/`](/syntax/$$SOLIDUS).
The most common ways to match a string against an anonymous regex `/pattern/` or against a named regex `R` include the following:
* *Smartmatch: "string" ~~ /pattern/, or "string" ~~ /<R>/*
[Smartmatching](/language/operators#index-entry-smartmatch_operator) a string against a [`Regex`](/type/Regex) performs a regex match of the string against the [`Regex`](/type/Regex):
Raku highlighting
```
say "Go ahead, make my day." ~~ / \w+ /; # OUTPUT: «「Go」»
my regex R { me|you };
say "You talkin' to me?" ~~ / <R> /; # OUTPUT: «「me」 R => 「me」»
say "May the force be with you." ~~ &R ; # OUTPUT: «「you」»
```
The different outputs of the last two statements show that these two ways of smartmatching against a named regex are not identical. The difference arises because the method call `<R>` from within the anonymous regex `/ /` installs a so-called ['named capture'](/language/regexes#Named_captures) in the [`Match`](/type/Match) object, while the smartmatch against the named [`Regex`](/type/Regex) as such does not.
* *Explicit topic match: m/pattern/, or m/<R>/*
The match operator `m/ /` immediately matches the topic variable [`$_`](/language/variables#index-entry-topic_variable) against the regex following the `m`.
As with the `rx/ /` syntax for regex definitions, the match operator may be used with adverbs in between `m` and the opening regex delimiter, and with delimiters other than the slash. However, while the `rx/ /` syntax may only be used with [*regex adverbs*](/language/regexes#Regex_adverbs) that affect the compilation of the regex, the `m/ /` syntax may additionally be used with [*matching adverbs*](/language/regexes#Matching_adverbs) that determine how the regex engine is to perform pattern matching.
Here's an example that illustrates the primary difference between the `m/ /` and `/ /` syntax:
Raku highlighting
```
my $match;
$_ = "abc";
$match = m/.+/; say $match; say $match.^name; # OUTPUT: «「abc」Match»
$match = /.+/; say $match; say $match.^name; # OUTPUT: «/.+/Regex»
```
* *Implicit topic match in sink and Boolean contexts*
In case a [`Regex`](/type/Regex) object is used in sink context, or in a context in which it is coerced to [`Bool`](/type/Bool), the topic variable [`$_`](/language/variables#index-entry-topic_variable) is automatically matched against it:
Raku highlighting
```
$_ = "dummy string"; # Set the topic explicitly
rx/ s.* /; # Regex object in sink context matches automatically
say $/; # OUTPUT: «「string」»
say $/ if rx/ d.* /; # Regex object in Boolean context matches automatically
# OUTPUT: «「dummy string」»
```
* *Match method: "string".match: /pattern/, or "string".match: /<R>/*
The [`match`](/type/Str#method_match) method is analogous to the `m/ /` operator discussed above. Invoking it on a string, with a [`Regex`](/type/Regex) as an argument, matches the string against the [`Regex`](/type/Regex).
* *Parsing grammars: grammar-name.parse($string)*
Although parsing a [grammar](/language/grammars) involves more than just matching a string against a regex, this powerful regex-based text destructuring tool can't be left out from this overview of common pattern matching methods.
If you feel that your needs exceed what simple regexes have to offer, check out this [grammar tutorial](/language/grammar_tutorial) to take regexes to the next level.
# [Literals and metacharacters](#Regexes "go to top of document")[§](#Literals_and_metacharacters "direct link")
A regex describes a pattern to be matched in terms of literals and metacharacters. Alphanumeric characters and the underscore `_` constitute the literals: these characters match themselves and nothing else. Other characters act as metacharacters and may, as such, have a special meaning, either by themselves (such as the dot `.`, which serves as a wildcard) or together with other characters in larger metasyntactic constructs (such as `<?before ...>`, which defines a lookahead assertion).
In its simplest form a regex comprises only literals:
```raku
/Cześć/; # "Hello" in Polish
/こんばんは/; # "Good afternoon" in Japanese
/Καλησπέρα/; # "Good evening" in Greek
```
If you want a regex to literally match one or more characters that normally act as metacharacters, those characters must either be escaped using a backslash, or be quoted using single or double quotes.
The backslash serves as a switch. It switches a single metacharacter into a literal, and vice versa:
```raku
/ \# /; # matches the hash metacharacter literally
/ \w /; # turns literal 'w' into a character class (see below)
/Hallelujah\!/; # matches string 'Hallelujah!' incl. exclamation mark
```
Even if a metacharacter does not (yet) have a special meaning in Raku, escaping (or quoting) it is required to ensure that the regex compiles and matches the character literally. This allows the clear distinction between literals and metacharacters to be maintained. So, for instance, to match a comma this will work:
```raku
/ \, /; # matches a literal comma ','
```
while this will fail:
```raku
/ , /; # !! error: an as-yet meaningless/unrecognized metacharacter
# does not automatically match literally
```
While an escaping backslash exerts its effect on the next individual character, both a single metacharacter and a sequence of metacharacters may be turned into literally matching strings by quoting them in single or double quotes:
```raku
/ "abc" /; # quoting literals does not make them more literal
/ "Hallelujah!" /; # yet, this form is generally preferred over /Hallelujah\!/
/ "two words" /; # quoting a space renders it significant, so this matches
# the string 'two words' including the intermediate space
/ '#!:@' /; # this regex matches the string of metacharacters '#!:@'
```
Quoting does not necessarily turn every metacharacter into a literal, however. This is because quotes follow Raku's normal [rules for interpolation](/language/quoting#The_Q_lang). In particular, `「…」` quotes do not allow any interpolation; single quotes (either `'…'` or `‘…’`) allow the backslash to escape single quotes and the backslash itself; and double quotes (either `"…"` or `“…”`) enable the interpolation of variables and code blocks of the form `{…}`. Hence all of this works:
```raku
/ '\\\'' /; # matches a backslash followed by a single quote: \'
/ 「\'」 /; # also matches a backslash followed by a single quote
my $x = 'Hi';
/ "$x there!" /; # matches the string 'Hi there!'
/ "1 + 1 = {1+1}" /; # matches the string '1 + 1 = 2'
```
while these examples illustrate mistakes that you will want to avoid:
```raku
/ '\' /; # !! error: this is NOT the way to literally match a
# backslash because now it escapes the second quote
/"Price tag $0.50"/; # !! error: "$0" is interpreted as the first positional
# capture (which is Nil), not as '$0'
```
Strings are searched left to right, so it is enough if only part of the string matches the regex:
```raku
if 'Life, the Universe and Everything' ~~ / and / {
say ~$/; # OUTPUT: «and»
say $/.prematch; # OUTPUT: «Life, the Universe »
say $/.postmatch; # OUTPUT: « Everything»
say $/.from; # OUTPUT: «19»
say $/.to; # OUTPUT: «22»
};
```
Match results are always stored in the `$/` variable and are also returned from the match. They are both of type [`Match`](/type/Match) if the match was successful; otherwise both are of type [`Nil`](/type/Nil).
# [Wildcards](#Regexes "go to top of document")[§](#Wildcards "direct link")
An unescaped dot `.` in a regex matches any single character.
So, these all match:
```raku
'raku' ~~ /rak./; # matches the whole string
'raku' ~~ / rak . /; # the same; whitespace is ignored
'raku' ~~ / ra.u /; # the . matches the k
'raker' ~~ / rak. /; # the . matches the e
```
while this doesn't match:
```raku
'raku' ~~ / . rak /;
```
because there's no character to match before `rak` in the target string.
Notably `.` also matches a logical newline `\n`:
```raku
my $text = qq:to/END/
Although I am a
multi-line text,
I can be matched
with /.*/.
END
;
say $text ~~ / .* /;
# OUTPUT: «「Although I am amulti-line text,I can be matchedwith /.*/.」»
```
# [Character classes](#Regexes "go to top of document")[§](#Character_classes "direct link")
## [Backslashed character classes](#Regexes "go to top of document")[§](#Backslashed_character_classes "direct link")
There are predefined character classes of the form `\w`. Its negation is written with an uppercase letter, `\W`.
### [`\n` and `\N`](#Regexes "go to top of document")[§](#\n_and_\N "direct link")
`\n` matches a logical newline. `\N` matches a single character that's not a logical newline.
The definition of what constitutes a logical newline follows the [Unicode definition of a line boundary](https://unicode.org/reports/tr18/#Line_Boundaries) and includes in particular all of: a line feed (LF) `\U+000A`, a vertical tab (VT) `\U+000B`, a form feed (FF) `\U+000C`, a carriage return (CR) `\U+000D`, and the Microsoft Windows style newline sequence CRLF.
The interpretation of `\n` in regexes is independent of the value of the variable `$?NL` controlled by the [newline pragma](/language/pragmas#newline).
### [`\t` and `\T`](#Regexes "go to top of document")[§](#\t_and_\T "direct link")
`\t` matches a single tab/tabulation character, `U+0009`. `\T` matches a single character that is not a tab.
Note that exotic tabs like the `U+000B VERTICAL TABULATION` character are not included here.
### [`\h` and `\H`](#Regexes "go to top of document")[§](#\h_and_\H "direct link")
`\h` matches a single horizontal whitespace character. `\H` matches a single character that is not a horizontal whitespace character.
Examples of horizontal whitespace characters are
「text」 without highlighting
```
```
U+0020 SPACE
U+00A0 NO-BREAK SPACE
U+0009 CHARACTER TABULATION
U+2001 EM QUAD
```
```
Vertical whitespace such as newline characters are explicitly excluded; those can be matched with `\v`; `\s` matches any kind of whitespace.
### [`\v` and `\V`](#Regexes "go to top of document")[§](#\v_and_\V "direct link")
`\v` matches a single vertical whitespace character. `\V` matches a single character that is not vertical whitespace.
Examples of vertical whitespace characters:
「text」 without highlighting
```
```
U+000A LINE FEED
U+000B VERTICAL TABULATION
U+000C FORM FEED
U+000D CARRIAGE RETURN
U+0085 NEXT LINE
U+2028 LINE SEPARATOR
U+2029 PARAGRAPH SEPARATOR
```
```
Use `\s` to match any kind of whitespace, not just vertical whitespace.
### [`\s` and `\S`](#Regexes "go to top of document")[§](#\s_and_\S "direct link")
`\s` matches a single whitespace character. `\S` matches a single character that is not whitespace.
```raku
say $/.prematch if 'Match the first word.' ~~ / \s+ /;
# OUTPUT: «Match»
```
### [`\d` and `\D`](#Regexes "go to top of document")[§](#\d_and_\D "direct link")
`\d` matches a single decimal digit (Unicode General Category *Number, Decimal Digit*, `Nd`); conversely, `\D` matches a single character that is *not* a decimal digit.
```raku
'ab42' ~~ /\d/ and say ~$/; # OUTPUT: «4»
'ab42' ~~ /\D/ and say ~$/; # OUTPUT: «a»
```
Note that not only the Arabic digits (commonly used in the Latin alphabet) match `\d`, but also decimal digits from other scripts.
Examples of decimal digits include:
「text」 without highlighting
```
```
U+0035 5 DIGIT FIVE
U+0BEB ௫ TAMIL DIGIT FIVE
U+0E53 ๓ THAI DIGIT THREE
U+17E5 ៥ KHMER DIGIT FIVE
```
```
Also note that "decimal digit" is a narrower category than "Number" because (Unicode) numbers include not only decimal numbers (`Nd`) but also letter numbers (`Nl`) and other numbers (`No`) Examples of Unicode numbers that are not decimal digits include:
「text」 without highlighting
```
```
U+2464 ⑤ CIRCLED DIGIT FIVE
U+2476 ⑶ PARENTHESIZED DIGIT THREE
U+2083 ₃ SUBSCRIPT THREE
```
```
To match against all numbers, you can use the [Unicode property](#Unicode_properties) `N`:
```raku
say '⑤' ~~ /<:N>/ # OUTPUT: «「⑤」»
```
### [`\w` and `\W`](#Regexes "go to top of document")[§](#\w_and_\W "direct link")
`\w` matches a single word character, i.e. a letter (Unicode category L), a digit or an underscore. `\W` matches a single character that is not a word character.
Examples of word characters:
「text」 without highlighting
```
```
0041 A LATIN CAPITAL LETTER A
0031 1 DIGIT ONE
03B4 δ GREEK SMALL LETTER DELTA
03F3 ϳ GREEK LETTER YOT
0409 Љ CYRILLIC CAPITAL LETTER LJE
```
```
### [`\c` and `\C`](#Regexes "go to top of document")[§](#\c_and_\C "direct link")
`\c` takes a parameter delimited by square-brackets which is the name of a Unicode character as it appears in the [Unicode Character Database (UCD)](https://unicode.org/ucd/) and matches that specific character. For example:
```raku
'a.b' ~~ /\c[FULL STOP]/ and say ~$/; # OUTPUT: «.»
```
`\C` matches a single character that is not the named Unicode character.
Note that the word "character" is used, here, in the sense that the UCD does, but because Raku uses [NFG](/language/glossary#NFG), combining code points and the base characters to which they are attached, will generally not match individually. For example if you compose `"ü"` as `"u\x[0308]"`, that works just fine, but matching may surprise you:
```raku
say "u\x[0308]" ~~ /\c[LATIN SMALL LETTER U]/; # OUTPUT: «Nil»
```
To match the unmodified character, you can use the [`:ignoremark`](#Ignoremark) adverb.
### [`\x` and `\X`](#Regexes "go to top of document")[§](#\x_and_\X "direct link")
`\x` takes a parameter delimited by square-brackets which is the hexadecimal representation of the Unicode codepoint representing the character to be matched. For example:
```raku
'a.b' ~~ /\x[2E]/ and say ~$/; # OUTPUT: «.»
```
`\X` matches a single character that is not the given Unicode codepoint.
In addition, `\x` and `\X` can be used without square brackets, in which case, any characters that follow the `x` or `X` that are valid hexadecimal digits will be consumed. This means that all of these are equivalent:
```raku
/\x2e/ and /\x002e/ and /\x00002e/
```
But this format can be ambiguous, so the use of surrounding whitespace is highly recommended in non-trivial expressions.
For additional provisos with respect to combining codepoints, see [`\c` and `\C`](#\c_and_\C).
## [Predefined character classes](#Regexes "go to top of document")[§](#Predefined_character_classes "direct link")
| Class | Shorthand | Description |
| --- | --- | --- |
| <alpha> | | Alphabetic characters plus underscore (\_) |
| <digit> | \d | Decimal digits |
| <xdigit> | | Hexadecimal digit [0-9A-Fa-f] |
| <alnum> | \w | <alpha> plus <digit> |
| <punct> | | Punctuation and Symbols (only Punct beyond ASCII) |
| <graph> | | <alnum> plus <punct> |
| <space> | \s | Whitespace |
| <cntrl> | | Control characters |
| <print> | | <graph> plus <space>, but no <cntrl> |
| <blank> | \h | Horizontal whitespace |
| <lower> | <:Ll> | Lowercase characters |
| <upper> | <:Lu> | Uppercase characters |
The predefined character classes in the leftmost column are all of the form `<name>`, a hint to the fact that they are implemented as built-in [named regexes](/language/regexes#Subrules). As such they are subject to the usual capturing semantics. This means that if a character class is called with the syntax `<name>` (i.e. as indicated in the leftmost column), it will not only match, but also capture, installing a correspondingly named ['named capture'](/language/regexes#Named_captures) in the resulting [`Match`](/type/Match). In case just a match and no capture is desired, the capture may be suppressed through the use of call syntax that includes a leading dot: `<.name>`.
## [Predefined Regexes](#Regexes "go to top of document")[§](#Predefined_Regexes "direct link")
Besides the built-in character classes, Raku provides built-in [anchors](/language/regexes#Anchors) and [zero-width assertions](/language/regexes#Zero-width_assertions) defined as named regexes. These include `wb` (word boundary), `ww` (within word), and `same` (the next and previous character are the same). See the [anchors](/language/regexes#Anchors) and [zero-width assertions](/language/regexes#Zero-width_assertions) sections for details.
Raku also provides the two predefined tokens (i.e., regexes that don't [backtrack](/language/regexes#Backtracking)) shown below:
| Token | Regex equivalent | Description |
| --- | --- | --- |
| <ws> | <!ww> \s\*: | Word-separating whitespace (including zero, e.g. at EOF) |
| <ident> | <.alpha> \w\*: | Basic identifier (no support for ' or -). |
## [Unicode properties](#Regexes "go to top of document")[§](#Unicode_properties "direct link")
The character classes mentioned so far are mostly for convenience; another approach is to use Unicode character properties. These come in the form `<:property>`, where `property` can be a short or long Unicode General Category name. These use pair syntax.
To match against a Unicode property you can use either smartmatch or [`uniprop`](/routine/uniprop):
```raku
"a".uniprop('Script'); # OUTPUT: «Latin»
"a" ~~ / <:Script<Latin>> /; # OUTPUT: «「a」»
"a".uniprop('Block'); # OUTPUT: «Basic Latin»
"a" ~~ / <:Block('Basic Latin')> /; # OUTPUT: «「a」»
```
These are the Unicode general categories used for matching:
| Short | Long |
| --- | --- |
| L | Letter |
| LC | Cased\_Letter |
| Lu | Uppercase\_Letter |
| Ll | Lowercase\_Letter |
| Lt | Titlecase\_Letter |
| Lm | Modifier\_Letter |
| Lo | Other\_Letter |
| M | Mark |
| Mn | Nonspacing\_Mark |
| Mc | Spacing\_Mark |
| Me | Enclosing\_Mark |
| N | Number |
| Nd | Decimal\_Number or digit |
| Nl | Letter\_Number |
| No | Other\_Number |
| P | Punctuation or punct |
| Pc | Connector\_Punctuation |
| Pd | Dash\_Punctuation |
| Ps | Open\_Punctuation |
| Pe | Close\_Punctuation |
| Pi | Initial\_Punctuation |
| Pf | Final\_Punctuation |
| Po | Other\_Punctuation |
| S | Symbol |
| Sm | Math\_Symbol |
| Sc | Currency\_Symbol |
| Sk | Modifier\_Symbol |
| So | Other\_Symbol |
| Z | Separator |
| Zs | Space\_Separator |
| Zl | Line\_Separator |
| Zp | Paragraph\_Separator |
| C | Other |
| Cc | Control or cntrl |
| Cf | Format |
| Cs | Surrogate |
| Co | Private\_Use |
| Cn | Unassigned |
For example, `<:Lu>` matches a single, uppercase letter.
Its negation is this: `<:!property>`. So, `<:!Lu>` matches a single character that is not an uppercase letter.
Categories can be used together, with an infix operator:
| Operator | Meaning |
| --- | --- |
| + | set union |
| \- | set difference |
To match either a lowercase letter or a number, write `<:Ll+:N>` or `<:Ll+:Number>` or `<+ :Lowercase_Letter + :Number>`.
It's also possible to group categories and sets of categories with parentheses; for example:
```raku
say $0 if 'raku9' ~~ /\w+(<:Ll+:N>)/ # OUTPUT: «「9」»
```
## [Enumerated character classes and ranges](#Regexes "go to top of document")[§](#Enumerated_character_classes_and_ranges "direct link")
Sometimes the pre-existing wildcards and character classes are not enough. Fortunately, defining your own is fairly simple. Within `<[ ]>`, you can put any number of single characters and ranges of characters (expressed with two dots between the end points), with or without whitespace.
```raku
"abacabadabacaba" ~~ / <[ a .. c 1 2 3 ]>* /;
# Unicode hex codepoint range
"ÀÁÂÃÄÅÆ" ~~ / <[ \x[00C0] .. \x[00C6] ]>* /;
# Unicode named codepoint range
"αβγ" ~~ /<[\c[GREEK SMALL LETTER ALPHA]..\c[GREEK SMALL LETTER GAMMA]]>*/;
# Non-alphanumeric
'$@%!' ~~ /<[ ! @ $ % ]>+/ # OUTPUT: «「$@%!」»
```
As the last line above illustrates, within `<[ ]>` you do *not* need to quote or escape most non-alphanumeric characters the way you do in regex text outside of `<[ ]>`. You do, however, need to escape the much smaller set of characters that have special meaning within `<[ ]>`, such as `\`, `[`, and `]`.
To escape characters that would have some meaning inside the `<[ ]>`, precede the character with a `\`.
```raku
say "[ hey ]" ~~ /<-[ \] \[ \s ]>+/; # OUTPUT: «「hey」»
```
You do not have the option of quoting special characters inside a `<[ ]>` – a `'` just matches a literal `'`.
Within the `< >` you can use `+` and `-` to add or remove multiple range definitions and even mix in some of the Unicode categories above. You can also write the backslashed forms for character classes between the `[ ]`.
```raku
/ <[\d] - [13579]> /;
# starts with \d and removes odd ASCII digits, but not quite the same as
/ <[02468]> /;
# because the first one also contains "weird" unicodey digits
```
You can include Unicode properties in the list as well:
```raku
/<:Zs + [\x9] - [\xA0] - [\x202F] >/
# Any character with "Zs" property, or a tab, but not a "no-break space" or "narrow no-break space"
```
To negate a character class, put a `-` after the opening angle bracket:
```raku
say 'no quotes' ~~ / <-[ " ]> + /; # <-["]> matches any character except "
```
A common pattern for parsing quote-delimited strings involves negated character classes:
```raku
say '"in quotes"' ~~ / '"' <-[ " ]> * '"'/;
```
This regex first matches a quote, then any characters that aren't quotes, and then a quote again. The meaning of `*` and `+` in the examples above are explained in the next section on quantifiers.
Just as you can use the `-` for both set difference and negation of a single value, you can also explicitly put a `+` in front:
```raku
/ <+[123]> / # same as <[123]>
```
# [Quantifiers](#Regexes "go to |
## regexes.md
## Chunk 2 of 5
top of document")[§](#Quantifiers "direct link")
A quantifier makes the preceding atom match a variable number of times. For example, `a+` matches one or more `a` characters.
Quantifiers bind tighter than concatenation, so `ab+` matches one `a` followed by one or more `b`s. This is different for quotes, so `'ab'+` matches the strings `ab`, `abab`, `ababab` etc.
## [One or more: `+`](#Regexes "go to top of document")[§](#One_or_more:_+ "direct link")
The `+` quantifier makes the preceding atom match one or more times, with no upper limit.
For example, to match strings of the form `key=value`, you can write a regex like this:
```raku
/ \w+ '=' \w+ /
```
## [Zero or more: `*`](#Regexes "go to top of document")[§](#Zero_or_more:_* "direct link")
The `*` quantifier makes the preceding atom match zero or more times, with no upper limit.
For example, to allow optional whitespace between `a` and `b` you can write:
```raku
/ a \s* b /
```
## [Zero or one: `?`](#Regexes "go to top of document")[§](#Zero_or_one:_? "direct link")
The `?` quantifier makes the preceding atom match zero or once.
For example, to match `dog` or `dogs`, you can write:
```raku
/ dogs? /
```
## [General quantifier: `** min..max`](#Regexes "go to top of document")[§](#General_quantifier:_**_min..max "direct link")
To quantify an atom an arbitrary number of times, use the `**` quantifier, which takes a single [`Int`](/type/Int) or a [`Range`](/type/Range) on the right-hand side that specifies the number of times to match. If a [`Range`](/type/Range) is specified, the end-points specify the minimum and maximum number of times to match.
```raku
say 'abcdefg' ~~ /\w ** 4/; # OUTPUT: «「abcd」»
say 'a' ~~ /\w ** 2..5/; # OUTPUT: «Nil»
say 'abc' ~~ /\w ** 2..5/; # OUTPUT: «「abc」»
say 'abcdefg' ~~ /\w ** 2..5/; # OUTPUT: «「abcde」»
say 'abcdefg' ~~ /\w ** 2^..^5/; # OUTPUT: «「abcd」»
say 'abcdefg' ~~ /\w ** ^3/; # OUTPUT: «「ab」»
say 'abcdefg' ~~ /\w ** 1..*/; # OUTPUT: «「abcdefg」»
```
Only basic literal syntax for the right-hand side of the quantifier is supported, to avoid ambiguities with other regex constructs. If you need to use a more complex expression, for example, a [`Range`](/type/Range) made from variables, enclose the [`Range`](/type/Range) in curly braces:
```raku
my $start = 3;
say 'abcdefg' ~~ /\w ** {$start .. $start+2}/; # OUTPUT: «「abcde」»
say 'abcdefg' ~~ /\w ** {π.Int}/; # OUTPUT: «「abc」»
```
Negative values are treated like zero:
```raku
say 'abcdefg' ~~ /\w ** {-Inf}/; # OUTPUT: «「」»
say 'abcdefg' ~~ /\w ** {-42}/; # OUTPUT: «「」»
say 'abcdefg' ~~ /\w ** {-10..-42}/; # OUTPUT: «「」»
say 'abcdefg' ~~ /\w ** {-42..-10}/; # OUTPUT: «「」»
```
If then, the resultant value is `Inf` or `NaN` or the resultant [`Range`](/type/Range) is empty, non-Numeric, contains `NaN` end-points, or has minimum effective end-point as `Inf`, the `X::Syntax::Regex::QuantifierValue` exception will be thrown:
```raku
(try say 'abcdefg' ~~ /\w ** {42..10}/ )
orelse say ($!.^name, $!.empty-range);
# OUTPUT: «(X::Syntax::Regex::QuantifierValue True)»
(try say 'abcdefg' ~~ /\w ** {Inf..Inf}/)
orelse say ($!.^name, $!.inf);
# OUTPUT: «(X::Syntax::Regex::QuantifierValue True)»
(try say 'abcdefg' ~~ /\w ** {NaN..42}/ )
orelse say ($!.^name, $!.non-numeric-range);
# OUTPUT: «(X::Syntax::Regex::QuantifierValue True)»
(try say 'abcdefg' ~~ /\w ** {"a".."c"}/)
orelse say ($!.^name, $!.non-numeric-range);
# OUTPUT: «(X::Syntax::Regex::QuantifierValue True)»
(try say 'abcdefg' ~~ /\w ** {Inf}/)
orelse say ($!.^name, $!.inf);
# OUTPUT: «(X::Syntax::Regex::QuantifierValue True)»
(try say 'abcdefg' ~~ /\w ** {NaN}/)
orelse say ($!.^name, $!.non-numeric);
# OUTPUT: «(X::Syntax::Regex::QuantifierValue True)»
```
## [Modified quantifier: `%`, `%%`](#Regexes "go to top of document")[§](#Modified_quantifier:_%,_%% "direct link")
To more easily match things like comma separated values, you can tack on a `%` modifier to any of the above quantifiers to specify a separator that must occur between each of the matches. For example, `a+ % ','` will match `a` or `a,a` or `a,a,a`, etc.
`%%` is like `%`, with the difference that it can optionally match trailing delimiters as well. This means that besides `a` and `a,a`, it can also match `a,` and `a,a,`.
The quantifier interacts with `%` and controls the number of overall repetitions that can match successfully, so `a* % ','` also matches the empty string. If you want match words delimited by commas, you might need to nest an ordinary and a modified quantifier:
```raku
say so 'abc,def' ~~ / ^ [\w+] ** 1 % ',' $ /; # OUTPUT: «False»
say so 'abc,def' ~~ / ^ [\w+] ** 2 % ',' $ /; # OUTPUT: «True»
```
## [Preventing backtracking: `:`](#Regexes "go to top of document")[§](#Preventing_backtracking:_: "direct link")
One way to prevent [backtracking](/language/regexes#Backtracking) is through the use of the `ratchet` adverb as described [below](/language/regexes#Ratchet). Another more fine-grained way of preventing backtracking in regexes is attaching a `:` modifier to a quantifier:
```raku
my $str = "ACG GCT ACT An interesting chain";
say $str ~~ /<[ACGT\s]>+ \s+ (<[A..Z a..z \s]>+)/;
# OUTPUT: «「ACG GCT ACT An interesting chain」 0 => 「An interesting chain」»
say $str ~~ /<[ACGT\s]>+: \s+ (<[A..Z a..z \s]>+)/;
# OUTPUT: «Nil»
```
In the second case, the "A" in "An" had already been absorbed by the pattern, preventing the matching of the second part of the pattern, after `\s+`. Generally we will want the opposite: prevent backtracking to match precisely what we are looking for.
In most cases, you will want to prevent backtracking for efficiency reasons, for instance here:
```raku
say $str ~~ m:g/[(<[ACGT]> **: 3) \s*]+ \s+ (<[A..Z a..z \s]>+)/;
# OUTPUT:
# «(「ACG GCT ACT An interesting chain」
# «0 => 「ACG」»
# «0 => 「GCT」»
# «0 => 「ACT」»
# «1 => 「An interesting chain」)»
```
Although in this case, eliminating the `:` from behind `**` would make it behave exactly in the same way. The best use is to create *tokens* that will not be backtracked:
```raku
$_ = "ACG GCT ACT IDAQT";
say m:g/[(\w+:) \s*]+ (\w+) $$/;
# OUTPUT:
# «(「ACG GCT ACT IDAQT」»
# «0 => 「ACG」»
# «0 => 「GCT」»
# «0 => 「ACT」»
# «1 => 「IDAQT」)»
```
Without the `:` following `\w+`, the *ID* part captured would have been simply `T`, since the pattern would go ahead and match everything, leaving a single letter to match the `\w+` expression at the end of the line.
## [Greedy versus frugal quantifiers: `?`](#Regexes "go to top of document")[§](#Greedy_versus_frugal_quantifiers:_? "direct link")
By default, quantifiers request a greedy match:
```raku
'abababa' ~~ /a .* a/ && say ~$/; # OUTPUT: «abababa»
```
You can attach a `?` modifier to the quantifier to enable frugal matching:
```raku
'abababa' ~~ /a .*? a/ && say ~$/; # OUTPUT: «aba»
```
You can also enable frugal matching for general quantifiers:
```raku
say '/foo/o/bar/' ~~ /\/.**?{1..10}\//; # OUTPUT: «「/foo/」»
say '/foo/o/bar/' ~~ /\/.**!{1..10}\//; # OUTPUT: «「/foo/o/bar/」»
```
Greedy matching can be explicitly requested with the `!` modifier.
# [Alternation: `||`](#Regexes "go to top of document")[§](#Alternation:_|| "direct link")
To match one of several possible alternatives, separate them by `||`; the first matching alternative wins.
For example, `ini` files have the following form:
「text」 without highlighting
```
```
[section]
key = value
```
```
Hence, if you parse a single line of an `ini` file, it can be either a section or a key-value pair and the regex would be (to a first approximation):
```raku
/ '[' \w+ ']' || \S+ \s* '=' \s* \S* /
```
That is, either a word surrounded by square brackets, or a string of non-whitespace characters, followed by zero or more spaces, followed by the equals sign `=`, followed again by optional whitespace, followed by another string of non-whitespace characters.
An empty string as the first branch is ignored, to allow you to format branches consistently. You could have written the previous example as
```raku
/
|| '[' \w+ ']'
|| \S+ \s* '=' \s* \S*
/
```
Even in non-backtracking contexts, the alternation operator `||` tries all the branches in order until the first one matches.
# [Longest alternation: `|`](#Regexes "go to top of document")[§](#Longest_alternation:_| "direct link")
In short, in regex branches separated by `|`, the longest token match wins, independent of the textual ordering in the regex. However, what `|` really does is more than that. It does not decide which branch wins after finishing the whole match, but follows the [longest-token matching (LTM) strategy](https://github.com/Raku/old-design-docs/blob/master/S05-regex.pod#Longest-token_matching).
Briefly, what `|` does is this:
* First, select the branch which has the longest declarative prefix.
```raku
say "abc" ~~ /ab | a.* /; # OUTPUT: «⌜abc⌟»
say "abc" ~~ /ab | a {} .* /; # OUTPUT: «⌜ab⌟»
say "if else" ~~ / if | if <.ws> else /; # OUTPUT: «「if」»
say "if else" ~~ / if | if \s+ else /; # OUTPUT: «「if else」»
```
As is shown above, `a.*` is a declarative prefix, while `a {} .*` terminates at `{}`, then its declarative prefix is `a`. Note that non-declarative atoms terminate declarative prefix. This is quite important if you want to apply `|` in a `rule`, which automatically enables `:s`, and `<.ws>` accidentally terminates declarative prefix.
* If it's a tie, select the match with the highest specificity.
```raku
say "abc" ~~ /a. | ab { print "win" } /; # OUTPUT: «win「ab」»
```
When two alternatives match at the same length, the tie is broken by specificity. That is, `ab`, as an exact match, counts as closer than `a.`, which uses character classes.
* If it's still a tie, use additional tie-breakers.
```raku
say "abc" ~~ /a\w| a. { print "lose" } /; # OUTPUT: «⌜ab⌟»
```
If the tie breaker above doesn't work, then the textually earlier alternative takes precedence.
For more details, see [the LTM strategy](https://github.com/Raku/old-design-docs/blob/master/S05-regex.pod#Longest-token_matching).
## [Quoted lists are LTM matches](#Regexes "go to top of document")[§](#Quoted_lists_are_LTM_matches "direct link")
Using a quoted list in a regex is equivalent to specifying the longest-match alternation of the list's elements. So, the following match:
```raku
say 'food' ~~ /< f fo foo food >/; # OUTPUT: «「food」»
```
is equivalent to:
```raku
say 'food' ~~ / f | fo | foo | food /; # OUTPUT: «「food」»
```
Note that the space after the first `<` is significant here: `<food>` calls the named rule `food` while `< food >` and `< food>` specify quoted lists with a single element, `'food'`.
If the first branch is an empty string, it is ignored. This allows you to format your regexes consistently:
```raku
/
| f
| fo
| foo
| food
/
```
Arrays can also be interpolated into a regex to achieve the same effect:
```raku
my @increasingly-edible = <f fo foo food>;
say 'food' ~~ /@increasingly-edible/; # OUTPUT: «「food」»
```
This is documented further under [Regex Interpolation](#Regex_interpolation), below.
# [Conjunction: `&&`](#Regexes "go to top of document")[§](#Conjunction:_&& "direct link")
Matches successfully if all `&&`-delimited segments match the same substring of the target string. The segments are evaluated left to right.
This can be useful for augmenting an existing regex. For example if you have a regex `quoted` that matches a quoted string, then `/ <quoted> && <-[x]>* /` matches a quoted string that does not contain the character `x`.
Note that you cannot easily obtain the same behavior with a lookahead, that is, a regex doesn't consume characters, because a lookahead doesn't stop looking when the quoted string stops matching.
```raku
say 'abc' ~~ / <?before a> && . /; # OUTPUT: «Nil»
say 'abc' ~~ / <?before a> . && . /; # OUTPUT: «「a」»
say 'abc' ~~ / <?before a> . /; # OUTPUT: «「a」»
say 'abc' ~~ / <?before a> .. /; # OUTPUT: «「ab」»
```
Just like with `||`, empty first branches are ignored.
# [Conjunction: `&`](#Regexes "go to top of document")[§](#Conjunction:_& "direct link")
Much like `&&` in a Regexes, it matches successfully if all segments separated by `&` match the same part of the target string.
`&` (unlike `&&`) is considered declarative, and notionally all the segments can be evaluated in parallel, or in any order the compiler chooses.
Just like with `||` and `&`, empty first branches are ignored.
# [Anchors](#Regexes "go to top of document")[§](#Anchors "direct link")
Regexes search an entire string for matches. Sometimes this is not what you want. Anchors match only at certain positions in the string, thereby anchoring the regex match to that position.
## [Start of string and end of string](#Regexes "go to top of document")[§](#Start_of_string_and_end_of_string "direct link")
The `^` anchor only matches at the start of the string:
```raku
say so 'karakul' ~~ / raku/; # OUTPUT: «True»
say so 'karakul' ~~ /^ raku/; # OUTPUT: «False»
say so 'rakuy' ~~ /^ raku/; # OUTPUT: «True»
say so 'raku' ~~ /^ raku/; # OUTPUT: «True»
```
The `$` anchor only matches at the end of the string:
```raku
say so 'use raku' ~~ / raku /; # OUTPUT: «True»
say so 'use raku' ~~ / raku $/; # OUTPUT: «True»
say so 'rakuy' ~~ / raku $/; # OUTPUT: «False»
```
You can combine both anchors:
```raku
say so 'use raku' ~~ /^ raku $/; # OUTPUT: «False»
say so 'raku' ~~ /^ raku $/; # OUTPUT: «True»
```
Keep in mind that `^` matches the start of a **string**, not the start of a **line**. Likewise, `$` matches the end of a **string**, not the end of a **line**.
The following is a multi-line string:
```raku
my $str = chomp q:to/EOS/;
Keep it secret
and keep it safe
EOS
# 'safe' is at the end of the string
say so $str ~~ /safe $/; # OUTPUT: «True»
# 'secret' is at the end of a line, not the string
say so $str ~~ /secret $/; # OUTPUT: «False»
# 'Keep' is at the start of the string
say so $str ~~ /^Keep /; # OUTPUT: «True»
# 'and' is at the start of a line -- not the string
say so $str ~~ /^and /; # OUTPUT: «False»
```
## [Start of line and end of line](#Regexes "go to top of document")[§](#Start_of_line_and_end_of_line "direct link")
The `^^` anchor matches at the start of a logical line. That is, either at the start of the string, or after a newline character. However, it does not match at the end of the string, even if it ends with a newline character.
The `$$` anchor matches at the end of a logical line. That is, before a newline character, or at the end of the string when the last character is not a newline character.
To understand the following example, it's important to know that the `q:to/EOS/...EOS` [heredoc](/language/quoting#Heredocs:_:to) syntax removes leading indention to the same level as the `EOS` marker, so that the first, second and last lines have no leading space and the third and fourth lines have two leading spaces each.
```raku
my $str = q:to/EOS/;
There was a young man of Japan
Whose limericks never would scan.
When asked why this was,
He replied "It's because I always try to fit
as many syllables into the last line as ever I possibly can."
EOS
# 'There' is at the start of string
say so $str ~~ /^^ There/; # OUTPUT: «True»
# 'limericks' is not at the start of a line
say so $str ~~ /^^ limericks/; # OUTPUT: «False»
# 'as' is at start of the last line
say so $str ~~ /^^ as/; # OUTPUT: «True»
# there are blanks between start of line and the "When"
say so $str ~~ /^^ When/; # OUTPUT: «False»
# 'Japan' is at end of first line
say so $str ~~ / Japan $$/; # OUTPUT: «True»
# there's a . between "scan" and the end of line
say so $str ~~ / scan $$/; # OUTPUT: «False»
# matched at the last line
say so $str ~~ / '."' $$/; # OUTPUT: «True»
```
## [Word boundary](#Regexes "go to top of document")[§](#Word_boundary "direct link")
To match any word boundary, use `<?wb>`. This is similar to `\b` in other languages. To match the opposite, any character that is not bounding a word, use `<!wb>`. This is similar to `\B` in other languages; `\b` and `\B` will throw an [`X::Obsolete`](/type/X/Obsolete) exception from version 6.d of Raku.
These are both zero-width regex elements.
```raku
say "two-words" ~~ / two<?wb>\-<?wb>words /; # OUTPUT: «「two-words」»
say "twowords" ~~ / two<!wb><!wb>words /; # OUTPUT: «「twowords」»
```
## [Left and right word boundary](#Regexes "go to top of document")[§](#Left_and_right_word_boundary "direct link")
`<<` matches a left word boundary. It matches positions where there is a non-word character at the left, or the start of the string, and a word character to the right.
`>>` matches a right word boundary. It matches positions where there is a word character at the left and a non-word character at the right, or the end of the string.
These are both zero-width regex elements.
```raku
my $str = 'The quick brown fox';
say so ' ' ~~ /\W/; # OUTPUT: «True»
say so $str ~~ /br/; # OUTPUT: «True»
say so $str ~~ /<< br/; # OUTPUT: «True»
say so $str ~~ /br >>/; # OUTPUT: «False»
say so $str ~~ /own/; # OUTPUT: «True»
say so $str ~~ /<< own/; # OUTPUT: «False»
say so $str ~~ /own >>/; # OUTPUT: «True»
say so $str ~~ /<< The/; # OUTPUT: «True»
say so $str ~~ /fox >>/; # OUTPUT: «True»
```
You can also use the variants `«` and `»` :
```raku
my $str = 'The quick brown fox';
say so $str ~~ /« own/; # OUTPUT: «False»
say so $str ~~ /own »/; # OUTPUT: «True»
```
To see the difference between `<?wb>` and `«`, `»`:
```raku
say "stuff here!!!".subst(:g, />>/, '|'); # OUTPUT: «stuff| here|!!!»
say "stuff here!!!".subst(:g, /<</, '|'); # OUTPUT: «|stuff |here!!!»
say "stuff here!!!".subst(:g, /<?wb>/, '|'); # OUTPUT: «|stuff| |here|!!!»
```
## [Summary of anchors](#Regexes "go to top of document")[§](#Summary_of_anchors "direct link")
Anchors are zero-width regex elements. Hence they do not use up a character of the input string, that is, they do not advance the current position at which the regex engine tries to match. A good mental model is that they match between two characters of an input string, or before the first, or after the last character of an input string.
| Anchor | Description | Examples |
| --- | --- | --- |
| ^ | Start of string | "⏏two\nlines" |
| ^^ | Start of line | "⏏two\n⏏lines" |
| $ | End of string | "two\nlines⏏" |
| $$ | End of line | "two⏏\nlines⏏" |
| << or « | Left word boundary | "⏏two ⏏words" |
| >> or » | Right word boundary | "two⏏ words⏏" |
| <?wb> | Any word boundary | "⏏two⏏ ⏏words⏏~!" |
| <!wb> | Not a word boundary | "t⏏w⏏o w⏏o⏏r⏏d⏏s~⏏!" |
| <?ww> | Within word | "t⏏w⏏o w⏏o⏏r⏏d⏏s~!" |
| <!ww> | Not within word | "⏏two⏏ ⏏words⏏~⏏!⏏" |
# [Zero-width assertions](#Regexes "go to top of document")[§](#Zero-width_assertions "direct link")
Zero-Width assertions can help you implement your own anchor: it turns another regex into an anchor, making them consume no characters of the input string. There are two variants: lookahead and lookbehind assertions.
Technically, anchors are also zero-width assertions, and they can look both ahead and behind.
## [Lookaround assertions](#Regexes "go to top of document")[§](#Lookaround_assertions "direct link")
Lookaround assertions, which need a character class in its simpler form, work both ways. They match, but they don't consume a character.
```raku
my regex key {^^ <![#-]> \d+ }
say "333" ~~ &key; # OUTPUT: «「333」»
say '333$' ~~ m/ \d+ <?[$]>/; # OUTPUT: «「333」»
say '$333' ~~ m/^^ <?[$]> . \d+ /; # OUTPUT: «「$333」»
```
They can be positive or negative: `![]` is negative, while `?[]` is positive; the square brackets will contain the characters or backslashed character classes that are going to be matched.
You can use predefined character classes and Unicode properties directly preceded by the exclamation or interrogation mark to convert them into lookaround assertions.:
```raku
say '333' ~~ m/^^ <?alnum> \d+ /; # OUTPUT: «「333」»
say '333' ~~ m/^^ <?:Nd> \d+ /; # OUTPUT: «「333」»
say '333' ~~ m/^^ <!:L> \d+ /; # OUTPUT: «「333」»
say '333' ~~ m/^^ \d+ <!:Script<Tamil>> /; # OUTPUT: «「33」»
```
In the first two cases, the corresponding character class matches, but does not consume, the first digit, which is then consumed by the expression; in the third, the negative lookaround assertion behaves in the same way. In the fourth statement the last digit is matched but not consumed, thus the match includes only the first two digits.
## [Lookahead assertions](#Regexes "go to top of document")[§](#Lookahead_assertions "direct link")
To check that a pattern appears before another pattern, use a lookahead assertion via the `before` assertion. This has the form:
```raku
<?before pattern>
```
Thus, to search for the string `foo` which is immediately followed by the string `bar`, use the following regexp:
```raku
/ foo <?before bar> /
```
For example:
```raku
say "foobar" ~~ / foo <?before bar> /; # OUTPUT: «foo»
```
However, if you want to search for a pattern which is **not** immediately followed by some pattern, then you need to use a negative lookahead assertion, this has the form:
```raku
<!before pattern>
```
In the following example, all occurrences of `foo` which is not before `bar` would match with
```raku
say "foobaz" ~~ / foo <!before bar> /; # OUTPUT: «foo»
```
Lookahead assertions can be used also with other patterns, like characters ranges, interpolated variables subscripts and so on. In such cases it does suffice to use a `?`, or a `!` for the negate form. For instance, the following lines all produce the very same result:
```raku
say 'abcdefg' ~~ rx{ abc <?before def> }; # OUTPUT: «「abc」»
say 'abcdefg' ~~ rx{ abc <?[ d..f ]> }; # OUTPUT: «「abc」»
my @ending_letters = <d e f>;
say 'abcdefg' ~~ rx{ abc <?@ending_letters> }; # OUTPUT: «「abc」»
```
Metacharacters can also be used in lookahead or -behind assertions.
```raku
say "First. Second" ~~ m:g/ <?after ^^ | "." \s+> <:Lu>\S+ /
# OUTPUT: «(「First.」 「Second」)»
```
A practical use of lookahead assertions is in substitutions, where you only want to substitute regex matches that are in a certain context. For example, you might want to substitute only numbers that are followed by a unit (like *kg*), but not other numbers:
```raku
my @units = <kg m km mm s h>;
$_ = "Please buy 2 packs of sugar, 1 kg each";
s:g[\d+ <?before \s* @units>] = 5 * $/;
say $_; # OUTPUT: «Please buy 2 packs of sugar, 5 kg each»
```
Since the lookahead is not part of the match object, the unit is not substituted.
## [Lookbehind assertions](#Regexes "go to top of document")[§](#Lookbehind_assertions "direct link")
To check that a pattern appears after another pattern, use a lookbehind assertion via the `after` assertion. This has the form:
```raku
<?after pattern>
```
Therefore, to search for the string `bar` immediately preceded by the string `foo`, use the following regexp:
```raku
/ <?after foo> bar /
```
For example:
```raku
say "foobar" ~~ / <?after foo> bar /; # OUTPUT: «bar»
```
However, if you want to search for a pattern which is **not** immediately preceded by some pattern, then you need to use a negative lookbehind assertion, this has the form:
```raku
<!after pattern>
```
Hence all occurrences of `bar` which do not have `foo` before them would be matched by
```raku
say "fotbar" ~~ / <!after foo> bar /; # OUTPUT: «bar»
```
These are, as in the case of lookahead, zero-width assertions which do not *consume* characters, like here:
```raku
say "atfoobar" ~~ / (.**3) .**2 <?after foo> bar /;
# OUTPUT: «「atfoobar」 0 => 「atf」»
```
where we capture the first 3 of the 5 characters before bar, but only if `bar` is preceded by `foo`. The fact that the assertion is zero-width allows us to use part of the characters in the assertion for capture.
# [Grouping and capturing](#Regexes "go to top of document")[§](#Grouping_and_capturing "direct link")
In regular (non-regex) Raku, you can use parentheses to group things together, usually to override operator precedence:
```raku
say 1 + 4 * 2; # OUTPUT: «9», parsed as 1 + (4 * 2)
say (1 + 4) * 2; # OUTPUT: «10»
```
The same grouping facility is available in regexes:
```raku
/ a || b c /; # matches 'a' or 'bc'
/ ( a || b ) c /; # matches 'ac' or 'bc'
```
The same grouping applies to quantifiers:
```raku
/ a b+ /; # matches an 'a' followed by one or more 'b's
/ (a b)+ /; # matches one or more sequences of 'ab'
/ (a || b)+ /; # matches a string of 'a's and 'b's, except empty string
```
An unquantified capture produces a [`Match`](/type/Match) object. When a capture is quantified (except with the `?` quantifier) the capture becomes a list of [`Match`](/type/Match) objects instead.
## [Capturing](#Regexes "go to top of document")[§](#Capturing "direct link")
The round parentheses don't just group, they also *capture*; that is, they make the string matched within the group available as a variable, and also as an element of the resulting [`Match`](/type/Match) object:
```raku
my $str = 'number 42';
if $str ~~ /'number ' (\d+) / {
say "The number is $0"; # OUTPUT: «The number is 42»
# or
say "The number is $/[0]"; # OUTPUT: «The number is 42»
}
```
Pairs of parentheses are numbered left to right, starting from zero.
```raku
if 'abc' ~~ /(a) b (c)/ {
say "0: $0; 1: $1"; # OUTPUT: «0: a; 1: c»
}
```
The `$0` and `$1` etc. syntax is shorthand. These captures are canonically available from the match object `$/` by using it as a list, so `$0` is actually syntactic sugar for `$/[0]`.
Coercing the match object to a list gives an easy way to programmatically access all elements:
```raku
if 'abc' ~~ /(a) b (c)/ {
say $/.list.join: ', ' # OUTPUT: «a, c»
}
```
## [Non-capturing grouping](#Regexes "go to top of document")[§](#Non-capturing_grouping "direct link")
The parentheses in regexes perform a double role: they group the regex elements inside and they capture what is matched by the sub-regex inside.
To get only the grouping behavior, you can use square brackets `[ ... ]` which, by default, don't capture.
```raku
if 'abc' ~~ / [a||b] (c) / {
|
## regexes.md
## Chunk 3 of 5
say ~$0; # OUTPUT: «c»
}
```
If you do not need the captures, using non-capturing `[ ... ]` groups provides the following benefits:
* they more cleanly communicate the regex intent,
* they make it easier to count the capturing groups that do match, and
* they make matching a bit faster.
## [Capture numbers](#Regexes "go to top of document")[§](#Capture_numbers "direct link")
It is stated above that captures are numbered from left to right. While true in principle, this is also an over simplification.
The following rules are listed for the sake of completeness. When you find yourself using them regularly, it's worth considering named captures (and possibly subrules) instead.
Alternations reset the capture count:
```raku
/ (x) (y) || (a) (.) (.) /
# $0 $1 $0 $1 $2
```
Example:
```raku
if 'abc' ~~ /(x)(y) || (a)(.)(.)/ {
say ~$1; # OUTPUT: «b»
}
```
If two (or more) alternations have a different number of captures, the one with the most captures determines the index of the next capture:
```raku
if 'abcd' ~~ / a [ b (.) || (x) (y) ] (.) / {
# $0 $0 $1 $2
say ~$2; # OUTPUT: «d»
}
```
Captures can be nested, in which case they are numbered per level; level 0 gets to use the capture variables, but it will become a list with the rest of the levels behaving as elements of that list
```raku
if 'abc' ~~ / ( a (.) (.) ) / {
say "Outer: $0"; # OUTPUT: «Outer: abc»
say "Inner: $0[0] and $0[1]"; # OUTPUT: «Inner: b and c»
}
```
These capture variables are only available outside the regex.
```raku
# !!WRONG!! The $0 refers to a capture *inside* the second capture
say "11" ~~ /(\d) ($0)/; # OUTPUT: «Nil»
```
In order to make them available inside the Regexes, you need to insert a code block behind the match; this code block may be empty if there's nothing meaningful to do:
```raku
# CORRECT: $0 is saved into a variable outside the second capture
# before it is used inside
say "11" ~~ /(\d) {} :my $c = $0; ($c)/; # OUTPUT: «「11」 0 => 「1」 1 => 「1」»
say "Matched $c"; # OUTPUT: «Matched 1»
```
This code block *publishes* the capture inside the regex, so that it can be assigned to other variables or used for subsequent matches
```raku
say "11" ~~ /(\d) {} $0/; # OUTPUT: «「11」 0 => 「1」»
```
`:my` helps scoping the `$c` variable within the regex and beyond; in this case we can use it in the next sentence to show what has been matched inside the regex. This can be used for debugging inside regular expressions, for instance:
```raku
my $paragraph="line\nline2\nline3";
$paragraph ~~ rx| :my $counter = 0; ( \V* { ++$counter } ) *%% \n |;
say "Matched $counter lines"; # OUTPUT: «Matched 3 lines»
```
Since `:my` blocks are simply declarations, the match variable `$/` or numbered matches such as `$0` will not be available in them unless they are previously *published* by inserting the empty block (or any block):
```raku
"aba" ~~ / (a) b {} :my $c = $/; /;
say $c; # OUTPUT: «「ab」 0 => 「a」»
```
Any other code block will also reveal the variables and make them available in declarations:
```raku
"aba" ~~ / (a) {say "Check so far ", ~$/} b :my $c = ~$0; /;
# OUTPUT: «Check so far a»
say "Capture $c"; # OUTPUT: «Capture a»
```
The `:our`, similarly to [`our`](/syntax/our) in classes, can be used in [`Grammar`](/type/Grammar)s to declare variables that can be accessed, via its fully qualified name, from outside the grammar:
```raku
grammar HasOur {
token TOP {
:our $our = 'Þor';
$our \s+ is \s+ mighty
}
}
say HasOur.parse('Þor is mighty'); # OUTPUT: «「Þor is mighty」»
say $HasOur::our; # OUTPUT: «Þor»
```
Once the parsing has been done successfully, we use the FQN name of the `$our` variable to access its value, that can be none other than `Þor`.
## [Named captures](#Regexes "go to top of document")[§](#Named_captures "direct link")
Instead of numbering captures, you can also give them names. The generic, and slightly verbose, way of naming captures is like this:
```raku
if 'abc' ~~ / $<myname> = [ \w+ ] / {
say ~$<myname> # OUTPUT: «abc»
}
```
The square brackets in the above example, which don't usually capture, will now capture its grouping with the given name.
The access to the named capture, `$<myname>`, is a shorthand for indexing the match object as a hash, in other words: `$/{ 'myname' }` or `$/<myname>`.
We can also use parentheses in the above example, but they will work exactly the same as square brackets. The captured group will only be accessible by its name as a key from the match object and not from its position in the list with `$/[0]` or `$0`.
Named captures can also be nested using regular capture group syntax:
```raku
if 'abc-abc-abc' ~~ / $<string>=( [ $<part>=[abc] ]* % '-' ) / {
say ~$<string>; # OUTPUT: «abc-abc-abc»
say ~$<string><part>; # OUTPUT: «abc abc abc»
say ~$<string><part>[0]; # OUTPUT: «abc»
}
```
Coercing the match object to a hash gives you easy programmatic access to all named captures:
```raku
if 'count=23' ~~ / $<variable>=\w+ '=' $<value>=\w+ / {
my %h = $/.hash;
say %h.keys.sort.join: ', '; # OUTPUT: «value, variable»
say %h.values.sort.join: ', '; # OUTPUT: «23, count»
for %h.kv -> $k, $v {
say "Found value '$v' with key '$k'";
# outputs two lines:
# Found value 'count' with key 'variable'
# Found value '23' with key 'value'
}
}
```
A more convenient way to get named captures is by using named regex as discussed in the [Subrules](/language/regexes#Subrules) section.
## [Capture markers: `<( )>`](#Regexes "go to top of document")[§](#Capture_markers:_<(_)> "direct link")
A `<(` token indicates the start of the match's overall capture, while the corresponding `)>` token indicates its endpoint. The `<(` is similar to other languages \K to discard any matches found before the `\K`.
```raku
say 'abc' ~~ / a <( b )> c/; # OUTPUT: «「b」»
say 'abc' ~~ / <(a <( b )> c)>/; # OUTPUT: «「bc」»
```
As in the example above, you can see `<(` sets the start point and `)>` sets the endpoint; since they are actually independent of each other, the inner-most start point wins (the one attached to `b`) and the outer-most end wins (the one attached to `c`).
# [Substitution](#Regexes "go to top of document")[§](#Substitution "direct link")
Regular expressions can also be used to substitute one piece of text for another. You can use this for anything, from correcting a spelling error (e.g., replacing 'Perl Jam' with 'Pearl Jam'), to reformatting an ISO8601 date from `yyyy-mm-ddThh:mm:ssZ` to `mm-dd-yy h:m {AM,PM}` and beyond.
Just like the search-and-replace editor's dialog box, the `s/ / /` operator has two sides, a left and right side. The left side is where your matching expression goes, and the right side is what you want to replace it with.
## [Lexical conventions](#Regexes "go to top of document")[§](#Lexical_conventions_0 "direct link")
Substitutions are written similarly to matching, but the substitution operator has both an area for the regex to match, and the text to substitute:
```raku
s/replace/with/; # a substitution that is applied to $_
$str ~~ s/replace/with/; # a substitution applied to a scalar
```
The substitution operator allows delimiters other than the slash:
```raku
s|replace|with|;
s!replace!with!;
s,replace,with,;
```
Note that neither the colon `:` nor balancing delimiters such as `{}` or `()` can be substitution delimiters. Colons clash with adverbs such as `s:i/Foo/bar/` and the other delimiters are used for other purposes.
If you use balancing curly braces, square brackets, or parentheses, the substitution works like this instead:
```raku
s[replace] = 'with';
```
The right-hand side is now a (not quoted) Raku expression, in which `$/` is available as the current match:
```raku
$_ = 'some 11 words 21';
s:g[ \d+ ] = 2 * $/;
.say; # OUTPUT: «some 22 words 42»
```
Like the `m//` operator, whitespace is ignored in the regex part of a substitution.
## [Replacing string literals](#Regexes "go to top of document")[§](#Replacing_string_literals "direct link")
The simplest thing to replace is a string literal. The string you want to replace goes on the left-hand side of the substitution operator, and the string you want to replace it with goes on the right-hand side; for example:
```raku
$_ = 'The Replacements';
s/Replace/Entrap/;
.say; # OUTPUT: «The Entrapments»
```
Alphanumeric characters and the underscore are literal matches, just as in its cousin the `m//` operator. All other characters must be escaped with a backslash `\` or included in quotes:
```raku
$_ = 'Space: 1999';
s/Space\:/Party like it's/;
.say # OUTPUT: «Party like it's 1999»
```
Note that the matching restrictions generally only apply to the left-hand side of the substitution expression, but some special characters or combinations of them may need to be escaped in the right-hand side (RHS). For example
```raku
$_ = 'foo';
s/foo/\%(/;
.say # OUTPUT: «%(»
```
or escape the '(' instead for the same result
```raku
s/foo/%\(/;
.say # OUTPUT: «%(»
```
but using either character alone does not require escaping. Forward slashes will need to be escaped, but escaping alphanumeric characters will cause them to be ignored. (NOTE: This RHS limitation was only recently noticed and this is not yet an exhaustive list of all characters or character pairs that require escapes for the RHS.)
By default, substitutions are only done on the first match:
```raku
$_ = 'There can be twly two';
s/tw/on/; # replace 'tw' with 'on' once
.say; # OUTPUT: «There can be only two»
```
## [Wildcards and character classes](#Regexes "go to top of document")[§](#Wildcards_and_character_classes "direct link")
Anything that can go into the `m//` operator can go into the left-hand side of the substitution operator, including wildcards and character classes. This is handy when the text you're matching isn't static, such as trying to match a number in the middle of a string:
```raku
$_ = "Blake's 9";
s/\d+/7/; # replace any sequence of digits with '7'
.say; # OUTPUT: «Blake's 7»
```
Of course, you can use any of the `+`, `*` and `?` modifiers, and they'll behave just as they would in the `m//` operator's context.
## [Capturing groups](#Regexes "go to top of document")[§](#Capturing_groups "direct link")
Just as in the match operator, capturing groups are allowed on the left-hand side, and the matched contents populate the `$0`..`$n` variables and the `$/` object:
```raku
$_ = '2016-01-23 18:09:00';
s/ (\d+)\-(\d+)\-(\d+) /today/; # replace YYYY-MM-DD with 'today'
.say; # OUTPUT: «today 18:09:00»
"$1-$2-$0".say; # OUTPUT: «01-23-2016»
"$/[1]-$/[2]-$/[0]".say; # OUTPUT: «01-23-2016»
```
Any of these variables `$0`, `$1`, `$/` can be used on the right-hand side of the operator as well, so you can manipulate what you've just matched. This way you can separate out the `YYYY`, `MM` and `DD` parts of a date and reformat them into `MM-DD-YYYY` order:
```raku
$_ = '2016-01-23 18:09:00';
s/ (\d+)\-(\d+)\-(\d+) /$1-$2-$0/; # transform YYYY-MM-DD to MM-DD-YYYY
.say; # OUTPUT: «01-23-2016 18:09:00»
```
Named capture can be used too:
```raku
$_ = '2016-01-23 18:09:00';
s/ $<y>=(\d+)\-$<m>=(\d+)\-$<d>=(\d+) /$<m>-$<d>-$<y>/;
.say; # OUTPUT: «01-23-2016 18:09:00»
```
Since the right-hand side is effectively a regular Raku interpolated string, you can reformat the time from `HH:MM` to `h:MM {AM,PM}` like so:
```raku
$_ = '18:38';
s/(\d+)\:(\d+)/{$0 % 12}\:$1 {$0 < 12 ?? 'AM' !! 'PM'}/;
.say; # OUTPUT: «6:38 PM»
```
Using the modulo `%` operator above keeps the sample code under 80 characters, but is otherwise the same as `$0 < 12 ?? $0 !! $0 - 12`. When combined with the power of the Parser Expression Grammars that **really** underlies what you're seeing here, you can use "regular expressions" to parse pretty much any text out there.
## [Common adverbs](#Regexes "go to top of document")[§](#Common_adverbs "direct link")
The full list of adverbs that you can apply to regular expressions can be found elsewhere in this document ([section Adverbs](#Adverbs)), but the most common are probably `:g` and `:i`.
* Global adverb `:g`
Ordinarily, matches are only made once in a given string, but adding the `:g` modifier overrides that behavior, so that substitutions are made everywhere possible. Substitutions are non-recursive; for example:
```raku
$_ = q{I can say "banana" but I don't know when to stop};
s:g/na/nana,/; # substitute 'nana,' for 'na'
.say; # OUTPUT: «I can say "banana,nana," but I don't ...»
```
Here, `na` was found twice in the original string and each time there was a substitution. The substitution only applied to the original string, though. The resulting string was not impacted.
* Insensitive adverb `:i`
Ordinarily, matches are case-sensitive. `s/foo/bar/` will only match `'foo'` and not `'Foo'`. If the adverb `:i` is used, though, matches become case-insensitive.
```raku
$_ = 'Fruit';
s/fruit/vegetable/;
.say; # OUTPUT: «Fruit»
s:i/fruit/vegetable/;
.say; # OUTPUT: «vegetable»
```
For more information on what these adverbs are actually doing, refer to the [section Adverbs](#Adverbs) section of this document.
These are just a few of the transformations you can apply with the substitution operator. Some of the simpler uses in the real world include removing personal data from log files, editing MySQL timestamps into PostgreSQL format, changing copyright information in HTML files and sanitizing form fields in a web application.
As an aside, novices to regular expressions often get overwhelmed and think that their regular expression needs to match every piece of data in the line, including what they want to match. Write just enough to match the data you're looking for, no more, no less.
## [`S///` non-destructive substitution](#Regexes "go to top of document")[§](#S///_non-destructive_substitution "direct link")
```raku
say S/o .+ d/new/ with 'old string'; # OUTPUT: «new string»
S:g/« (.)/$0.uc()/.say for <foo bar ber>; # OUTPUT: «FooBarBer»
```
`S///` uses the same semantics as the `s///` operator, except it leaves the original string intact and *returns the resultant string* instead of `$/` (`$/` still being set to the same values as with `s///`).
**Note:** since the result is obtained as a return value, using this operator with the `~~` smartmatch operator is a mistake and will issue a warning. To execute the substitution on a variable that isn't the `$_` this operator uses, alias it to `$_` with `given`, `with`, or any other way. Alternatively, use the [`.subst` method](/routine/subst).
# [Tilde for nesting structures](#Regexes "go to top of document")[§](#Tilde_for_nesting_structures "direct link")
The `~` operator is a helper for matching nested subrules with a specific terminator as the goal. It is designed to be placed between an opening and closing delimiter pair, like so:
```raku
/ '(' ~ ')' <expression> /
```
However, it mostly ignores the left argument, and operates on the next two atoms (which may be quantified). Its operation on those next two atoms is to "twiddle" them so that they are actually matched in reverse order. Hence the expression above, at first blush, is merely another way of writing:
```raku
/ '(' <expression> ')' /
```
Using `~` keeps the separators closer together but beyond that, when it rewrites the atoms it also inserts the apparatus that will set up the inner expression to recognize the terminator, and to produce an appropriate error message if the inner expression does not terminate on the required closing atom. So it really does pay attention to the left delimiter as well, and it actually rewrites our example to something more like:
```raku
$<OPEN> = '(' <SETGOAL: ')'> <expression> [ $GOAL || <FAILGOAL> ]
```
FAILGOAL is a special method that can be defined by the user and it will be called on parse failure:
```raku
grammar A { token TOP { '[' ~ ']' \w+ };
method FAILGOAL($goal) {
die "Cannot find $goal near position {self.pos}"
}
}
say A.parse: '[good]'; # OUTPUT: «「[good]」»
A.parse: '[bad'; # will throw FAILGOAL exception
CATCH { default { put .^name, ': ', .Str } };
# OUTPUT: «X::AdHoc: Cannot find ']' near position 4»
```
Note that you can use this construct to set up expectations for a closing construct even when there's no opening delimiter:
```raku
"3)" ~~ / <?> ~ ')' \d+ /; # OUTPUT: «「3)」»
"(3)" ~~ / <?> ~ ')' \d+ /; # OUTPUT: «「3)」»
```
Here `<?>` successfully matches the null string.
The order of the regex capture is original:
```raku
"abc" ~~ /a ~ (c) (b)/;
say $0; # OUTPUT: «「c」»
say $1; # OUTPUT: «「b」»
```
# [Recursive Regexes](#Regexes "go to top of document")[§](#Recursive_Regexes "direct link")
You can use `<~~>` to recursively invoke the current Regex from within the Regex. This can be extremely helpful for matching nested data structures. For example, consider this Regex:
```raku
/ '(' <-[()]>* ')' || '('[ <-[()]>* <~~> <-[()]>* ]* ')' /
```
This says "match **either** an open parentheses, followed by zero or more non-parentheses characters, followed by a close parentheses **or** an open parentheses followed by zero or more non-parentheses characters, followed by *another match for this Regex*, followed by zero or more non-parentheses characters, followed by a close parentheses." This Regex allows you to match arbitrarily many nested parentheses, as show below:
```raku
my $paren = rx/ '(' <-[()]>* ')' || '('[ <-[()]>* <~~> <-[()]>* ]* ')' /;
say 'text' ~~ $paren; # OUTPUT: «Nil»
say '(1 + 1) = 2' ~~ $paren; # OUTPUT: «「(1 + 1)」»
say '(1 + (2 × 3)) = 7' ~~ $paren; # OUTPUT: «「(1 + (2 × 3))」»
say '((5 + 2) × 6) = 42 (the answer)' ~~ $paren # OUTPUT: «「((5 + 2) × 6)」»
```
Note that the last expression shown above does *not* match all the way to the final `)`, as would have happened with `/'('.*')'/`, nor does it match only to the first `)`. Instead, it correctly matches to the close parentheses paired with the first opening parentheses, an effect that is very difficult to duplicate without recursive regexes.
When using recursive regexes (as with any other recursive data structure) you should be careful to avoid infinite recursion, which will cause your program to hang or crash.
# [Subrules](#Regexes "go to top of document")[§](#Subrules "direct link")
Just like you can put pieces of code into subroutines, you can also put pieces of regex into named rules.
```raku
my regex line { \N*\n }
if "abc\ndef" ~~ /<line> def/ {
say "First line: ", $<line>.chomp; # OUTPUT: «First line: abc»
}
```
A named regex can be declared with `my regex named-regex { body here }`, and called with `<named-regex>`. At the same time, calling a named regex installs a named capture with the same name.
To give the capture a different name from the regex, use the syntax `<capture-name=named-regex>`. If no capture is desired, a leading dot or ampersand will suppress it: `<.named-regex>` if it is a method declared in the same class or grammar, `<&named-regex>` for a regex declared in the same lexical context.
Here's more complete code for parsing `ini` files:
```raku
my regex header { \s* '[' (\w+) ']' \h* \n+ }
my regex identifier { \w+ }
my regex kvpair { \s* <key=identifier> '=' <value=identifier> \n+ }
my regex section {
<header>
<kvpair>*
}
my $contents = q:to/EOI/;
[passwords]
jack=password1
joy=muchmoresecure123
[quotas]
jack=123
joy=42
EOI
my %config;
if $contents ~~ /<section>*/ {
for $<section>.list -> $section {
my %section;
for $section<kvpair>.list -> $p {
%section{ $p<key> } = ~$p<value>;
}
%config{ $section<header>[0] } = %section;
}
}
say %config.raku;
# OUTPUT: «{:passwords(${:jack("password1"), :joy("muchmoresecure123")}),
# :quotas(${:jack("123"), :joy("42")})}»
```
Named regexes can and should be grouped in [grammars](/language/grammars). A list of predefined subrules is [here](#Predefined_character_classes).
# [Regex interpolation](#Regexes "go to top of document")[§](#Regex_interpolation "direct link")
Instead of using a literal pattern for a regex match, you can use a variable that holds that pattern. This variable can then be 'interpolated' into a regex, such that its appearance in the regex is replaced with the pattern that it holds. The advantage of using interpolation this way, is that the pattern need not be hardcoded in the source of your Raku program, but may instead be variable and generated at runtime.
There are four different ways of interpolating a variable into a regex as a pattern, which may be summarized as follows:
| Syntax | Description |
| --- | --- |
| $variable | Interpolates stringified contents of variable literally. |
| $(code) | Runs Raku code inside the regex, and interpolates the stringified return value literally. |
| <$variable> | Interpolates stringified contents of variable as a regex. |
| <{code}> | Runs Raku code inside the regex, and interpolates the stringified return value as a regex. |
Instead of the `$` sigil, you may use the `@` sigil for array interpolation. See below for how this works.
Let's start with the first two syntactical forms: `$variable` and `$(code)`. These forms will interpolate the stringified value of the variable or the stringified return value of the code literally, provided that the respective value isn't a [`Regex`](/type/Regex) object. If the value is a [`Regex`](/type/Regex), it will not be stringified, but instead be interpolated as such. 'Literally' means *strictly literally*, that is: as if the respective stringified value is quoted with a basic `Q` string [`Q[...]`](/language/quoting#Literal_strings:_Q). Consequently, the stringified value will not itself undergo any further interpolation.
For `$variable` this means the following:
```raku
my $string = 'Is this a regex or a string: 123\w+False$pattern1 ?';
my $pattern1 = 'string';
my $pattern2 = '\w+';
my $number = 123;
my $regex = /\w+/;
say $string.match: / 'string' /; # [1] OUTPUT: «「string」»
say $string.match: / $pattern1 /; # [2] OUTPUT: «「string」»
say $string.match: / $pattern2 /; # [3] OUTPUT: «「\w+」»
say $string.match: / $regex /; # [4] OUTPUT: «「Is」»
say $string.match: / $number /; # [5] OUTPUT: «「123」»
```
In this example, the statements `[1]` and `[2]` are equivalent and meant to illustrate a plain case of regex interpolation. Since unescaped/unquoted alphabetic characters in a regex match literally, the single quotes in the regex of statement `[1]` are functionally redundant; they have merely been included to emphasize the correspondence between the first two statements. Statement `[3]` unambiguously shows that the string pattern held by `$pattern2` is interpreted literally, and not as a regex. In case it would have been interpreted as a regex, it would have matched the first word of `$string`, i.e. `「Is」`, as can be seen in statement `[4]`. Statement `[5]` shows how the stringified number is used as a match pattern.
This code exemplifies the use of the `$(code)` syntax:
```raku
my $string = 'Is this a regex or a string: 123\w+False$pattern1 ?';
my $pattern1 = 'string';
my $pattern3 = 'gnirts';
my $pattern4 = '$pattern1';
my $bool = True;
my sub f1 { return Q[$pattern1] };
say $string.match: / $pattern3.flip /; # [6] OUTPUT: «Nil»
say $string.match: / "$pattern3.flip()" /; # [7] OUTPUT: «「string」»
say $string.match: / $($pattern3.flip) /; # [8] OUTPUT: «「string」»
say $string.match: / $([~] $pattern3.comb.reverse) /; # [9] OUTPUT: «「string」»
say $string.match: / $(!$bool) /; # [10] OUTPUT: «「False」»
say $string.match: / $pattern4 /; # [11] OUTPUT: «「$pattern1」»
say $string.match: / $(f1) /; # [12] OUTPUT: «「$pattern1」»
```
Statement `[6]` does not work as probably intended. To the human reader, the dot `.` may seem to represent the [method call operator](/language/operators#methodop_.), but since a dot is not a valid character for an [ordinary identifier](/language/syntax#Ordinary_identifiers), and given the regex context, the compiler will parse it as the regex wildcard [.](/language/regexes#Wildcards) that matches any character. The apparent ambiguity may be resolved in various ways, for instance through the use of straightforward [string interpolation](/language/quoting#Interpolation:_qq) from the regex as in statement `[7]` (note that the inclusion of the call operator `()` is key here), or by using the second syntax form from the above table as in statement `[8]`, in which case the match pattern `string` first emerges as the return value of the `flip` method call. Since general Raku code may be run from within the parentheses of `$( )`, the same effect can also be achieved with a bit more effort, like in statement `[9]`. Statement `[10]` illustrates how the stringified version of the code's return value (the Boolean value `False`) is matched literally.
Finally, statements `[11]` and `[12]` show how the value of `$pattern4` and the return value of `f1` are *not* subject to a further round of interpolation. Hence, in general, after possible stringification, `$variable` and `$(code)` provide for a strictly literal match of the variable or return value.
Now consider the second two syntactical forms from the table above: `<$variable>` and `<{code}>`. These forms will stringify the value of the variable or the return value of the code and interpolate it as a regex. If the respective value is a [`Regex`](/type/Regex), it is interpolated as such:
```raku
my $string = 'Is this a regex or a string: 123\w+$x ?';
my $pattern1 = '\w+';
my $number = 123;
my sub f1 { return /s\w+/ };
say $string.match: / <$pattern1> /; # OUTPUT: «「Is」»
say $string.match: / <$number> /; # OUTPUT: «「123」»
say $string.match: / <{ f1 }> /; # OUTPUT: «「string」»
```
Importantly, 'to interpolate as a regex' means to interpolate/insert into the target regex without protective quoting. Consequently, if the value of the variable `$variable1` is itself of the form `$variable2`, evaluation of `<$variable1>` or `<{ $variable1 }>` inside a target regex `/.../` will cause the target regex to assume the form `/$variable2/`. As described above, the evaluation of this regex will then trigger further interpolation of `$variable2`:
```raku
my $string = Q[Mindless \w+ $variable1 $variable2];
my $variable1 = Q[\w+];
my $variable2 = Q[$variable1];
my sub f1 { return Q[$variable2] };
# /<{ f1 }>/ ==> /$variable2/ ==> / '$variable1' /
say $string.match: / <{ f1 }> /; # OUTPUT: «「$variable1」»
# /<$variable2>/ ==> /$variable1/ ==> / '\w+' /
say $string.match: /<$variable2>/; # OUTPUT: «「\w+」»
# /<$variable1>/ ==> /\w+/
say $string.match: /<$variable1>/; # OUTPUT: «「Mindless」»
```
When an array variable is interpolated into a regex, the regex engine handles it like a `|` alternative of the regex elements (see the documentation on [embedded lists](/language/regexes#Quoted_lists_are_LTM_matches), above). The interpolation rules for individual elements are the same as for scalars, so strings and numbers match literally, and [`Regex`](/type/Regex) objects match as regexes. Just as with ordinary `|` interpolation, the longest match succeeds:
```raku
my @a = '2', 23, rx/a.+/;
say ('b235' ~~ / b @a /).Str; # OUTPUT: «b23»
```
If you have an expression that evaluates to a list, but you do not want to assign it to an @-sigiled variable first, you can interpolate it with `@(code)`. In this example, both regexes are equivalent:
```raku
my %h = a => 1, b => 2;
my @a = %h.keys;
say S:g/@(%h.keys)/%h{$/}/ given 'abc'; # OUTPUT: «12c>
say S:g/@a/%h{$/}/ given 'abc'; # OUTPUT: «12c>
```
The use of hashes in regexes is reserved.
## [Regex Boolean condition check](#Regexes "go to top of document")[§](#Regex_Boolean_condition_check "direct link")
The special operator `<?{}>` allows the evaluation of a Boolean expression that can perform a semantic evaluation of the match before the regular expression continues. In other words, it is possible to check in a Boolean context a part of a regular expression and therefore invalidate the whole match (or allow it to continue) even if the match succeeds from a syntactic point of |
## regexes.md
## Chunk 4 of 5
view.
In particular the `<?{}>` operator requires a `True` value in order to allow the regular expression to match, while its negated form `<!{}>` requires a `False` value.
In order to demonstrate the above operator, please consider the following example that involves a simple IPv4 address matching:
```raku
my $localhost = '127.0.0.1';
my regex ipv4-octet { \d ** 1..3 <?{ True }> }
$localhost ~~ / ^ <ipv4-octet> ** 4 % "." $ /;
say $/<ipv4-octet>; # OUTPUT: «[「127」 「0」 「0」 「1」]»
```
The `octet` regular expression matches against a number made by one up to three digits. Each match is driven by the result of the `<?{}>`, that being the fixed value of `True` means that the regular expression match has to be always considered as good. As a counter-example, using the special constant value `False` will invalidate the match even if the regular expression matches from a syntactic point of view:
```raku
my $localhost = '127.0.0.1';
my regex ipv4-octet { \d ** 1..3 <?{ False }> }
$localhost ~~ / ^ <ipv4-octet> ** 4 % "." $ /;
say $/<ipv4-octet>; # OUTPUT: «Nil»
```
From the above examples, it should be clear that it is possible to improve the semantic check, for instance ensuring that each *octet* is really a valid IPv4 octet:
```raku
my $localhost = '127.0.0.1';
my regex ipv4-octet { \d ** 1..3 <?{ 0 <= $/.Int <= 255 }> }
$localhost ~~ / ^ <ipv4-octet> ** 4 % "." $ /;
say $/<ipv4-octet>; # OUTPUT: «[「127」 「0」 「0」 「1」]»
```
Please note that it is not required to evaluate the regular expression in-line, but also a regular method can be called to get the Boolean value:
```raku
my $localhost = '127.0.0.1';
sub check-octet ( Int $o ){ 0 <= $o <= 255 }
my regex ipv4-octet { \d ** 1..3 <?{ &check-octet( $/.Int ) }> }
$localhost ~~ / ^ <ipv4-octet> ** 4 % "." $ /;
say $/<ipv4-octet>; # OUTPUT: «[「127」 「0」 「0」 「1」]»
```
Of course, being `<!{}>` the negation form of `<?{}>` the same Boolean evaluation can be rewritten in a negated form:
```raku
my $localhost = '127.0.0.1';
sub invalid-octet( Int $o ){ $o < 0 || $o > 255 }
my regex ipv4-octet { \d ** 1..3 <!{ &invalid-octet( $/.Int ) }> }
$localhost ~~ / ^ <ipv4-octet> ** 4 % "." $ /;
say $/<ipv4-octet>; # OUTPUT: «[「127」 「0」 「0」 「1」]»
```
# [Adverbs](#Regexes "go to top of document")[§](#Adverbs "direct link")
Adverbs, which modify how regexes work and provide convenient shortcuts for certain kinds of recurring tasks, are combinations of one or more letters preceded by a colon `:`.
The so-called *regex* adverbs apply at the point where a regex is defined; additionally, *matching* adverbs apply at the point that a regex matches against a string and *substitution* adverbs are applied exclusively in substitutions.
This distinction often blurs, because matching and declaration are often textually close but using the method form of matching, that is, `.match`, makes the distinction clear.
```raku
say "Abra abra CADABRA" ~~ m:exhaustive/:i a \w+ a/;
# OUTPUT: «(「Abra」 「abra」 「ADABRA」 「ADA」 「ABRA」)»
my $regex = /:i a \w+ a /;
say "Abra abra CADABRA".match($regex,:ex);
# OUTPUT: «(「Abra」 「abra」 「ADABRA」 「ADA」 「ABRA」)»
```
In the first example, the matching adverb (`:exhaustive`) is contiguous to the regex adverb (`:i`), and as a matter of fact, the "definition" and the "matching" go together; however, by using `match` it becomes clear that `:i` is only used when defining the `$regex` variable, and `:ex` (short for `:exhaustive`) as an argument when matching. As a matter of fact, matching adverbs cannot even be used in the definition of a regex:
```raku
my $regex = rx:ex/:i a \w+ a /;
# ===SORRY!=== Error while compiling (...)Adverb ex not allowed on rx
```
Regex adverbs like `:i` go into the definition line and matching adverbs like `:overlap` (which can be abbreviated to `:ov`) are appended to the match call:
```raku
my $regex = /:i . a/;
for 'baA'.match($regex, :overlap) -> $m {
say ~$m;
}
# OUTPUT: «baaA»
```
## [Regex adverbs](#Regexes "go to top of document")[§](#Regex_adverbs "direct link")
The adverbs that appear at the time of a regex declaration are part of the actual regex and influence how the Raku compiler translates the regex into binary code.
For example, the `:ignorecase` (`:i`) adverb tells the compiler to ignore the distinction between uppercase, lowercase, and titlecase letters.
So `'a' ~~ /A/` is false, but `'a' ~~ /:i A/` is a successful match.
Regex adverbs can come before or inside a regex declaration and only affect the part of the regex that comes afterwards, lexically. Note that regex adverbs appearing before the regex must appear after something that introduces the regex to the parser, like 'rx' or 'm' or a bare '/'. This is NOT valid:
```raku
my $rx1 = :i/a/; # adverb is before the regex is recognized => exception
```
but these are valid:
```raku
my $rx1 = rx:i/a/; # before
my $rx2 = m:i/a/; # before
my $rx3 = /:i a/; # inside
```
These two regexes are equivalent:
```raku
my $rx1 = rx:i/a/; # before
my $rx2 = rx/:i a/; # inside
```
Whereas these two are not:
```raku
my $rx3 = rx/a :i b/; # matches only the b case insensitively
my $rx4 = rx/:i a b/; # matches completely case insensitively
```
Square brackets and parentheses limit the scope of an adverb:
```raku
/ (:i a b) c /; # matches 'ABc' but not 'ABC'
/ [:i a b] c /; # matches 'ABc' but not 'ABC'
```
Alternations and conjunctions, and their branches, have no impact on the scope of an adverb:
/ :i a | b c /; # matches 'a', 'A', 'bc', 'Bc', 'bC' or 'BC' / [:i a | b] c /; # matches 'ac', 'Ac', 'bc', or 'Bc' but not 'aC', 'AC', 'bC' or 'BC'
When two adverbs are used together, they keep their colon at the front
```raku
"þor is Þor" ~~ m:g:i/þ/; # OUTPUT: «(「þ」 「Þ」)»
```
That implies that when there are multiple characters together after a `:`, they correspond to the same adverb, as in `:ov` or `:P5`.
### [Ignorecase](#Regexes "go to top of document")[§](#Ignorecase "direct link")
The `:ignorecase` or `:i` adverb instructs the regex engine to ignore the distinction between uppercase, lowercase, and titlecase letters.
See the [section Regex adverbs](/language/regexes#Regex_adverbs) for examples.
### [Ignoremark](#Regexes "go to top of document")[§](#Ignoremark "direct link")
The `:ignoremark` or `:m` adverb instructs the regex engine to only compare base characters, and ignore additional marks such as combining accents:
```raku
say so 'a' ~~ rx/ä/; # OUTPUT: «False»
say so 'a' ~~ rx:ignoremark /ä/; # OUTPUT: «True»
say so 'ỡ' ~~ rx:ignoremark /o/; # OUTPUT: «True»
```
### [Ratchet](#Regexes "go to top of document")[§](#Ratchet "direct link")
The `:ratchet` or `:r` adverb causes the regex engine to not backtrack (see [backtracking](/language/regexes#Backtracking)). Mnemonic: a [ratchet](https://en.wikipedia.org/wiki/Ratchet_%28device%29) only moves in one direction and can't backtrack.
Without this adverb, parts of a regex will try different ways to match a string in order to make it possible for other parts of the regex to match. For example, in `'abc' ~~ /\w+ ./`, the `\w+` first eats up the whole string, `abc` but then the `.` fails. Thus `\w+` gives up a character, matching only `ab`, and the `.` can successfully match the string `c`. This process of giving up characters (or in the case of alternations, trying a different branch) is known as backtracking.
```raku
say so 'abc' ~~ / \w+ . /; # OUTPUT: «True»
say so 'abc' ~~ / :r \w+ . /; # OUTPUT: «False»
```
Ratcheting can be an optimization, because backtracking is costly. But more importantly, it closely corresponds to how humans parse a text. If you have a regex `my regex identifier { \w+ }` and `my regex keyword { if | else | endif }`, you intuitively expect the `identifier` to gobble up a whole word and not have it give up its end to the next rule, if the next rule otherwise fails.
For example, you don't expect the word `motif` to be parsed as the identifier `mot` followed by the keyword `if`. Instead, you expect `motif` to be parsed as one identifier; and if the parser expects an `if` afterwards, best that it should fail than have it parse the input in a way you don't expect.
Since ratcheting behavior is often desirable in parsers, there's a shortcut to declaring a ratcheting regex:
```raku
my token thing { ... };
# short for
my regex thing { :r ... };
```
### [Sigspace](#Regexes "go to top of document")[§](#Sigspace "direct link")
The **`:sigspace`** or **`:s`** adverb changes the behavior of unquoted whitespace in a regex.
Without `:sigspace`, unquoted whitespace in a regex is generally ignored, to make regexes more readable by programmers. When `:sigspace` is present, unquoted whitespace may be converted into `<.ws>` subrule calls depending on where it occurs in the regex.
```raku
say so "I used Photoshop®" ~~ m:i/ photo shop /; # OUTPUT: «True»
say so "I used a photo shop" ~~ m:i:s/ photo shop /; # OUTPUT: «True»
say so "I used Photoshop®" ~~ m:i:s/ photo shop /; # OUTPUT: «False»
```
`m:s/ photo shop /` acts the same as `m/ photo <.ws> shop <.ws> /`. By default, `<.ws>` makes sure that words are separated, so `a b` and `^&` will match `<.ws>` in the middle, but `ab` won't:
```raku
say so "ab" ~~ m:s/a <.ws> b/; # OUTPUT: «False»
say so "a b" ~~ m:s/a <.ws> b/; # OUTPUT: «True»
say so "^&" ~~ m:s/'^' <.ws> '&'/; # OUTPUT: «True»
```
The third line is matched, because `^&` is not a word. For more clarification on how `<.ws>` rule works, refer to [WS rule description](/language/grammars#ws).
Where whitespace in a regex turns into `<.ws>` depends on what comes before the whitespace. In the above example, whitespace in the beginning of a regex doesn't turn into `<.ws>`, but whitespace after characters does. In general, the rule is that if a term might match something, whitespace after it will turn into `<.ws>`.
In addition, if whitespace comes after a term but *before* a quantifier (`+`, `*`, or `?`), `<.ws>` will be matched after every match of the term. So, `foo +` becomes `[ foo <.ws> ]+`. On the other hand, whitespace *after* a quantifier acts as normal significant whitespace; e.g., "`foo+` " becomes `foo+ <.ws>`. On the other hand, whitespace between a quantifier and the `%` or `%%` quantifier modifier is not significant. Thus `foo+ % ,` does *not* become `foo+ <.ws>% ,` (which would be invalid anyway); instead, neither of the spaces are significant.
In all, this code:
```raku
rx :s {
^^
{
say "No sigspace after this";
}
<.assertion_and_then_ws>
characters_with_ws_after+
ws_separated_characters *
[
| some "stuff" .. .
| $$
]
:my $foo = "no ws after this";
$foo
}
```
Becomes:
```raku
rx {
^^ <.ws>
{
say "No space after this";
}
<.assertion_and_then_ws> <.ws>
characters_with_ws_after+ <.ws>
[ws_separated_characters <.ws>]* <.ws>
[
| some <.ws> "stuff" <.ws> .. <.ws> . <.ws>
| $$ <.ws>
] <.ws>
:my $foo = "no ws after this";
$foo <.ws>
}
```
If a regex is declared with the `rule` keyword, both the `:sigspace` and `:ratchet` adverbs are implied.
Grammars provide an easy way to override what `<.ws>` matches:
```raku
grammar Demo {
token ws {
<!ww> # only match when not within a word
\h* # only match horizontal whitespace
}
rule TOP { # called by Demo.parse;
a b '.'
}
}
# doesn't parse, whitespace required between a and b
say so Demo.parse("ab."); # OUTPUT: «False»
say so Demo.parse("a b."); # OUTPUT: «True»
say so Demo.parse("a\tb ."); # OUTPUT: «True»
# \n is vertical whitespace, so no match
say so Demo.parse("a\tb\n."); # OUTPUT: «False»
```
When parsing file formats where some whitespace (for example, vertical whitespace) is significant, it's advisable to override `ws`.
### [Perl compatibility adverb](#Regexes "go to top of document")[§](#Perl_compatibility_adverb "direct link")
The **`:Perl5`** or **`:P5`** adverb switch the Regex parsing and matching to the way Perl regexes behave:
```raku
so 'hello world' ~~ m:Perl5/^hello (world)/; # OUTPUT: «True»
so 'hello world' ~~ m/^hello (world)/; # OUTPUT: «False»
so 'hello world' ~~ m/^ 'hello ' ('world')/; # OUTPUT: «True»
```
The regular behavior is recommended and more idiomatic in Raku of course, but the **`:Perl5`** adverb can be useful when compatibility with Perl is required.
## [Matching adverbs](#Regexes "go to top of document")[§](#Matching_adverbs "direct link")
In contrast to regex adverbs, which are tied to the declaration of a regex, matching adverbs only make sense when matching a string against a regex.
They can never appear inside a regex, only on the outside – either as part of an `m/.../` match or as arguments to a match method.
### [Positional adverbs](#Regexes "go to top of document")[§](#Positional_adverbs "direct link")
Positional adverbs make the expression match only the string in the indicated position:
```raku
my $data = "f fo foo fooo foooo fooooo foooooo";
say $data ~~ m:nth(4)/fo+/; # OUTPUT: «「foooo」»
say $data ~~ m:1st/fo+/; # OUTPUT: «「fo」»
say $data ~~ m:3rd/fo+/; # OUTPUT: «「fooo」»
say $data ~~ m:nth(1,3)/fo+/; # OUTPUT: «(「fo」 「fooo」)»
```
As you can see, the adverb argument can also be a list. There's actually no difference between the `:nth` adverb and the rest. You choose them only based on legibility. From 6.d, you can also use [`Junction`](/type/Junction)s, [`Seq`](/type/Seq)s and [`Range`](/type/Range)s, even infinite ones, as arguments.
```raku
my $data = "f fo foo fooo foooo fooooo foooooo";
say $data ~~ m:st(1|8)/fo+/; # OUTPUT: «True»
```
In this case, one of them exists (1), so it returns True. Observe that we have used `:st`. As said above, it's functionally equivalent, although obviously less legible than using `:nth`, so this last form is advised.
### [Counting](#Regexes "go to top of document")[§](#Counting "direct link")
The `:x` counting adverb makes the expression match many times, like the `:g` adverb, but only up to the limit given by the adverb expression, stopping once the specified number of matches has been reached. The value must be a [`Numeric`](/type/Numeric) or a [`Range`](/type/Range).
```raku
my $data = "f fo foo fooo foooo fooooo foooooo";
$data ~~ s:x(8)/o/X/; # f fX fXX fXXX fXXoo fooooo foooooo
```
### [Continue](#Regexes "go to top of document")[§](#Continue "direct link")
The `:continue` or short `:c` adverb takes an argument. The argument is the position where the regex should start to search. By default, it searches from the start of the string, but `:c` overrides that. If no position is specified for `:c`, it will default to `0` unless `$/` is set, in which case, it defaults to `$/.to`.
```raku
given 'a1xa2' {
say ~m/a./; # OUTPUT: «a1»
say ~m:c(2)/a./; # OUTPUT: «a2»
}
```
*Note:* unlike `:pos`, a match with :continue() will attempt to match further in the string, instead of failing:
```raku
say "abcdefg" ~~ m:c(3)/e.+/; # OUTPUT: «「efg」»
say "abcdefg" ~~ m:p(3)/e.+/; # OUTPUT: «False»
```
### [Exhaustive](#Regexes "go to top of document")[§](#Exhaustive "direct link")
To find all possible matches of a regex – including overlapping ones – and several ones that start at the same position, use the `:exhaustive` (short `:ex`) adverb.
```raku
given 'abracadabra' {
for m:exhaustive/ a .* a / -> $match {
say ' ' x $match.from, ~$match;
}
}
```
The above code produces this output:
「text」 without highlighting
```
```
abracadabra
abracada
abraca
abra
acadabra
acada
aca
adabra
ada
abra
```
```
### [Global](#Regexes "go to top of document")[§](#Global "direct link")
Instead of searching for just one match and returning a [`Match`](/type/Match), search for every non-overlapping match and return them in a [`List`](/type/List). In order to do this, use the `:global` adverb:
```raku
given 'several words here' {
my @matches = m:global/\w+/;
say @matches.elems; # OUTPUT: «3»
say ~@matches[2]; # OUTPUT: «here»
}
```
`:g` is shorthand for `:global`.
### [Pos](#Regexes "go to top of document")[§](#Pos "direct link")
Anchor the match at a specific position in the string:
```raku
given 'abcdef' {
my $match = m:pos(2)/.*/;
say $match.from; # OUTPUT: «2»
say ~$match; # OUTPUT: «cdef»
}
```
`:p` is shorthand for `:pos`.
*Note:* unlike `:continue`, a match anchored with :pos() will fail, instead of attempting to match further down the string:
```raku
say "abcdefg" ~~ m:c(3)/e.+/; # OUTPUT: «「efg」»
say "abcdefg" ~~ m:p(3)/e.+/; # OUTPUT: «False»
```
### [Overlap](#Regexes "go to top of document")[§](#Overlap "direct link")
To get several matches, including overlapping matches, but only one (the longest) from each starting position, specify the `:overlap` (short `:ov`) adverb:
```raku
given 'abracadabra' {
for m:overlap/ a .* a / -> $match {
say ' ' x $match.from, ~$match;
}
}
```
produces
「text」 without highlighting
```
```
abracadabra
acadabra
adabra
abra
```
```
## [Substitution adverbs](#Regexes "go to top of document")[§](#Substitution_adverbs "direct link")
You can apply matching adverbs (such as `:global`, `:pos` etc.) to substitutions. In addition, there are adverbs that only make sense for substitutions, because they transfer a property from the matched string to the replacement string.
### [Samecase](#Regexes "go to top of document")[§](#Samecase "direct link")
The `:samecase` or `:ii` substitution adverb implies the `:ignorecase` adverb for the regex part of the substitution, and in addition carries the case information to the replacement string:
```raku
$_ = 'The cat chases the dog';
s:global:samecase[the] = 'a';
say $_; # OUTPUT: «A cat chases a dog»
```
Here you can see that the first replacement string `a` got capitalized, because the first string of the matched string was also a capital letter.
### [Samemark](#Regexes "go to top of document")[§](#Samemark "direct link")
The `:samemark` or `:mm` adverb implies `:ignoremark` for the regex, and in addition, copies the markings from the matched characters to the replacement string:
```raku
given 'äộñ' {
say S:mm/ a .+ /uia/; # OUTPUT: «üị̂ã»
}
```
### [Samespace](#Regexes "go to top of document")[§](#Samespace "direct link")
The `:samespace` or `:ss` substitution modifier implies the `:sigspace` modifier for the regex, and in addition, copies the whitespace from the matched string to the replacement string:
```raku
say S:samespace/a ./c d/.raku given "a b"; # OUTPUT: «"c d"»
say S:samespace/a ./c d/.raku given "a\tb"; # OUTPUT: «"c\td"»
say S:samespace/a ./c d/.raku given "a\nb"; # OUTPUT: «"c\nd"»
```
The `ss/.../.../` syntactic form is a shorthand for `s:samespace/.../.../`.
# [Backtracking](#Regexes "go to top of document")[§](#Backtracking "direct link")
Raku defaults to [backtracking](/language/glossary#Backtracking) when evaluating regular expressions. Backtracking is a technique that allows the engine to try different matching in order to allow every part of a regular expression to succeed. This is costly, because it requires the engine to usually eat up as much as possible in the first match and then adjust going backwards in order to ensure all regular expression parts have a chance to match.
## [Understanding backtracking](#Regexes "go to top of document")[§](#Understanding_backtracking "direct link")
In order to better understand backtracking, consider the following example:
```raku
my $string = 'PostgreSQL is a SQL database!';
say $string ~~ /(.+)(SQL) (.+) $1/; # OUTPUT: «「PostgreSQL is a SQL」»
```
What happens in the above example is that the string has to be matched against the second occurrence of the word *SQL*, eating all characters before and leaving out the rest.
Since it is possible to execute a piece of code within a regular expression, it is also possible to inspect the [`Match`](/type/Match) object within the regular expression itself:
```raku
my $iteration = 0;
sub show-captures( Match $m ){
my Str $result_split;
say "\n=== Iteration {++$iteration} ===";
for $m.list.kv -> $i, $capture {
say "Capture $i = $capture";
$result_split ~= '[' ~ $capture ~ ']';
}
say $result_split;
}
$string ~~ /(.+)(SQL) (.+) $1 .+ { show-captures( $/ ); }/;
```
The `show-captures` method will dump all the elements of `$/` producing the following output:
「text」 without highlighting
```
```
=== Iteration 1 ===
Capture 0 = Postgre
Capture 1 = SQL
Capture 2 = is a
[Postgre][SQL][ is a ]
```
```
showing that the string has been split around the second occurrence of *SQL*, that is the repetition of the first capture (`$/[1]`).
With that in place, it is now possible to see how the engine backtracks to find the above match: it does suffice to move the `show-captures` in the middle of the regular expression, in particular before the repetition of the first capture `$1` to see it in action:
```raku
my $iteration = 0;
sub show-captures( Match $m ){
my Str $result-split;
say "\n=== Iteration {++$iteration} ===";
for $m.list.kv -> $i, $capture {
say "Capture $i = $capture";
$result-split ~= '[' ~ $capture ~ ']';
}
say $result-split;
}
$string ~~ / (.+)(SQL) (.+) { show-captures( $/ ); } $1 /;
```
The output will be much more verbose and will show several iterations, with the last one being the *winning*. The following is an excerpt of the output:
「text」 without highlighting
```
```
=== Iteration 1 ===
Capture 0 = PostgreSQL is a
Capture 1 = SQL
Capture 2 = database!
[PostgreSQL is a ][SQL][ database!]
=== Iteration 2 ===
Capture 0 = PostgreSQL is a
Capture 1 = SQL
Capture 2 = database
[PostgreSQL is a ][SQL][ database]
...
=== Iteration 24 ===
Capture 0 = Postgre
Capture 1 = SQL
Capture 2 = is a
[Postgre][SQL][ is a ]
```
```
In the first iteration the *SQL* part of *PostgreSQL* is kept within the word: that is not what the regular expression asks for, so there's the need for another iteration. The second iteration will move back, in particular one character back (removing thus the final *!*) and try to match again, resulting in a fail since again the *SQL* is still kept within *PostgreSQL*. After several iterations, the final result is match.
It is worth noting that the final iteration is number *24*, and that such number is exactly the distance, in number of chars, from the end of the string to the first *SQL* occurrence:
```raku
say $string.chars - $string.index: 'SQL'; # OUTPUT: «23»
```
Since there are 23 chars from the very end of the string to the very first *S* of *SQL* the backtracking engine will need 23 "useless" matches to find the right one, that is, it will need 24 steps to get the final result.
Backtracking is a costly machinery, therefore it is possible to disable it in those cases where the matching can be found *forward* only.
With regards to the above example, disabling backtracking means the regular expression will not have any chance to match:
```raku
say $string ~~ /(.+)(SQL) (.+) $1/; # OUTPUT: «「PostgreSQL is a SQL」»
say $string ~~ / :r (.+)(SQL) (.+) $1/; # OUTPUT: «Nil»
```
The fact is that, as shown in the *iteration 1* output, the first match of the regular expression engine will be `PostgreSQL is a` , `SQL`, `database` that does not leave out any room for matching another occurrence of the word *SQL* (as `$1` in the regular expression). Since the engine is not able to get backward and change the path to match, the regular expression fails.
It is worth noting that disabling backtracking will not prevent the engine to try several ways to match the regular expression. Consider the following slightly changed example:
```raku
my $string = 'PostgreSQL is a SQL database!';
say $string ~~ / (SQL) (.+) $1 /; # OUTPUT: «Nil»
```
Since there is no specification for a character before the word *SQL*, the engine will match against the rightmost word *SQL* and go forward from there. Since there is no repetition of *SQL* remaining, the match fails. It is possible, again, to inspect what the engine performs introducing a dumping piece of code within the regular expression:
```raku
my $iteration = 0;
sub show-captures( Match $m ){
my Str $result-split;
say "\n=== Iteration {++$iteration} ===";
for $m.list.kv -> $i, $capture {
say "Capture $i = $capture";
$result-split ~= '[' ~ $capture ~ ']';
}
say $result-split;
}
$string ~~ / (SQL) (.+) { show-captures( $/ ); } $1 /;
```
that produces a rather simple output:
「text」 without highlighting
```
```
=== Iteration 1 ===
Capture 0 = SQL
Capture 1 = is a SQL database!
[SQL][ is a SQL database!]
=== Iteration 2 ===
Capture 0 = SQL
Capture 1 = database!
[SQL][ database!]
```
```
Even using the [:r](/language/regexes#Ratchet) adverb to prevent backtracking will not change things:
```raku
my $iteration = 0;
sub show-captures( Match $m ){
my Str $result-split;
say "\n=== Iteration {++$iteration} ===";
for $m.list.kv -> $i, $capture {
say "Capture $i = $capture";
$result-split ~= '[' ~ $capture ~ ']';
}
say $result-split;
}
$string ~~ / :r (SQL) (.+) { show-captures( $/ ); } $1 /;
```
and the output will remain the same:
「text」 without highlighting
```
```
=== Iteration 1 ===
Capture 0 = SQL
Capture 1 = is a SQL database!
[SQL][ is a SQL database!]
=== Iteration 2 ===
Capture 0 = SQL
Capture 1 = database!
[SQL][ database!]
```
```
This demonstrates that disabling backtracking does not mean disabling possible multiple iterations of the matching engine, but rather disabling the backward matching tuning.
## [Backtracking control](#Regexes "go to top of document")[§](#Backtracking_control "direct link")
Raku offers several tools for controlling backtracking. First, you can use the `:ratchet` regex adverb to turn ratcheting on (or `:!ratchet` to turn it off). See [backtracking](/language/regexes#Ratchet) for details. Note that, as with all regex adverbs, you can limit the scope of `:ratchet` using square brackets. Thus, in the following code, backtracking is enabled for the first quantifier (`\S+`), disabled for the second quantifier (`\s+`), and re-enabled for the third (`\d+`).
```raku
'A 42' ~~ rx/\S+ [:r \s+ [:!r \d+ ] ] . / # OUTPUT: «「A 42」»
```
`:ratchet` is enabled by default in `token`s and `rule`s; see [grammars](/language/grammars) for more details.
Raku also offers three regex metacharacters to control backtracking at for an individual atom.
### [Disable backtracking: `:`](#Regexes "go to top of document")[§](#Disable_backtracking:_: "direct link")
The `:` metacharacter disables backtracking for the previous atom. Thus, `/ .*: a/` does not match `" a"` because the `.*` matches the entire string, leaving nothing for the `a` to match without backtracking.
### [Enable greedy backtracking: `:!`](#Regexes "go to top of document")[§](#Enable_greedy_backtracking:_:! "direct link")
The `:!` metacharacter enables greedy backtracking for the previous atom – that is, provides the backtracking behavior that's used when `:ratchet` is not in effect. `:!` is closely related to the `!` [greedy quantifier modifier](/language/regexes#Greedy_versus_frugal_quantifiers:_?); however – unlike `!`, which can only be used after a quantifier – `:!` can be used after any atom. For example, `:!` can be used after an alternation:
```raku
'abcd' ~~ /:ratchet [ab | abc] cd/; # OUTPUT: «Nil»
'abcd' ~~ |
## regexes.md
## Chunk 5 of 5
/:ratchet [ab | abc]:! cd/; # OUTPUT: «「abcd」»
```
### [Enable frugal backtracking: `:?`](#Regexes "go to top of document")[§](#Enable_frugal_backtracking:_:? "direct link")
The `:?` metacharacter works exactly like `:!`, except that it enables frugal backtracking. It is thus closely related to `?` [frugal quantifier modifier](/language/regexes#Greedy_versus_frugal_quantifiers:_?); again, however `:?` can be used after non-quantifier atoms. This includes contexts in which `?` would be the [zero or one](#Zero_or_one:_?) quantifier (instead of providing backtracking control):
```raku
my regex numbers { \d* }
'4247' ~~ /:ratchet <numbers>? 47/; # OUTPUT: «Nil»
'4247' ~~ /:ratchet <numbers>:? 47/; # OUTPUT: «「4247」»
```
## [A note on backtracking with sub-regexes](#Regexes "go to top of document")[§](#A_note_on_backtracking_with_sub-regexes "direct link")
`:`, `:!`, and `:?` control the backtracking behavior in their current regex – that is, they cause an atom to behave as though `:ratchet` were set differently in the current regex. However, neither these metacharacters nor `:!ratchet` can cause a non-backtracking sub-regex (including rules or tokens) to backtrack; the sub-regex has already failed to backtrack. On the other hand, they *can* prevent the sub-regex from backtracking. To expand on our previous example:
```raku
my regex numbers { \d* }
# By default <numbers> backtracks
'4247' ~~ / <numbers> 47/; # OUTPUT: «「4247」»
# : can disable backtracking over <numbers>
'4247' ~~ / <numbers>: 47/; # OUTPUT: «Nil»
my regex numbers-ratchet {:ratchet \d* }
# <numbers-ratchet> never backtracks
'4247' ~~ / <numbers-ratchet> 47/; # OUTPUT: «Nil»
# :! can't make it
'4247' ~~ / <numbers-ratchet>:! 47/; # OUTPUT: «Nil»
# Neither can setting :!ratchet
'4247' ~~ /:!r <numbers-ratchet> 47/; # OUTPUT: «Nil»
```
# [`$/` changes each time a regular expression is matched](#Regexes "go to top of document")[§](#$/_changes_each_time_a_regular_expression_is_matched "direct link")
It is worth noting that each time a regular expression is used, the returned [`Match`](/type/Match) (i.e., `$/`) is reset. In other words, `$/` always refers to the very last regular expression matched:
```raku
my $answer = 'a lot of Stuff';
say 'Hit a capital letter!' if $answer ~~ / <[A..Z>]> /;
say $/; # OUTPUT: «「S」»
say 'hit an x!' if $answer ~~ / x /;
say $/; # OUTPUT: «Nil»
```
The reset of `$/` applies independently from the scope where the regular expression is matched:
```raku
my $answer = 'a lot of Stuff';
if $answer ~~ / <[A..Z>]> / {
say 'Hit a capital letter';
say $/; # OUTPUT: «「S」»
}
say $/; # OUTPUT: «「S」»
if True {
say 'hit an x!' if $answer ~~ / x /;
say $/; # OUTPUT: «Nil»
}
say $/; # OUTPUT: «Nil»
```
The very same concept applies to named captures:
```raku
my $answer = 'a lot of Stuff';
if $answer ~~ / $<capital>=<[A..Z>]> / {
say 'Hit a capital letter';
say $/<capital>; # OUTPUT: «「S」»
}
say $/<capital>; # OUTPUT: «「S」»
say 'hit an x!' if $answer ~~ / $<x>=x /;
say $/<x>; # OUTPUT: «Nil»
say $/<capital>; # OUTPUT: «Nil»
```
# [Best practices and gotchas](#Regexes "go to top of document")[§](#Best_practices_and_gotchas "direct link")
The [Regexes: Best practices and gotchas](/language/regexes-best-practices) provides useful information on how to avoid common pitfalls when writing regexes and grammars.
|
## dist_zef-antononcube-Markup-Calendar.md
# Markup::Calendar
Raku package with Markup (HTML, Markdown) calendar functions for displaying monthly, yearly, and custom calendars.
### Motivation
The package
["Text::Calendar"](https://raku.land/zef:antononcube/Text::Calendar), [AAp1],
provides the core functions for making the calendars in this package.
The packages
["Data::Translators"](https://raku.land/zef:antononcube/Data::Translators), [AAp2], and
["Pretty::Table"](https://raku.land/cpan:ANTONOV/Pretty::Table), [ULp1],
provide additional formatting functionalities.
I want to keep "Text::Calendar" lightweight, without any dependencies. Hence I made this separate
package, "Markup::Calendar", that has more involved dependencies and use-cases.
An "involved use case" is calendar in which some of the days have tooltips and hyperlinks.
---
## Installation
From [Zef ecosystem](https://raku.land):
```
zef install Markup::Calendar
```
From GitHub:
```
zef install https://github.com/antononcube/Raku-Markup-Calendar.git
```
---
## Examples
### Basic HTML calendar
```
use Markup::Calendar;
use Text::Calendar;
calendar():html
```
| | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | |
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
| January 2024 | Mo | Tu | We | Th | Fr | Sa | Su | | --- | --- | --- | --- | --- | --- | --- | | 1 | 2 | 3 | 4 | 5 | 6 | 7 | | 8 | 9 | 10 | 11 | 12 | 13 | 14 | | 15 | 16 | 17 | 18 | 19 | 20 | 21 | | 22 | 23 | 24 | 25 | 26 | 27 | 28 | | 29 | 30 | 31 | | | | | | February 2024 | Mo | Tu | We | Th | Fr | Sa | Su | | --- | --- | --- | --- | --- | --- | --- | | | | | 1 | 2 | 3 | 4 | | 5 | 6 | 7 | 8 | 9 | 10 | 11 | | 12 | 13 | 14 | 15 | 16 | 17 | 18 | | 19 | 20 | 21 | 22 | 23 | 24 | 25 | | 26 | 27 | 28 | 29 | | | | | March 2024 | Mo | Tu | We | Th | Fr | Sa | Su | | --- | --- | --- | --- | --- | --- | --- | | | | | | 1 | 2 | 3 | | 4 | 5 | 6 | 7 | 8 | 9 | 10 | | 11 | 12 | 13 | 14 | 15 | 16 | 17 | | 18 | 19 | 20 | 21 | 22 | 23 | 24 | | 25 | 26 | 27 | 28 | 29 | 30 | 31 | |
### HTML yearly calendar with highlights
Here is an HTML calendar that weekend days are highlighted and with larger font:
```
calendar-year(
per-row => 4,
highlight => (Date.new(2024,1,1)...Date.new(2024,12,31)).grep({ $_.day-of-week ≥ 6 }),
highlight-style => 'color:orange; font-size:14pt'
):html
```
## 2024
| | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | |
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
| January | Mo | Tu | We | Th | Fr | Sa | Su | | --- | --- | --- | --- | --- | --- | --- | | 1 | 2 | 3 | 4 | 5 | 6 | 7 | | 8 | 9 | 10 | 11 | 12 | 13 | 14 | | 15 | 16 | 17 | 18 | 19 | 20 | 21 | | 22 | 23 | 24 | 25 | 26 | 27 | 28 | | 29 | 30 | 31 | | | | | | February | Mo | Tu | We | Th | Fr | Sa | Su | | --- | --- | --- | --- | --- | --- | --- | | | | | 1 | 2 | 3 | 4 | | 5 | 6 | 7 | 8 | 9 | 10 | 11 | | 12 | 13 | 14 | 15 | 16 | 17 | 18 | | 19 | 20 | 21 | 22 | 23 | 24 | 25 | | 26 | 27 | 28 | 29 | | | | | March | Mo | Tu | We | Th | Fr | Sa | Su | | --- | --- | --- | --- | --- | --- | --- | | | | | | 1 | 2 | 3 | | 4 | 5 | 6 | 7 | 8 | 9 | 10 | | 11 | 12 | 13 | 14 | 15 | 16 | 17 | | 18 | 19 | 20 | 21 | 22 | 23 | 24 | | 25 | 26 | 27 | 28 | 29 | 30 | 31 | | April | Mo | Tu | We | Th | Fr | Sa | Su | | --- | --- | --- | --- | --- | --- | --- | | 1 | 2 | 3 | 4 | 5 | 6 | 7 | | 8 | 9 | 10 | 11 | 12 | 13 | 14 | | 15 | 16 | 17 | 18 | 19 | 20 | 21 | | 22 | 23 | 24 | 25 | 26 | 27 | 28 | | 29 | 30 | | | | | | |
| May | Mo | Tu | We | Th | Fr | Sa | Su | | --- | --- | --- | --- | --- | --- | --- | | | | 1 | 2 | 3 | 4 | 5 | | 6 | 7 | 8 | 9 | 10 | 11 | 12 | | 13 | 14 | 15 | 16 | 17 | 18 | 19 | | 20 | 21 | 22 | 23 | 24 | 25 | 26 | | 27 | 28 | 29 | 30 | 31 | | | | June | Mo | Tu | We | Th | Fr | Sa | Su | | --- | --- | --- | --- | --- | --- | --- | | | | | | | 1 | 2 | | 3 | 4 | 5 | 6 | 7 | 8 | 9 | | 10 | 11 | 12 | 13 | 14 | 15 | 16 | | 17 | 18 | 19 | 20 | 21 | 22 | 23 | | 24 | 25 | 26 | 27 | 28 | 29 | 30 | | July | Mo | Tu | We | Th | Fr | Sa | Su | | --- | --- | --- | --- | --- | --- | --- | | 1 | 2 | 3 | 4 | 5 | 6 | 7 | | 8 | 9 | 10 | 11 | 12 | 13 | 14 | | 15 | 16 | 17 | 18 | 19 | 20 | 21 | | 22 | 23 | 24 | 25 | 26 | 27 | 28 | | 29 | 30 | 31 | | | | | | August | Mo | Tu | We | Th | Fr | Sa | Su | | --- | --- | --- | --- | --- | --- | --- | | | | | 1 | 2 | 3 | 4 | | 5 | 6 | 7 | 8 | 9 | 10 | 11 | | 12 | 13 | 14 | 15 | 16 | 17 | 18 | | 19 | 20 | 21 | 22 | 23 | 24 | 25 | | 26 | 27 | 28 | 29 | 30 | 31 | | |
| September | Mo | Tu | We | Th | Fr | Sa | Su | | --- | --- | --- | --- | --- | --- | --- | | | | | | | | 1 | | 2 | 3 | 4 | 5 | 6 | 7 | 8 | | 9 | 10 | 11 | 12 | 13 | 14 | 15 | | 16 | 17 | 18 | 19 | 20 | 21 | 22 | | 23 | 24 | 25 | 26 | 27 | 28 | 29 | | 30 | | | | | | | | October | Mo | Tu | We | Th | Fr | Sa | Su | | --- | --- | --- | --- | --- | --- | --- | | | 1 | 2 | 3 | 4 | 5 | 6 | | 7 | 8 | 9 | 10 | 11 | 12 | 13 | | 14 | 15 | 16 | 17 | 18 | 19 | 20 | | 21 | 22 | 23 | 24 | 25 | 26 | 27 | | 28 | 29 | 30 | 31 | | | | | November | Mo | Tu | We | Th | Fr | Sa | Su | | --- | --- | --- | --- | --- | --- | --- | | | | | | 1 | 2 | 3 | | 4 | 5 | 6 | 7 | 8 | 9 | 10 | | 11 | 12 | 13 | 14 | 15 | 16 | 17 | | 18 | 19 | 20 | 21 | 22 | 23 | 24 | | 25 | 26 | 27 | 28 | 29 | 30 | | | December | Mo | Tu | We | Th | Fr | Sa | Su | | --- | --- | --- | --- | --- | --- | --- | | | | | | | | 1 | | 2 | 3 | 4 | 5 | 6 | 7 | 8 | | 9 | 10 | 11 | 12 | 13 | 14 | 15 | | 16 | 17 | 18 | 19 | 20 | 21 | 22 | | 23 | 24 | 25 | 26 | 27 | 28 | 29 | | 30 | 31 | | | | | | |
### Standalone calendar file
Here we make a standalone calendar file:
```
spurt('example.html', calendar-year(year => 2024, highlight => [3=>3, 5=>24, 9=>9], highlight-style=>'color:red', format=>'html'))
```
```
# True
```
---
## TODO
* TODO Features
* DONE HTML
* DONE Full HTML calendar
* DONE Partial HTML calendar (e.g. equivalent of `cal -3`)
* DONE Highlighted days
* DONE Tooltips for days
* DONE Hyperlinks for days
* TODO Markdown
* TODO Full Markdown calendar
* TODO Partial Markdown calendar
* TODO Highlighted days
* TODO Tooltips for days
* TODO Hyperlinks for days
* Unit tests
* DONE Basic usage
* DONE Equivalence using different signatures
* TODO Correctness
* Documentation
* DONE Basic README
* TODO Diagrams
* TODO Comparisons
---
## References
[AAp1] Anton Antonov,
[Text::Calendar Raku package](https://github.com/antononcube/Raku-Text-Calendar),
(2024),
[GitHub/antononcube](https://github.com/antononcube).
[AAp2] Anton Antonov,
[Data::Translators Raku package](https://github.com/antononcube/Raku-Data-Translators),
(2023),
[GitHub/antononcube](https://github.com/antononcube).
[LUp1] Luis F. Uceta,
[Pretty::Table Raku package](https://gitlab.com/uzluisf/raku-pretty-table/),
(2020),
[GitLab/uzluisf](https://gitlab.com/uzluisf/).
|
## dist_zef-qorg11-Pleroma.md
[](https://github.com/dimethyltriptamine/pleroma-raku/actions)
|
## head.md
head
Combined from primary sources listed below.
# [In List](#___top "go to top of document")[§](#(List)_method_head "direct link")
See primary documentation
[in context](/type/List#method_head)
for **method head**.
```raku
multi method head(Any:D:) is raw
multi method head(Any:D: Callable:D $w)
multi method head(Any:D: $n)
```
This method is directly inherited from [`Any`](/type/Any), and it returns the **first** `$n` items of the list, an empty list if `$n` <= 0, or the first element with no argument. The version that takes a [`Callable`](/type/Callable) uses a [`WhateverCode`](/type/WhateverCode) to specify all elements, starting from the first, but the last ones.
Examples:
```raku
say <a b c d e>.head ; # OUTPUT: «a»
say <a b c d e>.head(2); # OUTPUT: «(a b)»
say <a b c d e>.head(*-3); # OUTPUT: «(a b)»
```
# [In Any](#___top "go to top of document")[§](#(Any)_routine_head "direct link")
See primary documentation
[in context](/type/Any#routine_head)
for **routine head**.
```raku
multi method head(Any:D:) is raw
multi method head(Any:D: Callable:D $w)
multi method head(Any:D: $n)
```
Returns either the first element in the object, or the first `$n` if that's used.
```raku
"aaabbc".comb.head.put; # OUTPUT: «a»
say ^10 .head(5); # OUTPUT: «(0 1 2 3 4)»
say ^∞ .head(5); # OUTPUT: «(0 1 2 3 4)»
say ^10 .head; # OUTPUT: «0»
say ^∞ .head; # OUTPUT: «0»
```
In the first two cases, the results are different since there's no defined order in [`Mix`](/type/Mix)es. In the other cases, it returns a [`Seq`](/type/Seq). A [`Callable`](/type/Callable) can be used to return all but the last elements:
```raku
say (^10).head( * - 3 );# OUTPUT: «(0 1 2 3 4 5 6)»
```
As of release 2022.07 of the Rakudo compiler, there is also a "sub" version of `head`.
```raku
multi head(\specifier, +values)
```
It **must** have the head specifier as the first argument. The rest of the arguments are turned into a [`Seq`](/type/Seq) and then have the `head` method called on it.
# [In Supply](#___top "go to top of document")[§](#(Supply)_method_head "direct link")
See primary documentation
[in context](/type/Supply#method_head)
for **method head**.
```raku
multi method head(Supply:D:)
multi method head(Supply:D: Callable:D $limit)
multi method head(Supply:D: \limit)
```
Creates a "head" supply with the same semantics as [List.head](/type/List#method_head).
```raku
my $s = Supply.from-list(4, 10, 3, 2);
my $hs = $s.head(2);
$hs.tap(&say); # OUTPUT: «410»
```
Since release 2020.07, A [`WhateverCode`](/type/WhateverCode) can be used also, again with the same semantics as `List.head`
```raku
my $s = Supply.from-list(4, 10, 3, 2, 1);
my $hs = $s.head( * - 2);
$hs.tap(&say); # OUTPUT: «4103»
```
|
## typeobject.md
class X::Does::TypeObject
Error due to mixing into a type object
```raku
class X::Does::TypeObject is Exception {}
```
When you try to add one or more roles to a type object with `does` after it has been composed, an error of type `X::Does::TypeObject` is thrown:
```raku
Mu does Numeric; # Cannot use 'does' operator with a type object.
```
The correct way to apply roles to a type is at declaration time:
```raku
class GrassmannNumber does Numeric { ... };
role AlgebraDebugger does IO { ... };
grammar IntegralParser does AlgebraParser { ... };
```
Roles may only be runtime-mixed into defined object instances:
```raku
GrassmannNumber.new does AlgebraDebugger;
```
(This restriction may be worked around by using [augment or supersede](/language/variables#The_augment_declarator), or with dark Metamodel magics, but this will likely result in a significant performance penalty.)
# [Methods](#class_X::Does::TypeObject "go to top of document")[§](#Methods "direct link")
## [method type](#class_X::Does::TypeObject "go to top of document")[§](#method_type "direct link")
```raku
method type(X::Does::TypeObject:D: --> Mu:U)
```
Returns the type object into which the code tried to mix in a role.
|
## dist_zef-gugod-RSV.md
```
This is an implementation of RSV decoder + encodder.
For the details of RSV, see:: https://github.com/Stenway/RSV-Specification
```
|
## numeric.md
Numeric
Combined from primary sources listed below.
# [In List](#___top "go to top of document")[§](#(List)_method_Numeric "direct link")
See primary documentation
[in context](/type/List#method_Numeric)
for **method Numeric**.
```raku
method Numeric(List:D: --> Int:D)
```
Returns the number of elements in the list (same as `.elems`).
```raku
say (1,2,3,4,5).Numeric; # OUTPUT: «5»
```
# [In role Sequence](#___top "go to top of document")[§](#(role_Sequence)_method_Numeric "direct link")
See primary documentation
[in context](/type/Sequence#method_Numeric)
for **method Numeric**.
```raku
method Numeric(::?CLASS:D:)
```
Returns the number of elements in the [cached](/type/PositionalBindFailover#method_cache) sequence.
# [In Capture](#___top "go to top of document")[§](#(Capture)_method_Numeric "direct link")
See primary documentation
[in context](/type/Capture#method_Numeric)
for **method Numeric**.
```raku
method Numeric(Capture:D: --> Int:D)
```
Returns the number of positional elements in the `Capture`.
```raku
say \(1,2,3, apples => 2).Numeric; # OUTPUT: «3»
```
# [In enum Bool](#___top "go to top of document")[§](#(enum_Bool)_routine_Numeric "direct link")
See primary documentation
[in context](/type/Bool#routine_Numeric)
for **routine Numeric**.
```raku
multi method Numeric(Bool:D --> Int:D)
```
Returns the value part of the `enum` pair.
```raku
say False.Numeric; # OUTPUT: «0»
say True.Numeric; # OUTPUT: «1»
```
# [In X::AdHoc](#___top "go to top of document")[§](#(X::AdHoc)_method_Numeric "direct link")
See primary documentation
[in context](/type/X/AdHoc#method_Numeric)
for **method Numeric**.
```raku
method Numeric()
```
Converts the payload to [`Numeric`](/type/Numeric) and returns it
# [In IntStr](#___top "go to top of document")[§](#(IntStr)_method_Numeric "direct link")
See primary documentation
[in context](/type/IntStr#method_Numeric)
for **method Numeric**.
```raku
multi method Numeric(IntStr:D: --> Int:D)
multi method Numeric(IntStr:U: --> Int:D)
```
The `:D` variant returns the numeric portion of the invocant. The `:U` variant issues a warning about using an uninitialized value in numeric context and then returns value `0`.
# [In Str](#___top "go to top of document")[§](#(Str)_method_Numeric "direct link")
See primary documentation
[in context](/type/Str#method_Numeric)
for **method Numeric**.
```raku
method Numeric(Str:D: --> Numeric:D)
```
Coerces the string to [`Numeric`](/type/Numeric) using semantics equivalent to [val](/routine/val) routine. [Fails](/routine/fail) with [`X::Str::Numeric`](/type/X/Str/Numeric) if the coercion to a number cannot be done.
Only Unicode characters with property `Nd`, as well as leading and trailing whitespace are allowed, with the special case of the empty string being coerced to `0`. Synthetic codepoints (e.g. `"7\x[308]"`) are forbidden.
While `Nl` and `No` characters can be used as numeric literals in the language, their conversion via `Str.Numeric` will fail, by design; the same will happen with synthetic numerics (composed of numbers and diacritic marks). See [unival](/routine/unival) if you need to coerce such characters to [`Numeric`](/type/Numeric). +, - and the Unicode MINUS SIGN − are all allowed.
```raku
" −33".Numeric; # OUTPUT: «-33»
```
# [In role Enumeration](#___top "go to top of document")[§](#(role_Enumeration)_method_Numeric "direct link")
See primary documentation
[in context](/type/Enumeration#method_Numeric)
for **method Numeric**.
```raku
multi method Numeric(::?CLASS:D:)
```
Takes a value of an enum and returns it after coercion to [`Numeric`](/type/Numeric):
```raku
enum Numbers ( cool => '42', almost-pi => '3.14', sqrt-n-one => 'i' );
say cool.Numeric; # OUTPUT: «42»
say almost-pi.Numeric; # OUTPUT: «3.14»
say sqrt-n-one.Numeric; # OUTPUT: «0+1i»
```
Note that if the value cannot be coerced to [`Numeric`](/type/Numeric), an exception will be thrown.
# [In NumStr](#___top "go to top of document")[§](#(NumStr)_method_Numeric "direct link")
See primary documentation
[in context](/type/NumStr#method_Numeric)
for **method Numeric**.
```raku
multi method Numeric(NumStr:D: --> Num:D)
multi method Numeric(NumStr:U: --> Num:D)
```
The `:D` variant returns the numeric portion of the invocant. The `:U` variant issues a warning about using an uninitialized value in numeric context and then returns value `0e0`.
# [In StrDistance](#___top "go to top of document")[§](#(StrDistance)_method_Numeric "direct link")
See primary documentation
[in context](/type/StrDistance#method_Numeric)
for **method Numeric**.
Returns the distance as a number.
# [In Map](#___top "go to top of document")[§](#(Map)_method_Numeric "direct link")
See primary documentation
[in context](/type/Map#method_Numeric)
for **method Numeric**.
```raku
method Numeric(Map:D: --> Int:D)
```
Returns the number of pairs stored in the `Map` (same as `.elems`).
```raku
my $m = Map.new('a' => 2, 'b' => 17);
say $m.Numeric; # OUTPUT: «2»
```
# [In Nil](#___top "go to top of document")[§](#(Nil)_method_Numeric "direct link")
See primary documentation
[in context](/type/Nil#method_Numeric)
for **method Numeric**.
```raku
method Numeric()
```
Warns the user that they tried to numify a `Nil`.
# [In enum Endian](#___top "go to top of document")[§](#(enum_Endian)_routine_Numeric "direct link")
See primary documentation
[in context](/type/Endian#routine_Numeric)
for **routine Numeric**.
```raku
multi method Numeric(Endian:D --> Int:D)
```
Returns the value part of the `enum` pair.
```raku
say NativeEndian.Numeric; # OUTPUT: «0»
say LittleEndian.Numeric; # OUTPUT: «1»
say BigEndian.Numeric; # OUTPUT: «2»
```
Note that the actual numeric values are subject to change. So please use the named values instead.
# [In IO::Path](#___top "go to top of document")[§](#(IO::Path)_method_Numeric "direct link")
See primary documentation
[in context](/type/IO/Path#method_Numeric)
for **method Numeric**.
```raku
method Numeric(IO::Path:D: --> Numeric:D)
```
Coerces [`.basename`](/routine/basename) to [`Numeric`](/type/Numeric). [Fails](/routine/fail) with [`X::Str::Numeric`](/type/X/Str/Numeric) if base name is not numerical.
# [In Thread](#___top "go to top of document")[§](#(Thread)_method_Numeric "direct link")
See primary documentation
[in context](/type/Thread#method_Numeric)
for **method Numeric**.
```raku
method Numeric(Thread:D: --> Int:D)
```
Returns a numeric, unique thread identifier, i.e. the same as [id](#method_id).
# [In role Numeric](#___top "go to top of document")[§](#(role_Numeric)_method_Numeric "direct link")
See primary documentation
[in context](/type/Numeric#method_Numeric)
for **method Numeric**.
```raku
multi method Numeric(Numeric:D: --> Numeric:D)
multi method Numeric(Numeric:U: --> Numeric:D)
```
The `:D` variant simply returns the invocant. The `:U` variant issues a warning about using an uninitialized value in numeric context and then returns `self.new`.
# [In DateTime](#___top "go to top of document")[§](#(DateTime)_method_Numeric "direct link")
See primary documentation
[in context](/type/DateTime#method_Numeric)
for **method Numeric**.
```raku
multi method Numeric(DateTime:D: --> Instant:D)
```
Available as of the 2021.09 release of the Rakudo compiler.
Converts the invocant to [`Instant`](/type/Instant). The same value can be obtained with the [`Instant`](/type/Instant) method. This allows `DateTime` objects to be used directly in arithmetic operations.
# [In ComplexStr](#___top "go to top of document")[§](#(ComplexStr)_method_Numeric "direct link")
See primary documentation
[in context](/type/ComplexStr#method_Numeric)
for **method Numeric**.
```raku
multi method Numeric(ComplexStr:D: --> Complex:D)
multi method Numeric(ComplexStr:U: --> Complex:D)
```
The `:D` variant returns the numeric portion of the invocant. The `:U` variant issues a warning about using an uninitialized value in numeric context and then returns value `<0+0i>`.
# [In RatStr](#___top "go to top of document")[§](#(RatStr)_method_Numeric "direct link")
See primary documentation
[in context](/type/RatStr#method_Numeric)
for **method Numeric**.
```raku
multi method Numeric(RatStr:D: --> Rat:D)
multi method Numeric(RatStr:U: --> Rat:D)
```
The `:D` variant returns the numeric portion of the invocant. The `:U` variant issues a warning about using an uninitialized value in numeric context and then returns value `0.0`.
# [In Date](#___top "go to top of document")[§](#(Date)_method_Numeric "direct link")
See primary documentation
[in context](/type/Date#method_Numeric)
for **method Numeric**.
```raku
multi method Numeric(Date:D: --> Int:D)
```
Converts the invocant to [`Int`](/type/Int). The same value can be obtained with the `daycount` method. This allows `Date` objects to be used directly in arithmetic operations.
Available as of release 2023.02 of the Rakudo compiler.
|
End of preview. Expand
in Data Studio
Raku Docs
About the Dataset
This dataset is the raku.org docs + raku.land project READMEs
License
Licenses are included in most of the project docs.
For the Raku docs themselves, the license is Artistic-2.0 license.
Unfortunately, some projects included in this dataset do not clearly specify a license.
I make no claim to authorship over any of this data.
Format
The dataset is formatted for continued pre-training.
Chunks are split at a seq_len of 8192 based on the Qwen 3 tokenizer.
Goals
This dataset is part of a larger collection designed to teach LLMs to write a niche programming language. In this case, Raku (perl 6).
- Downloads last month
- 35