

Update README.md
Browse files
README.md
CHANGED
|
@@ -32,7 +32,6 @@ tags:
|
|
| 32 |
</div>
|
| 33 |
<h1 style="margin-top: 0rem;">✨ Run & Fine-tune Qwen3 with Unsloth!</h1>
|
| 34 |
</div>
|
| 35 |
-
|
| 36 |
- Fine-tune Qwen3 (14B) for free using our Google [Colab notebook here](https://docs.unsloth.ai/get-started/unsloth-notebooks)!
|
| 37 |
- Read our Blog about Qwen3 support: [unsloth.ai/blog/qwen3](https://unsloth.ai/blog/qwen3)
|
| 38 |
- View the rest of our notebooks in our [docs here](https://docs.unsloth.ai/get-started/unsloth-notebooks).
|
|
@@ -46,7 +45,6 @@ tags:
|
|
| 46 |
| **Llama-3.2 (11B vision)** | [▶️ Start on Colab](https://colab.research.google.com/github/unslothai/notebooks/blob/main/nb/Llama3.2_(11B)-Vision.ipynb) | 2x faster | 60% less |
|
| 47 |
| **Qwen2.5 (7B)** | [▶️ Start on Colab](https://colab.research.google.com/github/unslothai/notebooks/blob/main/nb/Qwen2.5_(7B)-Alpaca.ipynb) | 2x faster | 60% less |
|
| 48 |
|
| 49 |
-
|
| 50 |
# Qwen3-30B-A3B-Instruct-2507
|
| 51 |
<a href="https://chat.qwen.ai/" target="_blank" style="margin: 2px;">
|
| 52 |
<img alt="Chat" src="https://img.shields.io/badge/%F0%9F%92%9C%EF%B8%8F%20Qwen%20Chat%20-536af5" style="display: inline-block; vertical-align: middle;"/>
|
|
@@ -61,6 +59,8 @@ We introduce the updated version of the **Qwen3-30B-A3B non-thinking mode**, nam
|
|
| 61 |
- **Markedly better alignment** with user preferences in **subjective and open-ended tasks**, enabling more helpful responses and higher-quality text generation.
|
| 62 |
- **Enhanced capabilities** in **256K long-context understanding**.
|
| 63 |
|
|
|
|
|
|
|
| 64 |
## Model Overview
|
| 65 |
|
| 66 |
**Qwen3-30B-A3B-Instruct-2507** has the following features:
|
|
@@ -79,6 +79,47 @@ We introduce the updated version of the **Qwen3-30B-A3B non-thinking mode**, nam
|
|
| 79 |
For more details, including benchmark evaluation, hardware requirements, and inference performance, please refer to our [blog](https://qwenlm.github.io/blog/qwen3/), [GitHub](https://github.com/QwenLM/Qwen3), and [Documentation](https://qwen.readthedocs.io/en/latest/).
|
| 80 |
|
| 81 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 82 |
## Quickstart
|
| 83 |
|
| 84 |
The code of Qwen3-MoE has been in the latest Hugging Face `transformers` and we advise you to use the latest version of `transformers`.
|
|
@@ -129,11 +170,11 @@ print("content:", content)
|
|
| 129 |
For deployment, you can use `sglang>=0.4.6.post1` or `vllm>=0.8.5` or to create an OpenAI-compatible API endpoint:
|
| 130 |
- SGLang:
|
| 131 |
```shell
|
| 132 |
-
python -m sglang.launch_server --model-path Qwen/Qwen3-30B-A3B-Instruct-2507 --
|
| 133 |
```
|
| 134 |
- vLLM:
|
| 135 |
```shell
|
| 136 |
-
vllm serve Qwen/Qwen3-30B-A3B-Instruct-2507 --
|
| 137 |
```
|
| 138 |
|
| 139 |
**Note: If you encounter out-of-memory (OOM) issues, consider reducing the context length to a shorter value, such as `32,768`.**
|
|
@@ -211,4 +252,4 @@ If you find our work helpful, feel free to give us a cite.
|
|
| 211 |
primaryClass={cs.CL},
|
| 212 |
url={https://arxiv.org/abs/2505.09388},
|
| 213 |
}
|
| 214 |
-
```
|
|
|
|
| 32 |
</div>
|
| 33 |
<h1 style="margin-top: 0rem;">✨ Run & Fine-tune Qwen3 with Unsloth!</h1>
|
| 34 |
</div>
|
|
|
|
| 35 |
- Fine-tune Qwen3 (14B) for free using our Google [Colab notebook here](https://docs.unsloth.ai/get-started/unsloth-notebooks)!
|
| 36 |
- Read our Blog about Qwen3 support: [unsloth.ai/blog/qwen3](https://unsloth.ai/blog/qwen3)
|
| 37 |
- View the rest of our notebooks in our [docs here](https://docs.unsloth.ai/get-started/unsloth-notebooks).
|
|
|
|
| 45 |
| **Llama-3.2 (11B vision)** | [▶️ Start on Colab](https://colab.research.google.com/github/unslothai/notebooks/blob/main/nb/Llama3.2_(11B)-Vision.ipynb) | 2x faster | 60% less |
|
| 46 |
| **Qwen2.5 (7B)** | [▶️ Start on Colab](https://colab.research.google.com/github/unslothai/notebooks/blob/main/nb/Qwen2.5_(7B)-Alpaca.ipynb) | 2x faster | 60% less |
|
| 47 |
|
|
|
|
| 48 |
# Qwen3-30B-A3B-Instruct-2507
|
| 49 |
<a href="https://chat.qwen.ai/" target="_blank" style="margin: 2px;">
|
| 50 |
<img alt="Chat" src="https://img.shields.io/badge/%F0%9F%92%9C%EF%B8%8F%20Qwen%20Chat%20-536af5" style="display: inline-block; vertical-align: middle;"/>
|
|
|
|
| 59 |
- **Markedly better alignment** with user preferences in **subjective and open-ended tasks**, enabling more helpful responses and higher-quality text generation.
|
| 60 |
- **Enhanced capabilities** in **256K long-context understanding**.
|
| 61 |
|
| 62 |
+
|
| 63 |
+
|
| 64 |
## Model Overview
|
| 65 |
|
| 66 |
**Qwen3-30B-A3B-Instruct-2507** has the following features:
|
|
|
|
| 79 |
For more details, including benchmark evaluation, hardware requirements, and inference performance, please refer to our [blog](https://qwenlm.github.io/blog/qwen3/), [GitHub](https://github.com/QwenLM/Qwen3), and [Documentation](https://qwen.readthedocs.io/en/latest/).
|
| 80 |
|
| 81 |
|
| 82 |
+
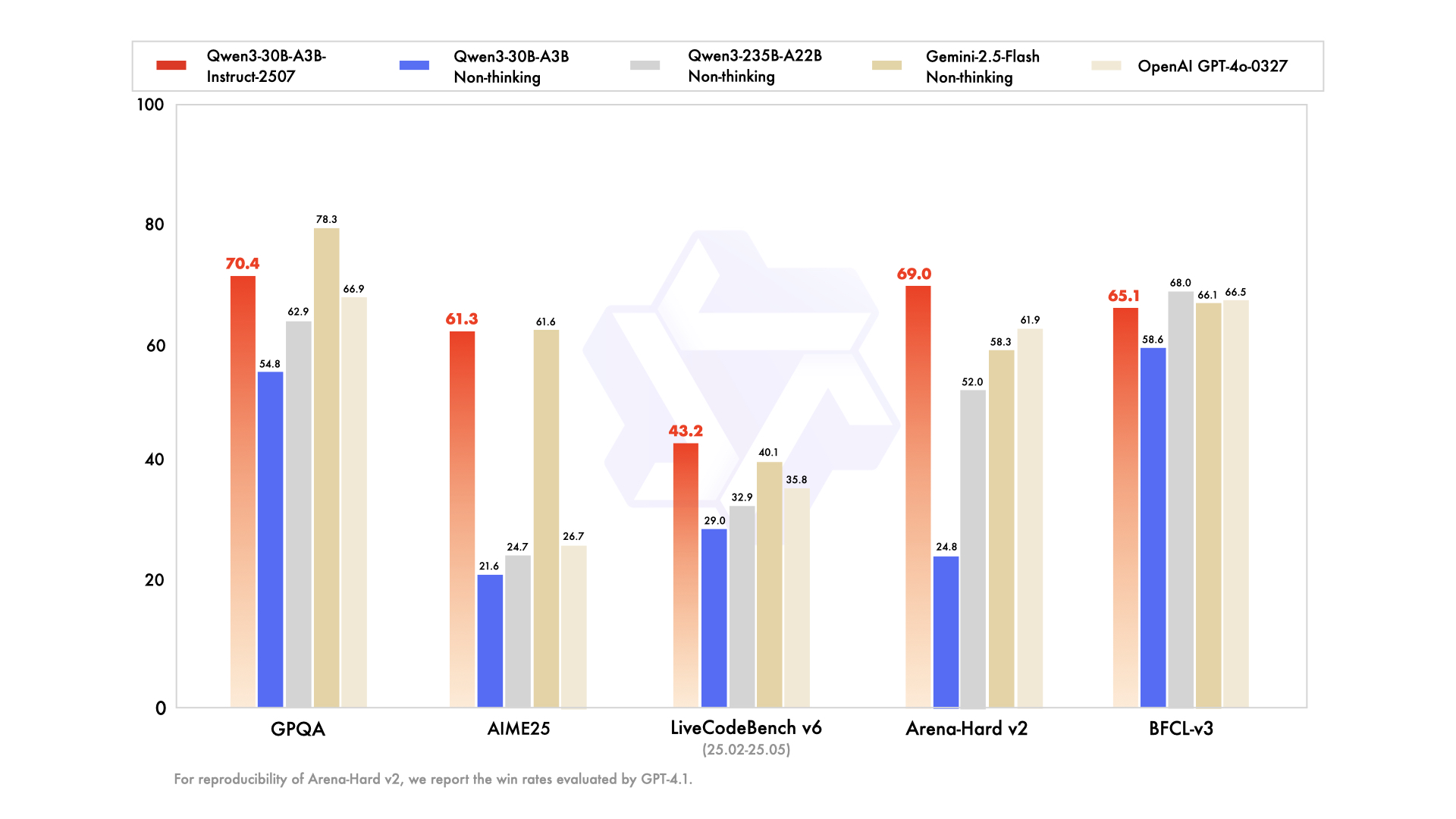
## Performance
|
| 83 |
+
|
| 84 |
+
| | Deepseek-V3-0324 | GPT-4o-0327 | Gemini-2.5-Flash Non-Thinking | Qwen3-235B-A22B Non-Thinking | Qwen3-30B-A3B Non-Thinking | Qwen3-30B-A3B-Instruct-2507 |
|
| 85 |
+
|--- | --- | --- | --- | --- | --- | --- |
|
| 86 |
+
| **Knowledge** | | | | | | |
|
| 87 |
+
| MMLU-Pro | **81.2** | 79.8 | 81.1 | 75.2 | 69.1 | 78.4 |
|
| 88 |
+
| MMLU-Redux | 90.4 | **91.3** | 90.6 | 89.2 | 84.1 | 89.3 |
|
| 89 |
+
| GPQA | 68.4 | 66.9 | **78.3** | 62.9 | 54.8 | 70.4 |
|
| 90 |
+
| SuperGPQA | **57.3** | 51.0 | 54.6 | 48.2 | 42.2 | 53.4 |
|
| 91 |
+
| **Reasoning** | | | | | | |
|
| 92 |
+
| AIME25 | 46.6 | 26.7 | **61.6** | 24.7 | 21.6 | 61.3 |
|
| 93 |
+
| HMMT25 | 27.5 | 7.9 | **45.8** | 10.0 | 12.0 | 43.0 |
|
| 94 |
+
| ZebraLogic | 83.4 | 52.6 | 57.9 | 37.7 | 33.2 | **90.0** |
|
| 95 |
+
| LiveBench 20241125 | 66.9 | 63.7 | **69.1** | 62.5 | 59.4 | 69.0 |
|
| 96 |
+
| **Coding** | | | | | | |
|
| 97 |
+
| LiveCodeBench v6 (25.02-25.05) | **45.2** | 35.8 | 40.1 | 32.9 | 29.0 | 43.2 |
|
| 98 |
+
| MultiPL-E | 82.2 | 82.7 | 77.7 | 79.3 | 74.6 | **83.8** |
|
| 99 |
+
| Aider-Polyglot | 55.1 | 45.3 | 44.0 | **59.6** | 24.4 | 35.6 |
|
| 100 |
+
| **Alignment** | | | | | | |
|
| 101 |
+
| IFEval | 82.3 | 83.9 | 84.3 | 83.2 | 83.7 | **84.7** |
|
| 102 |
+
| Arena-Hard v2* | 45.6 | 61.9 | 58.3 | 52.0 | 24.8 | **69.0** |
|
| 103 |
+
| Creative Writing v3 | 81.6 | 84.9 | 84.6 | 80.4 | 68.1 | **86.0** |
|
| 104 |
+
| WritingBench | 74.5 | 75.5 | 80.5 | 77.0 | 72.2 | **85.5** |
|
| 105 |
+
| **Agent** | | | | | | |
|
| 106 |
+
| BFCL-v3 | 64.7 | 66.5 | 66.1 | **68.0** | 58.6 | 65.1 |
|
| 107 |
+
| TAU1-Retail | 49.6 | 60.3# | **65.2** | 65.2 | 38.3 | 59.1 |
|
| 108 |
+
| TAU1-Airline | 32.0 | 42.8# | **48.0** | 32.0 | 18.0 | 40.0 |
|
| 109 |
+
| TAU2-Retail | **71.1** | 66.7# | 64.3 | 64.9 | 31.6 | 57.0 |
|
| 110 |
+
| TAU2-Airline | 36.0 | 42.0# | **42.5** | 36.0 | 18.0 | 38.0 |
|
| 111 |
+
| TAU2-Telecom | **34.0** | 29.8# | 16.9 | 24.6 | 18.4 | 12.3 |
|
| 112 |
+
| **Multilingualism** | | | | | | |
|
| 113 |
+
| MultiIF | 66.5 | 70.4 | 69.4 | 70.2 | **70.8** | 67.9 |
|
| 114 |
+
| MMLU-ProX | 75.8 | 76.2 | **78.3** | 73.2 | 65.1 | 72.0 |
|
| 115 |
+
| INCLUDE | 80.1 | 82.1 | **83.8** | 75.6 | 67.8 | 71.9 |
|
| 116 |
+
| PolyMATH | 32.2 | 25.5 | 41.9 | 27.0 | 23.3 | **43.1** |
|
| 117 |
+
|
| 118 |
+
*: For reproducibility, we report the win rates evaluated by GPT-4.1.
|
| 119 |
+
|
| 120 |
+
\#: Results were generated using GPT-4o-20241120, as access to the native function calling API of GPT-4o-0327 was unavailable.
|
| 121 |
+
|
| 122 |
+
|
| 123 |
## Quickstart
|
| 124 |
|
| 125 |
The code of Qwen3-MoE has been in the latest Hugging Face `transformers` and we advise you to use the latest version of `transformers`.
|
|
|
|
| 170 |
For deployment, you can use `sglang>=0.4.6.post1` or `vllm>=0.8.5` or to create an OpenAI-compatible API endpoint:
|
| 171 |
- SGLang:
|
| 172 |
```shell
|
| 173 |
+
python -m sglang.launch_server --model-path Qwen/Qwen3-30B-A3B-Instruct-2507 --context-length 262144
|
| 174 |
```
|
| 175 |
- vLLM:
|
| 176 |
```shell
|
| 177 |
+
vllm serve Qwen/Qwen3-30B-A3B-Instruct-2507 --max-model-len 262144
|
| 178 |
```
|
| 179 |
|
| 180 |
**Note: If you encounter out-of-memory (OOM) issues, consider reducing the context length to a shorter value, such as `32,768`.**
|
|
|
|
| 252 |
primaryClass={cs.CL},
|
| 253 |
url={https://arxiv.org/abs/2505.09388},
|
| 254 |
}
|
| 255 |
+
```
|