
SimpleStories Model Family
The SimpleStories models are a tiny model family created for interpretability research, trained on the SimpleStories dataset.
Usage
pip install simple_stories_train
from transformers import AutoTokenizer
import torch
from simple_stories_train.models.llama import Llama
from simple_stories_train.models.model_configs import MODEL_CONFIGS
# Select the model size you want to use
model_size = "35M" # Options: "35M", "30M", "11M", "5M", "1.25M"
# Load model configuration
model_config = MODEL_CONFIGS[model_size]
# Load appropriate model
model_path = f"SimpleStories/SimpleStories-{model_size}"
model = Llama.from_pretrained(model_path, model_config)
device = torch.device("cuda" if torch.cuda.is_available() else "mps" if torch.backends.mps.is_available() else "cpu")
model.to(device)
model.eval()
# Load tokenizer
tokenizer = AutoTokenizer.from_pretrained(model_path)
# Define your prompt
prompt = "The curious cat looked at the"
inputs = tokenizer(prompt, return_tensors="pt")
input_ids = inputs.input_ids.to(device)
# Generate text
with torch.no_grad():
output_ids = model.generate(
idx=input_ids,
max_new_tokens=50,
temperature=0.0,
top_k=40,
eos_token_id=tokenizer.eos_token_id
)
# Decode output
output_text = tokenizer.decode(output_ids[0], skip_special_tokens=True)
print(f"Generated text:\n{output_text}")
Model Variants
| Model Name | n_params | n_layers | d_model | n_heads | n_ctx | d_vocab |
|---|---|---|---|---|---|---|
| SimpleStories-35M | 35 million | 12 | 512 | 8 | 512 | 4096 |
| SimpleStories-30M | 30 million | 10 | 512 | 8 | 512 | 4096 |
| SimpleStories-11M | 11 million | 6 | 384 | 6 | 512 | 4096 |
| SimpleStories-5M | 5 million | 6 | 256 | 4 | 512 | 4096 |
| SimpleStories-1.25M | 1.25 million | 4 | 128 | 4 | 512 | 4096 |
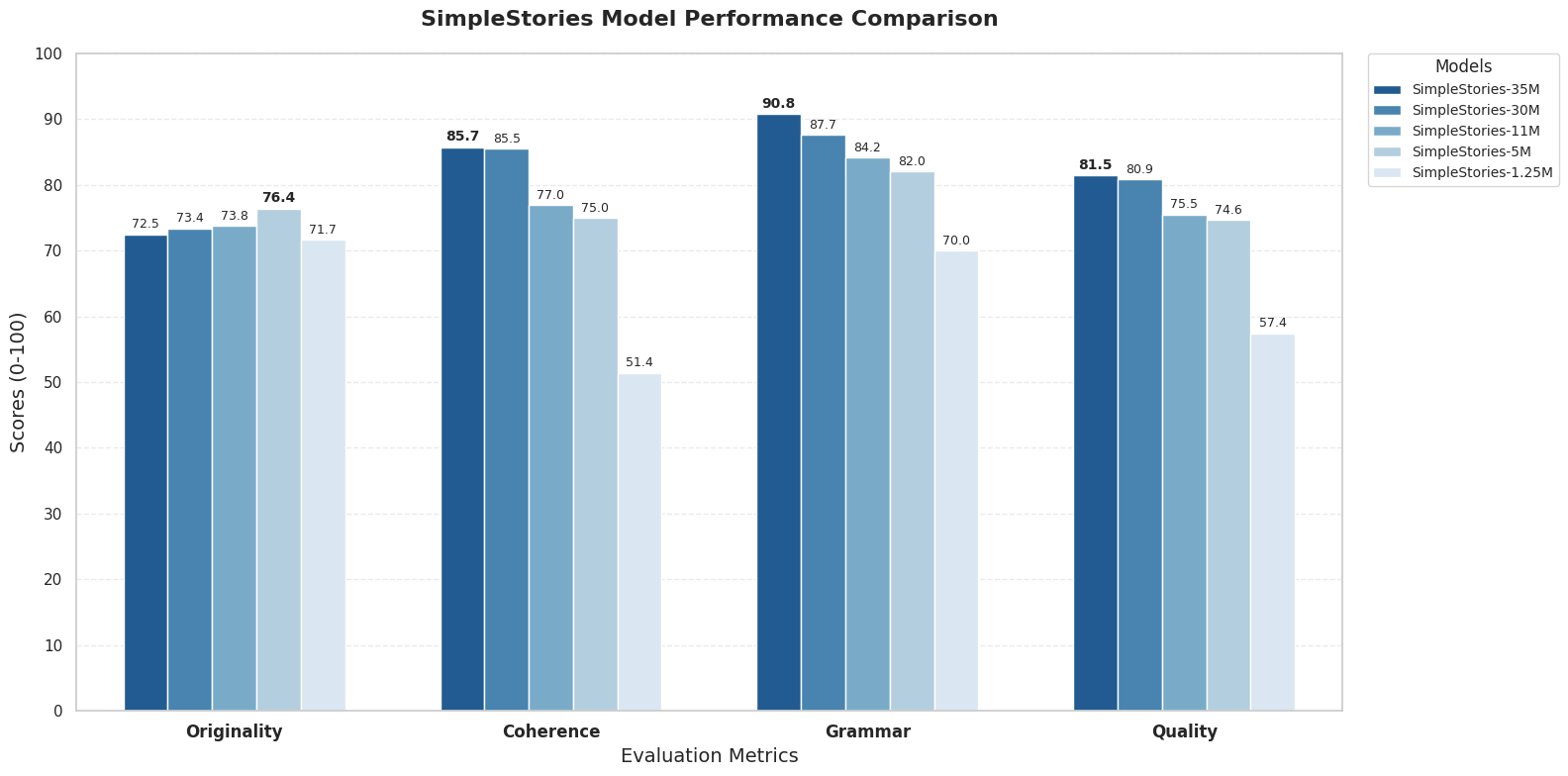
Performance Comparison
Model-evaluated generation quality metrics:
Tokenizer
We use a custom WordPiece tokenizer with a small vocabulary size of 4096. We conducted morphological analysis and coverage gain analysis on the dataset to build a small tokenizer without compromising on the quality of generation.
Dataset
The SimpleStories dataset is a collection of short stories generated by state-of-the-art language models. It features:
- Story annotation with high-level concepts: theme, topic, style, etc.
- Higher semantic and syntactic diversity through seeded story generation
- Generated by 2024 models
- Several NLP-metrics pre-computed to aid filtering
- ASCII-only guarantee for the English dataset
Read the dataset paper on arXiv.
- Downloads last month
- 4
Inference Providers
NEW
This model isn't deployed by any Inference Provider.
🙋
Ask for provider support
HF Inference deployability: The model has no library tag.