Spaces:
Runtime error

Runtime error
Upload folder using huggingface_hub
Browse filesThis view is limited to 50 files because it contains too many changes.
See raw diff
- .gitattributes +14 -0
- .gitignore +15 -0
- .gitmodules +10 -0
- ASR/FunASR.py +54 -0
- ASR/README.md +77 -0
- ASR/Whisper.py +129 -0
- ASR/__init__.py +4 -0
- ASR/requirements_funasr.txt +3 -0
- AutoDL部署.md +215 -0
- ChatTTS/.gitignore +163 -0
- ChatTTS/ChatTTS/__init__.py +1 -0
- ChatTTS/ChatTTS/core.py +200 -0
- ChatTTS/ChatTTS/experimental/llm.py +40 -0
- ChatTTS/ChatTTS/infer/api.py +125 -0
- ChatTTS/ChatTTS/model/dvae.py +155 -0
- ChatTTS/ChatTTS/model/gpt.py +265 -0
- ChatTTS/ChatTTS/utils/gpu_utils.py +23 -0
- ChatTTS/ChatTTS/utils/infer_utils.py +141 -0
- ChatTTS/ChatTTS/utils/io_utils.py +14 -0
- ChatTTS/LICENSE +407 -0
- ChatTTS/README.md +132 -0
- ChatTTS/README_CN.md +136 -0
- ChatTTS/example.ipynb +0 -0
- ChatTTS/requirements.txt +8 -0
- ChatTTS/webui.py +113 -0
- CosyVoice/.github/ISSUE_TEMPLATE/bug_report.md +38 -0
- CosyVoice/.github/ISSUE_TEMPLATE/feature_request.md +20 -0
- CosyVoice/.gitignore +49 -0
- CosyVoice/.gitmodules +3 -0
- CosyVoice/CODE_OF_CONDUCT.md +76 -0
- CosyVoice/FAQ.md +16 -0
- CosyVoice/LICENSE +201 -0
- CosyVoice/README.md +189 -0
- CosyVoice/asset/dingding.png +0 -0
- CosyVoice/cosyvoice/__init__.py +0 -0
- CosyVoice/cosyvoice/bin/inference.py +114 -0
- CosyVoice/cosyvoice/bin/train.py +136 -0
- CosyVoice/cosyvoice/cli/__init__.py +0 -0
- CosyVoice/cosyvoice/cli/cosyvoice.py +83 -0
- CosyVoice/cosyvoice/cli/frontend.py +168 -0
- CosyVoice/cosyvoice/cli/model.py +60 -0
- CosyVoice/cosyvoice/dataset/__init__.py +0 -0
- CosyVoice/cosyvoice/dataset/dataset.py +160 -0
- CosyVoice/cosyvoice/dataset/processor.py +369 -0
- CosyVoice/cosyvoice/flow/decoder.py +222 -0
- CosyVoice/cosyvoice/flow/flow.py +141 -0
- CosyVoice/cosyvoice/flow/flow_matching.py +138 -0
- CosyVoice/cosyvoice/flow/length_regulator.py +49 -0
- CosyVoice/cosyvoice/hifigan/f0_predictor.py +55 -0
- CosyVoice/cosyvoice/hifigan/generator.py +391 -0
.gitattributes
CHANGED
|
@@ -33,3 +33,17 @@ saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
| 36 |
+
Musetalk/data/video/man_musev.mp4 filter=lfs diff=lfs merge=lfs -text
|
| 37 |
+
Musetalk/data/video/monalisa_musev.mp4 filter=lfs diff=lfs merge=lfs -text
|
| 38 |
+
Musetalk/data/video/seaside4_musev.mp4 filter=lfs diff=lfs merge=lfs -text
|
| 39 |
+
Musetalk/data/video/sit_musev.mp4 filter=lfs diff=lfs merge=lfs -text
|
| 40 |
+
Musetalk/data/video/sun_musev.mp4 filter=lfs diff=lfs merge=lfs -text
|
| 41 |
+
Musetalk/data/video/yongen_musev.mp4 filter=lfs diff=lfs merge=lfs -text
|
| 42 |
+
examples/source_image/art_16.png filter=lfs diff=lfs merge=lfs -text
|
| 43 |
+
examples/source_image/art_17.png filter=lfs diff=lfs merge=lfs -text
|
| 44 |
+
examples/source_image/art_3.png filter=lfs diff=lfs merge=lfs -text
|
| 45 |
+
examples/source_image/art_4.png filter=lfs diff=lfs merge=lfs -text
|
| 46 |
+
examples/source_image/art_5.png filter=lfs diff=lfs merge=lfs -text
|
| 47 |
+
examples/source_image/art_8.png filter=lfs diff=lfs merge=lfs -text
|
| 48 |
+
examples/source_image/art_9.png filter=lfs diff=lfs merge=lfs -text
|
| 49 |
+
inputs/boy.png filter=lfs diff=lfs merge=lfs -text
|
.gitignore
ADDED
|
@@ -0,0 +1,15 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
.DS_Store
|
| 2 |
+
checkpoints/
|
| 3 |
+
gfpgan/
|
| 4 |
+
__pycache__/
|
| 5 |
+
*.pyc
|
| 6 |
+
Linly-AI
|
| 7 |
+
Qwen
|
| 8 |
+
checkpoints
|
| 9 |
+
temp
|
| 10 |
+
*.wav
|
| 11 |
+
*.vtt
|
| 12 |
+
*.srt
|
| 13 |
+
results/example_answer.mp4
|
| 14 |
+
request-Linly-api.py
|
| 15 |
+
results
|
.gitmodules
ADDED
|
@@ -0,0 +1,10 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
[submodule "MuseV"]
|
| 2 |
+
path = MuseV
|
| 3 |
+
url = https://github.com/TMElyralab/MuseV.git
|
| 4 |
+
|
| 5 |
+
[submodule "ChatTTS"]
|
| 6 |
+
path = ChatTTS
|
| 7 |
+
url = https://github.com/2noise/ChatTTS.git
|
| 8 |
+
[submodule "CosyVoice"]
|
| 9 |
+
path = CosyVoice
|
| 10 |
+
url = https://github.com/FunAudioLLM/CosyVoice.git
|
ASR/FunASR.py
ADDED
|
@@ -0,0 +1,54 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
'''
|
| 2 |
+
Reference: https://github.com/alibaba-damo-academy/FunASR
|
| 3 |
+
pip install funasr
|
| 4 |
+
pip install modelscope
|
| 5 |
+
pip install -U rotary_embedding_torch
|
| 6 |
+
'''
|
| 7 |
+
try:
|
| 8 |
+
from funasr import AutoModel
|
| 9 |
+
except:
|
| 10 |
+
print("如果想使用FunASR,请先安装funasr,若使用Whisper,请忽略此条信息")
|
| 11 |
+
import os
|
| 12 |
+
import sys
|
| 13 |
+
sys.path.append('./')
|
| 14 |
+
from src.cost_time import calculate_time
|
| 15 |
+
|
| 16 |
+
class FunASR:
|
| 17 |
+
def __init__(self) -> None:
|
| 18 |
+
# 定义模型的自定义路径
|
| 19 |
+
model_path = "FunASR/speech_seaco_paraformer_large_asr_nat-zh-cn-16k-common-vocab8404-pytorch"
|
| 20 |
+
vad_model_path = "FunASR/speech_fsmn_vad_zh-cn-16k-common-pytorch"
|
| 21 |
+
punc_model_path = "FunASR/punc_ct-transformer_zh-cn-common-vocab272727-pytorch"
|
| 22 |
+
|
| 23 |
+
# 检查文件是否存在于 FunASR 目录下
|
| 24 |
+
model_exists = os.path.exists(model_path)
|
| 25 |
+
vad_model_exists = os.path.exists(vad_model_path)
|
| 26 |
+
punc_model_exists = os.path.exists(punc_model_path)
|
| 27 |
+
# Modelscope AutoDownload
|
| 28 |
+
self.model = AutoModel(
|
| 29 |
+
model=model_path if model_exists else "paraformer-zh",
|
| 30 |
+
vad_model=vad_model_path if vad_model_exists else "fsmn-vad",
|
| 31 |
+
punc_model=punc_model_path if punc_model_exists else "ct-punc-c",
|
| 32 |
+
)
|
| 33 |
+
# 自定义路径
|
| 34 |
+
# self.model = AutoModel(model="FunASR/speech_seaco_paraformer_large_asr_nat-zh-cn-16k-common-vocab8404-pytorch", # model_revision="v2.0.4",
|
| 35 |
+
# vad_model="FunASR/speech_fsmn_vad_zh-cn-16k-common-pytorch", # vad_model_revision="v2.0.4",
|
| 36 |
+
# punc_model="FunASR/punc_ct-transformer_zh-cn-common-vocab272727-pytorch", # punc_model_revision="v2.0.4",
|
| 37 |
+
# # spk_model="cam++", spk_model_revision="v2.0.2",
|
| 38 |
+
# )
|
| 39 |
+
@calculate_time
|
| 40 |
+
def transcribe(self, audio_file):
|
| 41 |
+
res = self.model.generate(input=audio_file,
|
| 42 |
+
batch_size_s=300)
|
| 43 |
+
print(res)
|
| 44 |
+
return res[0]['text']
|
| 45 |
+
|
| 46 |
+
|
| 47 |
+
if __name__ == "__main__":
|
| 48 |
+
import os
|
| 49 |
+
# 创建ASR对象并进行语音识别
|
| 50 |
+
audio_file = "output.wav" # 音频文件路径
|
| 51 |
+
if not os.path.exists(audio_file):
|
| 52 |
+
os.system('edge-tts --text "hello" --write-media output.wav')
|
| 53 |
+
asr = FunASR()
|
| 54 |
+
print(asr.transcribe(audio_file))
|
ASR/README.md
ADDED
|
@@ -0,0 +1,77 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
## ASR 同数字人沟通的桥梁
|
| 2 |
+
|
| 3 |
+
### Whisper OpenAI
|
| 4 |
+
|
| 5 |
+
Whisper 是一个自动语音识别 (ASR) 系统,它使用从网络上收集的 680,000 小时多语言和多任务监督数据进行训练。使用如此庞大且多样化的数据集可以提高对口音、背景噪音和技术语言的鲁棒性。此外,它还支持多种语言的转录,以及将这些语言翻译成英语。
|
| 6 |
+
|
| 7 |
+
使用方法很简单,我们只要安装以下库,后续模型会自动下载
|
| 8 |
+
|
| 9 |
+
```bash
|
| 10 |
+
pip install -U openai-whisper
|
| 11 |
+
```
|
| 12 |
+
|
| 13 |
+
借鉴OpenAI的Whisper实现了ASR的语音识别,具体使用方法参考 [https://github.com/openai/whisper](https://github.com/openai/whisper)
|
| 14 |
+
|
| 15 |
+
```python
|
| 16 |
+
'''
|
| 17 |
+
https://github.com/openai/whisper
|
| 18 |
+
pip install -U openai-whisper
|
| 19 |
+
'''
|
| 20 |
+
import whisper
|
| 21 |
+
|
| 22 |
+
class WhisperASR:
|
| 23 |
+
def __init__(self, model_path):
|
| 24 |
+
self.LANGUAGES = {
|
| 25 |
+
"en": "english",
|
| 26 |
+
"zh": "chinese",
|
| 27 |
+
}
|
| 28 |
+
self.model = whisper.load_model(model_path)
|
| 29 |
+
|
| 30 |
+
def transcribe(self, audio_file):
|
| 31 |
+
result = self.model.transcribe(audio_file)
|
| 32 |
+
return result["text"]
|
| 33 |
+
```
|
| 34 |
+
|
| 35 |
+
|
| 36 |
+
|
| 37 |
+
### FunASR Alibaba
|
| 38 |
+
|
| 39 |
+
阿里的`FunASR`的语音识别效果也是相当不错,而且时间也是比whisper更快的,更能达到实时的效果,所以也将FunASR添加进去了,在ASR文件夹下的FunASR文件里可以进行体验,参考 [https://github.com/alibaba-damo-academy/FunASR](https://github.com/alibaba-damo-academy/FunASR)
|
| 40 |
+
|
| 41 |
+
需要注意的是,在第一次运行的时候,需要安装以下库。
|
| 42 |
+
|
| 43 |
+
```bash
|
| 44 |
+
pip install funasr
|
| 45 |
+
pip install modelscope
|
| 46 |
+
pip install -U rotary_embedding_torch
|
| 47 |
+
```
|
| 48 |
+
|
| 49 |
+
```python
|
| 50 |
+
'''
|
| 51 |
+
Reference: https://github.com/alibaba-damo-academy/FunASR
|
| 52 |
+
pip install funasr
|
| 53 |
+
pip install modelscope
|
| 54 |
+
pip install -U rotary_embedding_torch
|
| 55 |
+
'''
|
| 56 |
+
try:
|
| 57 |
+
from funasr import AutoModel
|
| 58 |
+
except:
|
| 59 |
+
print("如果想使用FunASR,请先安装funasr,若使用Whisper,请忽略此条信息")
|
| 60 |
+
|
| 61 |
+
class FunASR:
|
| 62 |
+
def __init__(self) -> None:
|
| 63 |
+
self.model = AutoModel(model="paraformer-zh", model_revision="v2.0.4",
|
| 64 |
+
vad_model="fsmn-vad", vad_model_revision="v2.0.4",
|
| 65 |
+
punc_model="ct-punc-c", punc_model_revision="v2.0.4",
|
| 66 |
+
# spk_model="cam++", spk_model_revision="v2.0.2",
|
| 67 |
+
)
|
| 68 |
+
|
| 69 |
+
def transcribe(self, audio_file):
|
| 70 |
+
res = self.model.generate(input=audio_file,
|
| 71 |
+
batch_size_s=300)
|
| 72 |
+
print(res)
|
| 73 |
+
return res[0]['text']
|
| 74 |
+
```
|
| 75 |
+
|
| 76 |
+
|
| 77 |
+
|
ASR/Whisper.py
ADDED
|
@@ -0,0 +1,129 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
'''
|
| 2 |
+
https://github.com/openai/whisper
|
| 3 |
+
pip install -U openai-whisper
|
| 4 |
+
'''
|
| 5 |
+
import whisper
|
| 6 |
+
import sys
|
| 7 |
+
sys.path.append('./')
|
| 8 |
+
from src.cost_time import calculate_time
|
| 9 |
+
|
| 10 |
+
class WhisperASR:
|
| 11 |
+
def __init__(self, model_path):
|
| 12 |
+
self.LANGUAGES = {
|
| 13 |
+
"en": "english",
|
| 14 |
+
"zh": "chinese",
|
| 15 |
+
"de": "german",
|
| 16 |
+
"es": "spanish",
|
| 17 |
+
"ru": "russian",
|
| 18 |
+
"ko": "korean",
|
| 19 |
+
"fr": "french",
|
| 20 |
+
"ja": "japanese",
|
| 21 |
+
"pt": "portuguese",
|
| 22 |
+
"tr": "turkish",
|
| 23 |
+
"pl": "polish",
|
| 24 |
+
"ca": "catalan",
|
| 25 |
+
"nl": "dutch",
|
| 26 |
+
"ar": "arabic",
|
| 27 |
+
"sv": "swedish",
|
| 28 |
+
"it": "italian",
|
| 29 |
+
"id": "indonesian",
|
| 30 |
+
"hi": "hindi",
|
| 31 |
+
"fi": "finnish",
|
| 32 |
+
"vi": "vietnamese",
|
| 33 |
+
"he": "hebrew",
|
| 34 |
+
"uk": "ukrainian",
|
| 35 |
+
"el": "greek",
|
| 36 |
+
"ms": "malay",
|
| 37 |
+
"cs": "czech",
|
| 38 |
+
"ro": "romanian",
|
| 39 |
+
"da": "danish",
|
| 40 |
+
"hu": "hungarian",
|
| 41 |
+
"ta": "tamil",
|
| 42 |
+
"no": "norwegian",
|
| 43 |
+
"th": "thai",
|
| 44 |
+
"ur": "urdu",
|
| 45 |
+
"hr": "croatian",
|
| 46 |
+
"bg": "bulgarian",
|
| 47 |
+
"lt": "lithuanian",
|
| 48 |
+
"la": "latin",
|
| 49 |
+
"mi": "maori",
|
| 50 |
+
"ml": "malayalam",
|
| 51 |
+
"cy": "welsh",
|
| 52 |
+
"sk": "slovak",
|
| 53 |
+
"te": "telugu",
|
| 54 |
+
"fa": "persian",
|
| 55 |
+
"lv": "latvian",
|
| 56 |
+
"bn": "bengali",
|
| 57 |
+
"sr": "serbian",
|
| 58 |
+
"az": "azerbaijani",
|
| 59 |
+
"sl": "slovenian",
|
| 60 |
+
"kn": "kannada",
|
| 61 |
+
"et": "estonian",
|
| 62 |
+
"mk": "macedonian",
|
| 63 |
+
"br": "breton",
|
| 64 |
+
"eu": "basque",
|
| 65 |
+
"is": "icelandic",
|
| 66 |
+
"hy": "armenian",
|
| 67 |
+
"ne": "nepali",
|
| 68 |
+
"mn": "mongolian",
|
| 69 |
+
"bs": "bosnian",
|
| 70 |
+
"kk": "kazakh",
|
| 71 |
+
"sq": "albanian",
|
| 72 |
+
"sw": "swahili",
|
| 73 |
+
"gl": "galician",
|
| 74 |
+
"mr": "marathi",
|
| 75 |
+
"pa": "punjabi",
|
| 76 |
+
"si": "sinhala",
|
| 77 |
+
"km": "khmer",
|
| 78 |
+
"sn": "shona",
|
| 79 |
+
"yo": "yoruba",
|
| 80 |
+
"so": "somali",
|
| 81 |
+
"af": "afrikaans",
|
| 82 |
+
"oc": "occitan",
|
| 83 |
+
"ka": "georgian",
|
| 84 |
+
"be": "belarusian",
|
| 85 |
+
"tg": "tajik",
|
| 86 |
+
"sd": "sindhi",
|
| 87 |
+
"gu": "gujarati",
|
| 88 |
+
"am": "amharic",
|
| 89 |
+
"yi": "yiddish",
|
| 90 |
+
"lo": "lao",
|
| 91 |
+
"uz": "uzbek",
|
| 92 |
+
"fo": "faroese",
|
| 93 |
+
"ht": "haitian creole",
|
| 94 |
+
"ps": "pashto",
|
| 95 |
+
"tk": "turkmen",
|
| 96 |
+
"nn": "nynorsk",
|
| 97 |
+
"mt": "maltese",
|
| 98 |
+
"sa": "sanskrit",
|
| 99 |
+
"lb": "luxembourgish",
|
| 100 |
+
"my": "myanmar",
|
| 101 |
+
"bo": "tibetan",
|
| 102 |
+
"tl": "tagalog",
|
| 103 |
+
"mg": "malagasy",
|
| 104 |
+
"as": "assamese",
|
| 105 |
+
"tt": "tatar",
|
| 106 |
+
"haw": "hawaiian",
|
| 107 |
+
"ln": "lingala",
|
| 108 |
+
"ha": "hausa",
|
| 109 |
+
"ba": "bashkir",
|
| 110 |
+
"jw": "javanese",
|
| 111 |
+
"su": "sundanese",
|
| 112 |
+
}
|
| 113 |
+
self.model = whisper.load_model(model_path)
|
| 114 |
+
|
| 115 |
+
@calculate_time
|
| 116 |
+
def transcribe(self, audio_file):
|
| 117 |
+
result = self.model.transcribe(audio_file)
|
| 118 |
+
return result["text"]
|
| 119 |
+
|
| 120 |
+
|
| 121 |
+
if __name__ == "__main__":
|
| 122 |
+
import os
|
| 123 |
+
# 创建ASR对象并进行语音识别
|
| 124 |
+
model_path = "./Whisper/tiny.pt" # 模型路径
|
| 125 |
+
audio_file = "output.wav" # 音频文件路径
|
| 126 |
+
if not os.path.exists(audio_file):
|
| 127 |
+
os.system('edge-tts --text "hello" --write-media output.wav')
|
| 128 |
+
asr = WhisperASR(model_path)
|
| 129 |
+
print(asr.transcribe(audio_file))
|
ASR/__init__.py
ADDED
|
@@ -0,0 +1,4 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from .Whisper import WhisperASR
|
| 2 |
+
from .FunASR import FunASR
|
| 3 |
+
|
| 4 |
+
__all__ = ['WhisperASR', 'FunASR']
|
ASR/requirements_funasr.txt
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
funasr
|
| 2 |
+
modelscope
|
| 3 |
+
# rotary_embedding_torch
|
AutoDL部署.md
ADDED
|
@@ -0,0 +1,215 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# 在AutoDL平台部署Linly-Talker (0基础小白超详细教程)
|
| 2 |
+
|
| 3 |
+
<!-- TOC -->
|
| 4 |
+
|
| 5 |
+
- [在AutoDL平台部署Linly-Talker 0基础小白超详细教程](#%E5%9C%A8autodl%E5%B9%B3%E5%8F%B0%E9%83%A8%E7%BD%B2linly-talker-0%E5%9F%BA%E7%A1%80%E5%B0%8F%E7%99%BD%E8%B6%85%E8%AF%A6%E7%BB%86%E6%95%99%E7%A8%8B)
|
| 6 |
+
- [快速上手直接使用镜像以下安装操作全免](#%E5%BF%AB%E9%80%9F%E4%B8%8A%E6%89%8B%E7%9B%B4%E6%8E%A5%E4%BD%BF%E7%94%A8%E9%95%9C%E5%83%8F%E4%BB%A5%E4%B8%8B%E5%AE%89%E8%A3%85%E6%93%8D%E4%BD%9C%E5%85%A8%E5%85%8D)
|
| 7 |
+
- [一、注册AutoDL](#%E4%B8%80%E6%B3%A8%E5%86%8Cautodl)
|
| 8 |
+
- [二、创建实例](#%E4%BA%8C%E5%88%9B%E5%BB%BA%E5%AE%9E%E4%BE%8B)
|
| 9 |
+
- [登录AutoDL,进入算力市场,选择机器](#%E7%99%BB%E5%BD%95autodl%E8%BF%9B%E5%85%A5%E7%AE%97%E5%8A%9B%E5%B8%82%E5%9C%BA%E9%80%89%E6%8B%A9%E6%9C%BA%E5%99%A8)
|
| 10 |
+
- [配置基础镜像](#%E9%85%8D%E7%BD%AE%E5%9F%BA%E7%A1%80%E9%95%9C%E5%83%8F)
|
| 11 |
+
- [无卡模式开机](#%E6%97%A0%E5%8D%A1%E6%A8%A1%E5%BC%8F%E5%BC%80%E6%9C%BA)
|
| 12 |
+
- [三、部署环境](#%E4%B8%89%E9%83%A8%E7%BD%B2%E7%8E%AF%E5%A2%83)
|
| 13 |
+
- [进入终端](#%E8%BF%9B%E5%85%A5%E7%BB%88%E7%AB%AF)
|
| 14 |
+
- [下载代码文件](#%E4%B8%8B%E8%BD%BD%E4%BB%A3%E7%A0%81%E6%96%87%E4%BB%B6)
|
| 15 |
+
- [下载模型文件](#%E4%B8%8B%E8%BD%BD%E6%A8%A1%E5%9E%8B%E6%96%87%E4%BB%B6)
|
| 16 |
+
- [四、Linly-Talker项目](#%E5%9B%9Blinly-talker%E9%A1%B9%E7%9B%AE)
|
| 17 |
+
- [环境安装](#%E7%8E%AF%E5%A2%83%E5%AE%89%E8%A3%85)
|
| 18 |
+
- [端口设置](#%E7%AB%AF%E5%8F%A3%E8%AE%BE%E7%BD%AE)
|
| 19 |
+
- [有卡开机](#%E6%9C%89%E5%8D%A1%E5%BC%80%E6%9C%BA)
|
| 20 |
+
- [运行网页版对话webui](#%E8%BF%90%E8%A1%8C%E7%BD%91%E9%A1%B5%E7%89%88%E5%AF%B9%E8%AF%9Dwebui)
|
| 21 |
+
- [端口映射](#%E7%AB%AF%E5%8F%A3%E6%98%A0%E5%B0%84)
|
| 22 |
+
- [体验Linly-Talker(成功)](#%E4%BD%93%E9%AA%8Clinly-talker%E6%88%90%E5%8A%9F)
|
| 23 |
+
|
| 24 |
+
<!-- /TOC -->
|
| 25 |
+
|
| 26 |
+
|
| 27 |
+
|
| 28 |
+
## 快速上手直接使用镜像(以下安装操作全免)
|
| 29 |
+
|
| 30 |
+
若使用我设定好的镜像,可以直接运行即可,不需要安装环境,直接运行webui.py或者是app_talk.py即可体验,不需要安装任何环境,可直接跳到4.4即可
|
| 31 |
+
|
| 32 |
+
访问后在自定义设置里面打开端口,默认是6006端口,直接使用运行即可!
|
| 33 |
+
|
| 34 |
+
```bash
|
| 35 |
+
python webui.py
|
| 36 |
+
python app_talk.py
|
| 37 |
+
```
|
| 38 |
+
|
| 39 |
+
环境模型都安装好了,直接使用即可,镜像地址在:[https://www.codewithgpu.com/i/Kedreamix/Linly-Talker/Kedreamix-Linly-Talker](https://www.codewithgpu.com/i/Kedreamix/Linly-Talker/Kedreamix-Linly-Talker),感谢大家的支持
|
| 40 |
+
|
| 41 |
+
|
| 42 |
+
|
| 43 |
+
## 一、注册AutoDL
|
| 44 |
+
|
| 45 |
+
[AutoDL官网](https://www.autodl.com/home) 注册账户好并充值,自己选择机器,我觉得如果正常跑一下,5元已经够了
|
| 46 |
+
|
| 47 |
+
|
| 48 |
+
|
| 49 |
+
## 二、创建实例
|
| 50 |
+
|
| 51 |
+
### 2.1 登录AutoDL,进入算力市场,选择机器
|
| 52 |
+
|
| 53 |
+
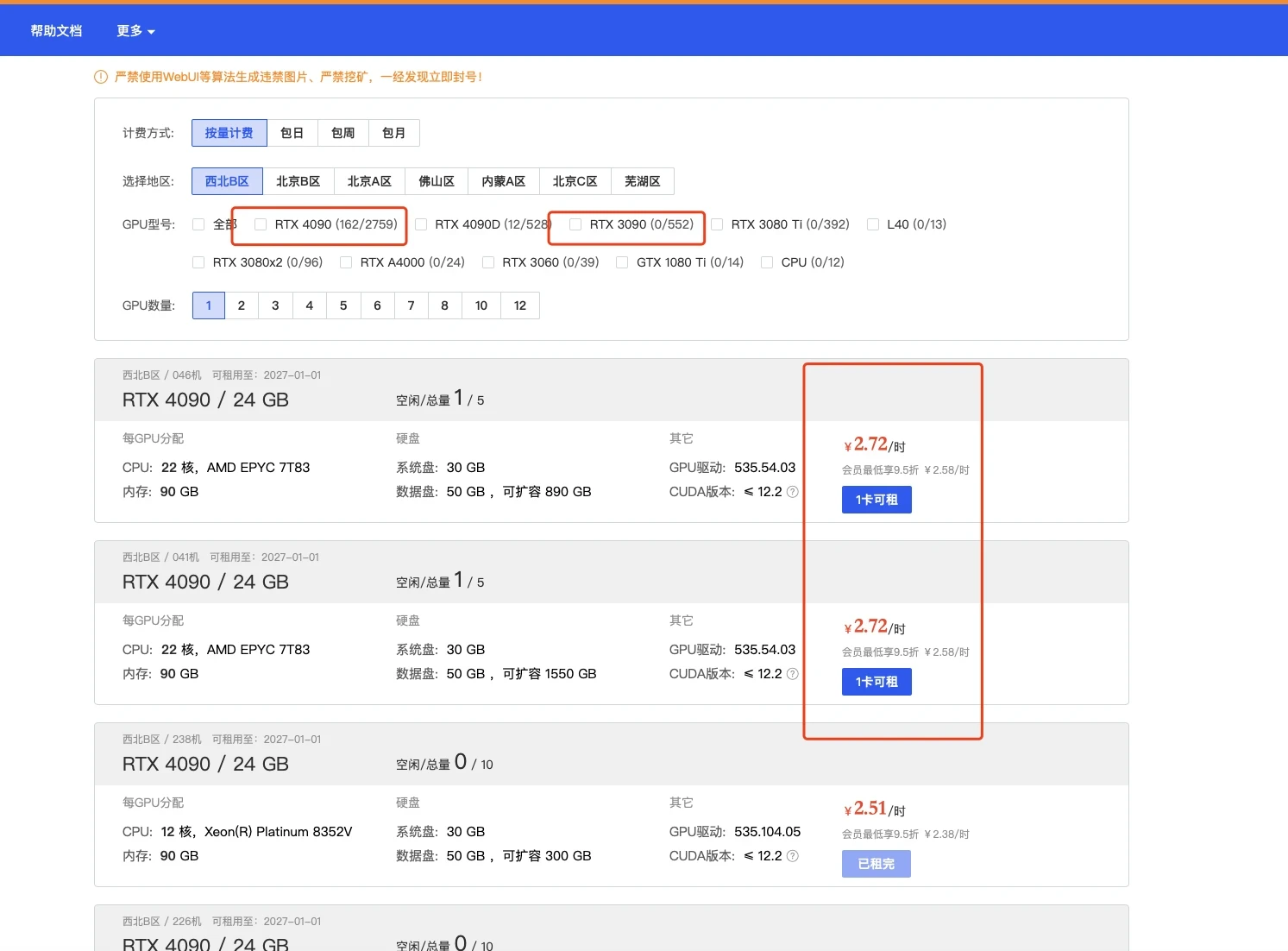
这一部分实际上我觉得12g都OK的,无非是速度问题而已
|
| 54 |
+
|
| 55 |
+
|
| 56 |
+
|
| 57 |
+
|
| 58 |
+
|
| 59 |
+
### 2.2 配置基础镜像
|
| 60 |
+
|
| 61 |
+
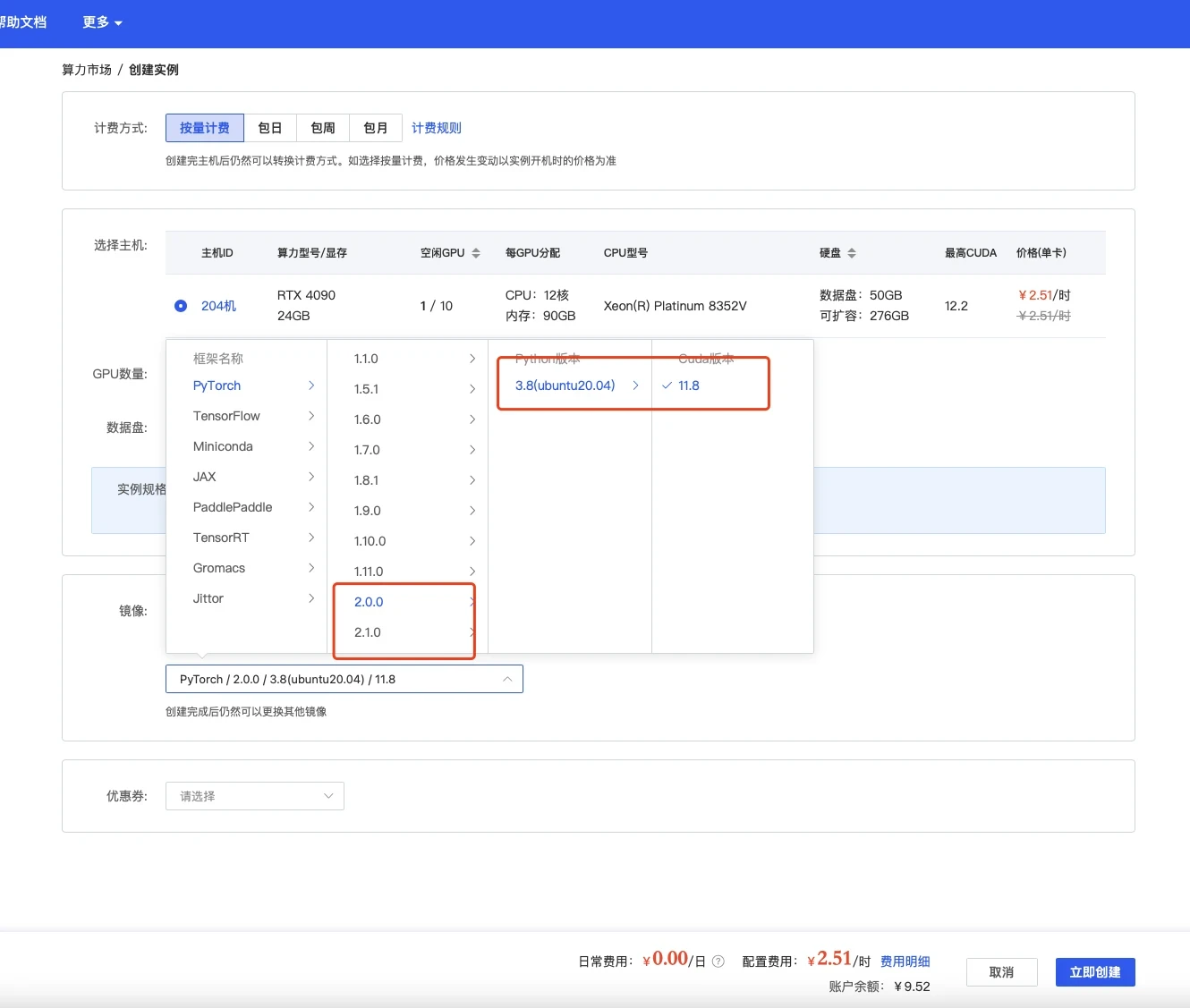
选择镜像,最好选择2.0以上可以体验克隆声音功能,其他无所谓
|
| 62 |
+
|
| 63 |
+
|
| 64 |
+
|
| 65 |
+
|
| 66 |
+
|
| 67 |
+
### 2.3 无卡模式开机
|
| 68 |
+
|
| 69 |
+
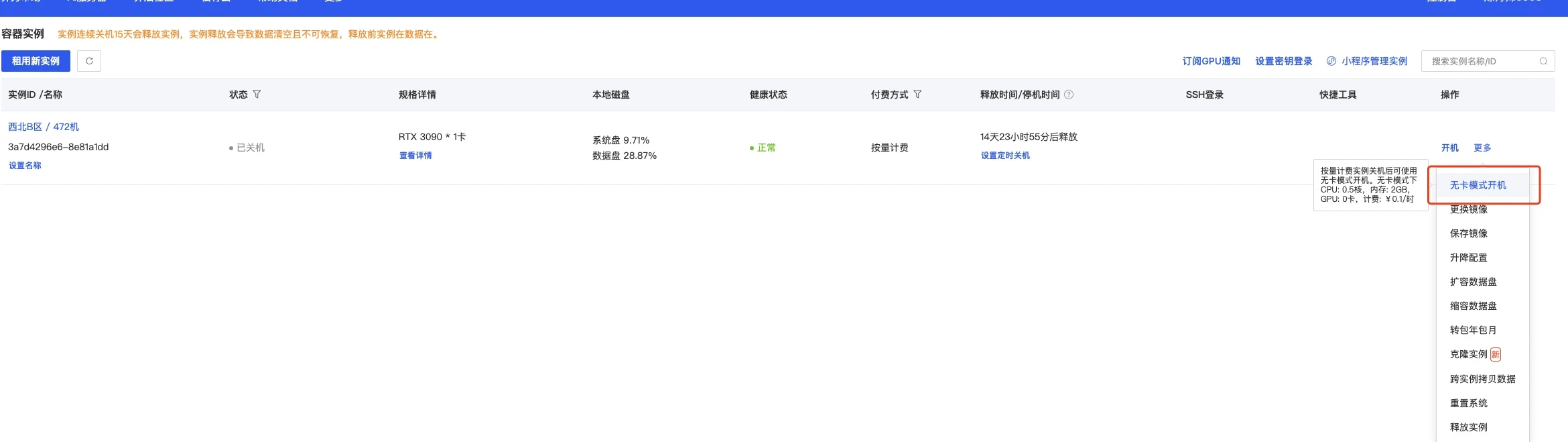
创建成功后为了省钱先关机,然后使用无卡模式开机。
|
| 70 |
+
无卡模式一个小时只需要0.1元,比较适合部署环境。
|
| 71 |
+
|
| 72 |
+
|
| 73 |
+
|
| 74 |
+
## 三、部署环境
|
| 75 |
+
|
| 76 |
+
### 3.1 进入终端
|
| 77 |
+
|
| 78 |
+
打开jupyterLab,进入数据盘(autodl-tmp),打开终端,将Linly-Talker模型下载到数据盘中。
|
| 79 |
+
|
| 80 |
+
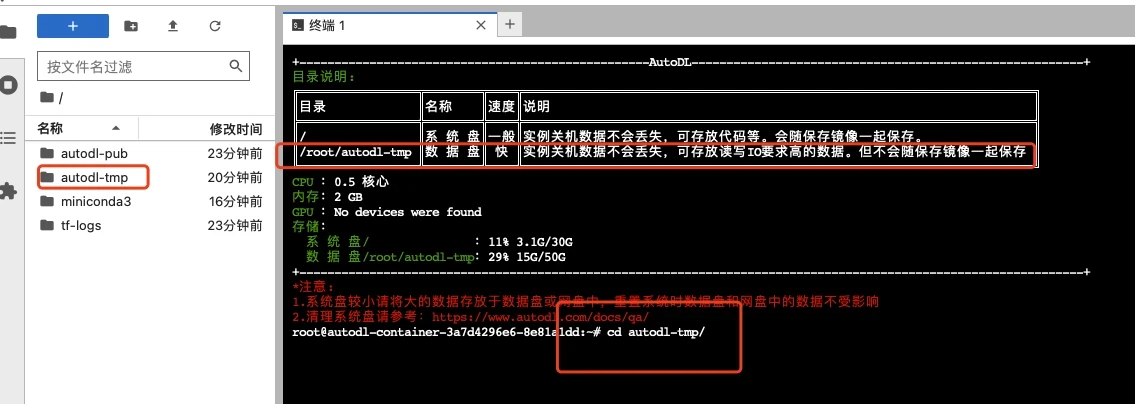
|
| 81 |
+
|
| 82 |
+
|
| 83 |
+
|
| 84 |
+
### 3.2 下载代码文件
|
| 85 |
+
|
| 86 |
+
根据Github上的说明,使用命令行下载模型文件和代码文件,利用学术加速会快一点
|
| 87 |
+
|
| 88 |
+
```bash
|
| 89 |
+
# 开启学术镜像,更快的clone代码 参考 https://www.autodl.com/docs/network_turbo/
|
| 90 |
+
source /etc/network_turbo
|
| 91 |
+
|
| 92 |
+
cd /root/autodl-tmp/
|
| 93 |
+
# 下载代码
|
| 94 |
+
git clone https://github.com/Kedreamix/Linly-Talker.git --depth 1
|
| 95 |
+
|
| 96 |
+
# 取消学术加速
|
| 97 |
+
unset http_proxy && unset https_proxy
|
| 98 |
+
```
|
| 99 |
+
|
| 100 |
+
|
| 101 |
+
|
| 102 |
+
### 3.3 下载模型文件
|
| 103 |
+
|
| 104 |
+
我制作一个脚本可以完成下述所有模型的下载,无需用户过多操作。这种方式适合网络稳定的情况,并且特别适合 Linux 用户。对于 Windows 用户,也可以使用 Git 来下载模型。如果网络环境不稳定,用户可以选择使用手动下载方法,或者尝试运行 Shell 脚本来完成下载。脚本具有以下功能。
|
| 105 |
+
|
| 106 |
+
1. **选择下载方式**: 用户可以选择从三种不同的源下载模型:ModelScope、Huggingface 或 Huggingface 镜像站点。
|
| 107 |
+
2. **下载模型**: 根据用户的选择,执行相应的下载命令。
|
| 108 |
+
3. **移动模型文件**: 下载完成后,将模型文件移动到指定的目录。
|
| 109 |
+
4. **错误处理**: 在每一步操作中加入了错误检查,如果操作失败,脚本会输出错误���息并停止执行。
|
| 110 |
+
|
| 111 |
+
选择使用`modelscope`来下载会快一点,不需要开学术加速,记得首先需要先安装modelscope库
|
| 112 |
+
|
| 113 |
+
```sh
|
| 114 |
+
# 下载modelscope
|
| 115 |
+
pip install modelscope -i https://pypi.tuna.tsinghua.edu.cn/simple
|
| 116 |
+
cd /root/autodl-tmp/Linly-Talker
|
| 117 |
+
sh scripts/download_models.sh
|
| 118 |
+
```
|
| 119 |
+
|
| 120 |
+
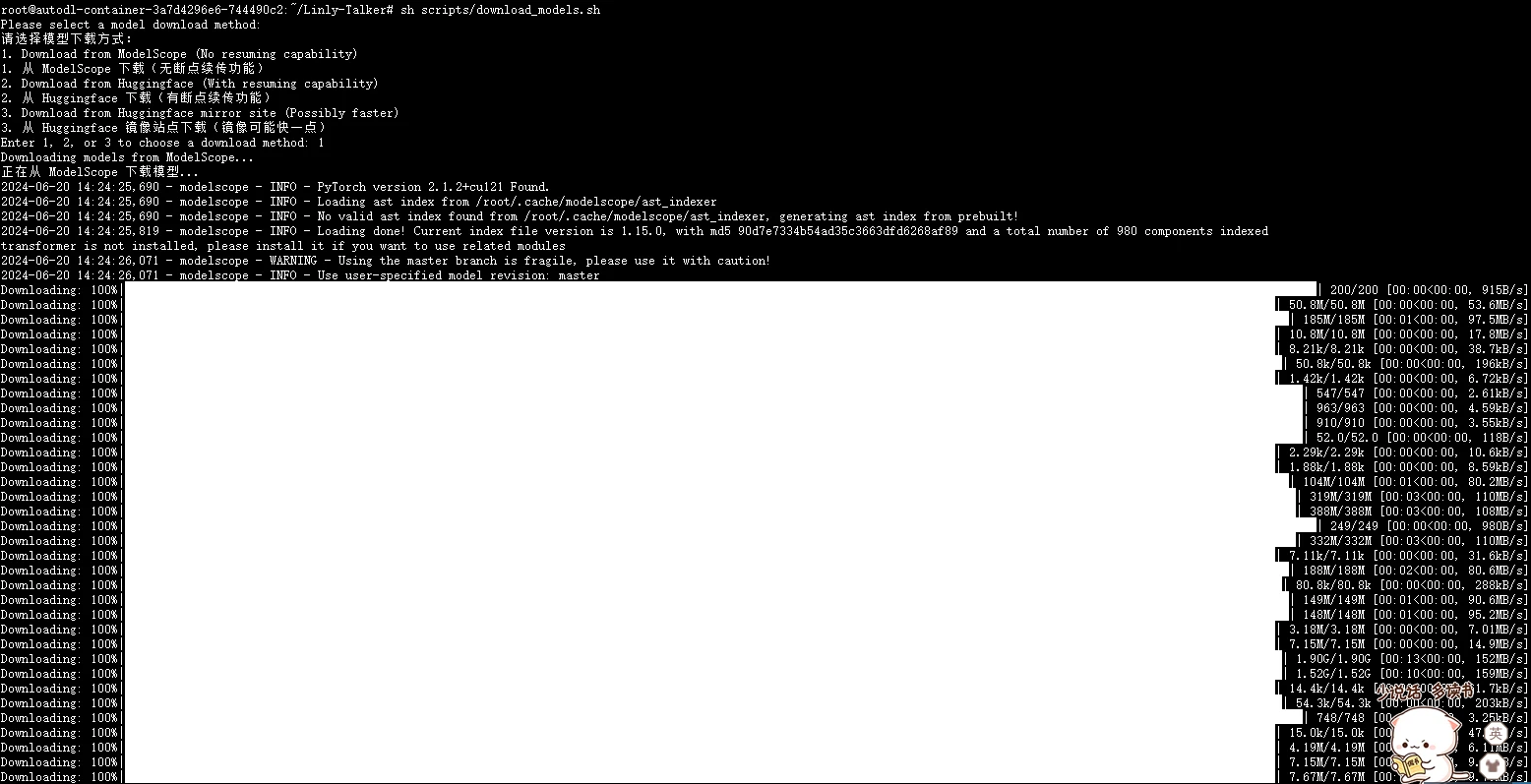
|
| 121 |
+
|
| 122 |
+
等待一段时间下载完以后,脚本会自动移动到对应的目录
|
| 123 |
+
|
| 124 |
+
|
| 125 |
+
|
| 126 |
+
## 四、Linly-Talker项目
|
| 127 |
+
|
| 128 |
+
### 4.1 环境安装
|
| 129 |
+
|
| 130 |
+
进入代码路径,进行安装环境,由于选了镜像是含有pytorch的,所以只需要进行安装其他依赖即可,可能需要花一定的时间,建议直接使用安装好的镜像
|
| 131 |
+
|
| 132 |
+
```bash
|
| 133 |
+
cd /root/autodl-tmp/Linly-Talker
|
| 134 |
+
|
| 135 |
+
conda install ffmpeg==4.2.2 # ffmpeg==4.2.2
|
| 136 |
+
|
| 137 |
+
# 升级pip
|
| 138 |
+
python -m pip install --upgrade pip
|
| 139 |
+
# 更换 pypi 源加速库的安装
|
| 140 |
+
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
|
| 141 |
+
|
| 142 |
+
pip install tb-nightly -i https://mirrors.aliyun.com/pypi/simple
|
| 143 |
+
pip install -r requirements_webui.txt
|
| 144 |
+
|
| 145 |
+
# 安装有关musetalk依赖
|
| 146 |
+
pip install --no-cache-dir -U openmim
|
| 147 |
+
mim install mmengine
|
| 148 |
+
mim install "mmcv>=2.0.1"
|
| 149 |
+
mim install "mmdet>=3.1.0"
|
| 150 |
+
mim install "mmpose>=1.1.0"
|
| 151 |
+
|
| 152 |
+
# 安装NeRF-based依赖,可能问题较多,可以先放弃
|
| 153 |
+
# 亲测需要有卡开机后再跑这个pytorch3d,需要一定的内存来编译
|
| 154 |
+
pip install "git+https://github.com/facebookresearch/pytorch3d.git"
|
| 155 |
+
|
| 156 |
+
# 若pyaudio出现问题,可安装对应依赖
|
| 157 |
+
sudo apt-get update
|
| 158 |
+
sudo apt-get install libasound-dev portaudio19-dev libportaudio2 libportaudiocpp0
|
| 159 |
+
pip install -r TFG/requirements_nerf.txt
|
| 160 |
+
```
|
| 161 |
+
|
| 162 |
+
|
| 163 |
+
|
| 164 |
+
### 4.2 有卡开机
|
| 165 |
+
|
| 166 |
+
进入autodl容器实例界面,执行关机操作,然后进行有卡开机,开机后打开jupyterLab。
|
| 167 |
+
|
| 168 |
+
查看配置
|
| 169 |
+
|
| 170 |
+
```bash
|
| 171 |
+
nvidia-smi
|
| 172 |
+
```
|
| 173 |
+
|
| 174 |
+
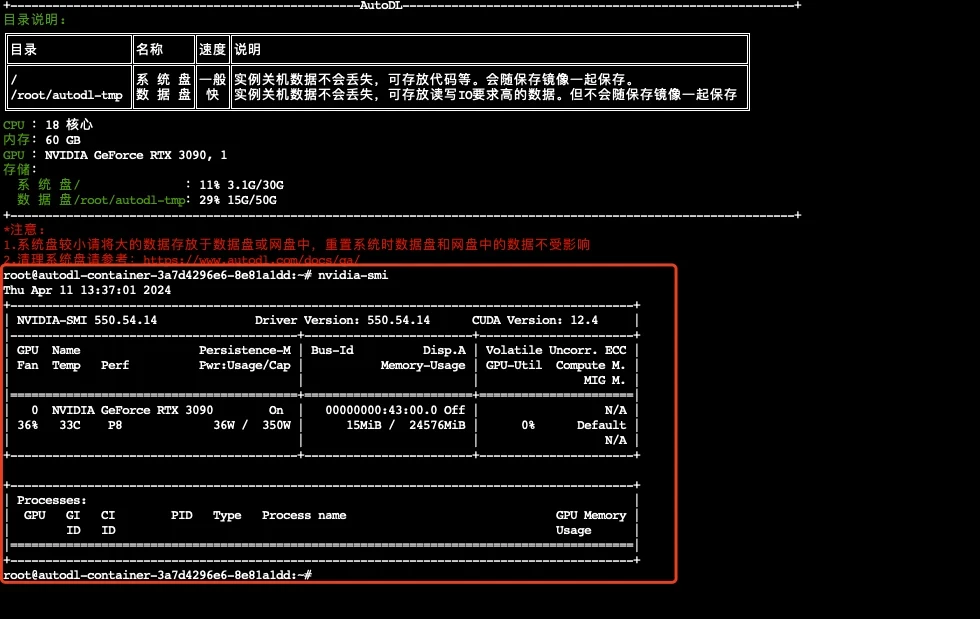
|
| 175 |
+
|
| 176 |
+
|
| 177 |
+
|
| 178 |
+
### 4.3 运行网页版对话webui
|
| 179 |
+
|
| 180 |
+
需要有卡模式开机,执行下边命令,这里面就跟代码是一模一样的了
|
| 181 |
+
|
| 182 |
+
```bash
|
| 183 |
+
cd /root/autodl-tmp/Linly-Talker
|
| 184 |
+
# 第一次运行可能会下载部分nltk,可以使用一下学术加速
|
| 185 |
+
source /etc/network_turbo
|
| 186 |
+
python webui.py
|
| 187 |
+
```
|
| 188 |
+
|
| 189 |
+
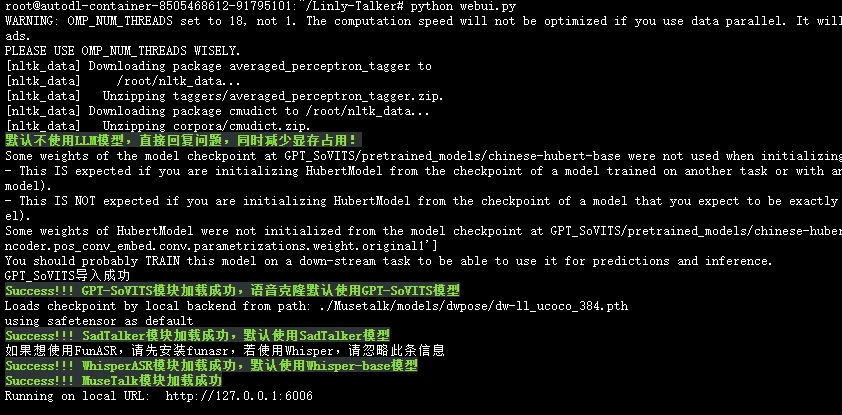
|
| 190 |
+
|
| 191 |
+
### 4.4 端口映射
|
| 192 |
+
|
| 193 |
+
这可以直接打开autodl的自定义服务,默认是6006端口,我们已经设置了,所以直接使用即可
|
| 194 |
+
|
| 195 |
+
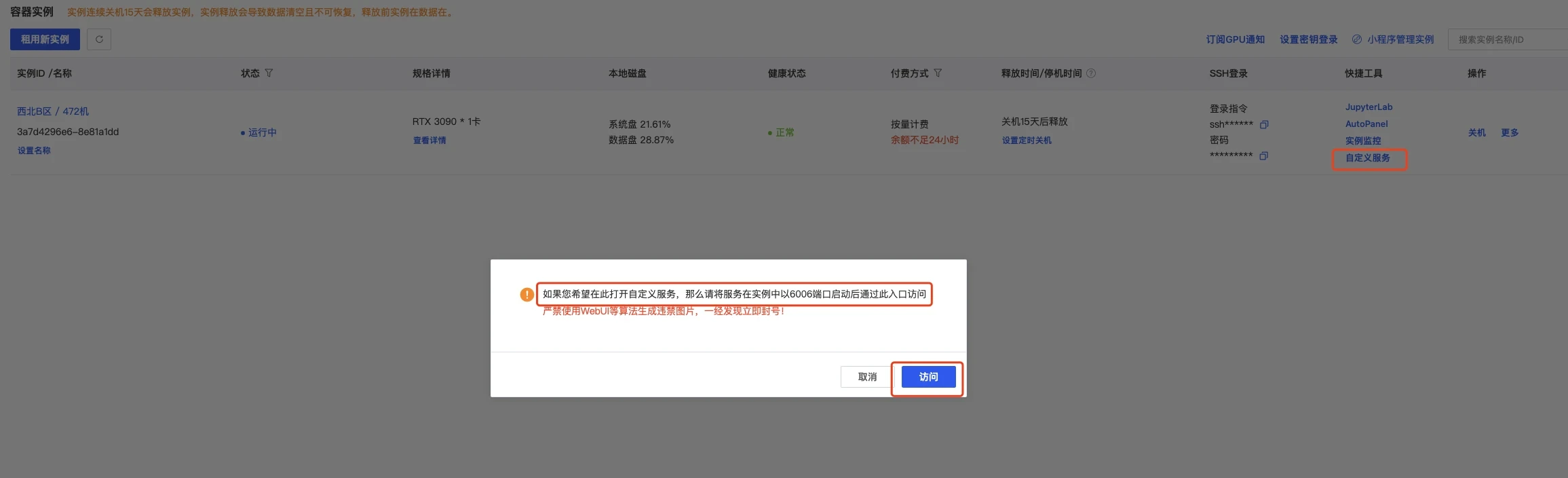
|
| 196 |
+
|
| 197 |
+
另外还有一种端口映射方式,是通过输入ssh账密实现的,步骤是一样的
|
| 198 |
+
|
| 199 |
+
> ssh端口映射工具:windows:[https://autodl-public.ks3-cn-beijing.ksyuncs.com/tool/AutoDL-SSH-Tools.zip](https://autodl-public.ks3-cn-beijing.ksyuncs.com/tool/AutoDL-SSH-Tools.zip)
|
| 200 |
+
|
| 201 |
+
### 4.5 体验Linly-Talker(成功)
|
| 202 |
+
|
| 203 |
+
点开网页,即可正确执行Linly-Talker,这一部分就跟视频一模一样了
|
| 204 |
+
|
| 205 |
+
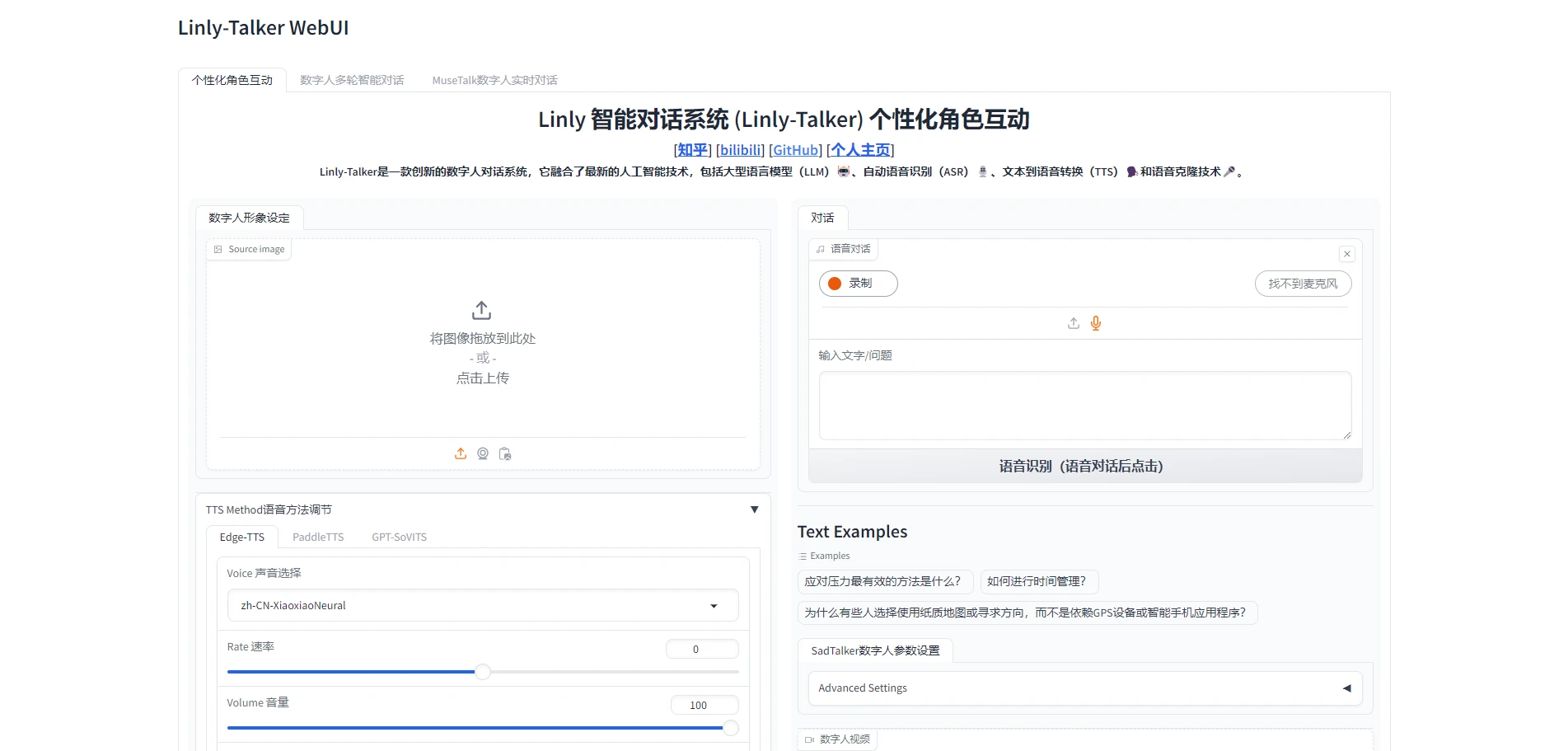
|
| 206 |
+
|
| 207 |
+
|
| 208 |
+
|
| 209 |
+
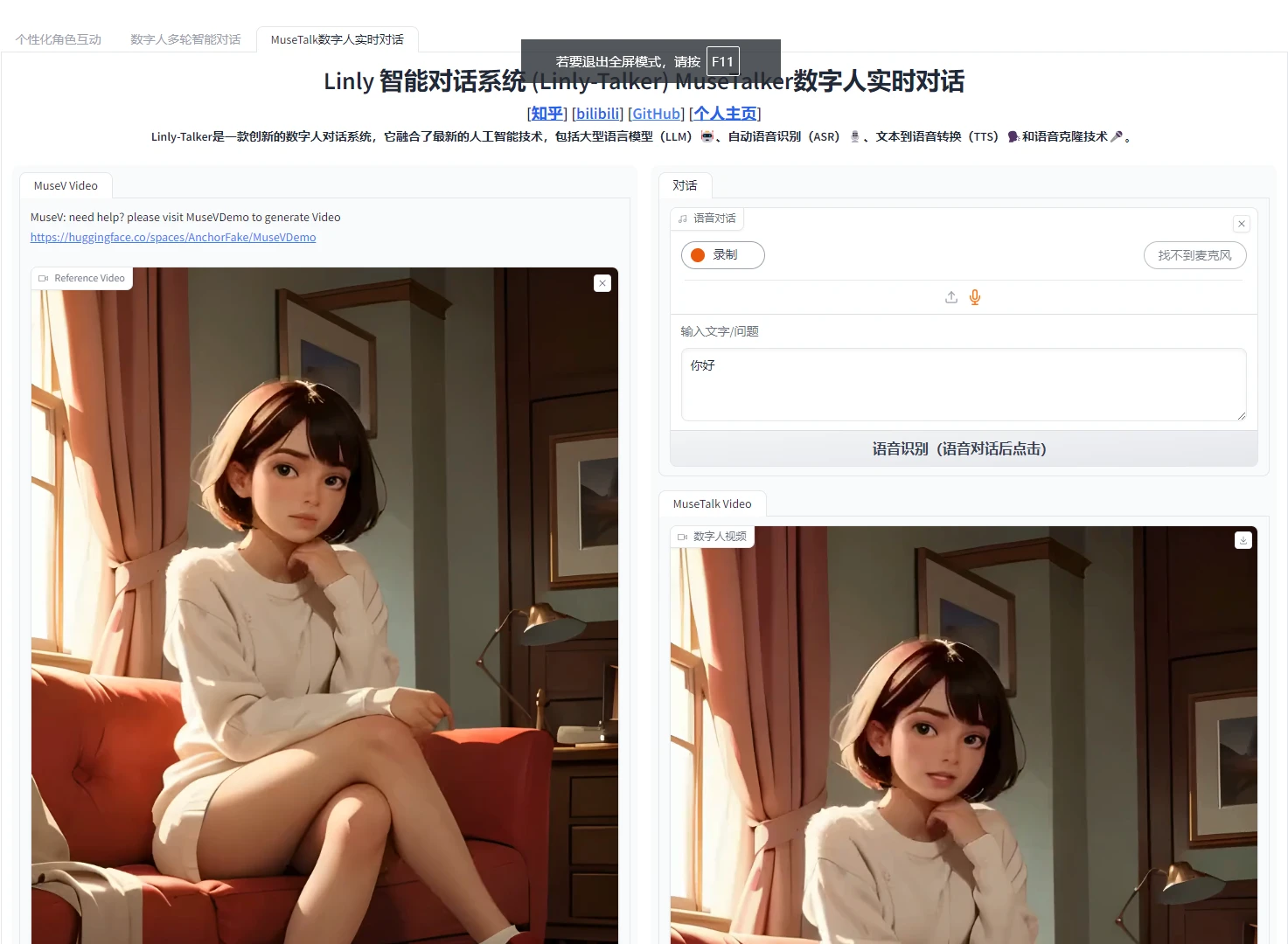
|
| 210 |
+
|
| 211 |
+
|
| 212 |
+
|
| 213 |
+
**!!!注意:不用了,一定要去控制台=》容器实例,把镜像实例关机,它是按时收费的,不关机会一直扣费的。**
|
| 214 |
+
|
| 215 |
+
**建议选北京区的,稍微便宜一些。可以晚上部署,网速快,便宜的GPU也充足。白天部署,北京区的GPU容易没有。**
|
ChatTTS/.gitignore
ADDED
|
@@ -0,0 +1,163 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Byte-compiled / optimized / DLL files
|
| 2 |
+
__pycache__/
|
| 3 |
+
*.py[cod]
|
| 4 |
+
*$py.class
|
| 5 |
+
*.ckpt
|
| 6 |
+
# C extensions
|
| 7 |
+
*.so
|
| 8 |
+
*.pt
|
| 9 |
+
|
| 10 |
+
# Distribution / packaging
|
| 11 |
+
.Python
|
| 12 |
+
outputs/
|
| 13 |
+
build/
|
| 14 |
+
develop-eggs/
|
| 15 |
+
dist/
|
| 16 |
+
downloads/
|
| 17 |
+
eggs/
|
| 18 |
+
.eggs/
|
| 19 |
+
lib/
|
| 20 |
+
lib64/
|
| 21 |
+
parts/
|
| 22 |
+
sdist/
|
| 23 |
+
var/
|
| 24 |
+
wheels/
|
| 25 |
+
share/python-wheels/
|
| 26 |
+
*.egg-info/
|
| 27 |
+
asset/*
|
| 28 |
+
.installed.cfg
|
| 29 |
+
*.egg
|
| 30 |
+
MANIFEST
|
| 31 |
+
|
| 32 |
+
# PyInstaller
|
| 33 |
+
# Usually these files are written by a python script from a template
|
| 34 |
+
# before PyInstaller builds the exe, so as to inject date/other infos into it.
|
| 35 |
+
*.manifest
|
| 36 |
+
*.spec
|
| 37 |
+
|
| 38 |
+
# Installer logs
|
| 39 |
+
pip-log.txt
|
| 40 |
+
pip-delete-this-directory.txt
|
| 41 |
+
|
| 42 |
+
# Unit test / coverage reports
|
| 43 |
+
htmlcov/
|
| 44 |
+
.tox/
|
| 45 |
+
.nox/
|
| 46 |
+
.coverage
|
| 47 |
+
.coverage.*
|
| 48 |
+
.cache
|
| 49 |
+
nosetests.xml
|
| 50 |
+
coverage.xml
|
| 51 |
+
*.cover
|
| 52 |
+
*.py,cover
|
| 53 |
+
.hypothesis/
|
| 54 |
+
.pytest_cache/
|
| 55 |
+
cover/
|
| 56 |
+
|
| 57 |
+
# Translations
|
| 58 |
+
*.mo
|
| 59 |
+
*.pot
|
| 60 |
+
|
| 61 |
+
# Django stuff:
|
| 62 |
+
*.log
|
| 63 |
+
local_settings.py
|
| 64 |
+
db.sqlite3
|
| 65 |
+
db.sqlite3-journal
|
| 66 |
+
|
| 67 |
+
# Flask stuff:
|
| 68 |
+
instance/
|
| 69 |
+
.webassets-cache
|
| 70 |
+
|
| 71 |
+
# Scrapy stuff:
|
| 72 |
+
.scrapy
|
| 73 |
+
|
| 74 |
+
# Sphinx documentation
|
| 75 |
+
docs/_build/
|
| 76 |
+
|
| 77 |
+
# PyBuilder
|
| 78 |
+
.pybuilder/
|
| 79 |
+
target/
|
| 80 |
+
|
| 81 |
+
# Jupyter Notebook
|
| 82 |
+
.ipynb_checkpoints
|
| 83 |
+
|
| 84 |
+
# IPython
|
| 85 |
+
profile_default/
|
| 86 |
+
ipython_config.py
|
| 87 |
+
|
| 88 |
+
# pyenv
|
| 89 |
+
# For a library or package, you might want to ignore these files since the code is
|
| 90 |
+
# intended to run in multiple environments; otherwise, check them in:
|
| 91 |
+
# .python-version
|
| 92 |
+
|
| 93 |
+
# pipenv
|
| 94 |
+
# According to pypa/pipenv#598, it is recommended to include Pipfile.lock in version control.
|
| 95 |
+
# However, in case of collaboration, if having platform-specific dependencies or dependencies
|
| 96 |
+
# having no cross-platform support, pipenv may install dependencies that don't work, or not
|
| 97 |
+
# install all needed dependencies.
|
| 98 |
+
#Pipfile.lock
|
| 99 |
+
|
| 100 |
+
# poetry
|
| 101 |
+
# Similar to Pipfile.lock, it is generally recommended to include poetry.lock in version control.
|
| 102 |
+
# This is especially recommended for binary packages to ensure reproducibility, and is more
|
| 103 |
+
# commonly ignored for libraries.
|
| 104 |
+
# https://python-poetry.org/docs/basic-usage/#commit-your-poetrylock-file-to-version-control
|
| 105 |
+
#poetry.lock
|
| 106 |
+
|
| 107 |
+
# pdm
|
| 108 |
+
# Similar to Pipfile.lock, it is generally recommended to include pdm.lock in version control.
|
| 109 |
+
#pdm.lock
|
| 110 |
+
# pdm stores project-wide configurations in .pdm.toml, but it is recommended to not include it
|
| 111 |
+
# in version control.
|
| 112 |
+
# https://pdm.fming.dev/#use-with-ide
|
| 113 |
+
.pdm.toml
|
| 114 |
+
|
| 115 |
+
# PEP 582; used by e.g. github.com/David-OConnor/pyflow and github.com/pdm-project/pdm
|
| 116 |
+
__pypackages__/
|
| 117 |
+
|
| 118 |
+
# Celery stuff
|
| 119 |
+
celerybeat-schedule
|
| 120 |
+
celerybeat.pid
|
| 121 |
+
|
| 122 |
+
# SageMath parsed files
|
| 123 |
+
*.sage.py
|
| 124 |
+
|
| 125 |
+
# Environments
|
| 126 |
+
.env
|
| 127 |
+
.venv
|
| 128 |
+
env/
|
| 129 |
+
venv/
|
| 130 |
+
ENV/
|
| 131 |
+
env.bak/
|
| 132 |
+
venv.bak/
|
| 133 |
+
|
| 134 |
+
# Spyder project settings
|
| 135 |
+
.spyderproject
|
| 136 |
+
.spyproject
|
| 137 |
+
|
| 138 |
+
# Rope project settings
|
| 139 |
+
.ropeproject
|
| 140 |
+
|
| 141 |
+
# mkdocs documentation
|
| 142 |
+
/site
|
| 143 |
+
|
| 144 |
+
# mypy
|
| 145 |
+
.mypy_cache/
|
| 146 |
+
.dmypy.json
|
| 147 |
+
dmypy.json
|
| 148 |
+
|
| 149 |
+
# Pyre type checker
|
| 150 |
+
.pyre/
|
| 151 |
+
|
| 152 |
+
# pytype static type analyzer
|
| 153 |
+
.pytype/
|
| 154 |
+
|
| 155 |
+
# Cython debug symbols
|
| 156 |
+
cython_debug/
|
| 157 |
+
|
| 158 |
+
# PyCharm
|
| 159 |
+
# JetBrains specific template is maintained in a separate JetBrains.gitignore that can
|
| 160 |
+
# be found at https://github.com/github/gitignore/blob/main/Global/JetBrains.gitignore
|
| 161 |
+
# and can be added to the global gitignore or merged into this file. For a more nuclear
|
| 162 |
+
# option (not recommended) you can uncomment the following to ignore the entire idea folder.
|
| 163 |
+
#.idea/
|
ChatTTS/ChatTTS/__init__.py
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
from .core import Chat
|
ChatTTS/ChatTTS/core.py
ADDED
|
@@ -0,0 +1,200 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
|
| 2 |
+
import os
|
| 3 |
+
import logging
|
| 4 |
+
from functools import partial
|
| 5 |
+
from omegaconf import OmegaConf
|
| 6 |
+
|
| 7 |
+
import torch
|
| 8 |
+
from vocos import Vocos
|
| 9 |
+
from .model.dvae import DVAE
|
| 10 |
+
from .model.gpt import GPT_warpper
|
| 11 |
+
from .utils.gpu_utils import select_device
|
| 12 |
+
from .utils.infer_utils import count_invalid_characters, detect_language, apply_character_map, apply_half2full_map
|
| 13 |
+
from .utils.io_utils import get_latest_modified_file
|
| 14 |
+
from .infer.api import refine_text, infer_code
|
| 15 |
+
|
| 16 |
+
from huggingface_hub import snapshot_download
|
| 17 |
+
|
| 18 |
+
logging.basicConfig(level = logging.INFO)
|
| 19 |
+
|
| 20 |
+
|
| 21 |
+
class Chat:
|
| 22 |
+
def __init__(self, ):
|
| 23 |
+
self.pretrain_models = {}
|
| 24 |
+
self.normalizer = {}
|
| 25 |
+
self.logger = logging.getLogger(__name__)
|
| 26 |
+
|
| 27 |
+
def check_model(self, level = logging.INFO, use_decoder = False):
|
| 28 |
+
not_finish = False
|
| 29 |
+
check_list = ['vocos', 'gpt', 'tokenizer']
|
| 30 |
+
|
| 31 |
+
if use_decoder:
|
| 32 |
+
check_list.append('decoder')
|
| 33 |
+
else:
|
| 34 |
+
check_list.append('dvae')
|
| 35 |
+
|
| 36 |
+
for module in check_list:
|
| 37 |
+
if module not in self.pretrain_models:
|
| 38 |
+
self.logger.log(logging.WARNING, f'{module} not initialized.')
|
| 39 |
+
not_finish = True
|
| 40 |
+
|
| 41 |
+
if not not_finish:
|
| 42 |
+
self.logger.log(level, f'All initialized.')
|
| 43 |
+
|
| 44 |
+
return not not_finish
|
| 45 |
+
|
| 46 |
+
def load_models(self, source='huggingface', force_redownload=False, local_path='<LOCAL_PATH>', **kwargs):
|
| 47 |
+
if source == 'huggingface':
|
| 48 |
+
hf_home = os.getenv('HF_HOME', os.path.expanduser("~/.cache/huggingface"))
|
| 49 |
+
try:
|
| 50 |
+
download_path = get_latest_modified_file(os.path.join(hf_home, 'hub/models--2Noise--ChatTTS/snapshots'))
|
| 51 |
+
except:
|
| 52 |
+
download_path = None
|
| 53 |
+
if download_path is None or force_redownload:
|
| 54 |
+
self.logger.log(logging.INFO, f'Download from HF: https://huggingface.co/2Noise/ChatTTS')
|
| 55 |
+
download_path = snapshot_download(repo_id="2Noise/ChatTTS", allow_patterns=["*.pt", "*.yaml"])
|
| 56 |
+
else:
|
| 57 |
+
self.logger.log(logging.INFO, f'Load from cache: {download_path}')
|
| 58 |
+
elif source == 'local':
|
| 59 |
+
self.logger.log(logging.INFO, f'Load from local: {local_path}')
|
| 60 |
+
download_path = local_path
|
| 61 |
+
|
| 62 |
+
self._load(**{k: os.path.join(download_path, v) for k, v in OmegaConf.load(os.path.join(download_path, 'config', 'path.yaml')).items()}, **kwargs)
|
| 63 |
+
|
| 64 |
+
def _load(
|
| 65 |
+
self,
|
| 66 |
+
vocos_config_path: str = None,
|
| 67 |
+
vocos_ckpt_path: str = None,
|
| 68 |
+
dvae_config_path: str = None,
|
| 69 |
+
dvae_ckpt_path: str = None,
|
| 70 |
+
gpt_config_path: str = None,
|
| 71 |
+
gpt_ckpt_path: str = None,
|
| 72 |
+
decoder_config_path: str = None,
|
| 73 |
+
decoder_ckpt_path: str = None,
|
| 74 |
+
tokenizer_path: str = None,
|
| 75 |
+
device: str = None,
|
| 76 |
+
compile: bool = True,
|
| 77 |
+
):
|
| 78 |
+
if not device:
|
| 79 |
+
device = select_device(4096)
|
| 80 |
+
self.logger.log(logging.INFO, f'use {device}')
|
| 81 |
+
|
| 82 |
+
if vocos_config_path:
|
| 83 |
+
vocos = Vocos.from_hparams(vocos_config_path).to(device).eval()
|
| 84 |
+
assert vocos_ckpt_path, 'vocos_ckpt_path should not be None'
|
| 85 |
+
vocos.load_state_dict(torch.load(vocos_ckpt_path))
|
| 86 |
+
self.pretrain_models['vocos'] = vocos
|
| 87 |
+
self.logger.log(logging.INFO, 'vocos loaded.')
|
| 88 |
+
|
| 89 |
+
if dvae_config_path:
|
| 90 |
+
cfg = OmegaConf.load(dvae_config_path)
|
| 91 |
+
dvae = DVAE(**cfg).to(device).eval()
|
| 92 |
+
assert dvae_ckpt_path, 'dvae_ckpt_path should not be None'
|
| 93 |
+
dvae.load_state_dict(torch.load(dvae_ckpt_path, map_location='cpu'))
|
| 94 |
+
self.pretrain_models['dvae'] = dvae
|
| 95 |
+
self.logger.log(logging.INFO, 'dvae loaded.')
|
| 96 |
+
|
| 97 |
+
if gpt_config_path:
|
| 98 |
+
cfg = OmegaConf.load(gpt_config_path)
|
| 99 |
+
gpt = GPT_warpper(**cfg).to(device).eval()
|
| 100 |
+
assert gpt_ckpt_path, 'gpt_ckpt_path should not be None'
|
| 101 |
+
gpt.load_state_dict(torch.load(gpt_ckpt_path, map_location='cpu'))
|
| 102 |
+
if compile and 'cuda' in str(device):
|
| 103 |
+
gpt.gpt.forward = torch.compile(gpt.gpt.forward, backend='inductor', dynamic=True)
|
| 104 |
+
self.pretrain_models['gpt'] = gpt
|
| 105 |
+
spk_stat_path = os.path.join(os.path.dirname(gpt_ckpt_path), 'spk_stat.pt')
|
| 106 |
+
assert os.path.exists(spk_stat_path), f'Missing spk_stat.pt: {spk_stat_path}'
|
| 107 |
+
self.pretrain_models['spk_stat'] = torch.load(spk_stat_path).to(device)
|
| 108 |
+
self.logger.log(logging.INFO, 'gpt loaded.')
|
| 109 |
+
|
| 110 |
+
if decoder_config_path:
|
| 111 |
+
cfg = OmegaConf.load(decoder_config_path)
|
| 112 |
+
decoder = DVAE(**cfg).to(device).eval()
|
| 113 |
+
assert decoder_ckpt_path, 'decoder_ckpt_path should not be None'
|
| 114 |
+
decoder.load_state_dict(torch.load(decoder_ckpt_path, map_location='cpu'))
|
| 115 |
+
self.pretrain_models['decoder'] = decoder
|
| 116 |
+
self.logger.log(logging.INFO, 'decoder loaded.')
|
| 117 |
+
|
| 118 |
+
if tokenizer_path:
|
| 119 |
+
tokenizer = torch.load(tokenizer_path, map_location='cpu')
|
| 120 |
+
tokenizer.padding_side = 'left'
|
| 121 |
+
self.pretrain_models['tokenizer'] = tokenizer
|
| 122 |
+
self.logger.log(logging.INFO, 'tokenizer loaded.')
|
| 123 |
+
|
| 124 |
+
self.check_model()
|
| 125 |
+
|
| 126 |
+
def infer(
|
| 127 |
+
self,
|
| 128 |
+
text,
|
| 129 |
+
skip_refine_text=False,
|
| 130 |
+
refine_text_only=False,
|
| 131 |
+
params_refine_text={},
|
| 132 |
+
params_infer_code={'prompt':'[speed_5]'},
|
| 133 |
+
use_decoder=True,
|
| 134 |
+
do_text_normalization=True,
|
| 135 |
+
lang=None,
|
| 136 |
+
):
|
| 137 |
+
|
| 138 |
+
assert self.check_model(use_decoder=use_decoder)
|
| 139 |
+
|
| 140 |
+
if not isinstance(text, list):
|
| 141 |
+
text = [text]
|
| 142 |
+
|
| 143 |
+
if do_text_normalization:
|
| 144 |
+
for i, t in enumerate(text):
|
| 145 |
+
_lang = detect_language(t) if lang is None else lang
|
| 146 |
+
self.init_normalizer(_lang)
|
| 147 |
+
text[i] = self.normalizer[_lang](t)
|
| 148 |
+
if _lang == 'zh':
|
| 149 |
+
text[i] = apply_half2full_map(text[i])
|
| 150 |
+
|
| 151 |
+
for i, t in enumerate(text):
|
| 152 |
+
invalid_characters = count_invalid_characters(t)
|
| 153 |
+
if len(invalid_characters):
|
| 154 |
+
self.logger.log(logging.WARNING, f'Invalid characters found! : {invalid_characters}')
|
| 155 |
+
text[i] = apply_character_map(t)
|
| 156 |
+
|
| 157 |
+
if not skip_refine_text:
|
| 158 |
+
text_tokens = refine_text(self.pretrain_models, text, **params_refine_text)['ids']
|
| 159 |
+
text_tokens = [i[i < self.pretrain_models['tokenizer'].convert_tokens_to_ids('[break_0]')] for i in text_tokens]
|
| 160 |
+
text = self.pretrain_models['tokenizer'].batch_decode(text_tokens)
|
| 161 |
+
if refine_text_only:
|
| 162 |
+
return text
|
| 163 |
+
|
| 164 |
+
text = [params_infer_code.get('prompt', '') + i for i in text]
|
| 165 |
+
params_infer_code.pop('prompt', '')
|
| 166 |
+
result = infer_code(self.pretrain_models, text, **params_infer_code, return_hidden=use_decoder)
|
| 167 |
+
|
| 168 |
+
if use_decoder:
|
| 169 |
+
mel_spec = [self.pretrain_models['decoder'](i[None].permute(0,2,1)) for i in result['hiddens']]
|
| 170 |
+
else:
|
| 171 |
+
mel_spec = [self.pretrain_models['dvae'](i[None].permute(0,2,1)) for i in result['ids']]
|
| 172 |
+
|
| 173 |
+
wav = [self.pretrain_models['vocos'].decode(i).cpu().numpy() for i in mel_spec]
|
| 174 |
+
|
| 175 |
+
return wav
|
| 176 |
+
|
| 177 |
+
def sample_random_speaker(self, ):
|
| 178 |
+
|
| 179 |
+
dim = self.pretrain_models['gpt'].gpt.layers[0].mlp.gate_proj.in_features
|
| 180 |
+
std, mean = self.pretrain_models['spk_stat'].chunk(2)
|
| 181 |
+
return torch.randn(dim, device=std.device) * std + mean
|
| 182 |
+
|
| 183 |
+
def init_normalizer(self, lang):
|
| 184 |
+
|
| 185 |
+
if lang not in self.normalizer:
|
| 186 |
+
if lang == 'zh':
|
| 187 |
+
try:
|
| 188 |
+
from tn.chinese.normalizer import Normalizer
|
| 189 |
+
except:
|
| 190 |
+
self.logger.log(logging.WARNING, f'Package WeTextProcessing not found! \
|
| 191 |
+
Run: conda install -c conda-forge pynini=2.1.5 && pip install WeTextProcessing')
|
| 192 |
+
self.normalizer[lang] = Normalizer().normalize
|
| 193 |
+
else:
|
| 194 |
+
try:
|
| 195 |
+
from nemo_text_processing.text_normalization.normalize import Normalizer
|
| 196 |
+
except:
|
| 197 |
+
self.logger.log(logging.WARNING, f'Package nemo_text_processing not found! \
|
| 198 |
+
Run: conda install -c conda-forge pynini=2.1.5 && pip install nemo_text_processing')
|
| 199 |
+
self.normalizer[lang] = partial(Normalizer(input_case='cased', lang=lang).normalize, verbose=False, punct_post_process=True)
|
| 200 |
+
|
ChatTTS/ChatTTS/experimental/llm.py
ADDED
|
@@ -0,0 +1,40 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
|
| 2 |
+
from openai import OpenAI
|
| 3 |
+
|
| 4 |
+
prompt_dict = {
|
| 5 |
+
'kimi': [ {"role": "system", "content": "你是 Kimi,由 Moonshot AI 提供的人工智能助手,你更擅长中文和英文的对话。"},
|
| 6 |
+
{"role": "user", "content": "你好,请注意你现在生成的文字要按照人日常生活的口吻,你的回复将会后续用TTS模型转为语音,并且请把回答控制在100字以内。并且标点符号仅包含逗号和句号,将数字等转为文字回答。"},
|
| 7 |
+
{"role": "assistant", "content": "好的,我现在生成的文字将按照人日常生活的口吻, 并且我会把回答控制在一百字以内, 标点符号仅包含逗号和句号,将阿拉伯数字等转为中文文字回答。下面请开始对话。"},],
|
| 8 |
+
'deepseek': [
|
| 9 |
+
{"role": "system", "content": "You are a helpful assistant"},
|
| 10 |
+
{"role": "user", "content": "你好,请注意你现在生成的文字要按照人日常生活的口吻,你的回复将会后续用TTS模型转为语音,并且请把回答控制在100字以内。并且标点符号仅包含逗号和句号,将数字等转为文字回答。"},
|
| 11 |
+
{"role": "assistant", "content": "好的,我现在生成的文字将按照人日常生活的口吻, 并且我会把回答控制在一百字以内, 标点符号仅包含逗号和句号,将阿拉伯数字等转为中文文字回答。下面请开始对话。"},],
|
| 12 |
+
'deepseek_TN': [
|
| 13 |
+
{"role": "system", "content": "You are a helpful assistant"},
|
| 14 |
+
{"role": "user", "content": "你好,现在我们在处理TTS的文本输入,下面将会给你输入一段文本,请你将其中的阿拉伯数字等等转为文字表达,并且输出的文本里仅包含逗号和句号这两个标点符号"},
|
| 15 |
+
{"role": "assistant", "content": "好的,我现在对TTS的文本输入进行处理。这一般叫做text normalization。下面请输入"},
|
| 16 |
+
{"role": "user", "content": "We paid $123 for this desk."},
|
| 17 |
+
{"role": "assistant", "content": "We paid one hundred and twenty three dollars for this desk."},
|
| 18 |
+
{"role": "user", "content": "详询请拨打010-724654"},
|
| 19 |
+
{"role": "assistant", "content": "详询请拨打零幺零,七二四六五四"},
|
| 20 |
+
{"role": "user", "content": "罗森宣布将于7月24日退市,在华门店超6000家!"},
|
| 21 |
+
{"role": "assistant", "content": "罗森宣布将于七月二十四日退市,在华门店超过六千家。"},
|
| 22 |
+
],
|
| 23 |
+
}
|
| 24 |
+
|
| 25 |
+
class llm_api:
|
| 26 |
+
def __init__(self, api_key, base_url, model):
|
| 27 |
+
self.client = OpenAI(
|
| 28 |
+
api_key = api_key,
|
| 29 |
+
base_url = base_url,
|
| 30 |
+
)
|
| 31 |
+
self.model = model
|
| 32 |
+
def call(self, user_question, temperature = 0.3, prompt_version='kimi', **kwargs):
|
| 33 |
+
|
| 34 |
+
completion = self.client.chat.completions.create(
|
| 35 |
+
model = self.model,
|
| 36 |
+
messages = prompt_dict[prompt_version]+[{"role": "user", "content": user_question},],
|
| 37 |
+
temperature = temperature,
|
| 38 |
+
**kwargs
|
| 39 |
+
)
|
| 40 |
+
return completion.choices[0].message.content
|
ChatTTS/ChatTTS/infer/api.py
ADDED
|
@@ -0,0 +1,125 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
|
| 2 |
+
import torch
|
| 3 |
+
import torch.nn.functional as F
|
| 4 |
+
from transformers.generation import TopKLogitsWarper, TopPLogitsWarper
|
| 5 |
+
from ..utils.infer_utils import CustomRepetitionPenaltyLogitsProcessorRepeat
|
| 6 |
+
|
| 7 |
+
def infer_code(
|
| 8 |
+
models,
|
| 9 |
+
text,
|
| 10 |
+
spk_emb = None,
|
| 11 |
+
top_P = 0.7,
|
| 12 |
+
top_K = 20,
|
| 13 |
+
temperature = 0.3,
|
| 14 |
+
repetition_penalty = 1.05,
|
| 15 |
+
max_new_token = 2048,
|
| 16 |
+
**kwargs
|
| 17 |
+
):
|
| 18 |
+
|
| 19 |
+
device = next(models['gpt'].parameters()).device
|
| 20 |
+
|
| 21 |
+
if not isinstance(text, list):
|
| 22 |
+
text = [text]
|
| 23 |
+
|
| 24 |
+
if not isinstance(temperature, list):
|
| 25 |
+
temperature = [temperature] * models['gpt'].num_vq
|
| 26 |
+
|
| 27 |
+
if spk_emb is not None:
|
| 28 |
+
text = [f'[Stts][spk_emb]{i}[Ptts]' for i in text]
|
| 29 |
+
else:
|
| 30 |
+
text = [f'[Stts][empty_spk]{i}[Ptts]' for i in text]
|
| 31 |
+
|
| 32 |
+
text_token = models['tokenizer'](text, return_tensors='pt', add_special_tokens=False, padding=True).to(device)
|
| 33 |
+
input_ids = text_token['input_ids'][...,None].expand(-1, -1, models['gpt'].num_vq)
|
| 34 |
+
text_mask = torch.ones(text_token['input_ids'].shape, dtype=bool, device=device)
|
| 35 |
+
|
| 36 |
+
inputs = {
|
| 37 |
+
'input_ids': input_ids,
|
| 38 |
+
'text_mask': text_mask,
|
| 39 |
+
'attention_mask': text_token['attention_mask'],
|
| 40 |
+
}
|
| 41 |
+
|
| 42 |
+
emb = models['gpt'].get_emb(**inputs)
|
| 43 |
+
if spk_emb is not None:
|
| 44 |
+
emb[inputs['input_ids'][..., 0] == models['tokenizer'].convert_tokens_to_ids('[spk_emb]')] = \
|
| 45 |
+
F.normalize(spk_emb.to(device).to(emb.dtype)[None].expand(len(text), -1), p=2.0, dim=1, eps=1e-12)
|
| 46 |
+
|
| 47 |
+
num_code = models['gpt'].emb_code[0].num_embeddings - 1
|
| 48 |
+
|
| 49 |
+
LogitsWarpers = []
|
| 50 |
+
if top_P is not None:
|
| 51 |
+
LogitsWarpers.append(TopPLogitsWarper(top_P, min_tokens_to_keep=3))
|
| 52 |
+
if top_K is not None:
|
| 53 |
+
LogitsWarpers.append(TopKLogitsWarper(top_K, min_tokens_to_keep=3))
|
| 54 |
+
|
| 55 |
+
LogitsProcessors = []
|
| 56 |
+
if repetition_penalty is not None and repetition_penalty != 1:
|
| 57 |
+
LogitsProcessors.append(CustomRepetitionPenaltyLogitsProcessorRepeat(\
|
| 58 |
+
repetition_penalty, num_code, 16))
|
| 59 |
+
|
| 60 |
+
result = models['gpt'].generate(
|
| 61 |
+
emb, inputs['input_ids'],
|
| 62 |
+
temperature = torch.tensor(temperature, device=device),
|
| 63 |
+
attention_mask = inputs['attention_mask'],
|
| 64 |
+
LogitsWarpers = LogitsWarpers,
|
| 65 |
+
LogitsProcessors = LogitsProcessors,
|
| 66 |
+
eos_token = num_code,
|
| 67 |
+
max_new_token = max_new_token,
|
| 68 |
+
infer_text = False,
|
| 69 |
+
**kwargs
|
| 70 |
+
)
|
| 71 |
+
|
| 72 |
+
return result
|
| 73 |
+
|
| 74 |
+
|
| 75 |
+
def refine_text(
|
| 76 |
+
models,
|
| 77 |
+
text,
|
| 78 |
+
top_P = 0.7,
|
| 79 |
+
top_K = 20,
|
| 80 |
+
temperature = 0.7,
|
| 81 |
+
repetition_penalty = 1.0,
|
| 82 |
+
max_new_token = 384,
|
| 83 |
+
prompt = '',
|
| 84 |
+
**kwargs
|
| 85 |
+
):
|
| 86 |
+
|
| 87 |
+
device = next(models['gpt'].parameters()).device
|
| 88 |
+
|
| 89 |
+
if not isinstance(text, list):
|
| 90 |
+
text = [text]
|
| 91 |
+
|
| 92 |
+
assert len(text), 'text should not be empty'
|
| 93 |
+
|
| 94 |
+
text = [f"[Sbreak]{i}[Pbreak]{prompt}" for i in text]
|
| 95 |
+
text_token = models['tokenizer'](text, return_tensors='pt', add_special_tokens=False, padding=True).to(device)
|
| 96 |
+
text_mask = torch.ones(text_token['input_ids'].shape, dtype=bool, device=device)
|
| 97 |
+
|
| 98 |
+
inputs = {
|
| 99 |
+
'input_ids': text_token['input_ids'][...,None].expand(-1, -1, models['gpt'].num_vq),
|
| 100 |
+
'text_mask': text_mask,
|
| 101 |
+
'attention_mask': text_token['attention_mask'],
|
| 102 |
+
}
|
| 103 |
+
|
| 104 |
+
LogitsWarpers = []
|
| 105 |
+
if top_P is not None:
|
| 106 |
+
LogitsWarpers.append(TopPLogitsWarper(top_P, min_tokens_to_keep=3))
|
| 107 |
+
if top_K is not None:
|
| 108 |
+
LogitsWarpers.append(TopKLogitsWarper(top_K, min_tokens_to_keep=3))
|
| 109 |
+
|
| 110 |
+
LogitsProcessors = []
|
| 111 |
+
if repetition_penalty is not None and repetition_penalty != 1:
|
| 112 |
+
LogitsProcessors.append(CustomRepetitionPenaltyLogitsProcessorRepeat(repetition_penalty, len(models['tokenizer']), 16))
|
| 113 |
+
|
| 114 |
+
result = models['gpt'].generate(
|
| 115 |
+
models['gpt'].get_emb(**inputs), inputs['input_ids'],
|
| 116 |
+
temperature = torch.tensor([temperature,], device=device),
|
| 117 |
+
attention_mask = inputs['attention_mask'],
|
| 118 |
+
LogitsWarpers = LogitsWarpers,
|
| 119 |
+
LogitsProcessors = LogitsProcessors,
|
| 120 |
+
eos_token = torch.tensor(models['tokenizer'].convert_tokens_to_ids('[Ebreak]'), device=device)[None],
|
| 121 |
+
max_new_token = max_new_token,
|
| 122 |
+
infer_text = True,
|
| 123 |
+
**kwargs
|
| 124 |
+
)
|
| 125 |
+
return result
|
ChatTTS/ChatTTS/model/dvae.py
ADDED
|
@@ -0,0 +1,155 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import math
|
| 2 |
+
from einops import rearrange
|
| 3 |
+
from vector_quantize_pytorch import GroupedResidualFSQ
|
| 4 |
+
|
| 5 |
+
import torch
|
| 6 |
+
import torch.nn as nn
|
| 7 |
+
import torch.nn.functional as F
|
| 8 |
+
|
| 9 |
+
class ConvNeXtBlock(nn.Module):
|
| 10 |
+
def __init__(
|
| 11 |
+
self,
|
| 12 |
+
dim: int,
|
| 13 |
+
intermediate_dim: int,
|
| 14 |
+
kernel, dilation,
|
| 15 |
+
layer_scale_init_value: float = 1e-6,
|
| 16 |
+
):
|
| 17 |
+
# ConvNeXt Block copied from Vocos.
|
| 18 |
+
super().__init__()
|
| 19 |
+
self.dwconv = nn.Conv1d(dim, dim,
|
| 20 |
+
kernel_size=kernel, padding=dilation*(kernel//2),
|
| 21 |
+
dilation=dilation, groups=dim
|
| 22 |
+
) # depthwise conv
|
| 23 |
+
|
| 24 |
+
self.norm = nn.LayerNorm(dim, eps=1e-6)
|
| 25 |
+
self.pwconv1 = nn.Linear(dim, intermediate_dim) # pointwise/1x1 convs, implemented with linear layers
|
| 26 |
+
self.act = nn.GELU()
|
| 27 |
+
self.pwconv2 = nn.Linear(intermediate_dim, dim)
|
| 28 |
+
self.gamma = (
|
| 29 |
+
nn.Parameter(layer_scale_init_value * torch.ones(dim), requires_grad=True)
|
| 30 |
+
if layer_scale_init_value > 0
|
| 31 |
+
else None
|
| 32 |
+
)
|
| 33 |
+
|
| 34 |
+
def forward(self, x: torch.Tensor, cond = None) -> torch.Tensor:
|
| 35 |
+
residual = x
|
| 36 |
+
x = self.dwconv(x)
|
| 37 |
+
x = x.transpose(1, 2) # (B, C, T) -> (B, T, C)
|
| 38 |
+
x = self.norm(x)
|
| 39 |
+
x = self.pwconv1(x)
|
| 40 |
+
x = self.act(x)
|
| 41 |
+
x = self.pwconv2(x)
|
| 42 |
+
if self.gamma is not None:
|
| 43 |
+
x = self.gamma * x
|
| 44 |
+
x = x.transpose(1, 2) # (B, T, C) -> (B, C, T)
|
| 45 |
+
|
| 46 |
+
x = residual + x
|
| 47 |
+
return x
|
| 48 |
+
|
| 49 |
+
|
| 50 |
+
|
| 51 |
+
class GFSQ(nn.Module):
|
| 52 |
+
|
| 53 |
+
def __init__(self,
|
| 54 |
+
dim, levels, G, R, eps=1e-5, transpose = True
|
| 55 |
+
):
|
| 56 |
+
super(GFSQ, self).__init__()
|
| 57 |
+
self.quantizer = GroupedResidualFSQ(
|
| 58 |
+
dim=dim,
|
| 59 |
+
levels=levels,
|
| 60 |
+
num_quantizers=R,
|
| 61 |
+
groups=G,
|
| 62 |
+
)
|
| 63 |
+
self.n_ind = math.prod(levels)
|
| 64 |
+
self.eps = eps
|
| 65 |
+
self.transpose = transpose
|
| 66 |
+
self.G = G
|
| 67 |
+
self.R = R
|
| 68 |
+
|
| 69 |
+
def _embed(self, x):
|
| 70 |
+
if self.transpose:
|
| 71 |
+
x = x.transpose(1,2)
|
| 72 |
+
x = rearrange(
|
| 73 |
+
x, "b t (g r) -> g b t r", g = self.G, r = self.R,
|
| 74 |
+
)
|
| 75 |
+
feat = self.quantizer.get_output_from_indices(x)
|
| 76 |
+
return feat.transpose(1,2) if self.transpose else feat
|
| 77 |
+
|
| 78 |
+
def forward(self, x,):
|
| 79 |
+
if self.transpose:
|
| 80 |
+
x = x.transpose(1,2)
|
| 81 |
+
feat, ind = self.quantizer(x)
|
| 82 |
+
ind = rearrange(
|
| 83 |
+
ind, "g b t r ->b t (g r)",
|
| 84 |
+
)
|
| 85 |
+
embed_onehot = F.one_hot(ind.long(), self.n_ind).to(x.dtype)
|
| 86 |
+
e_mean = torch.mean(embed_onehot, dim=[0,1])
|
| 87 |
+
e_mean = e_mean / (e_mean.sum(dim=1) + self.eps).unsqueeze(1)
|
| 88 |
+
perplexity = torch.exp(-torch.sum(e_mean * torch.log(e_mean + self.eps), dim=1))
|
| 89 |
+
|
| 90 |
+
return (
|
| 91 |
+
torch.zeros(perplexity.shape, dtype=x.dtype, device=x.device),
|
| 92 |
+
feat.transpose(1,2) if self.transpose else feat,
|
| 93 |
+
perplexity,
|
| 94 |
+
None,
|
| 95 |
+
ind.transpose(1,2) if self.transpose else ind,
|
| 96 |
+
)
|
| 97 |
+
|
| 98 |
+
class DVAEDecoder(nn.Module):
|
| 99 |
+
def __init__(self, idim, odim,
|
| 100 |
+
n_layer = 12, bn_dim = 64, hidden = 256,
|
| 101 |
+
kernel = 7, dilation = 2, up = False
|
| 102 |
+
):
|
| 103 |
+
super().__init__()
|
| 104 |
+
self.up = up
|
| 105 |
+
self.conv_in = nn.Sequential(
|
| 106 |
+
nn.Conv1d(idim, bn_dim, 3, 1, 1), nn.GELU(),
|
| 107 |
+
nn.Conv1d(bn_dim, hidden, 3, 1, 1)
|
| 108 |
+
)
|
| 109 |
+
self.decoder_block = nn.ModuleList([
|
| 110 |
+
ConvNeXtBlock(hidden, hidden* 4, kernel, dilation,)
|
| 111 |
+
for _ in range(n_layer)])
|
| 112 |
+
self.conv_out = nn.Conv1d(hidden, odim, kernel_size=1, bias=False)
|
| 113 |
+
|
| 114 |
+
def forward(self, input, conditioning=None):
|
| 115 |
+
# B, T, C
|
| 116 |
+
x = input.transpose(1, 2)
|
| 117 |
+
x = self.conv_in(x)
|
| 118 |
+
for f in self.decoder_block:
|
| 119 |
+
x = f(x, conditioning)
|
| 120 |
+
|
| 121 |
+
x = self.conv_out(x)
|
| 122 |
+
return x.transpose(1, 2)
|
| 123 |
+
|
| 124 |
+
|
| 125 |
+
class DVAE(nn.Module):
|
| 126 |
+
def __init__(
|
| 127 |
+
self, decoder_config, vq_config, dim=512
|
| 128 |
+
):
|
| 129 |
+
super().__init__()
|
| 130 |
+
self.register_buffer('coef', torch.randn(1, 100, 1))
|
| 131 |
+
|
| 132 |
+
self.decoder = DVAEDecoder(**decoder_config)
|
| 133 |
+
self.out_conv = nn.Conv1d(dim, 100, 3, 1, 1, bias=False)
|
| 134 |
+
if vq_config is not None:
|
| 135 |
+
self.vq_layer = GFSQ(**vq_config)
|
| 136 |
+
else:
|
| 137 |
+
self.vq_layer = None
|
| 138 |
+
|
| 139 |
+
def forward(self, inp):
|
| 140 |
+
|
| 141 |
+
if self.vq_layer is not None:
|
| 142 |
+
vq_feats = self.vq_layer._embed(inp)
|
| 143 |
+
else:
|
| 144 |
+
vq_feats = inp.detach().clone()
|
| 145 |
+
|
| 146 |
+
temp = torch.chunk(vq_feats, 2, dim=1) # flatten trick :)
|
| 147 |
+
temp = torch.stack(temp, -1)
|
| 148 |
+
vq_feats = temp.reshape(*temp.shape[:2], -1)
|
| 149 |
+
|
| 150 |
+
vq_feats = vq_feats.transpose(1, 2)
|
| 151 |
+
dec_out = self.decoder(input=vq_feats)
|
| 152 |
+
dec_out = self.out_conv(dec_out.transpose(1, 2))
|
| 153 |
+
mel = dec_out * self.coef
|
| 154 |
+
|
| 155 |
+
return mel
|
ChatTTS/ChatTTS/model/gpt.py
ADDED
|
@@ -0,0 +1,265 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
os.environ["TOKENIZERS_PARALLELISM"] = "false"
|
| 3 |
+
|
| 4 |
+
import logging
|
| 5 |
+
from tqdm import tqdm
|
| 6 |
+
from einops import rearrange
|
| 7 |
+
from transformers.cache_utils import Cache
|
| 8 |
+
|
| 9 |
+
import torch
|
| 10 |
+
import torch.nn as nn
|
| 11 |
+
import torch.nn.functional as F
|
| 12 |
+
import torch.nn.utils.parametrize as P
|
| 13 |
+
from torch.nn.utils.parametrizations import weight_norm
|
| 14 |
+
from transformers import LlamaModel, LlamaConfig
|
| 15 |
+
|
| 16 |
+
|
| 17 |
+
class LlamaMLP(nn.Module):
|
| 18 |
+
def __init__(self, hidden_size, intermediate_size):
|
| 19 |
+
super().__init__()
|
| 20 |
+
self.hidden_size = hidden_size
|
| 21 |
+
self.intermediate_size = intermediate_size
|
| 22 |
+
self.gate_proj = nn.Linear(self.hidden_size, self.intermediate_size, bias=False)
|
| 23 |
+
self.up_proj = nn.Linear(self.hidden_size, self.intermediate_size, bias=False)
|
| 24 |
+
self.down_proj = nn.Linear(self.intermediate_size, self.hidden_size, bias=False)
|
| 25 |
+
self.act_fn = F.silu
|
| 26 |
+
|
| 27 |
+
def forward(self, x):
|
| 28 |
+
down_proj = self.down_proj(self.act_fn(self.gate_proj(x)) * self.up_proj(x))
|
| 29 |
+
return down_proj
|
| 30 |
+
|
| 31 |
+
|
| 32 |
+
class GPT_warpper(nn.Module):
|
| 33 |
+
def __init__(
|
| 34 |
+
self,
|
| 35 |
+
gpt_config,
|
| 36 |
+
num_audio_tokens,
|
| 37 |
+
num_text_tokens,
|
| 38 |
+
num_vq=4,
|
| 39 |
+
**kwargs,
|
| 40 |
+
):
|
| 41 |
+
super().__init__()
|
| 42 |
+
|
| 43 |
+
self.logger = logging.getLogger(__name__)
|
| 44 |
+
self.gpt = self.build_model(gpt_config)
|
| 45 |
+
self.model_dim = self.gpt.config.hidden_size
|
| 46 |
+
|
| 47 |
+
self.num_vq = num_vq
|
| 48 |
+
self.emb_code = nn.ModuleList([nn.Embedding(num_audio_tokens, self.model_dim) for i in range(self.num_vq)])
|
| 49 |
+
self.emb_text = nn.Embedding(num_text_tokens, self.model_dim)
|
| 50 |
+
self.head_text = weight_norm(nn.Linear(self.model_dim, num_text_tokens, bias=False), name='weight')
|
| 51 |
+
self.head_code = nn.ModuleList([weight_norm(nn.Linear(self.model_dim, num_audio_tokens, bias=False), name='weight') for i in range(self.num_vq)])
|
| 52 |
+
|
| 53 |
+
def build_model(self, config):
|
| 54 |
+
|
| 55 |
+
configuration = LlamaConfig(**config)
|
| 56 |
+
model = LlamaModel(configuration)
|
| 57 |
+
del model.embed_tokens
|
| 58 |
+
|
| 59 |
+
return model
|
| 60 |
+
|
| 61 |
+
def get_emb(self, input_ids, text_mask, **kwargs):
|
| 62 |
+
|
| 63 |
+
emb_text = self.emb_text(input_ids[text_mask][:, 0])
|
| 64 |
+
|
| 65 |
+
emb_code = [self.emb_code[i](input_ids[~text_mask][:, i]) for i in range(self.num_vq)]
|
| 66 |
+
emb_code = torch.stack(emb_code, 2).sum(2)
|
| 67 |
+
|
| 68 |
+
emb = torch.zeros((input_ids.shape[:-1])+(emb_text.shape[-1],), device=emb_text.device, dtype=emb_text.dtype)
|
| 69 |
+
emb[text_mask] = emb_text
|
| 70 |
+
emb[~text_mask] = emb_code.to(emb.dtype)
|
| 71 |
+
|
| 72 |
+
return emb
|
| 73 |
+
|
| 74 |
+
def prepare_inputs_for_generation(
|
| 75 |
+
self, input_ids, past_key_values=None, attention_mask=None, inputs_embeds=None, cache_position=None, **kwargs
|
| 76 |
+
):
|
| 77 |
+
# With static cache, the `past_key_values` is None
|
| 78 |
+
# TODO joao: standardize interface for the different Cache classes and remove of this if
|
| 79 |
+
has_static_cache = False
|
| 80 |
+
if past_key_values is None:
|
| 81 |
+
past_key_values = getattr(self.gpt.layers[0].self_attn, "past_key_value", None)
|
| 82 |
+
has_static_cache = past_key_values is not None
|
| 83 |
+
|
| 84 |
+
past_length = 0
|
| 85 |
+
if past_key_values is not None:
|
| 86 |
+
if isinstance(past_key_values, Cache):
|
| 87 |
+
past_length = cache_position[0] if cache_position is not None else past_key_values.get_seq_length()
|
| 88 |
+
max_cache_length = (
|
| 89 |
+
torch.tensor(past_key_values.get_max_length(), device=input_ids.device)
|
| 90 |
+
if past_key_values.get_max_length() is not None
|
| 91 |
+
else None
|
| 92 |
+
)
|
| 93 |
+
cache_length = past_length if max_cache_length is None else torch.min(max_cache_length, past_length)
|
| 94 |
+
# TODO joao: remove this `else` after `generate` prioritizes `Cache` objects
|
| 95 |
+
else:
|
| 96 |
+
cache_length = past_length = past_key_values[0][0].shape[2]
|
| 97 |
+
max_cache_length = None
|
| 98 |
+
|
| 99 |
+
# Keep only the unprocessed tokens:
|
| 100 |
+
# 1 - If the length of the attention_mask exceeds the length of input_ids, then we are in a setting where
|
| 101 |
+
# some of the inputs are exclusively passed as part of the cache (e.g. when passing input_embeds as
|
| 102 |
+
# input)
|
| 103 |
+
if attention_mask is not None and attention_mask.shape[1] > input_ids.shape[1]:
|
| 104 |
+
input_ids = input_ids[:, -(attention_mask.shape[1] - past_length) :]
|
| 105 |
+
# 2 - If the past_length is smaller than input_ids', then input_ids holds all input tokens. We can discard
|
| 106 |
+
# input_ids based on the past_length.
|
| 107 |
+
elif past_length < input_ids.shape[1]:
|
| 108 |
+
input_ids = input_ids[:, past_length:]
|
| 109 |
+
# 3 - Otherwise (past_length >= input_ids.shape[1]), let's assume input_ids only has unprocessed tokens.
|
| 110 |
+
|
| 111 |
+
# If we are about to go beyond the maximum cache length, we need to crop the input attention mask.
|
| 112 |
+
if (
|
| 113 |
+
max_cache_length is not None
|
| 114 |
+
and attention_mask is not None
|
| 115 |
+
and cache_length + input_ids.shape[1] > max_cache_length
|
| 116 |
+
):
|
| 117 |
+
attention_mask = attention_mask[:, -max_cache_length:]
|
| 118 |
+
|
| 119 |
+
position_ids = kwargs.get("position_ids", None)
|
| 120 |
+
if attention_mask is not None and position_ids is None:
|
| 121 |
+
# create position_ids on the fly for batch generation
|
| 122 |
+
position_ids = attention_mask.long().cumsum(-1) - 1
|
| 123 |
+
position_ids.masked_fill_(attention_mask == 0, 1)
|
| 124 |
+
if past_key_values:
|
| 125 |
+
position_ids = position_ids[:, -input_ids.shape[1] :]
|
| 126 |
+
|
| 127 |
+
# if `inputs_embeds` are passed, we only want to use them in the 1st generation step
|
| 128 |
+
if inputs_embeds is not None and past_key_values is None:
|
| 129 |
+
model_inputs = {"inputs_embeds": inputs_embeds}
|
| 130 |
+
else:
|
| 131 |
+
# The `contiguous()` here is necessary to have a static stride during decoding. torchdynamo otherwise
|
| 132 |
+
# recompiles graphs as the stride of the inputs is a guard. Ref: https://github.com/huggingface/transformers/pull/29114
|
| 133 |
+
# TODO: use `next_tokens` directly instead.
|
| 134 |
+
model_inputs = {"input_ids": input_ids.contiguous()}
|
| 135 |
+
|
| 136 |
+
input_length = position_ids.shape[-1] if position_ids is not None else input_ids.shape[-1]
|
| 137 |
+
if cache_position is None:
|
| 138 |
+
cache_position = torch.arange(past_length, past_length + input_length, device=input_ids.device)
|
| 139 |
+
else:
|
| 140 |
+
cache_position = cache_position[-input_length:]
|
| 141 |
+
|
| 142 |
+
if has_static_cache:
|
| 143 |
+
past_key_values = None
|
| 144 |
+
|
| 145 |
+
model_inputs.update(
|
| 146 |
+
{
|
| 147 |
+
"position_ids": position_ids,
|
| 148 |
+
"cache_position": cache_position,
|
| 149 |
+
"past_key_values": past_key_values,
|
| 150 |
+
"use_cache": kwargs.get("use_cache"),
|
| 151 |
+
"attention_mask": attention_mask,
|
| 152 |
+
}
|
| 153 |
+
)
|
| 154 |
+
return model_inputs
|
| 155 |
+
|
| 156 |
+
def generate(
|
| 157 |
+
self,
|
| 158 |
+
emb,
|
| 159 |
+
inputs_ids,
|
| 160 |
+
temperature,
|
| 161 |
+
eos_token,
|
| 162 |
+
attention_mask = None,
|
| 163 |
+
max_new_token = 2048,
|
| 164 |
+
min_new_token = 0,
|
| 165 |
+
LogitsWarpers = [],
|
| 166 |
+
LogitsProcessors = [],
|
| 167 |
+
infer_text=False,
|
| 168 |
+
return_attn=False,
|
| 169 |
+
return_hidden=False,
|
| 170 |
+
):
|
| 171 |
+
|
| 172 |
+
with torch.no_grad():
|
| 173 |
+
|
| 174 |
+
attentions = []
|
| 175 |
+
hiddens = []
|
| 176 |
+
|
| 177 |
+
start_idx, end_idx = inputs_ids.shape[1], torch.zeros(inputs_ids.shape[0], device=inputs_ids.device, dtype=torch.long)
|
| 178 |
+
finish = torch.zeros(inputs_ids.shape[0], device=inputs_ids.device).bool()
|
| 179 |
+
|
| 180 |
+
temperature = temperature[None].expand(inputs_ids.shape[0], -1)
|
| 181 |
+
temperature = rearrange(temperature, "b n -> (b n) 1")
|
| 182 |
+
|
| 183 |
+
attention_mask_cache = torch.ones((inputs_ids.shape[0], inputs_ids.shape[1]+max_new_token,), dtype=torch.bool, device=inputs_ids.device)
|
| 184 |
+
if attention_mask is not None:
|
| 185 |
+
attention_mask_cache[:, :attention_mask.shape[1]] = attention_mask
|
| 186 |
+
|
| 187 |
+
for i in tqdm(range(max_new_token)):
|
| 188 |
+
|
| 189 |
+
model_input = self.prepare_inputs_for_generation(inputs_ids,
|
| 190 |
+
outputs.past_key_values if i!=0 else None,
|
| 191 |
+
attention_mask_cache[:, :inputs_ids.shape[1]], use_cache=True)
|
| 192 |
+
|
| 193 |
+
if i == 0:
|
| 194 |
+
model_input['inputs_embeds'] = emb
|
| 195 |
+
else:
|
| 196 |
+
if infer_text:
|
| 197 |
+
model_input['inputs_embeds'] = self.emb_text(model_input['input_ids'][:,:,0])
|
| 198 |
+
else:
|
| 199 |
+
code_emb = [self.emb_code[i](model_input['input_ids'][:,:,i]) for i in range(self.num_vq)]
|
| 200 |
+
model_input['inputs_embeds'] = torch.stack(code_emb, 3).sum(3)
|
| 201 |
+
|
| 202 |
+
model_input['input_ids'] = None
|
| 203 |
+
outputs = self.gpt.forward(**model_input, output_attentions=return_attn)
|
| 204 |
+
attentions.append(outputs.attentions)
|
| 205 |
+
hidden_states = outputs[0] # 🐻
|
| 206 |
+
if return_hidden:
|
| 207 |
+
hiddens.append(hidden_states[:, -1])
|
| 208 |
+
|
| 209 |
+
with P.cached():
|
| 210 |
+
if infer_text:
|
| 211 |
+
logits = self.head_text(hidden_states)
|
| 212 |
+
else:
|
| 213 |
+
logits = torch.stack([self.head_code[i](hidden_states) for i in range(self.num_vq)], 3)
|
| 214 |
+
|
| 215 |
+
logits = logits[:, -1].float()
|
| 216 |
+
|
| 217 |
+
if not infer_text:
|
| 218 |
+
logits = rearrange(logits, "b c n -> (b n) c")
|
| 219 |
+
logits_token = rearrange(inputs_ids[:, start_idx:], "b c n -> (b n) c")
|
| 220 |
+
else:
|
| 221 |
+
logits_token = inputs_ids[:, start_idx:, 0]
|
| 222 |
+
|
| 223 |
+
logits = logits / temperature
|
| 224 |
+
|
| 225 |
+
for logitsProcessors in LogitsProcessors:
|
| 226 |
+
logits = logitsProcessors(logits_token, logits)
|
| 227 |
+
|
| 228 |
+
for logitsWarpers in LogitsWarpers:
|
| 229 |
+
logits = logitsWarpers(logits_token, logits)
|
| 230 |
+
|
| 231 |
+
if i < min_new_token:
|
| 232 |
+
logits[:, eos_token] = -torch.inf
|
| 233 |
+
|
| 234 |
+
scores = F.softmax(logits, dim=-1)
|
| 235 |
+
|
| 236 |
+
idx_next = torch.multinomial(scores, num_samples=1)
|
| 237 |
+
|
| 238 |
+
if not infer_text:
|
| 239 |
+
idx_next = rearrange(idx_next, "(b n) 1 -> b n", n=self.num_vq)
|
| 240 |
+
finish = finish | (idx_next == eos_token).any(1)
|
| 241 |
+
inputs_ids = torch.cat([inputs_ids, idx_next.unsqueeze(1)], 1)
|
| 242 |
+
else:
|
| 243 |
+
finish = finish | (idx_next == eos_token).any(1)
|
| 244 |
+
inputs_ids = torch.cat([inputs_ids, idx_next.unsqueeze(-1).expand(-1, -1, self.num_vq)], 1)
|
| 245 |
+
|
| 246 |
+
end_idx = end_idx + (~finish).int()
|
| 247 |
+
|
| 248 |
+
if finish.all():
|
| 249 |
+
break
|
| 250 |
+
|
| 251 |
+
inputs_ids = [inputs_ids[idx, start_idx: start_idx+i] for idx, i in enumerate(end_idx.int())]
|
| 252 |
+
inputs_ids = [i[:, 0] for i in inputs_ids] if infer_text else inputs_ids
|
| 253 |
+
|
| 254 |
+
if return_hidden:
|
| 255 |
+
hiddens = torch.stack(hiddens, 1)
|
| 256 |
+
hiddens = [hiddens[idx, :i] for idx, i in enumerate(end_idx.int())]
|
| 257 |
+
|
| 258 |
+
if not finish.all():
|
| 259 |
+
self.logger.warn(f'Incomplete result. hit max_new_token: {max_new_token}')
|
| 260 |
+
|
| 261 |
+
return {
|
| 262 |
+
'ids': inputs_ids,
|
| 263 |
+
'attentions': attentions,
|
| 264 |
+
'hiddens':hiddens,
|
| 265 |
+
}
|
ChatTTS/ChatTTS/utils/gpu_utils.py
ADDED
|
@@ -0,0 +1,23 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
|
| 2 |
+
import torch
|
| 3 |
+
import logging
|
| 4 |
+
|
| 5 |
+
def select_device(min_memory = 2048):
|
| 6 |
+
logger = logging.getLogger(__name__)
|
| 7 |
+
if torch.cuda.is_available():
|
| 8 |
+
available_gpus = []
|
| 9 |
+
for i in range(torch.cuda.device_count()):
|
| 10 |
+
props = torch.cuda.get_device_properties(i)
|
| 11 |
+
free_memory = props.total_memory - torch.cuda.memory_reserved(i)
|
| 12 |
+
available_gpus.append((i, free_memory))
|
| 13 |
+
selected_gpu, max_free_memory = max(available_gpus, key=lambda x: x[1])
|
| 14 |
+
device = torch.device(f'cuda:{selected_gpu}')
|
| 15 |
+
free_memory_mb = max_free_memory / (1024 * 1024)
|
| 16 |
+
if free_memory_mb < min_memory:
|
| 17 |
+
logger.log(logging.WARNING, f'GPU {selected_gpu} has {round(free_memory_mb, 2)} MB memory left.')
|
| 18 |
+
device = torch.device('cpu')
|
| 19 |
+
else:
|
| 20 |
+
logger.log(logging.WARNING, f'No GPU found, use CPU instead')
|
| 21 |
+
device = torch.device('cpu')
|
| 22 |
+
|
| 23 |
+
return device
|
ChatTTS/ChatTTS/utils/infer_utils.py
ADDED
|
@@ -0,0 +1,141 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
|
| 2 |
+
import re
|
| 3 |
+
import torch
|
| 4 |
+
import torch.nn.functional as F
|
| 5 |
+
|
| 6 |
+
|
| 7 |
+
class CustomRepetitionPenaltyLogitsProcessorRepeat():
|
| 8 |
+
|
| 9 |
+
def __init__(self, penalty: float, max_input_ids, past_window):
|
| 10 |
+
if not isinstance(penalty, float) or not (penalty > 0):
|
| 11 |
+
raise ValueError(f"`penalty` has to be a strictly positive float, but is {penalty}")
|
| 12 |
+
|
| 13 |
+
self.penalty = penalty
|
| 14 |
+
self.max_input_ids = max_input_ids
|
| 15 |
+
self.past_window = past_window
|
| 16 |
+
|
| 17 |
+
def __call__(self, input_ids: torch.LongTensor, scores: torch.FloatTensor) -> torch.FloatTensor:
|
| 18 |
+
|
| 19 |
+
input_ids = input_ids[:, -self.past_window:]
|
| 20 |
+
freq = F.one_hot(input_ids, scores.size(1)).sum(1)
|
| 21 |
+
freq[self.max_input_ids:] = 0
|
| 22 |
+
alpha = self.penalty**freq
|
| 23 |
+
scores = torch.where(scores < 0, scores*alpha, scores/alpha)
|
| 24 |
+
|
| 25 |
+
return scores
|
| 26 |
+
|
| 27 |
+
class CustomRepetitionPenaltyLogitsProcessor():
|
| 28 |
+
|
| 29 |
+
def __init__(self, penalty: float, max_input_ids, past_window):
|
| 30 |
+
if not isinstance(penalty, float) or not (penalty > 0):
|
| 31 |
+
raise ValueError(f"`penalty` has to be a strictly positive float, but is {penalty}")
|
| 32 |
+
|
| 33 |
+
self.penalty = penalty
|
| 34 |
+
self.max_input_ids = max_input_ids
|
| 35 |
+
self.past_window = past_window
|
| 36 |
+
|
| 37 |
+
def __call__(self, input_ids: torch.LongTensor, scores: torch.FloatTensor) -> torch.FloatTensor:
|
| 38 |
+
|
| 39 |
+
input_ids = input_ids[:, -self.past_window:]
|
| 40 |
+
score = torch.gather(scores, 1, input_ids)
|
| 41 |
+
_score = score.detach().clone()
|
| 42 |
+
score = torch.where(score < 0, score * self.penalty, score / self.penalty)
|
| 43 |
+
score[input_ids>=self.max_input_ids] = _score[input_ids>=self.max_input_ids]
|
| 44 |
+
scores.scatter_(1, input_ids, score)
|
| 45 |
+
|
| 46 |
+
return scores
|
| 47 |
+
|
| 48 |
+
def count_invalid_characters(s):
|
| 49 |
+
|
| 50 |
+
s = re.sub(r'\[uv_break\]|\[laugh\]|\[lbreak\]', '', s)
|
| 51 |
+
pattern = re.compile(r'[^\u4e00-\u9fffA-Za-z,。、,\. ]')
|
| 52 |
+
non_alphabetic_chinese_chars = pattern.findall(s)
|
| 53 |
+
return set(non_alphabetic_chinese_chars)
|
| 54 |
+
|
| 55 |
+
def detect_language(sentence):
|
| 56 |
+
|
| 57 |
+
chinese_char_pattern = re.compile(r'[\u4e00-\u9fff]')
|
| 58 |
+
english_word_pattern = re.compile(r'\b[A-Za-z]+\b')
|
| 59 |
+
|
| 60 |
+
chinese_chars = chinese_char_pattern.findall(sentence)
|
| 61 |
+
english_words = english_word_pattern.findall(sentence)
|
| 62 |
+
|
| 63 |
+
if len(chinese_chars) > len(english_words):
|
| 64 |
+
return "zh"
|
| 65 |
+
else:
|
| 66 |
+
return "en"
|
| 67 |
+
|
| 68 |
+
|
| 69 |
+
character_map = {
|
| 70 |
+
':': ',',
|
| 71 |
+
';': ',',
|
| 72 |
+
'!': '。',
|
| 73 |
+
'(': ',',
|
| 74 |
+
')': ',',
|
| 75 |
+
'【': ',',
|
| 76 |
+
'】': ',',
|
| 77 |
+
'『': ',',
|
| 78 |
+
'』': ',',
|
| 79 |
+
'「': ',',
|
| 80 |
+
'」': ',',
|
| 81 |
+
'《': ',',
|
| 82 |
+
'》': ',',
|
| 83 |
+
'-': ',',
|
| 84 |
+
'‘': '',
|
| 85 |
+
'“': '',
|
| 86 |
+
'’': '',
|
| 87 |
+
'”': '',
|
| 88 |
+
':': ',',
|
| 89 |
+
';': ',',
|
| 90 |
+
'!': '.',
|
| 91 |
+
'(': ',',
|
| 92 |
+
')': ',',
|
| 93 |
+
'[': ',',
|
| 94 |
+
']': ',',
|
| 95 |
+
'>': ',',
|
| 96 |
+
'<': ',',
|
| 97 |
+
'-': ',',
|
| 98 |
+
}
|
| 99 |
+
|
| 100 |
+
halfwidth_2_fullwidth_map = {
|
| 101 |
+
'!': '!',
|
| 102 |
+
'"': '“',
|
| 103 |
+
"'": '‘',
|
| 104 |
+
'#': '#',
|
| 105 |
+
'$': '$',
|
| 106 |
+
'%': '%',
|
| 107 |
+
'&': '&',
|
| 108 |
+
'(': '(',
|
| 109 |
+
')': ')',
|
| 110 |
+
',': ',',
|
| 111 |
+
'-': '-',
|
| 112 |
+
'*': '*',
|
| 113 |
+
'+': '+',
|
| 114 |
+
'.': '。',
|
| 115 |
+
'/': '/',
|
| 116 |
+
':': ':',
|
| 117 |
+
';': ';',
|
| 118 |
+
'<': '<',
|
| 119 |
+
'=': '=',
|
| 120 |
+
'>': '>',
|
| 121 |
+
'?': '?',
|
| 122 |
+
'@': '@',
|
| 123 |
+
# '[': '[',
|
| 124 |
+
'\\': '\',
|
| 125 |
+
# ']': ']',
|
| 126 |
+
'^': '^',
|
| 127 |
+
# '_': '_',
|
| 128 |
+
'`': '`',
|
| 129 |
+
'{': '{',
|
| 130 |
+
'|': '|',
|
| 131 |
+
'}': '}',
|
| 132 |
+
'~': '~'
|
| 133 |
+
}
|
| 134 |
+
|
| 135 |
+
def apply_half2full_map(text):
|
| 136 |
+
translation_table = str.maketrans(halfwidth_2_fullwidth_map)
|
| 137 |
+
return text.translate(translation_table)
|
| 138 |
+
|
| 139 |
+
def apply_character_map(text):
|
| 140 |
+
translation_table = str.maketrans(character_map)
|
| 141 |
+
return text.translate(translation_table)
|
ChatTTS/ChatTTS/utils/io_utils.py
ADDED
|
@@ -0,0 +1,14 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
|
| 2 |
+
import os
|
| 3 |
+
import logging
|
| 4 |
+
|
| 5 |
+
def get_latest_modified_file(directory):
|
| 6 |
+
logger = logging.getLogger(__name__)
|
| 7 |
+
|
| 8 |
+
files = [os.path.join(directory, f) for f in os.listdir(directory)]
|
| 9 |
+
if not files:
|
| 10 |
+
logger.log(logging.WARNING, f'No files found in the directory: {directory}')
|
| 11 |
+
return None
|
| 12 |
+
latest_file = max(files, key=os.path.getmtime)
|
| 13 |
+
|
| 14 |
+
return latest_file
|
ChatTTS/LICENSE
ADDED
|
@@ -0,0 +1,407 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Attribution-NonCommercial 4.0 International
|
| 2 |
+
|
| 3 |
+
=======================================================================
|
| 4 |
+
|
| 5 |
+
Creative Commons Corporation ("Creative Commons") is not a law firm and
|
| 6 |
+
does not provide legal services or legal advice. Distribution of
|
| 7 |
+
Creative Commons public licenses does not create a lawyer-client or
|
| 8 |
+
other relationship. Creative Commons makes its licenses and related
|
| 9 |
+
information available on an "as-is" basis. Creative Commons gives no
|
| 10 |
+
warranties regarding its licenses, any material licensed under their
|
| 11 |
+
terms and conditions, or any related information. Creative Commons
|
| 12 |
+
disclaims all liability for damages resulting from their use to the
|
| 13 |
+
fullest extent possible.
|
| 14 |
+
|
| 15 |
+
Using Creative Commons Public Licenses
|
| 16 |
+
|
| 17 |
+
Creative Commons public licenses provide a standard set of terms and
|
| 18 |
+
conditions that creators and other rights holders may use to share
|
| 19 |
+
original works of authorship and other material subject to copyright
|
| 20 |
+
and certain other rights specified in the public license below. The
|
| 21 |
+
following considerations are for informational purposes only, are not
|
| 22 |
+
exhaustive, and do not form part of our licenses.
|
| 23 |
+
|
| 24 |
+
Considerations for licensors: Our public licenses are
|
| 25 |
+
intended for use by those authorized to give the public
|
| 26 |
+
permission to use material in ways otherwise restricted by
|
| 27 |
+
copyright and certain other rights. Our licenses are
|
| 28 |
+
irrevocable. Licensors should read and understand the terms
|
| 29 |
+
and conditions of the license they choose before applying it.
|
| 30 |
+
Licensors should also secure all rights necessary before
|
| 31 |
+
applying our licenses so that the public can reuse the
|
| 32 |
+
material as expected. Licensors should clearly mark any
|
| 33 |
+
material not subject to the license. This includes other CC-
|
| 34 |
+
licensed material, or material used under an exception or
|
| 35 |
+
limitation to copyright. More considerations for licensors:
|
| 36 |
+
wiki.creativecommons.org/Considerations_for_licensors
|
| 37 |
+
|
| 38 |
+
Considerations for the public: By using one of our public
|
| 39 |
+
licenses, a licensor grants the public permission to use the
|
| 40 |
+
licensed material under specified terms and conditions. If
|
| 41 |
+
the licensor's permission is not necessary for any reason--for
|
| 42 |
+
example, because of any applicable exception or limitation to
|
| 43 |
+
copyright--then that use is not regulated by the license. Our
|
| 44 |
+
licenses grant only permissions under copyright and certain
|
| 45 |
+
other rights that a licensor has authority to grant. Use of
|
| 46 |
+
the licensed material may still be restricted for other
|
| 47 |
+
reasons, including because others have copyright or other
|
| 48 |
+
rights in the material. A licensor may make special requests,
|
| 49 |
+
such as asking that all changes be marked or described.
|
| 50 |
+
Although not required by our licenses, you are encouraged to
|
| 51 |
+
respect those requests where reasonable. More considerations
|
| 52 |
+
for the public:
|
| 53 |
+
wiki.creativecommons.org/Considerations_for_licensees
|
| 54 |
+
|
| 55 |
+
=======================================================================
|
| 56 |
+
|
| 57 |
+
Creative Commons Attribution-NonCommercial 4.0 International Public
|
| 58 |
+
License
|
| 59 |
+
|
| 60 |
+
By exercising the Licensed Rights (defined below), You accept and agree
|
| 61 |
+
to be bound by the terms and conditions of this Creative Commons
|
| 62 |
+
Attribution-NonCommercial 4.0 International Public License ("Public
|
| 63 |
+
License"). To the extent this Public License may be interpreted as a
|
| 64 |
+
contract, You are granted the Licensed Rights in consideration of Your
|
| 65 |
+
acceptance of these terms and conditions, and the Licensor grants You
|
| 66 |
+
such rights in consideration of benefits the Licensor receives from
|
| 67 |
+
making the Licensed Material available under these terms and
|
| 68 |
+
conditions.
|
| 69 |
+
|
| 70 |
+
|
| 71 |
+
Section 1 -- Definitions.
|
| 72 |
+
|
| 73 |
+
a. Adapted Material means material subject to Copyright and Similar
|
| 74 |
+
Rights that is derived from or based upon the Licensed Material
|
| 75 |
+
and in which the Licensed Material is translated, altered,
|
| 76 |
+
arranged, transformed, or otherwise modified in a manner requiring
|
| 77 |
+
permission under the Copyright and Similar Rights held by the
|
| 78 |
+
Licensor. For purposes of this Public License, where the Licensed
|
| 79 |
+
Material is a musical work, performance, or sound recording,
|
| 80 |
+
Adapted Material is always produced where the Licensed Material is
|
| 81 |
+
synched in timed relation with a moving image.
|
| 82 |
+
|
| 83 |
+
b. Adapter's License means the license You apply to Your Copyright
|
| 84 |
+
and Similar Rights in Your contributions to Adapted Material in
|
| 85 |
+
accordance with the terms and conditions of this Public License.
|
| 86 |
+
|
| 87 |
+
c. Copyright and Similar Rights means copyright and/or similar rights
|
| 88 |
+
closely related to copyright including, without limitation,
|
| 89 |
+
performance, broadcast, sound recording, and Sui Generis Database
|
| 90 |
+
Rights, without regard to how the rights are labeled or
|
| 91 |
+
categorized. For purposes of this Public License, the rights
|
| 92 |
+
specified in Section 2(b)(1)-(2) are not Copyright and Similar
|
| 93 |
+
Rights.
|
| 94 |
+
d. Effective Technological Measures means those measures that, in the
|
| 95 |
+
absence of proper authority, may not be circumvented under laws
|
| 96 |
+
fulfilling obligations under Article 11 of the WIPO Copyright
|
| 97 |
+
Treaty adopted on December 20, 1996, and/or similar international
|
| 98 |
+
agreements.
|
| 99 |
+
|
| 100 |
+
e. Exceptions and Limitations means fair use, fair dealing, and/or
|
| 101 |
+
any other exception or limitation to Copyright and Similar Rights
|
| 102 |
+
that applies to Your use of the Licensed Material.
|
| 103 |
+
|
| 104 |
+
f. Licensed Material means the artistic or literary work, database,
|
| 105 |
+
or other material to which the Licensor applied this Public
|
| 106 |
+
License.
|
| 107 |
+
|
| 108 |
+
g. Licensed Rights means the rights granted to You subject to the
|
| 109 |
+
terms and conditions of this Public License, which are limited to
|
| 110 |
+
all Copyright and Similar Rights that apply to Your use of the
|
| 111 |
+
Licensed Material and that the Licensor has authority to license.
|
| 112 |
+
|
| 113 |
+
h. Licensor means the individual(s) or entity(ies) granting rights
|
| 114 |
+
under this Public License.
|
| 115 |
+
|
| 116 |
+
i. NonCommercial means not primarily intended for or directed towards
|
| 117 |
+
commercial advantage or monetary compensation. For purposes of
|
| 118 |
+
this Public License, the exchange of the Licensed Material for
|
| 119 |
+
other material subject to Copyright and Similar Rights by digital
|
| 120 |
+
file-sharing or similar means is NonCommercial provided there is
|
| 121 |
+
no payment of monetary compensation in connection with the
|
| 122 |
+
exchange.
|
| 123 |
+
|
| 124 |
+
j. Share means to provide material to the public by any means or
|
| 125 |
+
process that requires permission under the Licensed Rights, such
|
| 126 |
+
as reproduction, public display, public performance, distribution,
|
| 127 |
+
dissemination, communication, or importation, and to make material
|
| 128 |
+
available to the public including in ways that members of the
|
| 129 |
+
public may access the material from a place and at a time
|
| 130 |
+
individually chosen by them.
|
| 131 |
+
|
| 132 |
+
k. Sui Generis Database Rights means rights other than copyright
|
| 133 |
+
resulting from Directive 96/9/EC of the European Parliament and of
|
| 134 |
+
the Council of 11 March 1996 on the legal protection of databases,
|
| 135 |
+
as amended and/or succeeded, as well as other essentially
|
| 136 |
+
equivalent rights anywhere in the world.
|
| 137 |
+
|
| 138 |
+
l. You means the individual or entity exercising the Licensed Rights
|
| 139 |
+
under this Public License. Your has a corresponding meaning.
|
| 140 |
+
|
| 141 |
+
|
| 142 |
+
Section 2 -- Scope.
|
| 143 |
+
|
| 144 |
+
a. License grant.
|
| 145 |
+
|
| 146 |
+
1. Subject to the terms and conditions of this Public License,
|
| 147 |
+
the Licensor hereby grants You a worldwide, royalty-free,
|
| 148 |
+
non-sublicensable, non-exclusive, irrevocable license to
|
| 149 |
+
exercise the Licensed Rights in the Licensed Material to:
|
| 150 |
+
|
| 151 |
+
a. reproduce and Share the Licensed Material, in whole or
|
| 152 |
+
in part, for NonCommercial purposes only; and
|
| 153 |
+
|
| 154 |
+
b. produce, reproduce, and Share Adapted Material for
|
| 155 |
+
NonCommercial purposes only.
|
| 156 |
+
|
| 157 |
+
2. Exceptions and Limitations. For the avoidance of doubt, where
|
| 158 |
+
Exceptions and Limitations apply to Your use, this Public
|
| 159 |
+
License does not apply, and You do not need to comply with
|
| 160 |
+
its terms and conditions.
|
| 161 |
+
|
| 162 |
+
3. Term. The term of this Public License is specified in Section
|
| 163 |
+
6(a).
|
| 164 |
+
|
| 165 |
+
4. Media and formats; technical modifications allowed. The
|
| 166 |
+
Licensor authorizes You to exercise the Licensed Rights in
|
| 167 |
+
all media and formats whether now known or hereafter created,
|
| 168 |
+
and to make technical modifications necessary to do so. The
|
| 169 |
+
Licensor waives and/or agrees not to assert any right or
|
| 170 |
+
authority to forbid You from making technical modifications
|
| 171 |
+
necessary to exercise the Licensed Rights, including
|
| 172 |
+
technical modifications necessary to circumvent Effective
|
| 173 |
+
Technological Measures. For purposes of this Public License,
|
| 174 |
+
simply making modifications authorized by this Section 2(a)
|
| 175 |
+
(4) never produces Adapted Material.
|
| 176 |
+
|
| 177 |
+
5. Downstream recipients.
|
| 178 |
+
|
| 179 |
+
a. Offer from the Licensor -- Licensed Material. Every
|
| 180 |
+
recipient of the Licensed Material automatically
|
| 181 |
+
receives an offer from the Licensor to exercise the
|
| 182 |
+
Licensed Rights under the terms and conditions of this
|
| 183 |
+
Public License.
|
| 184 |
+
|
| 185 |
+
b. No downstream restrictions. You may not offer or impose
|
| 186 |
+
any additional or different terms or conditions on, or
|
| 187 |
+
apply any Effective Technological Measures to, the
|
| 188 |
+
Licensed Material if doing so restricts exercise of the
|
| 189 |
+
Licensed Rights by any recipient of the Licensed
|
| 190 |
+
Material.
|
| 191 |
+
|
| 192 |
+
6. No endorsement. Nothing in this Public License constitutes or
|
| 193 |
+
may be construed as permission to assert or imply that You
|
| 194 |
+
are, or that Your use of the Licensed Material is, connected
|
| 195 |
+
with, or sponsored, endorsed, or granted official status by,
|
| 196 |
+
the Licensor or others designated to receive attribution as
|
| 197 |
+
provided in Section 3(a)(1)(A)(i).
|
| 198 |
+
|
| 199 |
+
b. Other rights.
|
| 200 |
+
|
| 201 |
+
1. Moral rights, such as the right of integrity, are not
|
| 202 |
+
licensed under this Public License, nor are publicity,
|
| 203 |
+
privacy, and/or other similar personality rights; however, to
|
| 204 |
+
the extent possible, the Licensor waives and/or agrees not to
|
| 205 |
+
assert any such rights held by the Licensor to the limited
|
| 206 |
+
extent necessary to allow You to exercise the Licensed
|
| 207 |
+
Rights, but not otherwise.
|
| 208 |
+
|
| 209 |
+
2. Patent and trademark rights are not licensed under this
|
| 210 |
+
Public License.
|
| 211 |
+
|
| 212 |
+
3. To the extent possible, the Licensor waives any right to
|
| 213 |
+
collect royalties from You for the exercise of the Licensed
|
| 214 |
+
Rights, whether directly or through a collecting society
|
| 215 |
+
under any voluntary or waivable statutory or compulsory
|
| 216 |
+
licensing scheme. In all other cases the Licensor expressly
|
| 217 |
+
reserves any right to collect such royalties, including when
|
| 218 |
+
the Licensed Material is used other than for NonCommercial
|
| 219 |
+
purposes.
|
| 220 |
+
|
| 221 |
+
|
| 222 |
+
Section 3 -- License Conditions.
|
| 223 |
+
|
| 224 |
+
Your exercise of the Licensed Rights is expressly made subject to the
|
| 225 |
+
following conditions.
|
| 226 |
+
|
| 227 |
+
a. Attribution.
|
| 228 |
+
|
| 229 |
+
1. If You Share the Licensed Material (including in modified
|
| 230 |
+
form), You must:
|
| 231 |
+
|
| 232 |
+
a. retain the following if it is supplied by the Licensor
|
| 233 |
+
with the Licensed Material:
|
| 234 |
+
|
| 235 |
+
i. identification of the creator(s) of the Licensed
|
| 236 |
+
Material and any others designated to receive
|
| 237 |
+
attribution, in any reasonable manner requested by
|
| 238 |
+
the Licensor (including by pseudonym if
|
| 239 |
+
designated);
|
| 240 |
+
|
| 241 |
+
ii. a copyright notice;
|
| 242 |
+
|
| 243 |
+
iii. a notice that refers to this Public License;
|
| 244 |
+
|
| 245 |
+
iv. a notice that refers to the disclaimer of
|
| 246 |
+
warranties;
|
| 247 |
+
|
| 248 |
+
v. a URI or hyperlink to the Licensed Material to the
|
| 249 |
+
extent reasonably practicable;
|
| 250 |
+
|
| 251 |
+
b. indicate if You modified the Licensed Material and
|
| 252 |
+
retain an indication of any previous modifications; and
|
| 253 |
+
|
| 254 |
+
c. indicate the Licensed Material is licensed under this
|
| 255 |
+
Public License, and include the text of, or the URI or
|
| 256 |
+
hyperlink to, this Public License.
|
| 257 |
+
|
| 258 |
+
2. You may satisfy the conditions in Section 3(a)(1) in any
|
| 259 |
+
reasonable manner based on the medium, means, and context in
|
| 260 |
+
which You Share the Licensed Material. For example, it may be
|
| 261 |
+
reasonable to satisfy the conditions by providing a URI or
|
| 262 |
+
hyperlink to a resource that includes the required
|
| 263 |
+
information.
|
| 264 |
+
|
| 265 |
+
3. If requested by the Licensor, You must remove any of the
|
| 266 |
+
information required by Section 3(a)(1)(A) to the extent
|
| 267 |
+
reasonably practicable.
|
| 268 |
+
|
| 269 |
+
4. If You Share Adapted Material You produce, the Adapter's
|
| 270 |
+
License You apply must not prevent recipients of the Adapted
|
| 271 |
+
Material from complying with this Public License.
|
| 272 |
+
|
| 273 |
+
|
| 274 |
+
Section 4 -- Sui Generis Database Rights.
|
| 275 |
+
|
| 276 |
+
Where the Licensed Rights include Sui Generis Database Rights that
|
| 277 |
+
apply to Your use of the Licensed Material:
|
| 278 |
+
|
| 279 |
+
a. for the avoidance of doubt, Section 2(a)(1) grants You the right
|
| 280 |
+
to extract, reuse, reproduce, and Share all or a substantial
|
| 281 |
+
portion of the contents of the database for NonCommercial purposes
|
| 282 |
+
only;
|
| 283 |
+
|
| 284 |
+
b. if You include all or a substantial portion of the database
|
| 285 |
+
contents in a database in which You have Sui Generis Database
|
| 286 |
+
Rights, then the database in which You have Sui Generis Database
|
| 287 |
+
Rights (but not its individual contents) is Adapted Material; and
|
| 288 |
+
|
| 289 |
+
c. You must comply with the conditions in Section 3(a) if You Share
|
| 290 |
+
all or a substantial portion of the contents of the database.
|
| 291 |
+
|
| 292 |
+
For the avoidance of doubt, this Section 4 supplements and does not
|
| 293 |
+
replace Your obligations under this Public License where the Licensed
|
| 294 |
+
Rights include other Copyright and Similar Rights.
|
| 295 |
+
|
| 296 |
+
|
| 297 |
+
Section 5 -- Disclaimer of Warranties and Limitation of Liability.
|
| 298 |
+
|
| 299 |
+
a. UNLESS OTHERWISE SEPARATELY UNDERTAKEN BY THE LICENSOR, TO THE
|
| 300 |
+
EXTENT POSSIBLE, THE LICENSOR OFFERS THE LICENSED MATERIAL AS-IS
|
| 301 |
+
AND AS-AVAILABLE, AND MAKES NO REPRESENTATIONS OR WARRANTIES OF
|
| 302 |
+
ANY KIND CONCERNING THE LICENSED MATERIAL, WHETHER EXPRESS,
|
| 303 |
+
IMPLIED, STATUTORY, OR OTHER. THIS INCLUDES, WITHOUT LIMITATION,
|
| 304 |
+
WARRANTIES OF TITLE, MERCHANTABILITY, FITNESS FOR A PARTICULAR
|
| 305 |
+
PURPOSE, NON-INFRINGEMENT, ABSENCE OF LATENT OR OTHER DEFECTS,
|
| 306 |
+
ACCURACY, OR THE PRESENCE OR ABSENCE OF ERRORS, WHETHER OR NOT
|
| 307 |
+
KNOWN OR DISCOVERABLE. WHERE DISCLAIMERS OF WARRANTIES ARE NOT
|
| 308 |
+
ALLOWED IN FULL OR IN PART, THIS DISCLAIMER MAY NOT APPLY TO YOU.
|
| 309 |
+
|
| 310 |
+
b. TO THE EXTENT POSSIBLE, IN NO EVENT WILL THE LICENSOR BE LIABLE
|
| 311 |
+
TO YOU ON ANY LEGAL THEORY (INCLUDING, WITHOUT LIMITATION,
|
| 312 |
+
NEGLIGENCE) OR OTHERWISE FOR ANY DIRECT, SPECIAL, INDIRECT,
|
| 313 |
+
INCIDENTAL, CONSEQUENTIAL, PUNITIVE, EXEMPLARY, OR OTHER LOSSES,
|
| 314 |
+
COSTS, EXPENSES, OR DAMAGES ARISING OUT OF THIS PUBLIC LICENSE OR
|
| 315 |
+
USE OF THE LICENSED MATERIAL, EVEN IF THE LICENSOR HAS BEEN
|
| 316 |
+
ADVISED OF THE POSSIBILITY OF SUCH LOSSES, COSTS, EXPENSES, OR
|
| 317 |
+
DAMAGES. WHERE A LIMITATION OF LIABILITY IS NOT ALLOWED IN FULL OR
|
| 318 |
+
IN PART, THIS LIMITATION MAY NOT APPLY TO YOU.
|
| 319 |
+
|
| 320 |
+
c. The disclaimer of warranties and limitation of liability provided
|
| 321 |
+
above shall be interpreted in a manner that, to the extent
|
| 322 |
+
possible, most closely approximates an absolute disclaimer and
|
| 323 |
+
waiver of all liability.
|
| 324 |
+
|
| 325 |
+
|
| 326 |
+
Section 6 -- Term and Termination.
|
| 327 |
+
|
| 328 |
+
a. This Public License applies for the term of the Copyright and
|
| 329 |
+
Similar Rights licensed here. However, if You fail to comply with
|
| 330 |
+
this Public License, then Your rights under this Public License
|
| 331 |
+
terminate automatically.
|
| 332 |
+
|
| 333 |
+
b. Where Your right to use the Licensed Material has terminated under
|
| 334 |
+
Section 6(a), it reinstates:
|
| 335 |
+
|
| 336 |
+
1. automatically as of the date the violation is cured, provided
|
| 337 |
+
it is cured within 30 days of Your discovery of the
|
| 338 |
+
violation; or
|
| 339 |
+
|
| 340 |
+
2. upon express reinstatement by the Licensor.
|
| 341 |
+
|
| 342 |
+
For the avoidance of doubt, this Section 6(b) does not affect any
|
| 343 |
+
right the Licensor may have to seek remedies for Your violations
|
| 344 |
+
of this Public License.
|
| 345 |
+
|
| 346 |
+
c. For the avoidance of doubt, the Licensor may also offer the
|
| 347 |
+
Licensed Material under separate terms or conditions or stop
|
| 348 |
+
distributing the Licensed Material at any time; however, doing so
|
| 349 |
+
will not terminate this Public License.
|
| 350 |
+
|
| 351 |
+
d. Sections 1, 5, 6, 7, and 8 survive termination of this Public
|
| 352 |
+
License.
|
| 353 |
+
|
| 354 |
+
|
| 355 |
+
Section 7 -- Other Terms and Conditions.
|
| 356 |
+
|
| 357 |
+
a. The Licensor shall not be bound by any additional or different
|
| 358 |
+
terms or conditions communicated by You unless expressly agreed.
|
| 359 |
+
|
| 360 |
+
b. Any arrangements, understandings, or agreements regarding the
|
| 361 |
+
Licensed Material not stated herein are separate from and
|
| 362 |
+
independent of the terms and conditions of this Public License.
|
| 363 |
+
|
| 364 |
+
|
| 365 |
+
Section 8 -- Interpretation.
|
| 366 |
+
|
| 367 |
+
a. For the avoidance of doubt, this Public License does not, and
|
| 368 |
+
shall not be interpreted to, reduce, limit, restrict, or impose
|
| 369 |
+
conditions on any use of the Licensed Material that could lawfully
|
| 370 |
+
be made without permission under this Public License.
|
| 371 |
+
|
| 372 |
+
b. To the extent possible, if any provision of this Public License is
|
| 373 |
+
deemed unenforceable, it shall be automatically reformed to the
|
| 374 |
+
minimum extent necessary to make it enforceable. If the provision
|
| 375 |
+
cannot be reformed, it shall be severed from this Public License
|
| 376 |
+
without affecting the enforceability of the remaining terms and
|
| 377 |
+
conditions.
|
| 378 |
+
|
| 379 |
+
c. No term or condition of this Public License will be waived and no
|
| 380 |
+
failure to comply consented to unless expressly agreed to by the
|
| 381 |
+
Licensor.
|
| 382 |
+
|
| 383 |
+
d. Nothing in this Public License constitutes or may be interpreted
|
| 384 |
+
as a limitation upon, or waiver of, any privileges and immunities
|
| 385 |
+
that apply to the Licensor or You, including from the legal
|
| 386 |
+
processes of any jurisdiction or authority.
|
| 387 |
+
|
| 388 |
+
=======================================================================
|
| 389 |
+
|
| 390 |
+
Creative Commons is not a party to its public
|
| 391 |
+
licenses. Notwithstanding, Creative Commons may elect to apply one of
|
| 392 |
+
its public licenses to material it publishes and in those instances
|
| 393 |
+
will be considered the “Licensor.” The text of the Creative Commons
|
| 394 |
+
public licenses is dedicated to the public domain under the CC0 Public
|
| 395 |
+
Domain Dedication. Except for the limited purpose of indicating that
|
| 396 |
+
material is shared under a Creative Commons public license or as
|
| 397 |
+
otherwise permitted by the Creative Commons policies published at
|
| 398 |
+
creativecommons.org/policies, Creative Commons does not authorize the
|
| 399 |
+
use of the trademark "Creative Commons" or any other trademark or logo
|
| 400 |
+
of Creative Commons without its prior written consent including,
|
| 401 |
+
without limitation, in connection with any unauthorized modifications
|
| 402 |
+
to any of its public licenses or any other arrangements,
|
| 403 |
+
understandings, or agreements concerning use of licensed material. For
|
| 404 |
+
the avoidance of doubt, this paragraph does not form part of the
|
| 405 |
+
public licenses.
|
| 406 |
+
|
| 407 |
+
Creative Commons may be contacted at creativecommons.org.
|
ChatTTS/README.md
ADDED
|
@@ -0,0 +1,132 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# ChatTTS
|
| 2 |
+
[**English**](./README.md) | [**中文简体**](./README_CN.md)
|
| 3 |
+
|
| 4 |
+
ChatTTS is a text-to-speech model designed specifically for dialogue scenario such as LLM assistant. It supports both English and Chinese languages. Our model is trained with 100,000+ hours composed of chinese and english. The open-source version on **[HuggingFace](https://huggingface.co/2Noise/ChatTTS)** is a 40,000 hours pre trained model without SFT.
|
| 5 |
+
|
| 6 |
+
For formal inquiries about model and roadmap, please contact us at **open-source@2noise.com**. You could join our QQ group: ~~808364215 (Full)~~ 230696694 (Group 2) for discussion. Adding github issues is always welcomed.
|
| 7 |
+
|
| 8 |
+
---
|
| 9 |
+
## Highlights
|
| 10 |
+
1. **Conversational TTS**: ChatTTS is optimized for dialogue-based tasks, enabling natural and expressive speech synthesis. It supports multiple speakers, facilitating interactive conversations.
|
| 11 |
+
2. **Fine-grained Control**: The model could predict and control fine-grained prosodic features, including laughter, pauses, and interjections.
|
| 12 |
+
3. **Better Prosody**: ChatTTS surpasses most of open-source TTS models in terms of prosody. We provide pretrained models to support further research and development.
|
| 13 |
+
|
| 14 |
+
For the detailed description of the model, you can refer to **[video on Bilibili](https://www.bilibili.com/video/BV1zn4y1o7iV)**
|
| 15 |
+
|
| 16 |
+
---
|
| 17 |
+
|
| 18 |
+
## Disclaimer
|
| 19 |
+
|
| 20 |
+
This repo is for academic purposes only. It is intended for educational and research use, and should not be used for any commercial or legal purposes. The authors do not guarantee the accuracy, completeness, or reliability of the information. The information and data used in this repo, are for academic and research purposes only. The data obtained from publicly available sources, and the authors do not claim any ownership or copyright over the data.
|
| 21 |
+
|
| 22 |
+
ChatTTS is a powerful text-to-speech system. However, it is very important to utilize this technology responsibly and ethically. To limit the use of ChatTTS, we added a small amount of high-frequency noise during the training of the 40,000-hour model, and compressed the audio quality as much as possible using MP3 format, to prevent malicious actors from potentially using it for criminal purposes. At the same time, we have internally trained a detection model and plan to open-source it in the future.
|
| 23 |
+
|
| 24 |
+
|
| 25 |
+
---
|
| 26 |
+
## Usage
|
| 27 |
+
|
| 28 |
+
<h4>Basic usage</h4>
|
| 29 |
+
|
| 30 |
+
```python
|
| 31 |
+
import ChatTTS
|
| 32 |
+
from IPython.display import Audio
|
| 33 |
+
|
| 34 |
+
chat = ChatTTS.Chat()
|
| 35 |
+
chat.load_models(compile=False) # Set to True for better performance
|
| 36 |
+
|
| 37 |
+
texts = ["PUT YOUR TEXT HERE",]
|
| 38 |
+
|
| 39 |
+
wavs = chat.infer(texts, )
|
| 40 |
+
|
| 41 |
+
torchaudio.save("output1.wav", torch.from_numpy(wavs[0]), 24000)
|
| 42 |
+
```
|
| 43 |
+
|
| 44 |
+
<h4>Advanced usage</h4>
|
| 45 |
+
|
| 46 |
+
```python
|
| 47 |
+
###################################
|
| 48 |
+
# Sample a speaker from Gaussian.
|
| 49 |
+
|
| 50 |
+
rand_spk = chat.sample_random_speaker()
|
| 51 |
+
|
| 52 |
+
params_infer_code = {
|
| 53 |
+
'spk_emb': rand_spk, # add sampled speaker
|
| 54 |
+
'temperature': .3, # using custom temperature
|
| 55 |
+
'top_P': 0.7, # top P decode
|
| 56 |
+
'top_K': 20, # top K decode
|
| 57 |
+
}
|
| 58 |
+
|
| 59 |
+
###################################
|
| 60 |
+
# For sentence level manual control.
|
| 61 |
+
|
| 62 |
+
# use oral_(0-9), laugh_(0-2), break_(0-7)
|
| 63 |
+
# to generate special token in text to synthesize.
|
| 64 |
+
params_refine_text = {
|
| 65 |
+
'prompt': '[oral_2][laugh_0][break_6]'
|
| 66 |
+
}
|
| 67 |
+
|
| 68 |
+
wav = chat.infer(texts, params_refine_text=params_refine_text, params_infer_code=params_infer_code)
|
| 69 |
+
|
| 70 |
+
###################################
|
| 71 |
+
# For word level manual control.
|
| 72 |
+
text = 'What is [uv_break]your favorite english food?[laugh][lbreak]'
|
| 73 |
+
wav = chat.infer(text, skip_refine_text=True, params_refine_text=params_refine_text, params_infer_code=params_infer_code)
|
| 74 |
+
torchaudio.save("output2.wav", torch.from_numpy(wavs[0]), 24000)
|
| 75 |
+
```
|
| 76 |
+
|
| 77 |
+
<details open>
|
| 78 |
+
<summary><h4>Example: self introduction</h4></summary>
|
| 79 |
+
|
| 80 |
+
```python
|
| 81 |
+
inputs_en = """
|
| 82 |
+
chat T T S is a text to speech model designed for dialogue applications.
|
| 83 |
+
[uv_break]it supports mixed language input [uv_break]and offers multi speaker
|
| 84 |
+
capabilities with precise control over prosodic elements [laugh]like like
|
| 85 |
+
[uv_break]laughter[laugh], [uv_break]pauses, [uv_break]and intonation.
|
| 86 |
+
[uv_break]it delivers natural and expressive speech,[uv_break]so please
|
| 87 |
+
[uv_break] use the project responsibly at your own risk.[uv_break]
|
| 88 |
+
""".replace('\n', '') # English is still experimental.
|
| 89 |
+
|
| 90 |
+
params_refine_text = {
|
| 91 |
+
'prompt': '[oral_2][laugh_0][break_4]'
|
| 92 |
+
}
|
| 93 |
+
# audio_array_cn = chat.infer(inputs_cn, params_refine_text=params_refine_text)
|
| 94 |
+
audio_array_en = chat.infer(inputs_en, params_refine_text=params_refine_text)
|
| 95 |
+
torchaudio.save("output3.wav", torch.from_numpy(audio_array_en[0]), 24000)
|
| 96 |
+
```
|
| 97 |
+
[male speaker](https://github.com/2noise/ChatTTS/assets/130631963/e0f51251-db7f-4d39-a0e9-3e095bb65de1)
|
| 98 |
+
|
| 99 |
+
[female speaker](https://github.com/2noise/ChatTTS/assets/130631963/f5dcdd01-1091-47c5-8241-c4f6aaaa8bbd)
|
| 100 |
+
</details>
|
| 101 |
+
|
| 102 |
+
---
|
| 103 |
+
## Roadmap
|
| 104 |
+
- [x] Open-source the 40k hour base model and spk_stats file
|
| 105 |
+
- [ ] Open-source VQ encoder and Lora training code
|
| 106 |
+
- [ ] Streaming audio generation without refining the text*
|
| 107 |
+
- [ ] Open-source the 40k hour version with multi-emotion control
|
| 108 |
+
- [ ] ChatTTS.cpp maybe? (PR or new repo are welcomed.)
|
| 109 |
+
|
| 110 |
+
----
|
| 111 |
+
## FAQ
|
| 112 |
+
|
| 113 |
+
##### How much VRAM do I need? How about infer speed?
|
| 114 |
+
For a 30-second audio clip, at least 4GB of GPU memory is required. For the 4090 GPU, it can generate audio corresponding to approximately 7 semantic tokens per second. The Real-Time Factor (RTF) is around 0.3.
|
| 115 |
+
|
| 116 |
+
##### model stability is not good enough, with issues such as multi speakers or poor audio quality.
|
| 117 |
+
|
| 118 |
+
This is a problem that typically occurs with autoregressive models(for bark and valle). It's generally difficult to avoid. One can try multiple samples to find a suitable result.
|
| 119 |
+
|
| 120 |
+
##### Besides laughter, can we control anything else? Can we control other emotions?
|
| 121 |
+
|
| 122 |
+
In the current released model, the only token-level control units are [laugh], [uv_break], and [lbreak]. In future versions, we may open-source models with additional emotional control capabilities.
|
| 123 |
+
|
| 124 |
+
---
|
| 125 |
+
## Acknowledgements
|
| 126 |
+
- [bark](https://github.com/suno-ai/bark), [XTTSv2](https://github.com/coqui-ai/TTS) and [valle](https://arxiv.org/abs/2301.02111) demostrate a remarkable TTS result by a autoregressive-style system.
|
| 127 |
+
- [fish-speech](https://github.com/fishaudio/fish-speech) reveals capability of GVQ as audio tokenizer for LLM modeling.
|
| 128 |
+
- [vocos](https://github.com/gemelo-ai/vocos) which is used as a pretrained vocoder.
|
| 129 |
+
|
| 130 |
+
---
|
| 131 |
+
## Special Appreciation
|
| 132 |
+
- [wlu-audio lab](https://audio.westlake.edu.cn/) for early algorithm experiments.
|
ChatTTS/README_CN.md
ADDED
|
@@ -0,0 +1,136 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# ChatTTS
|
| 2 |
+
[**English**](./README.md) | [**中文简体**](./README_CN.md)
|
| 3 |
+
|
| 4 |
+
ChatTTS是专门为对话场景设计的文本转语音模型,例如LLM助手对话任务。它支持英文和中文两种语言。最大的模型使用了10万小时以上的中英文数据进行训练。在HuggingFace中开源的版本为4万小时训练且未SFT的版本.
|
| 5 |
+
|
| 6 |
+
如需就模型进行正式商业咨询,请发送邮件至 **open-source@2noise.com**。对于中文用户,您可以加入我们的QQ群:~~808364215 (已满)~~ 230696694 (二群) 进行讨论。同时欢迎在GitHub上提出问题。如果遇到无法使用 **[HuggingFace](https://huggingface.co/2Noise/ChatTTS)** 的情况,可以在 [modelscope](https://www.modelscope.cn/models/pzc163/chatTTS) 上进行下载.
|
| 7 |
+
|
| 8 |
+
---
|
| 9 |
+
## 亮点
|
| 10 |
+
1. **对话式 TTS**: ChatTTS针对对话式任务进行了优化,实现了自然流畅的语音合成,同时支持多说话人。
|
| 11 |
+
2. **细粒度控制**: 该模型能够预测和控制细粒度的韵律特征,包括笑声、停顿和插入词等。
|
| 12 |
+
3. **更好的韵律**: ChatTTS在韵律方面超越了大部分开源TTS模型。同时提供预训练模型,支持进一步的研究。
|
| 13 |
+
|
| 14 |
+
对于模型的具体介绍, 可以参考B站的 **[宣传视频](https://www.bilibili.com/video/BV1zn4y1o7iV)**
|
| 15 |
+
|
| 16 |
+
---
|
| 17 |
+
|
| 18 |
+
## 免责声明
|
| 19 |
+
本文件中的信息仅供学术交流使用。其目的是用于教育和研究,不得用于任何商业或法律目的。作者不保证信息的准确性、完整性或可靠性。本文件中使用的信息和数据,仅用于学术研究目的。这些数据来自公开可用的来源,作者不对数据的所有权或版权提出任何主张。
|
| 20 |
+
|
| 21 |
+
ChatTTS是一个强大的文本转语音系统。然而,负责任地和符合伦理地利用这项技术是非常重要的。为了限制ChatTTS的使用,我们在4w小时模型的训练过程中添加了少量额外的高频噪音,并用mp3格式尽可能压低了音质,以防不法分子用于潜在的犯罪可能。同时我们在内部训练了检测模型,并计划在未来开放。
|
| 22 |
+
|
| 23 |
+
---
|
| 24 |
+
## 用法
|
| 25 |
+
|
| 26 |
+
<h4>基本用法</h4>
|
| 27 |
+
|
| 28 |
+
```python
|
| 29 |
+
import ChatTTS
|
| 30 |
+
from IPython.display import Audio
|
| 31 |
+
|
| 32 |
+
chat = ChatTTS.Chat()
|
| 33 |
+
chat.load_models(compile=False) # 设置为True以获得更快速度
|
| 34 |
+
|
| 35 |
+
texts = ["在这里输入你的文本",]
|
| 36 |
+
|
| 37 |
+
wavs = chat.infer(texts, use_decoder=True)
|
| 38 |
+
|
| 39 |
+
torchaudio.save("output1.wav", torch.from_numpy(wavs[0]), 24000)
|
| 40 |
+
```
|
| 41 |
+
|
| 42 |
+
<h4>进阶用法</h4>
|
| 43 |
+
|
| 44 |
+
```python
|
| 45 |
+
###################################
|
| 46 |
+
# Sample a speaker from Gaussian.
|
| 47 |
+
|
| 48 |
+
rand_spk = chat.sample_random_speaker()
|
| 49 |
+
|
| 50 |
+
params_infer_code = {
|
| 51 |
+
'spk_emb': rand_spk, # add sampled speaker
|
| 52 |
+
'temperature': .3, # using custom temperature
|
| 53 |
+
'top_P': 0.7, # top P decode
|
| 54 |
+
'top_K': 20, # top K decode
|
| 55 |
+
}
|
| 56 |
+
|
| 57 |
+
###################################
|
| 58 |
+
# For sentence level manual control.
|
| 59 |
+
|
| 60 |
+
# use oral_(0-9), laugh_(0-2), break_(0-7)
|
| 61 |
+
# to generate special token in text to synthesize.
|
| 62 |
+
params_refine_text = {
|
| 63 |
+
'prompt': '[oral_2][laugh_0][break_6]'
|
| 64 |
+
}
|
| 65 |
+
|
| 66 |
+
wav = chat.infer(texts, params_refine_text=params_refine_text, params_infer_code=params_infer_code)
|
| 67 |
+
|
| 68 |
+
###################################
|
| 69 |
+
# For word level manual control.
|
| 70 |
+
# use_decoder=False to infer faster with a bit worse quality
|
| 71 |
+
text = 'What is [uv_break]your favorite english food?[laugh][lbreak]'
|
| 72 |
+
wav = chat.infer(text, skip_refine_text=True, params_infer_code=params_infer_code, use_decoder=False)
|
| 73 |
+
|
| 74 |
+
torchaudio.save("output2.wav", torch.from_numpy(wavs[0]), 24000)
|
| 75 |
+
```
|
| 76 |
+
|
| 77 |
+
<details open>
|
| 78 |
+
<summary><h4>自我介绍样例</h4></summary>
|
| 79 |
+
|
| 80 |
+
```python
|
| 81 |
+
inputs_cn = """
|
| 82 |
+
chat T T S 是一款强大的对话式文本转语音模型。它有中英混读和多说话人的能力。
|
| 83 |
+
chat T T S 不仅能够生成自然流畅的语音,还能控制[laugh]笑声啊[laugh],
|
| 84 |
+
停顿啊[uv_break]语气词啊等副语言现象[uv_break]。这个韵律超越了许多开源模型[uv_break]。
|
| 85 |
+
请注意,chat T T S 的使用应遵守法律和伦理准则,避免滥用的安全风险。[uv_break]'
|
| 86 |
+
""".replace('\n', '')
|
| 87 |
+
|
| 88 |
+
params_refine_text = {
|
| 89 |
+
'prompt': '[oral_2][laugh_0][break_4]'
|
| 90 |
+
}
|
| 91 |
+
audio_array_cn = chat.infer(inputs_cn, params_refine_text=params_refine_text)
|
| 92 |
+
# audio_array_en = chat.infer(inputs_en, params_refine_text=params_refine_text)
|
| 93 |
+
|
| 94 |
+
torchaudio.save("output3.wav", torch.from_numpy(audio_array_cn[0]), 24000)
|
| 95 |
+
```
|
| 96 |
+
[男说话人](https://github.com/2noise/ChatTTS/assets/130631963/bbfa3b83-2b67-4bb6-9315-64c992b63788)
|
| 97 |
+
|
| 98 |
+
[女说话人](https://github.com/2noise/ChatTTS/assets/130631963/e061f230-0e05-45e6-8e4e-0189f2d260c4)
|
| 99 |
+
</details>
|
| 100 |
+
|
| 101 |
+
|
| 102 |
+
---
|
| 103 |
+
## 计划路线
|
| 104 |
+
- [x] 开源4w小时基础模型和spk_stats文件
|
| 105 |
+
- [ ] 开源VQ encoder和Lora 训练代码
|
| 106 |
+
- [ ] 在非refine text情况下, 流式生成音频*
|
| 107 |
+
- [ ] 开源多情感可控的4w小时版本
|
| 108 |
+
- [ ] ChatTTS.cpp maybe? (欢迎社区PR或独立的新repo)
|
| 109 |
+
|
| 110 |
+
---
|
| 111 |
+
## 常见问题
|
| 112 |
+
|
| 113 |
+
##### 连不上HuggingFace
|
| 114 |
+
请使用[modelscope](https://www.modelscope.cn/models/pzc163/chatTTS)的版本. 并设置cache的位置:
|
| 115 |
+
```python
|
| 116 |
+
chat.load_models(source='local', local_path='你的下载位置')
|
| 117 |
+
```
|
| 118 |
+
|
| 119 |
+
##### 我要多少显存? Infer的速度是怎么样的?
|
| 120 |
+
对于30s的音频, 至少需要4G的显存. 对于4090, 1s生成约7个字所对应的音频. RTF约0.3.
|
| 121 |
+
|
| 122 |
+
##### 模型稳定性似乎不够好, 会出现其他说话人或音质很差的现象.
|
| 123 |
+
这是自回归模型通常都会出现的问题. 说话人可能会在中间变化, 可能会采样到音质非常差的结果, 这通常难以避免. 可以多采样几次来找到合适的结果.
|
| 124 |
+
|
| 125 |
+
##### 除了笑声还能控制什么吗? 还能控制其他情感吗?
|
| 126 |
+
在现在放出的模型版本中, 只有[laugh]和[uv_break], [lbreak]作为字级别的控制单元. 在未来的版本中我们可能会开源其他情感控制的版本.
|
| 127 |
+
|
| 128 |
+
---
|
| 129 |
+
## 致谢
|
| 130 |
+
- [bark](https://github.com/suno-ai/bark),[XTTSv2](https://github.com/coqui-ai/TTS)和[valle](https://arxiv.org/abs/2301.02111)展示了自回归任务用于TTS任务的可能性.
|
| 131 |
+
- [fish-speech](https://github.com/fishaudio/fish-speech)一个优秀的自回归TTS模型, 揭示了GVQ用于LLM任务的可能性.
|
| 132 |
+
- [vocos](https://github.com/gemelo-ai/vocos)作为模型中的vocoder.
|
| 133 |
+
|
| 134 |
+
---
|
| 135 |
+
## 特别致谢
|
| 136 |
+
- [wlu-audio lab](https://audio.westlake.edu.cn/)为我们提供了早期算法试验的支持.
|
ChatTTS/example.ipynb
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
ChatTTS/requirements.txt
ADDED
|
@@ -0,0 +1,8 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
omegaconf~=2.3.0
|
| 2 |
+
torch~=2.1.0
|
| 3 |
+
tqdm
|
| 4 |
+
einops
|
| 5 |
+
vector_quantize_pytorch
|
| 6 |
+
transformers~=4.41.1
|
| 7 |
+
vocos
|
| 8 |
+
IPython
|
ChatTTS/webui.py
ADDED
|
@@ -0,0 +1,113 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
import random
|
| 3 |
+
import argparse
|
| 4 |
+
|
| 5 |
+
import torch
|
| 6 |
+
import gradio as gr
|
| 7 |
+
import numpy as np
|
| 8 |
+
|
| 9 |
+
import ChatTTS
|
| 10 |
+
|
| 11 |
+
|
| 12 |
+
def generate_seed():
|
| 13 |
+
new_seed = random.randint(1, 100000000)
|
| 14 |
+
return {
|
| 15 |
+
"__type__": "update",
|
| 16 |
+
"value": new_seed
|
| 17 |
+
}
|
| 18 |
+
|
| 19 |
+
|
| 20 |
+
def generate_audio(text, temperature, top_P, top_K, audio_seed_input, text_seed_input, refine_text_flag):
|
| 21 |
+
|
| 22 |
+
torch.manual_seed(audio_seed_input)
|
| 23 |
+
rand_spk = chat.sample_random_speaker()
|
| 24 |
+
params_infer_code = {
|
| 25 |
+
'spk_emb': rand_spk,
|
| 26 |
+
'temperature': temperature,
|
| 27 |
+
'top_P': top_P,
|
| 28 |
+
'top_K': top_K,
|
| 29 |
+
}
|
| 30 |
+
params_refine_text = {'prompt': '[oral_2][laugh_0][break_6]'}
|
| 31 |
+
|
| 32 |
+
torch.manual_seed(text_seed_input)
|
| 33 |
+
|
| 34 |
+
if refine_text_flag:
|
| 35 |
+
text = chat.infer(text,
|
| 36 |
+
skip_refine_text=False,
|
| 37 |
+
refine_text_only=True,
|
| 38 |
+
params_refine_text=params_refine_text,
|
| 39 |
+
params_infer_code=params_infer_code
|
| 40 |
+
)
|
| 41 |
+
|
| 42 |
+
wav = chat.infer(text,
|
| 43 |
+
skip_refine_text=True,
|
| 44 |
+
params_refine_text=params_refine_text,
|
| 45 |
+
params_infer_code=params_infer_code
|
| 46 |
+
)
|
| 47 |
+
|
| 48 |
+
audio_data = np.array(wav[0]).flatten()
|
| 49 |
+
sample_rate = 24000
|
| 50 |
+
text_data = text[0] if isinstance(text, list) else text
|
| 51 |
+
|
| 52 |
+
return [(sample_rate, audio_data), text_data]
|
| 53 |
+
|
| 54 |
+
|
| 55 |
+
def main():
|
| 56 |
+
|
| 57 |
+
with gr.Blocks() as demo:
|
| 58 |
+
gr.Markdown("# ChatTTS Webui")
|
| 59 |
+
gr.Markdown("ChatTTS Model: [2noise/ChatTTS](https://github.com/2noise/ChatTTS)")
|
| 60 |
+
|
| 61 |
+
default_text = "四川美食确实以辣闻名,但也有不辣的选择。比如甜水面、赖汤圆、蛋烘糕、叶儿粑等,这些小吃口味温和,甜而不腻,也很受欢迎。"
|
| 62 |
+
text_input = gr.Textbox(label="Input Text", lines=4, placeholder="Please Input Text...", value=default_text)
|
| 63 |
+
|
| 64 |
+
with gr.Row():
|
| 65 |
+
refine_text_checkbox = gr.Checkbox(label="Refine text", value=True)
|
| 66 |
+
temperature_slider = gr.Slider(minimum=0.00001, maximum=1.0, step=0.00001, value=0.3, label="Audio temperature")
|
| 67 |
+
top_p_slider = gr.Slider(minimum=0.1, maximum=0.9, step=0.05, value=0.7, label="top_P")
|
| 68 |
+
top_k_slider = gr.Slider(minimum=1, maximum=20, step=1, value=20, label="top_K")
|
| 69 |
+
|
| 70 |
+
with gr.Row():
|
| 71 |
+
audio_seed_input = gr.Number(value=2, label="Audio Seed")
|
| 72 |
+
generate_audio_seed = gr.Button("\U0001F3B2")
|
| 73 |
+
text_seed_input = gr.Number(value=42, label="Text Seed")
|
| 74 |
+
generate_text_seed = gr.Button("\U0001F3B2")
|
| 75 |
+
|
| 76 |
+
generate_button = gr.Button("Generate")
|
| 77 |
+
|
| 78 |
+
text_output = gr.Textbox(label="Output Text", interactive=False)
|
| 79 |
+
audio_output = gr.Audio(label="Output Audio")
|
| 80 |
+
|
| 81 |
+
generate_audio_seed.click(generate_seed,
|
| 82 |
+
inputs=[],
|
| 83 |
+
outputs=audio_seed_input)
|
| 84 |
+
|
| 85 |
+
generate_text_seed.click(generate_seed,
|
| 86 |
+
inputs=[],
|
| 87 |
+
outputs=text_seed_input)
|
| 88 |
+
|
| 89 |
+
generate_button.click(generate_audio,
|
| 90 |
+
inputs=[text_input, temperature_slider, top_p_slider, top_k_slider, audio_seed_input, text_seed_input, refine_text_checkbox],
|
| 91 |
+
outputs=[audio_output, text_output])
|
| 92 |
+
|
| 93 |
+
parser = argparse.ArgumentParser(description='ChatTTS demo Launch')
|
| 94 |
+
parser.add_argument('--server_name', type=str, default='0.0.0.0', help='Server name')
|
| 95 |
+
parser.add_argument('--server_port', type=int, default=8080, help='Server port')
|
| 96 |
+
parser.add_argument('--local_path', type=str, default=None, help='the local_path if need')
|
| 97 |
+
args = parser.parse_args()
|
| 98 |
+
|
| 99 |
+
print("loading ChatTTS model...")
|
| 100 |
+
global chat
|
| 101 |
+
chat = ChatTTS.Chat()
|
| 102 |
+
|
| 103 |
+
if args.local_path == None:
|
| 104 |
+
chat.load_models()
|
| 105 |
+
else:
|
| 106 |
+
print('local model path:', args.local_path)
|
| 107 |
+
chat.load_models('local', local_path=args.local_path)
|
| 108 |
+
|
| 109 |
+
demo.launch(server_name=args.server_name, server_port=args.server_port, inbrowser=True)
|
| 110 |
+
|
| 111 |
+
|
| 112 |
+
if __name__ == '__main__':
|
| 113 |
+
main()
|
CosyVoice/.github/ISSUE_TEMPLATE/bug_report.md
ADDED
|
@@ -0,0 +1,38 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
name: Bug report
|
| 3 |
+
about: Create a report to help us improve
|
| 4 |
+
title: ''
|
| 5 |
+
labels: ''
|
| 6 |
+
assignees: ''
|
| 7 |
+
|
| 8 |
+
---
|
| 9 |
+
|
| 10 |
+
**Describe the bug**
|
| 11 |
+
A clear and concise description of what the bug is.
|
| 12 |
+
|
| 13 |
+
**To Reproduce**
|
| 14 |
+
Steps to reproduce the behavior:
|
| 15 |
+
1. Go to '...'
|
| 16 |
+
2. Click on '....'
|
| 17 |
+
3. Scroll down to '....'
|
| 18 |
+
4. See error
|
| 19 |
+
|
| 20 |
+
**Expected behavior**
|
| 21 |
+
A clear and concise description of what you expected to happen.
|
| 22 |
+
|
| 23 |
+
**Screenshots**
|
| 24 |
+
If applicable, add screenshots to help explain your problem.
|
| 25 |
+
|
| 26 |
+
**Desktop (please complete the following information):**
|
| 27 |
+
- OS: [e.g. iOS]
|
| 28 |
+
- Browser [e.g. chrome, safari]
|
| 29 |
+
- Version [e.g. 22]
|
| 30 |
+
|
| 31 |
+
**Smartphone (please complete the following information):**
|
| 32 |
+
- Device: [e.g. iPhone6]
|
| 33 |
+
- OS: [e.g. iOS8.1]
|
| 34 |
+
- Browser [e.g. stock browser, safari]
|
| 35 |
+
- Version [e.g. 22]
|
| 36 |
+
|
| 37 |
+
**Additional context**
|
| 38 |
+
Add any other context about the problem here.
|
CosyVoice/.github/ISSUE_TEMPLATE/feature_request.md
ADDED
|
@@ -0,0 +1,20 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
name: Feature request
|
| 3 |
+
about: Suggest an idea for this project
|
| 4 |
+
title: ''
|
| 5 |
+
labels: ''
|
| 6 |
+
assignees: ''
|
| 7 |
+
|
| 8 |
+
---
|
| 9 |
+
|
| 10 |
+
**Is your feature request related to a problem? Please describe.**
|
| 11 |
+
A clear and concise description of what the problem is. Ex. I'm always frustrated when [...]
|
| 12 |
+
|
| 13 |
+
**Describe the solution you'd like**
|
| 14 |
+
A clear and concise description of what you want to happen.
|
| 15 |
+
|
| 16 |
+
**Describe alternatives you've considered**
|
| 17 |
+
A clear and concise description of any alternative solutions or features you've considered.
|
| 18 |
+
|
| 19 |
+
**Additional context**
|
| 20 |
+
Add any other context or screenshots about the feature request here.
|
CosyVoice/.gitignore
ADDED
|
@@ -0,0 +1,49 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Byte-compiled / optimized / DLL files
|
| 2 |
+
__pycache__/
|
| 3 |
+
*.py[cod]
|
| 4 |
+
*$py.class
|
| 5 |
+
|
| 6 |
+
# Visual Studio Code files
|
| 7 |
+
.vscode
|
| 8 |
+
.vs
|
| 9 |
+
|
| 10 |
+
# PyCharm files
|
| 11 |
+
.idea
|
| 12 |
+
|
| 13 |
+
# Eclipse Project settings
|
| 14 |
+
*.*project
|
| 15 |
+
.settings
|
| 16 |
+
|
| 17 |
+
# Sublime Text settings
|
| 18 |
+
*.sublime-workspace
|
| 19 |
+
*.sublime-project
|
| 20 |
+
|
| 21 |
+
# Editor temporaries
|
| 22 |
+
*.swn
|
| 23 |
+
*.swo
|
| 24 |
+
*.swp
|
| 25 |
+
*.swm
|
| 26 |
+
*~
|
| 27 |
+
|
| 28 |
+
# IPython notebook checkpoints
|
| 29 |
+
.ipynb_checkpoints
|
| 30 |
+
|
| 31 |
+
# macOS dir files
|
| 32 |
+
.DS_Store
|
| 33 |
+
|
| 34 |
+
exp
|
| 35 |
+
data
|
| 36 |
+
raw_wav
|
| 37 |
+
tensorboard
|
| 38 |
+
**/*build*
|
| 39 |
+
|
| 40 |
+
# Clangd files
|
| 41 |
+
.cache
|
| 42 |
+
compile_commands.json
|
| 43 |
+
|
| 44 |
+
# train/inference files
|
| 45 |
+
*.wav
|
| 46 |
+
*.pt
|
| 47 |
+
pretrained_models/*
|
| 48 |
+
*_pb2_grpc.py
|
| 49 |
+
*_pb2.py
|
CosyVoice/.gitmodules
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
[submodule "third_party/Matcha-TTS"]
|
| 2 |
+
path = third_party/Matcha-TTS
|
| 3 |
+
url = https://github.com/shivammehta25/Matcha-TTS.git
|
CosyVoice/CODE_OF_CONDUCT.md
ADDED
|
@@ -0,0 +1,76 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Contributor Covenant Code of Conduct
|
| 2 |
+
|
| 3 |
+
## Our Pledge
|
| 4 |
+
|
| 5 |
+
In the interest of fostering an open and welcoming environment, we as
|
| 6 |
+
contributors and maintainers pledge to making participation in our project and
|
| 7 |
+
our community a harassment-free experience for everyone, regardless of age, body
|
| 8 |
+
size, disability, ethnicity, sex characteristics, gender identity and expression,
|
| 9 |
+
level of experience, education, socio-economic status, nationality, personal
|
| 10 |
+
appearance, race, religion, or sexual identity and orientation.
|
| 11 |
+
|
| 12 |
+
## Our Standards
|
| 13 |
+
|
| 14 |
+
Examples of behavior that contributes to creating a positive environment
|
| 15 |
+
include:
|
| 16 |
+
|
| 17 |
+
* Using welcoming and inclusive language
|
| 18 |
+
* Being respectful of differing viewpoints and experiences
|
| 19 |
+
* Gracefully accepting constructive criticism
|
| 20 |
+
* Focusing on what is best for the community
|
| 21 |
+
* Showing empathy towards other community members
|
| 22 |
+
|
| 23 |
+
Examples of unacceptable behavior by participants include:
|
| 24 |
+
|
| 25 |
+
* The use of sexualized language or imagery and unwelcome sexual attention or
|
| 26 |
+
advances
|
| 27 |
+
* Trolling, insulting/derogatory comments, and personal or political attacks
|
| 28 |
+
* Public or private harassment
|
| 29 |
+
* Publishing others' private information, such as a physical or electronic
|
| 30 |
+
address, without explicit permission
|
| 31 |
+
* Other conduct which could reasonably be considered inappropriate in a
|
| 32 |
+
professional setting
|
| 33 |
+
|
| 34 |
+
## Our Responsibilities
|
| 35 |
+
|
| 36 |
+
Project maintainers are responsible for clarifying the standards of acceptable
|
| 37 |
+
behavior and are expected to take appropriate and fair corrective action in
|
| 38 |
+
response to any instances of unacceptable behavior.
|
| 39 |
+
|
| 40 |
+
Project maintainers have the right and responsibility to remove, edit, or
|
| 41 |
+
reject comments, commits, code, wiki edits, issues, and other contributions
|
| 42 |
+
that are not aligned to this Code of Conduct, or to ban temporarily or
|
| 43 |
+
permanently any contributor for other behaviors that they deem inappropriate,
|
| 44 |
+
threatening, offensive, or harmful.
|
| 45 |
+
|
| 46 |
+
## Scope
|
| 47 |
+
|
| 48 |
+
This Code of Conduct applies both within project spaces and in public spaces
|
| 49 |
+
when an individual is representing the project or its community. Examples of
|
| 50 |
+
representing a project or community include using an official project e-mail
|
| 51 |
+
address, posting via an official social media account, or acting as an appointed
|
| 52 |
+
representative at an online or offline event. Representation of a project may be
|
| 53 |
+
further defined and clarified by project maintainers.
|
| 54 |
+
|
| 55 |
+
## Enforcement
|
| 56 |
+
|
| 57 |
+
Instances of abusive, harassing, or otherwise unacceptable behavior may be
|
| 58 |
+
reported by contacting the project team at mikelei@mobvoi.com. All
|
| 59 |
+
complaints will be reviewed and investigated and will result in a response that
|
| 60 |
+
is deemed necessary and appropriate to the circumstances. The project team is
|
| 61 |
+
obligated to maintain confidentiality with regard to the reporter of an incident.
|
| 62 |
+
Further details of specific enforcement policies may be posted separately.
|
| 63 |
+
|
| 64 |
+
Project maintainers who do not follow or enforce the Code of Conduct in good
|
| 65 |
+
faith may face temporary or permanent repercussions as determined by other
|
| 66 |
+
members of the project's leadership.
|
| 67 |
+
|
| 68 |
+
## Attribution
|
| 69 |
+
|
| 70 |
+
This Code of Conduct is adapted from the [Contributor Covenant][homepage], version 1.4,
|
| 71 |
+
available at https://www.contributor-covenant.org/version/1/4/code-of-conduct.html
|
| 72 |
+
|
| 73 |
+
[homepage]: https://www.contributor-covenant.org
|
| 74 |
+
|
| 75 |
+
For answers to common questions about this code of conduct, see
|
| 76 |
+
https://www.contributor-covenant.org/faq
|
CosyVoice/FAQ.md
ADDED
|
@@ -0,0 +1,16 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
## ModuleNotFoundError: No module named 'matcha'
|
| 2 |
+
|
| 3 |
+
Matcha-TTS is a third_party module. Please check `third_party` directory. If there is no `Matcha-TTS`, execute `git submodule update --init --recursive`.
|
| 4 |
+
|
| 5 |
+
run `export PYTHONPATH=third_party/Matcha-TTS` if you want to use `from cosyvoice.cli.cosyvoice import CosyVoice` in python script.
|
| 6 |
+
|
| 7 |
+
## cannot find resource.zip or cannot unzip resource.zip
|
| 8 |
+
|
| 9 |
+
Please make sure you have git-lfs installed. Execute
|
| 10 |
+
|
| 11 |
+
```sh
|
| 12 |
+
git clone https://www.modelscope.cn/iic/CosyVoice-ttsfrd.git pretrained_models/CosyVoice-ttsfrd
|
| 13 |
+
cd pretrained_models/CosyVoice-ttsfrd/
|
| 14 |
+
unzip resource.zip -d .
|
| 15 |
+
pip install ttsfrd-0.3.6-cp38-cp38-linux_x86_64.whl
|
| 16 |
+
```
|
CosyVoice/LICENSE
ADDED
|
@@ -0,0 +1,201 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Apache License
|
| 2 |
+
Version 2.0, January 2004
|
| 3 |
+
http://www.apache.org/licenses/
|
| 4 |
+
|
| 5 |
+
TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
|
| 6 |
+
|
| 7 |
+
1. Definitions.
|
| 8 |
+
|
| 9 |
+
"License" shall mean the terms and conditions for use, reproduction,
|
| 10 |
+
and distribution as defined by Sections 1 through 9 of this document.
|
| 11 |
+
|
| 12 |
+
"Licensor" shall mean the copyright owner or entity authorized by
|
| 13 |
+
the copyright owner that is granting the License.
|
| 14 |
+
|
| 15 |
+
"Legal Entity" shall mean the union of the acting entity and all
|
| 16 |
+
other entities that control, are controlled by, or are under common
|
| 17 |
+
control with that entity. For the purposes of this definition,
|
| 18 |
+
"control" means (i) the power, direct or indirect, to cause the
|
| 19 |
+
direction or management of such entity, whether by contract or
|
| 20 |
+
otherwise, or (ii) ownership of fifty percent (50%) or more of the
|
| 21 |
+
outstanding shares, or (iii) beneficial ownership of such entity.
|
| 22 |
+
|
| 23 |
+
"You" (or "Your") shall mean an individual or Legal Entity
|
| 24 |
+
exercising permissions granted by this License.
|
| 25 |
+
|
| 26 |
+
"Source" form shall mean the preferred form for making modifications,
|
| 27 |
+
including but not limited to software source code, documentation
|
| 28 |
+
source, and configuration files.
|
| 29 |
+
|
| 30 |
+
"Object" form shall mean any form resulting from mechanical
|
| 31 |
+
transformation or translation of a Source form, including but
|
| 32 |
+
not limited to compiled object code, generated documentation,
|
| 33 |
+
and conversions to other media types.
|
| 34 |
+
|
| 35 |
+
"Work" shall mean the work of authorship, whether in Source or
|
| 36 |
+
Object form, made available under the License, as indicated by a
|
| 37 |
+
copyright notice that is included in or attached to the work
|
| 38 |
+
(an example is provided in the Appendix below).
|
| 39 |
+
|
| 40 |
+
"Derivative Works" shall mean any work, whether in Source or Object
|
| 41 |
+
form, that is based on (or derived from) the Work and for which the
|
| 42 |
+
editorial revisions, annotations, elaborations, or other modifications
|
| 43 |
+
represent, as a whole, an original work of authorship. For the purposes
|
| 44 |
+
of this License, Derivative Works shall not include works that remain
|
| 45 |
+
separable from, or merely link (or bind by name) to the interfaces of,
|
| 46 |
+
the Work and Derivative Works thereof.
|
| 47 |
+
|
| 48 |
+
"Contribution" shall mean any work of authorship, including
|
| 49 |
+
the original version of the Work and any modifications or additions
|
| 50 |
+
to that Work or Derivative Works thereof, that is intentionally
|
| 51 |
+
submitted to Licensor for inclusion in the Work by the copyright owner
|
| 52 |
+
or by an individual or Legal Entity authorized to submit on behalf of
|
| 53 |
+
the copyright owner. For the purposes of this definition, "submitted"
|
| 54 |
+
means any form of electronic, verbal, or written communication sent
|
| 55 |
+
to the Licensor or its representatives, including but not limited to
|
| 56 |
+
communication on electronic mailing lists, source code control systems,
|
| 57 |
+
and issue tracking systems that are managed by, or on behalf of, the
|
| 58 |
+
Licensor for the purpose of discussing and improving the Work, but
|
| 59 |
+
excluding communication that is conspicuously marked or otherwise
|
| 60 |
+
designated in writing by the copyright owner as "Not a Contribution."
|
| 61 |
+
|
| 62 |
+
"Contributor" shall mean Licensor and any individual or Legal Entity
|
| 63 |
+
on behalf of whom a Contribution has been received by Licensor and
|
| 64 |
+
subsequently incorporated within the Work.
|
| 65 |
+
|
| 66 |
+
2. Grant of Copyright License. Subject to the terms and conditions of
|
| 67 |
+
this License, each Contributor hereby grants to You a perpetual,
|
| 68 |
+
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
|
| 69 |
+
copyright license to reproduce, prepare Derivative Works of,
|
| 70 |
+
publicly display, publicly perform, sublicense, and distribute the
|
| 71 |
+
Work and such Derivative Works in Source or Object form.
|
| 72 |
+
|
| 73 |
+
3. Grant of Patent License. Subject to the terms and conditions of
|
| 74 |
+
this License, each Contributor hereby grants to You a perpetual,
|
| 75 |
+
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
|
| 76 |
+
(except as stated in this section) patent license to make, have made,
|
| 77 |
+
use, offer to sell, sell, import, and otherwise transfer the Work,
|
| 78 |
+
where such license applies only to those patent claims licensable
|
| 79 |
+
by such Contributor that are necessarily infringed by their
|
| 80 |
+
Contribution(s) alone or by combination of their Contribution(s)
|
| 81 |
+
with the Work to which such Contribution(s) was submitted. If You
|
| 82 |
+
institute patent litigation against any entity (including a
|
| 83 |
+
cross-claim or counterclaim in a lawsuit) alleging that the Work
|
| 84 |
+
or a Contribution incorporated within the Work constitutes direct
|
| 85 |
+
or contributory patent infringement, then any patent licenses
|
| 86 |
+
granted to You under this License for that Work shall terminate
|
| 87 |
+
as of the date such litigation is filed.
|
| 88 |
+
|
| 89 |
+
4. Redistribution. You may reproduce and distribute copies of the
|
| 90 |
+
Work or Derivative Works thereof in any medium, with or without
|
| 91 |
+
modifications, and in Source or Object form, provided that You
|
| 92 |
+
meet the following conditions:
|
| 93 |
+
|
| 94 |
+
(a) You must give any other recipients of the Work or
|
| 95 |
+
Derivative Works a copy of this License; and
|
| 96 |
+
|
| 97 |
+
(b) You must cause any modified files to carry prominent notices
|
| 98 |
+
stating that You changed the files; and
|
| 99 |
+
|
| 100 |
+
(c) You must retain, in the Source form of any Derivative Works
|
| 101 |
+
that You distribute, all copyright, patent, trademark, and
|
| 102 |
+
attribution notices from the Source form of the Work,
|
| 103 |
+
excluding those notices that do not pertain to any part of
|
| 104 |
+
the Derivative Works; and
|
| 105 |
+
|
| 106 |
+
(d) If the Work includes a "NOTICE" text file as part of its
|
| 107 |
+
distribution, then any Derivative Works that You distribute must
|
| 108 |
+
include a readable copy of the attribution notices contained
|
| 109 |
+
within such NOTICE file, excluding those notices that do not
|
| 110 |
+
pertain to any part of the Derivative Works, in at least one
|
| 111 |
+
of the following places: within a NOTICE text file distributed
|
| 112 |
+
as part of the Derivative Works; within the Source form or
|
| 113 |
+
documentation, if provided along with the Derivative Works; or,
|
| 114 |
+
within a display generated by the Derivative Works, if and
|
| 115 |
+
wherever such third-party notices normally appear. The contents
|
| 116 |
+
of the NOTICE file are for informational purposes only and
|
| 117 |
+
do not modify the License. You may add Your own attribution
|
| 118 |
+
notices within Derivative Works that You distribute, alongside
|
| 119 |
+
or as an addendum to the NOTICE text from the Work, provided
|
| 120 |
+
that such additional attribution notices cannot be construed
|
| 121 |
+
as modifying the License.
|
| 122 |
+
|
| 123 |
+
You may add Your own copyright statement to Your modifications and
|
| 124 |
+
may provide additional or different license terms and conditions
|
| 125 |
+
for use, reproduction, or distribution of Your modifications, or
|
| 126 |
+
for any such Derivative Works as a whole, provided Your use,
|
| 127 |
+
reproduction, and distribution of the Work otherwise complies with
|
| 128 |
+
the conditions stated in this License.
|
| 129 |
+
|
| 130 |
+
5. Submission of Contributions. Unless You explicitly state otherwise,
|
| 131 |
+
any Contribution intentionally submitted for inclusion in the Work
|
| 132 |
+
by You to the Licensor shall be under the terms and conditions of
|
| 133 |
+
this License, without any additional terms or conditions.
|
| 134 |
+
Notwithstanding the above, nothing herein shall supersede or modify
|
| 135 |
+
the terms of any separate license agreement you may have executed
|
| 136 |
+
with Licensor regarding such Contributions.
|
| 137 |
+
|
| 138 |
+
6. Trademarks. This License does not grant permission to use the trade
|
| 139 |
+
names, trademarks, service marks, or product names of the Licensor,
|
| 140 |
+
except as required for reasonable and customary use in describing the
|
| 141 |
+
origin of the Work and reproducing the content of the NOTICE file.
|
| 142 |
+
|
| 143 |
+
7. Disclaimer of Warranty. Unless required by applicable law or
|
| 144 |
+
agreed to in writing, Licensor provides the Work (and each
|
| 145 |
+
Contributor provides its Contributions) on an "AS IS" BASIS,
|
| 146 |
+
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
|
| 147 |
+
implied, including, without limitation, any warranties or conditions
|
| 148 |
+
of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A
|
| 149 |
+
PARTICULAR PURPOSE. You are solely responsible for determining the
|
| 150 |
+
appropriateness of using or redistributing the Work and assume any
|
| 151 |
+
risks associated with Your exercise of permissions under this License.
|
| 152 |
+
|
| 153 |
+
8. Limitation of Liability. In no event and under no legal theory,
|
| 154 |
+
whether in tort (including negligence), contract, or otherwise,
|
| 155 |
+
unless required by applicable law (such as deliberate and grossly
|
| 156 |
+
negligent acts) or agreed to in writing, shall any Contributor be
|
| 157 |
+
liable to You for damages, including any direct, indirect, special,
|
| 158 |
+
incidental, or consequential damages of any character arising as a
|
| 159 |
+
result of this License or out of the use or inability to use the
|
| 160 |
+
Work (including but not limited to damages for loss of goodwill,
|
| 161 |
+
work stoppage, computer failure or malfunction, or any and all
|
| 162 |
+
other commercial damages or losses), even if such Contributor
|
| 163 |
+
has been advised of the possibility of such damages.
|
| 164 |
+
|
| 165 |
+
9. Accepting Warranty or Additional Liability. While redistributing
|
| 166 |
+
the Work or Derivative Works thereof, You may choose to offer,
|
| 167 |
+
and charge a fee for, acceptance of support, warranty, indemnity,
|
| 168 |
+
or other liability obligations and/or rights consistent with this
|
| 169 |
+
License. However, in accepting such obligations, You may act only
|
| 170 |
+
on Your own behalf and on Your sole responsibility, not on behalf
|
| 171 |
+
of any other Contributor, and only if You agree to indemnify,
|
| 172 |
+
defend, and hold each Contributor harmless for any liability
|
| 173 |
+
incurred by, or claims asserted against, such Contributor by reason
|
| 174 |
+
of your accepting any such warranty or additional liability.
|
| 175 |
+
|
| 176 |
+
END OF TERMS AND CONDITIONS
|
| 177 |
+
|
| 178 |
+
APPENDIX: How to apply the Apache License to your work.
|
| 179 |
+
|
| 180 |
+
To apply the Apache License to your work, attach the following
|
| 181 |
+
boilerplate notice, with the fields enclosed by brackets "[]"
|
| 182 |
+
replaced with your own identifying information. (Don't include
|
| 183 |
+
the brackets!) The text should be enclosed in the appropriate
|
| 184 |
+
comment syntax for the file format. We also recommend that a
|
| 185 |
+
file or class name and description of purpose be included on the
|
| 186 |
+
same "printed page" as the copyright notice for easier
|
| 187 |
+
identification within third-party archives.
|
| 188 |
+
|
| 189 |
+
Copyright [yyyy] [name of copyright owner]
|
| 190 |
+
|
| 191 |
+
Licensed under the Apache License, Version 2.0 (the "License");
|
| 192 |
+
you may not use this file except in compliance with the License.
|
| 193 |
+
You may obtain a copy of the License at
|
| 194 |
+
|
| 195 |
+
http://www.apache.org/licenses/LICENSE-2.0
|
| 196 |
+
|
| 197 |
+
Unless required by applicable law or agreed to in writing, software
|
| 198 |
+
distributed under the License is distributed on an "AS IS" BASIS,
|
| 199 |
+
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 200 |
+
See the License for the specific language governing permissions and
|
| 201 |
+
limitations under the License.
|
CosyVoice/README.md
ADDED
|
@@ -0,0 +1,189 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# CosyVoice
|
| 2 |
+
## 👉🏻 [CosyVoice Demos](https://fun-audio-llm.github.io/) 👈🏻
|
| 3 |
+
[[CosyVoice Paper](https://fun-audio-llm.github.io/pdf/CosyVoice_v1.pdf)][[CosyVoice Studio](https://www.modelscope.cn/studios/iic/CosyVoice-300M)][[CosyVoice Code](https://github.com/FunAudioLLM/CosyVoice)]
|
| 4 |
+
|
| 5 |
+
For `SenseVoice`, visit [SenseVoice repo](https://github.com/FunAudioLLM/SenseVoice) and [SenseVoice space](https://www.modelscope.cn/studios/iic/SenseVoice).
|
| 6 |
+
|
| 7 |
+
## Roadmap
|
| 8 |
+
|
| 9 |
+
- [x] 2024/07
|
| 10 |
+
|
| 11 |
+
- [x] Flow matching training support
|
| 12 |
+
- [x] WeTextProcessing support when ttsfrd is not avaliable
|
| 13 |
+
- [x] Fastapi server and client
|
| 14 |
+
|
| 15 |
+
- [ ] 2024/08
|
| 16 |
+
|
| 17 |
+
- [ ] Repetition Aware Sampling(RAS) inference for llm stability
|
| 18 |
+
- [ ] Streaming inference mode support, including kv cache and sdpa for rtf optimization
|
| 19 |
+
|
| 20 |
+
- [ ] 2024/09
|
| 21 |
+
|
| 22 |
+
- [ ] 50hz llm model which supports 10 language
|
| 23 |
+
|
| 24 |
+
- [ ] 2024/10
|
| 25 |
+
|
| 26 |
+
- [ ] 50hz llama based llm model which supports lora finetune
|
| 27 |
+
|
| 28 |
+
- [ ] TBD
|
| 29 |
+
|
| 30 |
+
- [ ] Support more instruction mode
|
| 31 |
+
- [ ] Voice conversion
|
| 32 |
+
- [ ] Music generation
|
| 33 |
+
- [ ] Training script sample based on Mandarin
|
| 34 |
+
- [ ] CosyVoice-500M trained with more multi-lingual data
|
| 35 |
+
- [ ] More...
|
| 36 |
+
|
| 37 |
+
## Install
|
| 38 |
+
|
| 39 |
+
**Clone and install**
|
| 40 |
+
|
| 41 |
+
- Clone the repo
|
| 42 |
+
``` sh
|
| 43 |
+
git clone --recursive https://github.com/FunAudioLLM/CosyVoice.git
|
| 44 |
+
# If you failed to clone submodule due to network failures, please run following command until success
|
| 45 |
+
cd CosyVoice
|
| 46 |
+
git submodule update --init --recursive
|
| 47 |
+
```
|
| 48 |
+
|
| 49 |
+
- Install Conda: please see https://docs.conda.io/en/latest/miniconda.html
|
| 50 |
+
- Create Conda env:
|
| 51 |
+
|
| 52 |
+
``` sh
|
| 53 |
+
conda create -n cosyvoice python=3.8
|
| 54 |
+
conda activate cosyvoice
|
| 55 |
+
# pynini is required by WeTextProcessing, use conda to install it as it can be executed on all platform.
|
| 56 |
+
conda install -y -c conda-forge pynini==2.1.5
|
| 57 |
+
pip install -r requirements.txt -i https://mirrors.aliyun.com/pypi/simple/ --trusted-host=mirrors.aliyun.com
|
| 58 |
+
|
| 59 |
+
# If you encounter sox compatibility issues
|
| 60 |
+
# ubuntu
|
| 61 |
+
sudo apt-get install sox libsox-dev
|
| 62 |
+
# centos
|
| 63 |
+
sudo yum install sox sox-devel
|
| 64 |
+
```
|
| 65 |
+
|
| 66 |
+
**Model download**
|
| 67 |
+
|
| 68 |
+
We strongly recommend that you download our pretrained `CosyVoice-300M` `CosyVoice-300M-SFT` `CosyVoice-300M-Instruct` model and `CosyVoice-ttsfrd` resource.
|
| 69 |
+
|
| 70 |
+
If you are expert in this field, and you are only interested in training your own CosyVoice model from scratch, you can skip this step.
|
| 71 |
+
|
| 72 |
+
``` python
|
| 73 |
+
# SDK模型下载
|
| 74 |
+
from modelscope import snapshot_download
|
| 75 |
+
snapshot_download('iic/CosyVoice-300M', local_dir='pretrained_models/CosyVoice-300M')
|
| 76 |
+
snapshot_download('iic/CosyVoice-300M-SFT', local_dir='pretrained_models/CosyVoice-300M-SFT')
|
| 77 |
+
snapshot_download('iic/CosyVoice-300M-Instruct', local_dir='pretrained_models/CosyVoice-300M-Instruct')
|
| 78 |
+
snapshot_download('iic/CosyVoice-ttsfrd', local_dir='pretrained_models/CosyVoice-ttsfrd')
|
| 79 |
+
```
|
| 80 |
+
|
| 81 |
+
``` sh
|
| 82 |
+
# git模型下载,请确保已安装git lfs
|
| 83 |
+
mkdir -p pretrained_models
|
| 84 |
+
git clone https://www.modelscope.cn/iic/CosyVoice-300M.git pretrained_models/CosyVoice-300M
|
| 85 |
+
git clone https://www.modelscope.cn/iic/CosyVoice-300M-SFT.git pretrained_models/CosyVoice-300M-SFT
|
| 86 |
+
git clone https://www.modelscope.cn/iic/CosyVoice-300M-Instruct.git pretrained_models/CosyVoice-300M-Instruct
|
| 87 |
+
git clone https://www.modelscope.cn/iic/CosyVoice-ttsfrd.git pretrained_models/CosyVoice-ttsfrd
|
| 88 |
+
```
|
| 89 |
+
|
| 90 |
+
Optionaly, you can unzip `ttsfrd` resouce and install `ttsfrd` package for better text normalization performance.
|
| 91 |
+
|
| 92 |
+
Notice that this step is not necessary. If you do not install `ttsfrd` package, we will use WeTextProcessing by default.
|
| 93 |
+
|
| 94 |
+
``` sh
|
| 95 |
+
cd pretrained_models/CosyVoice-ttsfrd/
|
| 96 |
+
unzip resource.zip -d .
|
| 97 |
+
pip install ttsfrd-0.3.6-cp38-cp38-linux_x86_64.whl
|
| 98 |
+
```
|
| 99 |
+
|
| 100 |
+
**Basic Usage**
|
| 101 |
+
|
| 102 |
+
For zero_shot/cross_lingual inference, please use `CosyVoice-300M` model.
|
| 103 |
+
For sft inference, please use `CosyVoice-300M-SFT` model.
|
| 104 |
+
For instruct inference, please use `CosyVoice-300M-Instruct` model.
|
| 105 |
+
First, add `third_party/Matcha-TTS` to your `PYTHONPATH`.
|
| 106 |
+
|
| 107 |
+
``` sh
|
| 108 |
+
export PYTHONPATH=third_party/Matcha-TTS
|
| 109 |
+
```
|
| 110 |
+
|
| 111 |
+
``` python
|
| 112 |
+
from cosyvoice.cli.cosyvoice import CosyVoice
|
| 113 |
+
from cosyvoice.utils.file_utils import load_wav
|
| 114 |
+
import torchaudio
|
| 115 |
+
|
| 116 |
+
cosyvoice = CosyVoice('pretrained_models/CosyVoice-300M-SFT')
|
| 117 |
+
# sft usage
|
| 118 |
+
print(cosyvoice.list_avaliable_spks())
|
| 119 |
+
output = cosyvoice.inference_sft('你好,我是通义生成式语音大模型,请问有什么可以帮您的吗?', '中文女')
|
| 120 |
+
torchaudio.save('sft.wav', output['tts_speech'], 22050)
|
| 121 |
+
|
| 122 |
+
cosyvoice = CosyVoice('pretrained_models/CosyVoice-300M')
|
| 123 |
+
# zero_shot usage, <|zh|><|en|><|jp|><|yue|><|ko|> for Chinese/English/Japanese/Cantonese/Korean
|
| 124 |
+
prompt_speech_16k = load_wav('zero_shot_prompt.wav', 16000)
|
| 125 |
+
output = cosyvoice.inference_zero_shot('收到好友从远方寄来的生日礼物,那份意外的惊喜与深深的祝福让我心中充满了甜蜜的快乐,笑容如花儿般绽放。', '希望你以后能够做的比我还好呦。', prompt_speech_16k)
|
| 126 |
+
torchaudio.save('zero_shot.wav', output['tts_speech'], 22050)
|
| 127 |
+
# cross_lingual usage
|
| 128 |
+
prompt_speech_16k = load_wav('cross_lingual_prompt.wav', 16000)
|
| 129 |
+
output = cosyvoice.inference_cross_lingual('<|en|>And then later on, fully acquiring that company. So keeping management in line, interest in line with the asset that\'s coming into the family is a reason why sometimes we don\'t buy the whole thing.', prompt_speech_16k)
|
| 130 |
+
torchaudio.save('cross_lingual.wav', output['tts_speech'], 22050)
|
| 131 |
+
|
| 132 |
+
cosyvoice = CosyVoice('pretrained_models/CosyVoice-300M-Instruct')
|
| 133 |
+
# instruct usage, support <laughter></laughter><strong></strong>[laughter][breath]
|
| 134 |
+
output = cosyvoice.inference_instruct('在面对挑战时,他展现了非凡的<strong>勇气</strong>与<strong>智慧</strong>。', '中文男', 'Theo \'Crimson\', is a fiery, passionate rebel leader. Fights with fervor for justice, but struggles with impulsiveness.')
|
| 135 |
+
torchaudio.save('instruct.wav', output['tts_speech'], 22050)
|
| 136 |
+
```
|
| 137 |
+
|
| 138 |
+
**Start web demo**
|
| 139 |
+
|
| 140 |
+
You can use our web demo page to get familiar with CosyVoice quickly.
|
| 141 |
+
We support sft/zero_shot/cross_lingual/instruct inference in web demo.
|
| 142 |
+
|
| 143 |
+
Please see the demo website for details.
|
| 144 |
+
|
| 145 |
+
``` python
|
| 146 |
+
# change iic/CosyVoice-300M-SFT for sft inference, or iic/CosyVoice-300M-Instruct for instruct inference
|
| 147 |
+
python3 webui.py --port 50000 --model_dir pretrained_models/CosyVoice-300M
|
| 148 |
+
```
|
| 149 |
+
|
| 150 |
+
**Advanced Usage**
|
| 151 |
+
|
| 152 |
+
For advanced user, we have provided train and inference scripts in `examples/libritts/cosyvoice/run.sh`.
|
| 153 |
+
You can get familiar with CosyVoice following this recipie.
|
| 154 |
+
|
| 155 |
+
**Build for deployment**
|
| 156 |
+
|
| 157 |
+
Optionally, if you want to use grpc for service deployment,
|
| 158 |
+
you can run following steps. Otherwise, you can just ignore this step.
|
| 159 |
+
|
| 160 |
+
``` sh
|
| 161 |
+
cd runtime/python
|
| 162 |
+
docker build -t cosyvoice:v1.0 .
|
| 163 |
+
# change iic/CosyVoice-300M to iic/CosyVoice-300M-Instruct if you want to use instruct inference
|
| 164 |
+
# for grpc usage
|
| 165 |
+
docker run -d --runtime=nvidia -p 50000:50000 cosyvoice:v1.0 /bin/bash -c "cd /opt/CosyVoice/CosyVoice/runtime/python/grpc && python3 server.py --port 50000 --max_conc 4 --model_dir iic/CosyVoice-300M && sleep infinity"
|
| 166 |
+
python3 grpc/client.py --port 50000 --mode <sft|zero_shot|cross_lingual|instruct>
|
| 167 |
+
# for fastapi usage
|
| 168 |
+
docker run -d --runtime=nvidia -p 50000:50000 cosyvoice:v1.0 /bin/bash -c "cd /opt/CosyVoice/CosyVoice/runtime/python/fastapi && MODEL_DIR=iic/CosyVoice-300M fastapi dev --port 50000 server.py && sleep infinity"
|
| 169 |
+
python3 fastapi/client.py --port 50000 --mode <sft|zero_shot|cross_lingual|instruct>
|
| 170 |
+
```
|
| 171 |
+
|
| 172 |
+
## Discussion & Communication
|
| 173 |
+
|
| 174 |
+
You can directly discuss on [Github Issues](https://github.com/FunAudioLLM/CosyVoice/issues).
|
| 175 |
+
|
| 176 |
+
You can also scan the QR code to join our official Dingding chat group.
|
| 177 |
+
|
| 178 |
+
<img src="./asset/dingding.png" width="250px">
|
| 179 |
+
|
| 180 |
+
## Acknowledge
|
| 181 |
+
|
| 182 |
+
1. We borrowed a lot of code from [FunASR](https://github.com/modelscope/FunASR).
|
| 183 |
+
2. We borrowed a lot of code from [FunCodec](https://github.com/modelscope/FunCodec).
|
| 184 |
+
3. We borrowed a lot of code from [Matcha-TTS](https://github.com/shivammehta25/Matcha-TTS).
|
| 185 |
+
4. We borrowed a lot of code from [AcademiCodec](https://github.com/yangdongchao/AcademiCodec).
|
| 186 |
+
5. We borrowed a lot of code from [WeNet](https://github.com/wenet-e2e/wenet).
|
| 187 |
+
|
| 188 |
+
## Disclaimer
|
| 189 |
+
The content provided above is for academic purposes only and is intended to demonstrate technical capabilities. Some examples are sourced from the internet. If any content infringes on your rights, please contact us to request its removal.
|
CosyVoice/asset/dingding.png
ADDED

|
CosyVoice/cosyvoice/__init__.py
ADDED
|
File without changes
|
CosyVoice/cosyvoice/bin/inference.py
ADDED
|
@@ -0,0 +1,114 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) 2024 Alibaba Inc (authors: Xiang Lyu)
|
| 2 |
+
#
|
| 3 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 4 |
+
# you may not use this file except in compliance with the License.
|
| 5 |
+
# You may obtain a copy of the License at
|
| 6 |
+
#
|
| 7 |
+
# http://www.apache.org/licenses/LICENSE-2.0
|
| 8 |
+
#
|
| 9 |
+
# Unless required by applicable law or agreed to in writing, software
|
| 10 |
+
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 11 |
+
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 12 |
+
# See the License for the specific language governing permissions and
|
| 13 |
+
# limitations under the License.
|
| 14 |
+
|
| 15 |
+
from __future__ import print_function
|
| 16 |
+
|
| 17 |
+
import argparse
|
| 18 |
+
import logging
|
| 19 |
+
logging.getLogger('matplotlib').setLevel(logging.WARNING)
|
| 20 |
+
import os
|
| 21 |
+
|
| 22 |
+
import torch
|
| 23 |
+
from torch.utils.data import DataLoader
|
| 24 |
+
import torchaudio
|
| 25 |
+
from hyperpyyaml import load_hyperpyyaml
|
| 26 |
+
from tqdm import tqdm
|
| 27 |
+
from cosyvoice.cli.model import CosyVoiceModel
|
| 28 |
+
|
| 29 |
+
from cosyvoice.dataset.dataset import Dataset
|
| 30 |
+
|
| 31 |
+
def get_args():
|
| 32 |
+
parser = argparse.ArgumentParser(description='inference with your model')
|
| 33 |
+
parser.add_argument('--config', required=True, help='config file')
|
| 34 |
+
parser.add_argument('--prompt_data', required=True, help='prompt data file')
|
| 35 |
+
parser.add_argument('--prompt_utt2data', required=True, help='prompt data file')
|
| 36 |
+
parser.add_argument('--tts_text', required=True, help='tts input file')
|
| 37 |
+
parser.add_argument('--llm_model', required=True, help='llm model file')
|
| 38 |
+
parser.add_argument('--flow_model', required=True, help='flow model file')
|
| 39 |
+
parser.add_argument('--hifigan_model', required=True, help='hifigan model file')
|
| 40 |
+
parser.add_argument('--gpu',
|
| 41 |
+
type=int,
|
| 42 |
+
default=-1,
|
| 43 |
+
help='gpu id for this rank, -1 for cpu')
|
| 44 |
+
parser.add_argument('--mode',
|
| 45 |
+
default='sft',
|
| 46 |
+
choices=['sft', 'zero_shot'],
|
| 47 |
+
help='inference mode')
|
| 48 |
+
parser.add_argument('--result_dir', required=True, help='asr result file')
|
| 49 |
+
args = parser.parse_args()
|
| 50 |
+
print(args)
|
| 51 |
+
return args
|
| 52 |
+
|
| 53 |
+
|
| 54 |
+
def main():
|
| 55 |
+
args = get_args()
|
| 56 |
+
logging.basicConfig(level=logging.DEBUG,
|
| 57 |
+
format='%(asctime)s %(levelname)s %(message)s')
|
| 58 |
+
os.environ['CUDA_VISIBLE_DEVICES'] = str(args.gpu)
|
| 59 |
+
|
| 60 |
+
# Init cosyvoice models from configs
|
| 61 |
+
use_cuda = args.gpu >= 0 and torch.cuda.is_available()
|
| 62 |
+
device = torch.device('cuda' if use_cuda else 'cpu')
|
| 63 |
+
with open(args.config, 'r') as f:
|
| 64 |
+
configs = load_hyperpyyaml(f)
|
| 65 |
+
|
| 66 |
+
model = CosyVoiceModel(configs['llm'], configs['flow'], configs['hift'])
|
| 67 |
+
model.load(args.llm_model, args.flow_model, args.hifigan_model)
|
| 68 |
+
|
| 69 |
+
test_dataset = Dataset(args.prompt_data, data_pipeline=configs['data_pipeline'], mode='inference', shuffle=False, partition=False, tts_file=args.tts_text, prompt_utt2data=args.prompt_utt2data)
|
| 70 |
+
test_data_loader = DataLoader(test_dataset, batch_size=None, num_workers=0)
|
| 71 |
+
|
| 72 |
+
del configs
|
| 73 |
+
os.makedirs(args.result_dir, exist_ok=True)
|
| 74 |
+
fn = os.path.join(args.result_dir, 'wav.scp')
|
| 75 |
+
f = open(fn, 'w')
|
| 76 |
+
with torch.no_grad():
|
| 77 |
+
for batch_idx, batch in tqdm(enumerate(test_data_loader)):
|
| 78 |
+
utts = batch["utts"]
|
| 79 |
+
assert len(utts) == 1, "inference mode only support batchsize 1"
|
| 80 |
+
text = batch["text"]
|
| 81 |
+
text_token = batch["text_token"].to(device)
|
| 82 |
+
text_token_len = batch["text_token_len"].to(device)
|
| 83 |
+
tts_text = batch["tts_text"]
|
| 84 |
+
tts_index = batch["tts_index"]
|
| 85 |
+
tts_text_token = batch["tts_text_token"].to(device)
|
| 86 |
+
tts_text_token_len = batch["tts_text_token_len"].to(device)
|
| 87 |
+
speech_token = batch["speech_token"].to(device)
|
| 88 |
+
speech_token_len = batch["speech_token_len"].to(device)
|
| 89 |
+
speech_feat = batch["speech_feat"].to(device)
|
| 90 |
+
speech_feat_len = batch["speech_feat_len"].to(device)
|
| 91 |
+
utt_embedding = batch["utt_embedding"].to(device)
|
| 92 |
+
spk_embedding = batch["spk_embedding"].to(device)
|
| 93 |
+
if args.mode == 'sft':
|
| 94 |
+
model_input = {'text': tts_text_token, 'text_len': tts_text_token_len,
|
| 95 |
+
'llm_embedding': spk_embedding, 'flow_embedding': spk_embedding}
|
| 96 |
+
else:
|
| 97 |
+
model_input = {'text': tts_text_token, 'text_len': tts_text_token_len,
|
| 98 |
+
'prompt_text': text_token, 'prompt_text_len': text_token_len,
|
| 99 |
+
'llm_prompt_speech_token': speech_token, 'llm_prompt_speech_token_len': speech_token_len,
|
| 100 |
+
'flow_prompt_speech_token': speech_token, 'flow_prompt_speech_token_len': speech_token_len,
|
| 101 |
+
'prompt_speech_feat': speech_feat, 'prompt_speech_feat_len': speech_feat_len,
|
| 102 |
+
'llm_embedding': utt_embedding, 'flow_embedding': utt_embedding}
|
| 103 |
+
model_output = model.inference(**model_input)
|
| 104 |
+
tts_key = '{}_{}'.format(utts[0], tts_index[0])
|
| 105 |
+
tts_fn = os.path.join(args.result_dir, '{}.wav'.format(tts_key))
|
| 106 |
+
torchaudio.save(tts_fn, model_output['tts_speech'], sample_rate=22050)
|
| 107 |
+
f.write('{} {}\n'.format(tts_key, tts_fn))
|
| 108 |
+
f.flush()
|
| 109 |
+
f.close()
|
| 110 |
+
logging.info('Result wav.scp saved in {}'.format(fn))
|
| 111 |
+
|
| 112 |
+
|
| 113 |
+
if __name__ == '__main__':
|
| 114 |
+
main()
|
CosyVoice/cosyvoice/bin/train.py
ADDED
|
@@ -0,0 +1,136 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) 2024 Alibaba Inc (authors: Xiang Lyu)
|
| 2 |
+
#
|
| 3 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 4 |
+
# you may not use this file except in compliance with the License.
|
| 5 |
+
# You may obtain a copy of the License at
|
| 6 |
+
#
|
| 7 |
+
# http://www.apache.org/licenses/LICENSE-2.0
|
| 8 |
+
#
|
| 9 |
+
# Unless required by applicable law or agreed to in writing, software
|
| 10 |
+
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 11 |
+
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 12 |
+
# See the License for the specific language governing permissions and
|
| 13 |
+
# limitations under the License.
|
| 14 |
+
|
| 15 |
+
from __future__ import print_function
|
| 16 |
+
import argparse
|
| 17 |
+
import datetime
|
| 18 |
+
import logging
|
| 19 |
+
logging.getLogger('matplotlib').setLevel(logging.WARNING)
|
| 20 |
+
from copy import deepcopy
|
| 21 |
+
import torch
|
| 22 |
+
import torch.distributed as dist
|
| 23 |
+
import deepspeed
|
| 24 |
+
|
| 25 |
+
from hyperpyyaml import load_hyperpyyaml
|
| 26 |
+
|
| 27 |
+
from torch.distributed.elastic.multiprocessing.errors import record
|
| 28 |
+
|
| 29 |
+
from cosyvoice.utils.executor import Executor
|
| 30 |
+
from cosyvoice.utils.train_utils import (
|
| 31 |
+
init_distributed,
|
| 32 |
+
init_dataset_and_dataloader,
|
| 33 |
+
init_optimizer_and_scheduler,
|
| 34 |
+
init_summarywriter, save_model,
|
| 35 |
+
wrap_cuda_model, check_modify_and_save_config)
|
| 36 |
+
|
| 37 |
+
|
| 38 |
+
def get_args():
|
| 39 |
+
parser = argparse.ArgumentParser(description='training your network')
|
| 40 |
+
parser.add_argument('--train_engine',
|
| 41 |
+
default='torch_ddp',
|
| 42 |
+
choices=['torch_ddp', 'deepspeed'],
|
| 43 |
+
help='Engine for paralleled training')
|
| 44 |
+
parser.add_argument('--model', required=True, help='model which will be trained')
|
| 45 |
+
parser.add_argument('--config', required=True, help='config file')
|
| 46 |
+
parser.add_argument('--train_data', required=True, help='train data file')
|
| 47 |
+
parser.add_argument('--cv_data', required=True, help='cv data file')
|
| 48 |
+
parser.add_argument('--checkpoint', help='checkpoint model')
|
| 49 |
+
parser.add_argument('--model_dir', required=True, help='save model dir')
|
| 50 |
+
parser.add_argument('--tensorboard_dir',
|
| 51 |
+
default='tensorboard',
|
| 52 |
+
help='tensorboard log dir')
|
| 53 |
+
parser.add_argument('--ddp.dist_backend',
|
| 54 |
+
dest='dist_backend',
|
| 55 |
+
default='nccl',
|
| 56 |
+
choices=['nccl', 'gloo'],
|
| 57 |
+
help='distributed backend')
|
| 58 |
+
parser.add_argument('--num_workers',
|
| 59 |
+
default=0,
|
| 60 |
+
type=int,
|
| 61 |
+
help='num of subprocess workers for reading')
|
| 62 |
+
parser.add_argument('--prefetch',
|
| 63 |
+
default=100,
|
| 64 |
+
type=int,
|
| 65 |
+
help='prefetch number')
|
| 66 |
+
parser.add_argument('--pin_memory',
|
| 67 |
+
action='store_true',
|
| 68 |
+
default=False,
|
| 69 |
+
help='Use pinned memory buffers used for reading')
|
| 70 |
+
parser.add_argument('--deepspeed.save_states',
|
| 71 |
+
dest='save_states',
|
| 72 |
+
default='model_only',
|
| 73 |
+
choices=['model_only', 'model+optimizer'],
|
| 74 |
+
help='save model/optimizer states')
|
| 75 |
+
parser.add_argument('--timeout',
|
| 76 |
+
default=30,
|
| 77 |
+
type=int,
|
| 78 |
+
help='timeout (in seconds) of cosyvoice_join.')
|
| 79 |
+
parser = deepspeed.add_config_arguments(parser)
|
| 80 |
+
args = parser.parse_args()
|
| 81 |
+
return args
|
| 82 |
+
|
| 83 |
+
|
| 84 |
+
@record
|
| 85 |
+
def main():
|
| 86 |
+
args = get_args()
|
| 87 |
+
logging.basicConfig(level=logging.DEBUG,
|
| 88 |
+
format='%(asctime)s %(levelname)s %(message)s')
|
| 89 |
+
|
| 90 |
+
override_dict = {k: None for k in ['llm', 'flow', 'hift'] if k != args.model}
|
| 91 |
+
with open(args.config, 'r') as f:
|
| 92 |
+
configs = load_hyperpyyaml(f, overrides=override_dict)
|
| 93 |
+
configs['train_conf'].update(vars(args))
|
| 94 |
+
|
| 95 |
+
# Init env for ddp
|
| 96 |
+
init_distributed(args)
|
| 97 |
+
|
| 98 |
+
# Get dataset & dataloader
|
| 99 |
+
train_dataset, cv_dataset, train_data_loader, cv_data_loader = \
|
| 100 |
+
init_dataset_and_dataloader(args, configs)
|
| 101 |
+
|
| 102 |
+
# Do some sanity checks and save config to arsg.model_dir
|
| 103 |
+
configs = check_modify_and_save_config(args, configs)
|
| 104 |
+
|
| 105 |
+
# Tensorboard summary
|
| 106 |
+
writer = init_summarywriter(args)
|
| 107 |
+
|
| 108 |
+
# load checkpoint
|
| 109 |
+
model = configs[args.model]
|
| 110 |
+
if args.checkpoint is not None:
|
| 111 |
+
model.load_state_dict(torch.load(args.checkpoint, map_location='cpu'))
|
| 112 |
+
|
| 113 |
+
# Dispatch model from cpu to gpu
|
| 114 |
+
model = wrap_cuda_model(args, model)
|
| 115 |
+
|
| 116 |
+
# Get optimizer & scheduler
|
| 117 |
+
model, optimizer, scheduler = init_optimizer_and_scheduler(args, configs, model)
|
| 118 |
+
|
| 119 |
+
# Save init checkpoints
|
| 120 |
+
info_dict = deepcopy(configs['train_conf'])
|
| 121 |
+
save_model(model, 'init', info_dict)
|
| 122 |
+
|
| 123 |
+
# Get executor
|
| 124 |
+
executor = Executor()
|
| 125 |
+
|
| 126 |
+
# Start training loop
|
| 127 |
+
for epoch in range(info_dict['max_epoch']):
|
| 128 |
+
executor.epoch = epoch
|
| 129 |
+
train_dataset.set_epoch(epoch)
|
| 130 |
+
dist.barrier()
|
| 131 |
+
group_join = dist.new_group(backend="gloo", timeout=datetime.timedelta(seconds=args.timeout))
|
| 132 |
+
executor.train_one_epoc(model, optimizer, scheduler, train_data_loader, cv_data_loader, writer, info_dict, group_join)
|
| 133 |
+
dist.destroy_process_group(group_join)
|
| 134 |
+
|
| 135 |
+
if __name__ == '__main__':
|
| 136 |
+
main()
|
CosyVoice/cosyvoice/cli/__init__.py
ADDED
|
File without changes
|
CosyVoice/cosyvoice/cli/cosyvoice.py
ADDED
|
@@ -0,0 +1,83 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) 2024 Alibaba Inc (authors: Xiang Lyu)
|
| 2 |
+
#
|
| 3 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 4 |
+
# you may not use this file except in compliance with the License.
|
| 5 |
+
# You may obtain a copy of the License at
|
| 6 |
+
#
|
| 7 |
+
# http://www.apache.org/licenses/LICENSE-2.0
|
| 8 |
+
#
|
| 9 |
+
# Unless required by applicable law or agreed to in writing, software
|
| 10 |
+
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 11 |
+
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 12 |
+
# See the License for the specific language governing permissions and
|
| 13 |
+
# limitations under the License.
|
| 14 |
+
import os
|
| 15 |
+
import torch
|
| 16 |
+
from hyperpyyaml import load_hyperpyyaml
|
| 17 |
+
from modelscope import snapshot_download
|
| 18 |
+
from cosyvoice.cli.frontend import CosyVoiceFrontEnd
|
| 19 |
+
from cosyvoice.cli.model import CosyVoiceModel
|
| 20 |
+
|
| 21 |
+
class CosyVoice:
|
| 22 |
+
|
| 23 |
+
def __init__(self, model_dir):
|
| 24 |
+
instruct = True if '-Instruct' in model_dir else False
|
| 25 |
+
self.model_dir = model_dir
|
| 26 |
+
if not os.path.exists(model_dir):
|
| 27 |
+
model_dir = snapshot_download(model_dir)
|
| 28 |
+
with open('{}/cosyvoice.yaml'.format(model_dir), 'r') as f:
|
| 29 |
+
configs = load_hyperpyyaml(f)
|
| 30 |
+
self.frontend = CosyVoiceFrontEnd(configs['get_tokenizer'],
|
| 31 |
+
configs['feat_extractor'],
|
| 32 |
+
'{}/campplus.onnx'.format(model_dir),
|
| 33 |
+
'{}/speech_tokenizer_v1.onnx'.format(model_dir),
|
| 34 |
+
'{}/spk2info.pt'.format(model_dir),
|
| 35 |
+
instruct,
|
| 36 |
+
configs['allowed_special'])
|
| 37 |
+
self.model = CosyVoiceModel(configs['llm'], configs['flow'], configs['hift'])
|
| 38 |
+
self.model.load('{}/llm.pt'.format(model_dir),
|
| 39 |
+
'{}/flow.pt'.format(model_dir),
|
| 40 |
+
'{}/hift.pt'.format(model_dir))
|
| 41 |
+
del configs
|
| 42 |
+
|
| 43 |
+
def list_avaliable_spks(self):
|
| 44 |
+
spks = list(self.frontend.spk2info.keys())
|
| 45 |
+
return spks
|
| 46 |
+
|
| 47 |
+
def inference_sft(self, tts_text, spk_id):
|
| 48 |
+
tts_speeches = []
|
| 49 |
+
for i in self.frontend.text_normalize(tts_text, split=True):
|
| 50 |
+
model_input = self.frontend.frontend_sft(i, spk_id)
|
| 51 |
+
model_output = self.model.inference(**model_input)
|
| 52 |
+
tts_speeches.append(model_output['tts_speech'])
|
| 53 |
+
return {'tts_speech': torch.concat(tts_speeches, dim=1)}
|
| 54 |
+
|
| 55 |
+
def inference_zero_shot(self, tts_text, prompt_text, prompt_speech_16k):
|
| 56 |
+
prompt_text = self.frontend.text_normalize(prompt_text, split=False)
|
| 57 |
+
tts_speeches = []
|
| 58 |
+
for i in self.frontend.text_normalize(tts_text, split=True):
|
| 59 |
+
model_input = self.frontend.frontend_zero_shot(i, prompt_text, prompt_speech_16k)
|
| 60 |
+
model_output = self.model.inference(**model_input)
|
| 61 |
+
tts_speeches.append(model_output['tts_speech'])
|
| 62 |
+
return {'tts_speech': torch.concat(tts_speeches, dim=1)}
|
| 63 |
+
|
| 64 |
+
def inference_cross_lingual(self, tts_text, prompt_speech_16k):
|
| 65 |
+
if self.frontend.instruct is True:
|
| 66 |
+
raise ValueError('{} do not support cross_lingual inference'.format(self.model_dir))
|
| 67 |
+
tts_speeches = []
|
| 68 |
+
for i in self.frontend.text_normalize(tts_text, split=True):
|
| 69 |
+
model_input = self.frontend.frontend_cross_lingual(i, prompt_speech_16k)
|
| 70 |
+
model_output = self.model.inference(**model_input)
|
| 71 |
+
tts_speeches.append(model_output['tts_speech'])
|
| 72 |
+
return {'tts_speech': torch.concat(tts_speeches, dim=1)}
|
| 73 |
+
|
| 74 |
+
def inference_instruct(self, tts_text, spk_id, instruct_text):
|
| 75 |
+
if self.frontend.instruct is False:
|
| 76 |
+
raise ValueError('{} do not support instruct inference'.format(self.model_dir))
|
| 77 |
+
instruct_text = self.frontend.text_normalize(instruct_text, split=False)
|
| 78 |
+
tts_speeches = []
|
| 79 |
+
for i in self.frontend.text_normalize(tts_text, split=True):
|
| 80 |
+
model_input = self.frontend.frontend_instruct(i, spk_id, instruct_text)
|
| 81 |
+
model_output = self.model.inference(**model_input)
|
| 82 |
+
tts_speeches.append(model_output['tts_speech'])
|
| 83 |
+
return {'tts_speech': torch.concat(tts_speeches, dim=1)}
|
CosyVoice/cosyvoice/cli/frontend.py
ADDED
|
@@ -0,0 +1,168 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) 2024 Alibaba Inc (authors: Xiang Lyu)
|
| 2 |
+
#
|
| 3 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 4 |
+
# you may not use this file except in compliance with the License.
|
| 5 |
+
# You may obtain a copy of the License at
|
| 6 |
+
#
|
| 7 |
+
# http://www.apache.org/licenses/LICENSE-2.0
|
| 8 |
+
#
|
| 9 |
+
# Unless required by applicable law or agreed to in writing, software
|
| 10 |
+
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 11 |
+
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 12 |
+
# See the License for the specific language governing permissions and
|
| 13 |
+
# limitations under the License.
|
| 14 |
+
from functools import partial
|
| 15 |
+
import onnxruntime
|
| 16 |
+
import torch
|
| 17 |
+
import numpy as np
|
| 18 |
+
import whisper
|
| 19 |
+
from typing import Callable
|
| 20 |
+
import torchaudio.compliance.kaldi as kaldi
|
| 21 |
+
import torchaudio
|
| 22 |
+
import os
|
| 23 |
+
import re
|
| 24 |
+
import inflect
|
| 25 |
+
try:
|
| 26 |
+
import ttsfrd
|
| 27 |
+
use_ttsfrd = True
|
| 28 |
+
except ImportError:
|
| 29 |
+
print("failed to import ttsfrd, use WeTextProcessing instead")
|
| 30 |
+
from tn.chinese.normalizer import Normalizer as ZhNormalizer
|
| 31 |
+
from tn.english.normalizer import Normalizer as EnNormalizer
|
| 32 |
+
use_ttsfrd = False
|
| 33 |
+
from cosyvoice.utils.frontend_utils import contains_chinese, replace_blank, replace_corner_mark, remove_bracket, spell_out_number, split_paragraph
|
| 34 |
+
|
| 35 |
+
|
| 36 |
+
class CosyVoiceFrontEnd:
|
| 37 |
+
|
| 38 |
+
def __init__(self,
|
| 39 |
+
get_tokenizer: Callable,
|
| 40 |
+
feat_extractor: Callable,
|
| 41 |
+
campplus_model: str,
|
| 42 |
+
speech_tokenizer_model: str,
|
| 43 |
+
spk2info: str = '',
|
| 44 |
+
instruct: bool = False,
|
| 45 |
+
allowed_special: str = 'all'):
|
| 46 |
+
self.tokenizer = get_tokenizer()
|
| 47 |
+
self.feat_extractor = feat_extractor
|
| 48 |
+
self.device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
|
| 49 |
+
option = onnxruntime.SessionOptions()
|
| 50 |
+
option.graph_optimization_level = onnxruntime.GraphOptimizationLevel.ORT_ENABLE_ALL
|
| 51 |
+
option.intra_op_num_threads = 1
|
| 52 |
+
self.campplus_session = onnxruntime.InferenceSession(campplus_model, sess_options=option, providers=["CPUExecutionProvider"])
|
| 53 |
+
self.speech_tokenizer_session = onnxruntime.InferenceSession(speech_tokenizer_model, sess_options=option, providers=["CUDAExecutionProvider"if torch.cuda.is_available() else "CPUExecutionProvider"])
|
| 54 |
+
if os.path.exists(spk2info):
|
| 55 |
+
self.spk2info = torch.load(spk2info, map_location=self.device)
|
| 56 |
+
self.instruct = instruct
|
| 57 |
+
self.allowed_special = allowed_special
|
| 58 |
+
self.inflect_parser = inflect.engine()
|
| 59 |
+
self.use_ttsfrd = use_ttsfrd
|
| 60 |
+
if self.use_ttsfrd:
|
| 61 |
+
self.frd = ttsfrd.TtsFrontendEngine()
|
| 62 |
+
ROOT_DIR = os.path.dirname(os.path.abspath(__file__))
|
| 63 |
+
assert self.frd.initialize('{}/../../pretrained_models/CosyVoice-ttsfrd/resource'.format(ROOT_DIR)) is True, 'failed to initialize ttsfrd resource'
|
| 64 |
+
self.frd.set_lang_type('pinyin')
|
| 65 |
+
self.frd.enable_pinyin_mix(True)
|
| 66 |
+
self.frd.set_breakmodel_index(1)
|
| 67 |
+
else:
|
| 68 |
+
self.zh_tn_model = ZhNormalizer(remove_erhua=False, full_to_half=False)
|
| 69 |
+
self.en_tn_model = EnNormalizer()
|
| 70 |
+
|
| 71 |
+
def _extract_text_token(self, text):
|
| 72 |
+
text_token = self.tokenizer.encode(text, allowed_special=self.allowed_special)
|
| 73 |
+
text_token = torch.tensor([text_token], dtype=torch.int32).to(self.device)
|
| 74 |
+
text_token_len = torch.tensor([text_token.shape[1]], dtype=torch.int32).to(self.device)
|
| 75 |
+
return text_token, text_token_len
|
| 76 |
+
|
| 77 |
+
def _extract_speech_token(self, speech):
|
| 78 |
+
feat = whisper.log_mel_spectrogram(speech, n_mels=128)
|
| 79 |
+
speech_token = self.speech_tokenizer_session.run(None, {self.speech_tokenizer_session.get_inputs()[0].name: feat.detach().cpu().numpy(),
|
| 80 |
+
self.speech_tokenizer_session.get_inputs()[1].name: np.array([feat.shape[2]], dtype=np.int32)})[0].flatten().tolist()
|
| 81 |
+
speech_token = torch.tensor([speech_token], dtype=torch.int32).to(self.device)
|
| 82 |
+
speech_token_len = torch.tensor([speech_token.shape[1]], dtype=torch.int32).to(self.device)
|
| 83 |
+
return speech_token, speech_token_len
|
| 84 |
+
|
| 85 |
+
def _extract_spk_embedding(self, speech):
|
| 86 |
+
feat = kaldi.fbank(speech,
|
| 87 |
+
num_mel_bins=80,
|
| 88 |
+
dither=0,
|
| 89 |
+
sample_frequency=16000)
|
| 90 |
+
feat = feat - feat.mean(dim=0, keepdim=True)
|
| 91 |
+
embedding = self.campplus_session.run(None, {self.campplus_session.get_inputs()[0].name: feat.unsqueeze(dim=0).cpu().numpy()})[0].flatten().tolist()
|
| 92 |
+
embedding = torch.tensor([embedding]).to(self.device)
|
| 93 |
+
return embedding
|
| 94 |
+
|
| 95 |
+
def _extract_speech_feat(self, speech):
|
| 96 |
+
speech_feat = self.feat_extractor(speech).squeeze(dim=0).transpose(0, 1).to(self.device)
|
| 97 |
+
speech_feat = speech_feat.unsqueeze(dim=0)
|
| 98 |
+
speech_feat_len = torch.tensor([speech_feat.shape[1]], dtype=torch.int32).to(self.device)
|
| 99 |
+
return speech_feat, speech_feat_len
|
| 100 |
+
|
| 101 |
+
def text_normalize(self, text, split=True):
|
| 102 |
+
text = text.strip()
|
| 103 |
+
if contains_chinese(text):
|
| 104 |
+
if self.use_ttsfrd:
|
| 105 |
+
text = self.frd.get_frd_extra_info(text, 'input')
|
| 106 |
+
else:
|
| 107 |
+
text = self.zh_tn_model.normalize(text)
|
| 108 |
+
text = text.replace("\n", "")
|
| 109 |
+
text = replace_blank(text)
|
| 110 |
+
text = replace_corner_mark(text)
|
| 111 |
+
text = text.replace(".", "、")
|
| 112 |
+
text = text.replace(" - ", ",")
|
| 113 |
+
text = remove_bracket(text)
|
| 114 |
+
text = re.sub(r'[,,]+$', '。', text)
|
| 115 |
+
texts = [i for i in split_paragraph(text, partial(self.tokenizer.encode, allowed_special=self.allowed_special), "zh", token_max_n=80,
|
| 116 |
+
token_min_n=60, merge_len=20,
|
| 117 |
+
comma_split=False)]
|
| 118 |
+
else:
|
| 119 |
+
if self.use_ttsfrd:
|
| 120 |
+
text = self.frd.get_frd_extra_info(text, 'input')
|
| 121 |
+
else:
|
| 122 |
+
text = self.en_tn_model.normalize(text)
|
| 123 |
+
text = spell_out_number(text, self.inflect_parser)
|
| 124 |
+
texts = [i for i in split_paragraph(text, partial(self.tokenizer.encode, allowed_special=self.allowed_special), "en", token_max_n=80,
|
| 125 |
+
token_min_n=60, merge_len=20,
|
| 126 |
+
comma_split=False)]
|
| 127 |
+
if split is False:
|
| 128 |
+
return text
|
| 129 |
+
return texts
|
| 130 |
+
|
| 131 |
+
def frontend_sft(self, tts_text, spk_id):
|
| 132 |
+
tts_text_token, tts_text_token_len = self._extract_text_token(tts_text)
|
| 133 |
+
embedding = self.spk2info[spk_id]['embedding']
|
| 134 |
+
model_input = {'text': tts_text_token, 'text_len': tts_text_token_len, 'llm_embedding': embedding, 'flow_embedding': embedding}
|
| 135 |
+
return model_input
|
| 136 |
+
|
| 137 |
+
def frontend_zero_shot(self, tts_text, prompt_text, prompt_speech_16k):
|
| 138 |
+
tts_text_token, tts_text_token_len = self._extract_text_token(tts_text)
|
| 139 |
+
prompt_text_token, prompt_text_token_len = self._extract_text_token(prompt_text)
|
| 140 |
+
prompt_speech_22050 = torchaudio.transforms.Resample(orig_freq=16000, new_freq=22050)(prompt_speech_16k)
|
| 141 |
+
speech_feat, speech_feat_len = self._extract_speech_feat(prompt_speech_22050)
|
| 142 |
+
speech_token, speech_token_len = self._extract_speech_token(prompt_speech_16k)
|
| 143 |
+
embedding = self._extract_spk_embedding(prompt_speech_16k)
|
| 144 |
+
model_input = {'text': tts_text_token, 'text_len': tts_text_token_len,
|
| 145 |
+
'prompt_text': prompt_text_token, 'prompt_text_len': prompt_text_token_len,
|
| 146 |
+
'llm_prompt_speech_token': speech_token, 'llm_prompt_speech_token_len': speech_token_len,
|
| 147 |
+
'flow_prompt_speech_token': speech_token, 'flow_prompt_speech_token_len': speech_token_len,
|
| 148 |
+
'prompt_speech_feat': speech_feat, 'prompt_speech_feat_len': speech_feat_len,
|
| 149 |
+
'llm_embedding': embedding, 'flow_embedding': embedding}
|
| 150 |
+
return model_input
|
| 151 |
+
|
| 152 |
+
def frontend_cross_lingual(self, tts_text, prompt_speech_16k):
|
| 153 |
+
model_input = self.frontend_zero_shot(tts_text, '', prompt_speech_16k)
|
| 154 |
+
# in cross lingual mode, we remove prompt in llm
|
| 155 |
+
del model_input['prompt_text']
|
| 156 |
+
del model_input['prompt_text_len']
|
| 157 |
+
del model_input['llm_prompt_speech_token']
|
| 158 |
+
del model_input['llm_prompt_speech_token_len']
|
| 159 |
+
return model_input
|
| 160 |
+
|
| 161 |
+
def frontend_instruct(self, tts_text, spk_id, instruct_text):
|
| 162 |
+
model_input = self.frontend_sft(tts_text, spk_id)
|
| 163 |
+
# in instruct mode, we remove spk_embedding in llm due to information leakage
|
| 164 |
+
del model_input['llm_embedding']
|
| 165 |
+
instruct_text_token, instruct_text_token_len = self._extract_text_token(instruct_text + '<endofprompt>')
|
| 166 |
+
model_input['prompt_text'] = instruct_text_token
|
| 167 |
+
model_input['prompt_text_len'] = instruct_text_token_len
|
| 168 |
+
return model_input
|
CosyVoice/cosyvoice/cli/model.py
ADDED
|
@@ -0,0 +1,60 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) 2024 Alibaba Inc (authors: Xiang Lyu)
|
| 2 |
+
#
|
| 3 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 4 |
+
# you may not use this file except in compliance with the License.
|
| 5 |
+
# You may obtain a copy of the License at
|
| 6 |
+
#
|
| 7 |
+
# http://www.apache.org/licenses/LICENSE-2.0
|
| 8 |
+
#
|
| 9 |
+
# Unless required by applicable law or agreed to in writing, software
|
| 10 |
+
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 11 |
+
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 12 |
+
# See the License for the specific language governing permissions and
|
| 13 |
+
# limitations under the License.
|
| 14 |
+
import torch
|
| 15 |
+
|
| 16 |
+
class CosyVoiceModel:
|
| 17 |
+
|
| 18 |
+
def __init__(self,
|
| 19 |
+
llm: torch.nn.Module,
|
| 20 |
+
flow: torch.nn.Module,
|
| 21 |
+
hift: torch.nn.Module):
|
| 22 |
+
self.device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
|
| 23 |
+
self.llm = llm
|
| 24 |
+
self.flow = flow
|
| 25 |
+
self.hift = hift
|
| 26 |
+
|
| 27 |
+
def load(self, llm_model, flow_model, hift_model):
|
| 28 |
+
self.llm.load_state_dict(torch.load(llm_model, map_location=self.device))
|
| 29 |
+
self.llm.to(self.device).eval()
|
| 30 |
+
self.flow.load_state_dict(torch.load(flow_model, map_location=self.device))
|
| 31 |
+
self.flow.to(self.device).eval()
|
| 32 |
+
self.hift.load_state_dict(torch.load(hift_model, map_location=self.device))
|
| 33 |
+
self.hift.to(self.device).eval()
|
| 34 |
+
|
| 35 |
+
def inference(self, text, text_len, flow_embedding, llm_embedding=torch.zeros(0, 192),
|
| 36 |
+
prompt_text=torch.zeros(1, 0, dtype=torch.int32), prompt_text_len=torch.zeros(1, dtype=torch.int32),
|
| 37 |
+
llm_prompt_speech_token=torch.zeros(1, 0, dtype=torch.int32), llm_prompt_speech_token_len=torch.zeros(1, dtype=torch.int32),
|
| 38 |
+
flow_prompt_speech_token=torch.zeros(1, 0, dtype=torch.int32), flow_prompt_speech_token_len=torch.zeros(1, dtype=torch.int32),
|
| 39 |
+
prompt_speech_feat=torch.zeros(1, 0, 80), prompt_speech_feat_len=torch.zeros(1, dtype=torch.int32)):
|
| 40 |
+
tts_speech_token = self.llm.inference(text=text.to(self.device),
|
| 41 |
+
text_len=text_len.to(self.device),
|
| 42 |
+
prompt_text=prompt_text.to(self.device),
|
| 43 |
+
prompt_text_len=prompt_text_len.to(self.device),
|
| 44 |
+
prompt_speech_token=llm_prompt_speech_token.to(self.device),
|
| 45 |
+
prompt_speech_token_len=llm_prompt_speech_token_len.to(self.device),
|
| 46 |
+
embedding=llm_embedding.to(self.device),
|
| 47 |
+
beam_size=1,
|
| 48 |
+
sampling=25,
|
| 49 |
+
max_token_text_ratio=30,
|
| 50 |
+
min_token_text_ratio=3)
|
| 51 |
+
tts_mel = self.flow.inference(token=tts_speech_token,
|
| 52 |
+
token_len=torch.tensor([tts_speech_token.size(1)], dtype=torch.int32).to(self.device),
|
| 53 |
+
prompt_token=flow_prompt_speech_token.to(self.device),
|
| 54 |
+
prompt_token_len=flow_prompt_speech_token_len.to(self.device),
|
| 55 |
+
prompt_feat=prompt_speech_feat.to(self.device),
|
| 56 |
+
prompt_feat_len=prompt_speech_feat_len.to(self.device),
|
| 57 |
+
embedding=flow_embedding.to(self.device))
|
| 58 |
+
tts_speech = self.hift.inference(mel=tts_mel).cpu()
|
| 59 |
+
torch.cuda.empty_cache()
|
| 60 |
+
return {'tts_speech': tts_speech}
|
CosyVoice/cosyvoice/dataset/__init__.py
ADDED
|
File without changes
|
CosyVoice/cosyvoice/dataset/dataset.py
ADDED
|
@@ -0,0 +1,160 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) 2021 Mobvoi Inc. (authors: Binbin Zhang)
|
| 2 |
+
# 2024 Alibaba Inc (authors: Xiang Lyu)
|
| 3 |
+
#
|
| 4 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 5 |
+
# you may not use this file except in compliance with the License.
|
| 6 |
+
# You may obtain a copy of the License at
|
| 7 |
+
#
|
| 8 |
+
# http://www.apache.org/licenses/LICENSE-2.0
|
| 9 |
+
#
|
| 10 |
+
# Unless required by applicable law or agreed to in writing, software
|
| 11 |
+
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 12 |
+
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 13 |
+
# See the License for the specific language governing permissions and
|
| 14 |
+
# limitations under the License.
|
| 15 |
+
|
| 16 |
+
import random
|
| 17 |
+
import json
|
| 18 |
+
import math
|
| 19 |
+
from functools import partial
|
| 20 |
+
|
| 21 |
+
import torch
|
| 22 |
+
import torch.distributed as dist
|
| 23 |
+
from torch.utils.data import IterableDataset
|
| 24 |
+
from cosyvoice.utils.file_utils import read_lists, read_json_lists
|
| 25 |
+
|
| 26 |
+
|
| 27 |
+
class Processor(IterableDataset):
|
| 28 |
+
|
| 29 |
+
def __init__(self, source, f, *args, **kw):
|
| 30 |
+
assert callable(f)
|
| 31 |
+
self.source = source
|
| 32 |
+
self.f = f
|
| 33 |
+
self.args = args
|
| 34 |
+
self.kw = kw
|
| 35 |
+
|
| 36 |
+
def set_epoch(self, epoch):
|
| 37 |
+
self.source.set_epoch(epoch)
|
| 38 |
+
|
| 39 |
+
def __iter__(self):
|
| 40 |
+
""" Return an iterator over the source dataset processed by the
|
| 41 |
+
given processor.
|
| 42 |
+
"""
|
| 43 |
+
assert self.source is not None
|
| 44 |
+
assert callable(self.f)
|
| 45 |
+
return self.f(iter(self.source), *self.args, **self.kw)
|
| 46 |
+
|
| 47 |
+
def apply(self, f):
|
| 48 |
+
assert callable(f)
|
| 49 |
+
return Processor(self, f, *self.args, **self.kw)
|
| 50 |
+
|
| 51 |
+
|
| 52 |
+
class DistributedSampler:
|
| 53 |
+
|
| 54 |
+
def __init__(self, shuffle=True, partition=True):
|
| 55 |
+
self.epoch = -1
|
| 56 |
+
self.update()
|
| 57 |
+
self.shuffle = shuffle
|
| 58 |
+
self.partition = partition
|
| 59 |
+
|
| 60 |
+
def update(self):
|
| 61 |
+
assert dist.is_available()
|
| 62 |
+
if dist.is_initialized():
|
| 63 |
+
self.rank = dist.get_rank()
|
| 64 |
+
self.world_size = dist.get_world_size()
|
| 65 |
+
else:
|
| 66 |
+
self.rank = 0
|
| 67 |
+
self.world_size = 1
|
| 68 |
+
worker_info = torch.utils.data.get_worker_info()
|
| 69 |
+
if worker_info is None:
|
| 70 |
+
self.worker_id = 0
|
| 71 |
+
self.num_workers = 1
|
| 72 |
+
else:
|
| 73 |
+
self.worker_id = worker_info.id
|
| 74 |
+
self.num_workers = worker_info.num_workers
|
| 75 |
+
return dict(rank=self.rank,
|
| 76 |
+
world_size=self.world_size,
|
| 77 |
+
worker_id=self.worker_id,
|
| 78 |
+
num_workers=self.num_workers)
|
| 79 |
+
|
| 80 |
+
def set_epoch(self, epoch):
|
| 81 |
+
self.epoch = epoch
|
| 82 |
+
|
| 83 |
+
def sample(self, data):
|
| 84 |
+
""" Sample data according to rank/world_size/num_workers
|
| 85 |
+
|
| 86 |
+
Args:
|
| 87 |
+
data(List): input data list
|
| 88 |
+
|
| 89 |
+
Returns:
|
| 90 |
+
List: data list after sample
|
| 91 |
+
"""
|
| 92 |
+
data = list(range(len(data)))
|
| 93 |
+
# force datalist even
|
| 94 |
+
if self.partition:
|
| 95 |
+
if self.shuffle:
|
| 96 |
+
random.Random(self.epoch).shuffle(data)
|
| 97 |
+
if len(data) < self.world_size:
|
| 98 |
+
data = data * math.ceil(self.world_size / len(data))
|
| 99 |
+
data = data[:self.world_size]
|
| 100 |
+
data = data[self.rank::self.world_size]
|
| 101 |
+
if len(data) < self.num_workers:
|
| 102 |
+
data = data * math.ceil(self.num_workers / len(data))
|
| 103 |
+
data = data[:self.num_workers]
|
| 104 |
+
data = data[self.worker_id::self.num_workers]
|
| 105 |
+
return data
|
| 106 |
+
|
| 107 |
+
|
| 108 |
+
class DataList(IterableDataset):
|
| 109 |
+
|
| 110 |
+
def __init__(self, lists, shuffle=True, partition=True):
|
| 111 |
+
self.lists = lists
|
| 112 |
+
self.sampler = DistributedSampler(shuffle, partition)
|
| 113 |
+
|
| 114 |
+
def set_epoch(self, epoch):
|
| 115 |
+
self.sampler.set_epoch(epoch)
|
| 116 |
+
|
| 117 |
+
def __iter__(self):
|
| 118 |
+
sampler_info = self.sampler.update()
|
| 119 |
+
indexes = self.sampler.sample(self.lists)
|
| 120 |
+
for index in indexes:
|
| 121 |
+
data = dict(src=self.lists[index])
|
| 122 |
+
data.update(sampler_info)
|
| 123 |
+
yield data
|
| 124 |
+
|
| 125 |
+
|
| 126 |
+
def Dataset(data_list_file,
|
| 127 |
+
data_pipeline,
|
| 128 |
+
mode='train',
|
| 129 |
+
shuffle=True,
|
| 130 |
+
partition=True,
|
| 131 |
+
tts_file='',
|
| 132 |
+
prompt_utt2data=''):
|
| 133 |
+
""" Construct dataset from arguments
|
| 134 |
+
|
| 135 |
+
We have two shuffle stage in the Dataset. The first is global
|
| 136 |
+
shuffle at shards tar/raw file level. The second is global shuffle
|
| 137 |
+
at training samples level.
|
| 138 |
+
|
| 139 |
+
Args:
|
| 140 |
+
data_type(str): raw/shard
|
| 141 |
+
tokenizer (BaseTokenizer): tokenizer to tokenize
|
| 142 |
+
partition(bool): whether to do data partition in terms of rank
|
| 143 |
+
"""
|
| 144 |
+
assert mode in ['train', 'inference']
|
| 145 |
+
lists = read_lists(data_list_file)
|
| 146 |
+
if mode == 'inference':
|
| 147 |
+
with open(tts_file) as f:
|
| 148 |
+
tts_data = json.load(f)
|
| 149 |
+
utt2lists = read_json_lists(prompt_utt2data)
|
| 150 |
+
# filter unnecessary file in inference mode
|
| 151 |
+
lists = list(set([utt2lists[utt] for utt in tts_data.keys() if utt2lists[utt] in lists]))
|
| 152 |
+
dataset = DataList(lists,
|
| 153 |
+
shuffle=shuffle,
|
| 154 |
+
partition=partition)
|
| 155 |
+
if mode == 'inference':
|
| 156 |
+
# map partial arg tts_data in inference mode
|
| 157 |
+
data_pipeline[0] = partial(data_pipeline[0], tts_data=tts_data)
|
| 158 |
+
for func in data_pipeline:
|
| 159 |
+
dataset = Processor(dataset, func, mode=mode)
|
| 160 |
+
return dataset
|
CosyVoice/cosyvoice/dataset/processor.py
ADDED
|
@@ -0,0 +1,369 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) 2024 Alibaba Inc (authors: Xiang Lyu)
|
| 2 |
+
#
|
| 3 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 4 |
+
# you may not use this file except in compliance with the License.
|
| 5 |
+
# You may obtain a copy of the License at
|
| 6 |
+
#
|
| 7 |
+
# http://www.apache.org/licenses/LICENSE-2.0
|
| 8 |
+
#
|
| 9 |
+
# Unless required by applicable law or agreed to in writing, software
|
| 10 |
+
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 11 |
+
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 12 |
+
# See the License for the specific language governing permissions and
|
| 13 |
+
# limitations under the License.
|
| 14 |
+
import logging
|
| 15 |
+
import random
|
| 16 |
+
|
| 17 |
+
import pyarrow.parquet as pq
|
| 18 |
+
from io import BytesIO
|
| 19 |
+
import torch
|
| 20 |
+
import torchaudio
|
| 21 |
+
from torch.nn.utils.rnn import pad_sequence
|
| 22 |
+
import torch.nn.functional as F
|
| 23 |
+
|
| 24 |
+
torchaudio.set_audio_backend('soundfile')
|
| 25 |
+
|
| 26 |
+
AUDIO_FORMAT_SETS = set(['flac', 'mp3', 'm4a', 'ogg', 'opus', 'wav', 'wma'])
|
| 27 |
+
|
| 28 |
+
|
| 29 |
+
def parquet_opener(data, mode='train', tts_data={}):
|
| 30 |
+
""" Give url or local file, return file descriptor
|
| 31 |
+
Inplace operation.
|
| 32 |
+
|
| 33 |
+
Args:
|
| 34 |
+
data(Iterable[str]): url or local file list
|
| 35 |
+
|
| 36 |
+
Returns:
|
| 37 |
+
Iterable[{src, stream}]
|
| 38 |
+
"""
|
| 39 |
+
for sample in data:
|
| 40 |
+
assert 'src' in sample
|
| 41 |
+
url = sample['src']
|
| 42 |
+
try:
|
| 43 |
+
df = pq.read_table(url).to_pandas()
|
| 44 |
+
for i in range(len(df)):
|
| 45 |
+
if mode == 'inference' and df.loc[i, 'utt'] not in tts_data:
|
| 46 |
+
continue
|
| 47 |
+
sample.update(dict(df.loc[i]))
|
| 48 |
+
if mode == 'train':
|
| 49 |
+
# NOTE do not return sample directly, must initialize a new dict
|
| 50 |
+
yield {**sample}
|
| 51 |
+
else:
|
| 52 |
+
for index, text in enumerate(tts_data[df.loc[i, 'utt']]):
|
| 53 |
+
yield {**sample, 'tts_index': index, 'tts_text': text}
|
| 54 |
+
except Exception as ex:
|
| 55 |
+
logging.warning('Failed to open {}, ex info {}'.format(url, ex))
|
| 56 |
+
|
| 57 |
+
def filter(data,
|
| 58 |
+
max_length=10240,
|
| 59 |
+
min_length=10,
|
| 60 |
+
token_max_length=200,
|
| 61 |
+
token_min_length=1,
|
| 62 |
+
min_output_input_ratio=0.0005,
|
| 63 |
+
max_output_input_ratio=1,
|
| 64 |
+
mode='train'):
|
| 65 |
+
""" Filter sample according to feature and label length
|
| 66 |
+
Inplace operation.
|
| 67 |
+
|
| 68 |
+
Args::
|
| 69 |
+
data: Iterable[{key, wav, label, sample_rate}]
|
| 70 |
+
max_length: drop utterance which is greater than max_length(10ms)
|
| 71 |
+
min_length: drop utterance which is less than min_length(10ms)
|
| 72 |
+
token_max_length: drop utterance which is greater than
|
| 73 |
+
token_max_length, especially when use char unit for
|
| 74 |
+
english modeling
|
| 75 |
+
token_min_length: drop utterance which is
|
| 76 |
+
less than token_max_length
|
| 77 |
+
min_output_input_ratio: minimal ration of
|
| 78 |
+
token_length / feats_length(10ms)
|
| 79 |
+
max_output_input_ratio: maximum ration of
|
| 80 |
+
token_length / feats_length(10ms)
|
| 81 |
+
|
| 82 |
+
Returns:
|
| 83 |
+
Iterable[{key, wav, label, sample_rate}]
|
| 84 |
+
"""
|
| 85 |
+
for sample in data:
|
| 86 |
+
sample['speech'], sample['sample_rate'] = torchaudio.load(BytesIO(sample['audio_data']))
|
| 87 |
+
del sample['audio_data']
|
| 88 |
+
# sample['wav'] is torch.Tensor, we have 100 frames every second
|
| 89 |
+
num_frames = sample['speech'].size(1) / sample['sample_rate'] * 100
|
| 90 |
+
if num_frames < min_length:
|
| 91 |
+
continue
|
| 92 |
+
if num_frames > max_length:
|
| 93 |
+
continue
|
| 94 |
+
if len(sample['text_token']) < token_min_length:
|
| 95 |
+
continue
|
| 96 |
+
if len(sample['text_token']) > token_max_length:
|
| 97 |
+
continue
|
| 98 |
+
if len(sample['speech_token']) == 0:
|
| 99 |
+
continue
|
| 100 |
+
if num_frames != 0:
|
| 101 |
+
if len(sample['text_token']) / num_frames < min_output_input_ratio:
|
| 102 |
+
continue
|
| 103 |
+
if len(sample['text_token']) / num_frames > max_output_input_ratio:
|
| 104 |
+
continue
|
| 105 |
+
yield sample
|
| 106 |
+
|
| 107 |
+
|
| 108 |
+
def resample(data, resample_rate=22050, min_sample_rate=16000, mode='train'):
|
| 109 |
+
""" Resample data.
|
| 110 |
+
Inplace operation.
|
| 111 |
+
|
| 112 |
+
Args:
|
| 113 |
+
data: Iterable[{key, wav, label, sample_rate}]
|
| 114 |
+
resample_rate: target resample rate
|
| 115 |
+
|
| 116 |
+
Returns:
|
| 117 |
+
Iterable[{key, wav, label, sample_rate}]
|
| 118 |
+
"""
|
| 119 |
+
for sample in data:
|
| 120 |
+
assert 'sample_rate' in sample
|
| 121 |
+
assert 'speech' in sample
|
| 122 |
+
sample_rate = sample['sample_rate']
|
| 123 |
+
waveform = sample['speech']
|
| 124 |
+
if sample_rate != resample_rate:
|
| 125 |
+
if sample_rate < min_sample_rate:
|
| 126 |
+
continue
|
| 127 |
+
sample['sample_rate'] = resample_rate
|
| 128 |
+
sample['speech'] = torchaudio.transforms.Resample(
|
| 129 |
+
orig_freq=sample_rate, new_freq=resample_rate)(waveform)
|
| 130 |
+
max_val = sample['speech'].abs().max()
|
| 131 |
+
if max_val > 1:
|
| 132 |
+
sample['speech'] /= max_val
|
| 133 |
+
yield sample
|
| 134 |
+
|
| 135 |
+
|
| 136 |
+
def compute_fbank(data,
|
| 137 |
+
feat_extractor,
|
| 138 |
+
mode='train'):
|
| 139 |
+
""" Extract fbank
|
| 140 |
+
|
| 141 |
+
Args:
|
| 142 |
+
data: Iterable[{key, wav, label, sample_rate}]
|
| 143 |
+
|
| 144 |
+
Returns:
|
| 145 |
+
Iterable[{key, feat, label}]
|
| 146 |
+
"""
|
| 147 |
+
for sample in data:
|
| 148 |
+
assert 'sample_rate' in sample
|
| 149 |
+
assert 'speech' in sample
|
| 150 |
+
assert 'utt' in sample
|
| 151 |
+
assert 'text_token' in sample
|
| 152 |
+
waveform = sample['speech']
|
| 153 |
+
mat = feat_extractor(waveform).squeeze(dim=0).transpose(0, 1)
|
| 154 |
+
sample['speech_feat'] = mat
|
| 155 |
+
del sample['speech']
|
| 156 |
+
yield sample
|
| 157 |
+
|
| 158 |
+
|
| 159 |
+
def parse_embedding(data, normalize, mode='train'):
|
| 160 |
+
""" Parse utt_embedding/spk_embedding
|
| 161 |
+
|
| 162 |
+
Args:
|
| 163 |
+
data: Iterable[{key, wav, label, sample_rate}]
|
| 164 |
+
|
| 165 |
+
Returns:
|
| 166 |
+
Iterable[{key, feat, label}]
|
| 167 |
+
"""
|
| 168 |
+
for sample in data:
|
| 169 |
+
sample['utt_embedding'] = torch.tensor(sample['utt_embedding'], dtype=torch.float32)
|
| 170 |
+
sample['spk_embedding'] = torch.tensor(sample['spk_embedding'], dtype=torch.float32)
|
| 171 |
+
if normalize:
|
| 172 |
+
sample['utt_embedding'] = F.normalize(sample['utt_embedding'], dim=0)
|
| 173 |
+
sample['spk_embedding'] = F.normalize(sample['spk_embedding'], dim=0)
|
| 174 |
+
yield sample
|
| 175 |
+
|
| 176 |
+
|
| 177 |
+
def tokenize(data, get_tokenizer, allowed_special, mode='train'):
|
| 178 |
+
""" Decode text to chars or BPE
|
| 179 |
+
Inplace operation
|
| 180 |
+
|
| 181 |
+
Args:
|
| 182 |
+
data: Iterable[{key, wav, txt, sample_rate}]
|
| 183 |
+
|
| 184 |
+
Returns:
|
| 185 |
+
Iterable[{key, wav, txt, tokens, label, sample_rate}]
|
| 186 |
+
"""
|
| 187 |
+
tokenizer = get_tokenizer()
|
| 188 |
+
for sample in data:
|
| 189 |
+
assert 'text' in sample
|
| 190 |
+
sample['text_token'] = tokenizer.encode(sample['text'], allowed_special=allowed_special)
|
| 191 |
+
if mode == 'inference':
|
| 192 |
+
sample['tts_text_token'] = tokenizer.encode(sample['tts_text'], allowed_special=allowed_special)
|
| 193 |
+
yield sample
|
| 194 |
+
|
| 195 |
+
|
| 196 |
+
def shuffle(data, shuffle_size=10000, mode='train'):
|
| 197 |
+
""" Local shuffle the data
|
| 198 |
+
|
| 199 |
+
Args:
|
| 200 |
+
data: Iterable[{key, feat, label}]
|
| 201 |
+
shuffle_size: buffer size for shuffle
|
| 202 |
+
|
| 203 |
+
Returns:
|
| 204 |
+
Iterable[{key, feat, label}]
|
| 205 |
+
"""
|
| 206 |
+
buf = []
|
| 207 |
+
for sample in data:
|
| 208 |
+
buf.append(sample)
|
| 209 |
+
if len(buf) >= shuffle_size:
|
| 210 |
+
random.shuffle(buf)
|
| 211 |
+
for x in buf:
|
| 212 |
+
yield x
|
| 213 |
+
buf = []
|
| 214 |
+
# The sample left over
|
| 215 |
+
random.shuffle(buf)
|
| 216 |
+
for x in buf:
|
| 217 |
+
yield x
|
| 218 |
+
|
| 219 |
+
|
| 220 |
+
def sort(data, sort_size=500, mode='train'):
|
| 221 |
+
""" Sort the data by feature length.
|
| 222 |
+
Sort is used after shuffle and before batch, so we can group
|
| 223 |
+
utts with similar lengths into a batch, and `sort_size` should
|
| 224 |
+
be less than `shuffle_size`
|
| 225 |
+
|
| 226 |
+
Args:
|
| 227 |
+
data: Iterable[{key, feat, label}]
|
| 228 |
+
sort_size: buffer size for sort
|
| 229 |
+
|
| 230 |
+
Returns:
|
| 231 |
+
Iterable[{key, feat, label}]
|
| 232 |
+
"""
|
| 233 |
+
|
| 234 |
+
buf = []
|
| 235 |
+
for sample in data:
|
| 236 |
+
buf.append(sample)
|
| 237 |
+
if len(buf) >= sort_size:
|
| 238 |
+
buf.sort(key=lambda x: x['speech_feat'].size(0))
|
| 239 |
+
for x in buf:
|
| 240 |
+
yield x
|
| 241 |
+
buf = []
|
| 242 |
+
# The sample left over
|
| 243 |
+
buf.sort(key=lambda x: x['speech_feat'].size(0))
|
| 244 |
+
for x in buf:
|
| 245 |
+
yield x
|
| 246 |
+
|
| 247 |
+
|
| 248 |
+
def static_batch(data, batch_size=16):
|
| 249 |
+
""" Static batch the data by `batch_size`
|
| 250 |
+
|
| 251 |
+
Args:
|
| 252 |
+
data: Iterable[{key, feat, label}]
|
| 253 |
+
batch_size: batch size
|
| 254 |
+
|
| 255 |
+
Returns:
|
| 256 |
+
Iterable[List[{key, feat, label}]]
|
| 257 |
+
"""
|
| 258 |
+
buf = []
|
| 259 |
+
for sample in data:
|
| 260 |
+
buf.append(sample)
|
| 261 |
+
if len(buf) >= batch_size:
|
| 262 |
+
yield buf
|
| 263 |
+
buf = []
|
| 264 |
+
if len(buf) > 0:
|
| 265 |
+
yield buf
|
| 266 |
+
|
| 267 |
+
|
| 268 |
+
def dynamic_batch(data, max_frames_in_batch=12000, mode='train'):
|
| 269 |
+
""" Dynamic batch the data until the total frames in batch
|
| 270 |
+
reach `max_frames_in_batch`
|
| 271 |
+
|
| 272 |
+
Args:
|
| 273 |
+
data: Iterable[{key, feat, label}]
|
| 274 |
+
max_frames_in_batch: max_frames in one batch
|
| 275 |
+
|
| 276 |
+
Returns:
|
| 277 |
+
Iterable[List[{key, feat, label}]]
|
| 278 |
+
"""
|
| 279 |
+
buf = []
|
| 280 |
+
longest_frames = 0
|
| 281 |
+
for sample in data:
|
| 282 |
+
assert 'speech_feat' in sample
|
| 283 |
+
assert isinstance(sample['speech_feat'], torch.Tensor)
|
| 284 |
+
new_sample_frames = sample['speech_feat'].size(0)
|
| 285 |
+
longest_frames = max(longest_frames, new_sample_frames)
|
| 286 |
+
frames_after_padding = longest_frames * (len(buf) + 1)
|
| 287 |
+
if frames_after_padding > max_frames_in_batch:
|
| 288 |
+
yield buf
|
| 289 |
+
buf = [sample]
|
| 290 |
+
longest_frames = new_sample_frames
|
| 291 |
+
else:
|
| 292 |
+
buf.append(sample)
|
| 293 |
+
if len(buf) > 0:
|
| 294 |
+
yield buf
|
| 295 |
+
|
| 296 |
+
|
| 297 |
+
def batch(data, batch_type='static', batch_size=16, max_frames_in_batch=12000, mode='train'):
|
| 298 |
+
""" Wrapper for static/dynamic batch
|
| 299 |
+
"""
|
| 300 |
+
if mode == 'inference':
|
| 301 |
+
return static_batch(data, 1)
|
| 302 |
+
else:
|
| 303 |
+
if batch_type == 'static':
|
| 304 |
+
return static_batch(data, batch_size)
|
| 305 |
+
elif batch_type == 'dynamic':
|
| 306 |
+
return dynamic_batch(data, max_frames_in_batch)
|
| 307 |
+
else:
|
| 308 |
+
logging.fatal('Unsupported batch type {}'.format(batch_type))
|
| 309 |
+
|
| 310 |
+
|
| 311 |
+
def padding(data, use_spk_embedding, mode='train'):
|
| 312 |
+
""" Padding the data into training data
|
| 313 |
+
|
| 314 |
+
Args:
|
| 315 |
+
data: Iterable[List[{key, feat, label}]]
|
| 316 |
+
|
| 317 |
+
Returns:
|
| 318 |
+
Iterable[Tuple(keys, feats, labels, feats lengths, label lengths)]
|
| 319 |
+
"""
|
| 320 |
+
for sample in data:
|
| 321 |
+
assert isinstance(sample, list)
|
| 322 |
+
speech_feat_len = torch.tensor([x['speech_feat'].size(1) for x in sample],
|
| 323 |
+
dtype=torch.int32)
|
| 324 |
+
order = torch.argsort(speech_feat_len, descending=True)
|
| 325 |
+
|
| 326 |
+
utts = [sample[i]['utt'] for i in order]
|
| 327 |
+
speech_token = [torch.tensor(sample[i]['speech_token']) for i in order]
|
| 328 |
+
speech_token_len = torch.tensor([i.size(0) for i in speech_token], dtype=torch.int32)
|
| 329 |
+
speech_token = pad_sequence(speech_token,
|
| 330 |
+
batch_first=True,
|
| 331 |
+
padding_value=0)
|
| 332 |
+
speech_feat = [sample[i]['speech_feat'] for i in order]
|
| 333 |
+
speech_feat_len = torch.tensor([i.size(0) for i in speech_feat], dtype=torch.int32)
|
| 334 |
+
speech_feat = pad_sequence(speech_feat,
|
| 335 |
+
batch_first=True,
|
| 336 |
+
padding_value=0)
|
| 337 |
+
text = [sample[i]['text'] for i in order]
|
| 338 |
+
text_token = [torch.tensor(sample[i]['text_token']) for i in order]
|
| 339 |
+
text_token_len = torch.tensor([i.size(0) for i in text_token], dtype=torch.int32)
|
| 340 |
+
text_token = pad_sequence(text_token, batch_first=True, padding_value=0)
|
| 341 |
+
utt_embedding = torch.stack([sample[i]['utt_embedding'] for i in order], dim=0)
|
| 342 |
+
spk_embedding = torch.stack([sample[i]['spk_embedding'] for i in order], dim=0)
|
| 343 |
+
batch = {
|
| 344 |
+
"utts": utts,
|
| 345 |
+
"speech_token": speech_token,
|
| 346 |
+
"speech_token_len": speech_token_len,
|
| 347 |
+
"speech_feat": speech_feat,
|
| 348 |
+
"speech_feat_len": speech_feat_len,
|
| 349 |
+
"text": text,
|
| 350 |
+
"text_token": text_token,
|
| 351 |
+
"text_token_len": text_token_len,
|
| 352 |
+
"utt_embedding": utt_embedding,
|
| 353 |
+
"spk_embedding": spk_embedding,
|
| 354 |
+
}
|
| 355 |
+
if mode == 'inference':
|
| 356 |
+
tts_text = [sample[i]['tts_text'] for i in order]
|
| 357 |
+
tts_index = [sample[i]['tts_index'] for i in order]
|
| 358 |
+
tts_text_token = [torch.tensor(sample[i]['tts_text_token']) for i in order]
|
| 359 |
+
tts_text_token_len = torch.tensor([i.size(0) for i in tts_text_token], dtype=torch.int32)
|
| 360 |
+
tts_text_token = pad_sequence(tts_text_token, batch_first=True, padding_value=-1)
|
| 361 |
+
batch.update({'tts_text': tts_text,
|
| 362 |
+
'tts_index': tts_index,
|
| 363 |
+
'tts_text_token': tts_text_token,
|
| 364 |
+
'tts_text_token_len': tts_text_token_len})
|
| 365 |
+
if use_spk_embedding is True:
|
| 366 |
+
batch["embedding"] = batch["spk_embedding"]
|
| 367 |
+
else:
|
| 368 |
+
batch["embedding"] = batch["utt_embedding"]
|
| 369 |
+
yield batch
|
CosyVoice/cosyvoice/flow/decoder.py
ADDED
|
@@ -0,0 +1,222 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) 2024 Alibaba Inc (authors: Xiang Lyu, Zhihao Du)
|
| 2 |
+
#
|
| 3 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 4 |
+
# you may not use this file except in compliance with the License.
|
| 5 |
+
# You may obtain a copy of the License at
|
| 6 |
+
#
|
| 7 |
+
# http://www.apache.org/licenses/LICENSE-2.0
|
| 8 |
+
#
|
| 9 |
+
# Unless required by applicable law or agreed to in writing, software
|
| 10 |
+
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 11 |
+
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 12 |
+
# See the License for the specific language governing permissions and
|
| 13 |
+
# limitations under the License.
|
| 14 |
+
import torch
|
| 15 |
+
import torch.nn as nn
|
| 16 |
+
from einops import pack, rearrange, repeat
|
| 17 |
+
from matcha.models.components.decoder import SinusoidalPosEmb, Block1D, ResnetBlock1D, Downsample1D, TimestepEmbedding, Upsample1D
|
| 18 |
+
from matcha.models.components.transformer import BasicTransformerBlock
|
| 19 |
+
|
| 20 |
+
|
| 21 |
+
class ConditionalDecoder(nn.Module):
|
| 22 |
+
def __init__(
|
| 23 |
+
self,
|
| 24 |
+
in_channels,
|
| 25 |
+
out_channels,
|
| 26 |
+
channels=(256, 256),
|
| 27 |
+
dropout=0.05,
|
| 28 |
+
attention_head_dim=64,
|
| 29 |
+
n_blocks=1,
|
| 30 |
+
num_mid_blocks=2,
|
| 31 |
+
num_heads=4,
|
| 32 |
+
act_fn="snake",
|
| 33 |
+
):
|
| 34 |
+
"""
|
| 35 |
+
This decoder requires an input with the same shape of the target. So, if your text content
|
| 36 |
+
is shorter or longer than the outputs, please re-sampling it before feeding to the decoder.
|
| 37 |
+
"""
|
| 38 |
+
super().__init__()
|
| 39 |
+
channels = tuple(channels)
|
| 40 |
+
self.in_channels = in_channels
|
| 41 |
+
self.out_channels = out_channels
|
| 42 |
+
|
| 43 |
+
self.time_embeddings = SinusoidalPosEmb(in_channels)
|
| 44 |
+
time_embed_dim = channels[0] * 4
|
| 45 |
+
self.time_mlp = TimestepEmbedding(
|
| 46 |
+
in_channels=in_channels,
|
| 47 |
+
time_embed_dim=time_embed_dim,
|
| 48 |
+
act_fn="silu",
|
| 49 |
+
)
|
| 50 |
+
self.down_blocks = nn.ModuleList([])
|
| 51 |
+
self.mid_blocks = nn.ModuleList([])
|
| 52 |
+
self.up_blocks = nn.ModuleList([])
|
| 53 |
+
|
| 54 |
+
output_channel = in_channels
|
| 55 |
+
for i in range(len(channels)): # pylint: disable=consider-using-enumerate
|
| 56 |
+
input_channel = output_channel
|
| 57 |
+
output_channel = channels[i]
|
| 58 |
+
is_last = i == len(channels) - 1
|
| 59 |
+
resnet = ResnetBlock1D(dim=input_channel, dim_out=output_channel, time_emb_dim=time_embed_dim)
|
| 60 |
+
transformer_blocks = nn.ModuleList(
|
| 61 |
+
[
|
| 62 |
+
BasicTransformerBlock(
|
| 63 |
+
dim=output_channel,
|
| 64 |
+
num_attention_heads=num_heads,
|
| 65 |
+
attention_head_dim=attention_head_dim,
|
| 66 |
+
dropout=dropout,
|
| 67 |
+
activation_fn=act_fn,
|
| 68 |
+
)
|
| 69 |
+
for _ in range(n_blocks)
|
| 70 |
+
]
|
| 71 |
+
)
|
| 72 |
+
downsample = (
|
| 73 |
+
Downsample1D(output_channel) if not is_last else nn.Conv1d(output_channel, output_channel, 3, padding=1)
|
| 74 |
+
)
|
| 75 |
+
self.down_blocks.append(nn.ModuleList([resnet, transformer_blocks, downsample]))
|
| 76 |
+
|
| 77 |
+
for i in range(num_mid_blocks):
|
| 78 |
+
input_channel = channels[-1]
|
| 79 |
+
out_channels = channels[-1]
|
| 80 |
+
resnet = ResnetBlock1D(dim=input_channel, dim_out=output_channel, time_emb_dim=time_embed_dim)
|
| 81 |
+
|
| 82 |
+
transformer_blocks = nn.ModuleList(
|
| 83 |
+
[
|
| 84 |
+
BasicTransformerBlock(
|
| 85 |
+
dim=output_channel,
|
| 86 |
+
num_attention_heads=num_heads,
|
| 87 |
+
attention_head_dim=attention_head_dim,
|
| 88 |
+
dropout=dropout,
|
| 89 |
+
activation_fn=act_fn,
|
| 90 |
+
)
|
| 91 |
+
for _ in range(n_blocks)
|
| 92 |
+
]
|
| 93 |
+
)
|
| 94 |
+
|
| 95 |
+
self.mid_blocks.append(nn.ModuleList([resnet, transformer_blocks]))
|
| 96 |
+
|
| 97 |
+
channels = channels[::-1] + (channels[0],)
|
| 98 |
+
for i in range(len(channels) - 1):
|
| 99 |
+
input_channel = channels[i] * 2
|
| 100 |
+
output_channel = channels[i + 1]
|
| 101 |
+
is_last = i == len(channels) - 2
|
| 102 |
+
resnet = ResnetBlock1D(
|
| 103 |
+
dim=input_channel,
|
| 104 |
+
dim_out=output_channel,
|
| 105 |
+
time_emb_dim=time_embed_dim,
|
| 106 |
+
)
|
| 107 |
+
transformer_blocks = nn.ModuleList(
|
| 108 |
+
[
|
| 109 |
+
BasicTransformerBlock(
|
| 110 |
+
dim=output_channel,
|
| 111 |
+
num_attention_heads=num_heads,
|
| 112 |
+
attention_head_dim=attention_head_dim,
|
| 113 |
+
dropout=dropout,
|
| 114 |
+
activation_fn=act_fn,
|
| 115 |
+
)
|
| 116 |
+
for _ in range(n_blocks)
|
| 117 |
+
]
|
| 118 |
+
)
|
| 119 |
+
upsample = (
|
| 120 |
+
Upsample1D(output_channel, use_conv_transpose=True)
|
| 121 |
+
if not is_last
|
| 122 |
+
else nn.Conv1d(output_channel, output_channel, 3, padding=1)
|
| 123 |
+
)
|
| 124 |
+
self.up_blocks.append(nn.ModuleList([resnet, transformer_blocks, upsample]))
|
| 125 |
+
self.final_block = Block1D(channels[-1], channels[-1])
|
| 126 |
+
self.final_proj = nn.Conv1d(channels[-1], self.out_channels, 1)
|
| 127 |
+
self.initialize_weights()
|
| 128 |
+
|
| 129 |
+
|
| 130 |
+
def initialize_weights(self):
|
| 131 |
+
for m in self.modules():
|
| 132 |
+
if isinstance(m, nn.Conv1d):
|
| 133 |
+
nn.init.kaiming_normal_(m.weight, nonlinearity="relu")
|
| 134 |
+
if m.bias is not None:
|
| 135 |
+
nn.init.constant_(m.bias, 0)
|
| 136 |
+
elif isinstance(m, nn.GroupNorm):
|
| 137 |
+
nn.init.constant_(m.weight, 1)
|
| 138 |
+
nn.init.constant_(m.bias, 0)
|
| 139 |
+
elif isinstance(m, nn.Linear):
|
| 140 |
+
nn.init.kaiming_normal_(m.weight, nonlinearity="relu")
|
| 141 |
+
if m.bias is not None:
|
| 142 |
+
nn.init.constant_(m.bias, 0)
|
| 143 |
+
|
| 144 |
+
def forward(self, x, mask, mu, t, spks=None, cond=None):
|
| 145 |
+
"""Forward pass of the UNet1DConditional model.
|
| 146 |
+
|
| 147 |
+
Args:
|
| 148 |
+
x (torch.Tensor): shape (batch_size, in_channels, time)
|
| 149 |
+
mask (_type_): shape (batch_size, 1, time)
|
| 150 |
+
t (_type_): shape (batch_size)
|
| 151 |
+
spks (_type_, optional): shape: (batch_size, condition_channels). Defaults to None.
|
| 152 |
+
cond (_type_, optional): placeholder for future use. Defaults to None.
|
| 153 |
+
|
| 154 |
+
Raises:
|
| 155 |
+
ValueError: _description_
|
| 156 |
+
ValueError: _description_
|
| 157 |
+
|
| 158 |
+
Returns:
|
| 159 |
+
_type_: _description_
|
| 160 |
+
"""
|
| 161 |
+
|
| 162 |
+
t = self.time_embeddings(t)
|
| 163 |
+
t = self.time_mlp(t)
|
| 164 |
+
|
| 165 |
+
x = pack([x, mu], "b * t")[0]
|
| 166 |
+
|
| 167 |
+
if spks is not None:
|
| 168 |
+
spks = repeat(spks, "b c -> b c t", t=x.shape[-1])
|
| 169 |
+
x = pack([x, spks], "b * t")[0]
|
| 170 |
+
if cond is not None:
|
| 171 |
+
x = pack([x, cond], "b * t")[0]
|
| 172 |
+
|
| 173 |
+
hiddens = []
|
| 174 |
+
masks = [mask]
|
| 175 |
+
for resnet, transformer_blocks, downsample in self.down_blocks:
|
| 176 |
+
mask_down = masks[-1]
|
| 177 |
+
x = resnet(x, mask_down, t)
|
| 178 |
+
x = rearrange(x, "b c t -> b t c").contiguous()
|
| 179 |
+
attn_mask = torch.matmul(mask_down.transpose(1, 2).contiguous(), mask_down)
|
| 180 |
+
for transformer_block in transformer_blocks:
|
| 181 |
+
x = transformer_block(
|
| 182 |
+
hidden_states=x,
|
| 183 |
+
attention_mask=attn_mask,
|
| 184 |
+
timestep=t,
|
| 185 |
+
)
|
| 186 |
+
x = rearrange(x, "b t c -> b c t").contiguous()
|
| 187 |
+
hiddens.append(x) # Save hidden states for skip connections
|
| 188 |
+
x = downsample(x * mask_down)
|
| 189 |
+
masks.append(mask_down[:, :, ::2])
|
| 190 |
+
masks = masks[:-1]
|
| 191 |
+
mask_mid = masks[-1]
|
| 192 |
+
|
| 193 |
+
for resnet, transformer_blocks in self.mid_blocks:
|
| 194 |
+
x = resnet(x, mask_mid, t)
|
| 195 |
+
x = rearrange(x, "b c t -> b t c").contiguous()
|
| 196 |
+
attn_mask = torch.matmul(mask_mid.transpose(1, 2).contiguous(), mask_mid)
|
| 197 |
+
for transformer_block in transformer_blocks:
|
| 198 |
+
x = transformer_block(
|
| 199 |
+
hidden_states=x,
|
| 200 |
+
attention_mask=attn_mask,
|
| 201 |
+
timestep=t,
|
| 202 |
+
)
|
| 203 |
+
x = rearrange(x, "b t c -> b c t").contiguous()
|
| 204 |
+
|
| 205 |
+
for resnet, transformer_blocks, upsample in self.up_blocks:
|
| 206 |
+
mask_up = masks.pop()
|
| 207 |
+
skip = hiddens.pop()
|
| 208 |
+
x = pack([x[:, :, :skip.shape[-1]], skip], "b * t")[0]
|
| 209 |
+
x = resnet(x, mask_up, t)
|
| 210 |
+
x = rearrange(x, "b c t -> b t c").contiguous()
|
| 211 |
+
attn_mask = torch.matmul(mask_up.transpose(1, 2).contiguous(), mask_up)
|
| 212 |
+
for transformer_block in transformer_blocks:
|
| 213 |
+
x = transformer_block(
|
| 214 |
+
hidden_states=x,
|
| 215 |
+
attention_mask=attn_mask,
|
| 216 |
+
timestep=t,
|
| 217 |
+
)
|
| 218 |
+
x = rearrange(x, "b t c -> b c t").contiguous()
|
| 219 |
+
x = upsample(x * mask_up)
|
| 220 |
+
x = self.final_block(x, mask_up)
|
| 221 |
+
output = self.final_proj(x * mask_up)
|
| 222 |
+
return output * mask
|
CosyVoice/cosyvoice/flow/flow.py
ADDED
|
@@ -0,0 +1,141 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) 2024 Alibaba Inc (authors: Xiang Lyu, Zhihao Du)
|
| 2 |
+
#
|
| 3 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 4 |
+
# you may not use this file except in compliance with the License.
|
| 5 |
+
# You may obtain a copy of the License at
|
| 6 |
+
#
|
| 7 |
+
# http://www.apache.org/licenses/LICENSE-2.0
|
| 8 |
+
#
|
| 9 |
+
# Unless required by applicable law or agreed to in writing, software
|
| 10 |
+
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 11 |
+
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 12 |
+
# See the License for the specific language governing permissions and
|
| 13 |
+
# limitations under the License.
|
| 14 |
+
import logging
|
| 15 |
+
import random
|
| 16 |
+
from typing import Dict, Optional
|
| 17 |
+
import torch
|
| 18 |
+
import torch.nn as nn
|
| 19 |
+
from torch.nn import functional as F
|
| 20 |
+
from omegaconf import DictConfig
|
| 21 |
+
from cosyvoice.utils.mask import make_pad_mask
|
| 22 |
+
|
| 23 |
+
|
| 24 |
+
class MaskedDiffWithXvec(torch.nn.Module):
|
| 25 |
+
def __init__(self,
|
| 26 |
+
input_size: int = 512,
|
| 27 |
+
output_size: int = 80,
|
| 28 |
+
spk_embed_dim: int = 192,
|
| 29 |
+
output_type: str = "mel",
|
| 30 |
+
vocab_size: int = 4096,
|
| 31 |
+
input_frame_rate: int = 50,
|
| 32 |
+
only_mask_loss: bool = True,
|
| 33 |
+
encoder: torch.nn.Module = None,
|
| 34 |
+
length_regulator: torch.nn.Module = None,
|
| 35 |
+
decoder: torch.nn.Module = None,
|
| 36 |
+
decoder_conf: Dict = {'in_channels': 240, 'out_channel': 80, 'spk_emb_dim': 80, 'n_spks': 1, 'cfm_params': DictConfig({'sigma_min': 1e-06, 'solver': 'euler', 't_scheduler': 'cosine', 'training_cfg_rate': 0.2, 'inference_cfg_rate': 0.7, 'reg_loss_type': 'l1'}), 'decoder_params': {'channels': [256, 256], 'dropout': 0.0, 'attention_head_dim': 64, 'n_blocks': 4, 'num_mid_blocks': 12, 'num_heads': 8, 'act_fn': 'gelu'}},
|
| 37 |
+
mel_feat_conf: Dict = {'n_fft': 1024, 'num_mels': 80, 'sampling_rate': 22050, 'hop_size': 256, 'win_size': 1024, 'fmin': 0, 'fmax': 8000}):
|
| 38 |
+
super().__init__()
|
| 39 |
+
self.input_size = input_size
|
| 40 |
+
self.output_size = output_size
|
| 41 |
+
self.decoder_conf = decoder_conf
|
| 42 |
+
self.mel_feat_conf = mel_feat_conf
|
| 43 |
+
self.vocab_size = vocab_size
|
| 44 |
+
self.output_type = output_type
|
| 45 |
+
self.input_frame_rate = input_frame_rate
|
| 46 |
+
logging.info(f"input frame rate={self.input_frame_rate}")
|
| 47 |
+
self.input_embedding = nn.Embedding(vocab_size, input_size)
|
| 48 |
+
self.spk_embed_affine_layer = torch.nn.Linear(spk_embed_dim, output_size)
|
| 49 |
+
self.encoder = encoder
|
| 50 |
+
self.encoder_proj = torch.nn.Linear(self.encoder.output_size(), output_size)
|
| 51 |
+
self.decoder = decoder
|
| 52 |
+
self.length_regulator = length_regulator
|
| 53 |
+
self.only_mask_loss = only_mask_loss
|
| 54 |
+
|
| 55 |
+
def forward(
|
| 56 |
+
self,
|
| 57 |
+
batch: dict,
|
| 58 |
+
device: torch.device,
|
| 59 |
+
) -> Dict[str, Optional[torch.Tensor]]:
|
| 60 |
+
token = batch['speech_token'].to(device)
|
| 61 |
+
token_len = batch['speech_token_len'].to(device)
|
| 62 |
+
feat = batch['speech_feat'].to(device)
|
| 63 |
+
feat_len = batch['speech_feat_len'].to(device)
|
| 64 |
+
embedding = batch['embedding'].to(device)
|
| 65 |
+
|
| 66 |
+
# xvec projection
|
| 67 |
+
embedding = F.normalize(embedding, dim=1)
|
| 68 |
+
embedding = self.spk_embed_affine_layer(embedding)
|
| 69 |
+
|
| 70 |
+
# concat text and prompt_text
|
| 71 |
+
mask = (~make_pad_mask(token_len)).float().unsqueeze(-1).to(device)
|
| 72 |
+
token = self.input_embedding(torch.clamp(token, min=0)) * mask
|
| 73 |
+
|
| 74 |
+
# text encode
|
| 75 |
+
h, h_lengths = self.encoder(token, token_len)
|
| 76 |
+
h = self.encoder_proj(h)
|
| 77 |
+
h, h_lengths = self.length_regulator(h, feat_len)
|
| 78 |
+
|
| 79 |
+
# get conditions
|
| 80 |
+
conds = torch.zeros(feat.shape, device=token.device)
|
| 81 |
+
for i, j in enumerate(feat_len):
|
| 82 |
+
if random.random() < 0.5:
|
| 83 |
+
continue
|
| 84 |
+
index = random.randint(0, int(0.3 * j))
|
| 85 |
+
conds[i, :index] = feat[i, :index]
|
| 86 |
+
conds = conds.transpose(1, 2)
|
| 87 |
+
|
| 88 |
+
mask = (~make_pad_mask(feat_len)).to(h)
|
| 89 |
+
feat = F.interpolate(feat.unsqueeze(dim=1), size=h.shape[1:], mode="nearest").squeeze(dim=1)
|
| 90 |
+
loss, _ = self.decoder.compute_loss(
|
| 91 |
+
feat.transpose(1, 2).contiguous(),
|
| 92 |
+
mask.unsqueeze(1),
|
| 93 |
+
h.transpose(1, 2).contiguous(),
|
| 94 |
+
embedding,
|
| 95 |
+
cond=conds
|
| 96 |
+
)
|
| 97 |
+
return {'loss': loss}
|
| 98 |
+
|
| 99 |
+
@torch.inference_mode()
|
| 100 |
+
def inference(self,
|
| 101 |
+
token,
|
| 102 |
+
token_len,
|
| 103 |
+
prompt_token,
|
| 104 |
+
prompt_token_len,
|
| 105 |
+
prompt_feat,
|
| 106 |
+
prompt_feat_len,
|
| 107 |
+
embedding):
|
| 108 |
+
assert token.shape[0] == 1
|
| 109 |
+
# xvec projection
|
| 110 |
+
embedding = F.normalize(embedding, dim=1)
|
| 111 |
+
embedding = self.spk_embed_affine_layer(embedding)
|
| 112 |
+
|
| 113 |
+
# concat text and prompt_text
|
| 114 |
+
token, token_len = torch.concat([prompt_token, token], dim=1), prompt_token_len + token_len
|
| 115 |
+
mask = (~make_pad_mask(token_len)).float().unsqueeze(-1).to(embedding)
|
| 116 |
+
token = self.input_embedding(torch.clamp(token, min=0)) * mask
|
| 117 |
+
|
| 118 |
+
# text encode
|
| 119 |
+
h, h_lengths = self.encoder(token, token_len)
|
| 120 |
+
h = self.encoder_proj(h)
|
| 121 |
+
feat_len = (token_len / 50 * 22050 / 256).int()
|
| 122 |
+
h, h_lengths = self.length_regulator(h, feat_len)
|
| 123 |
+
|
| 124 |
+
# get conditions
|
| 125 |
+
conds = torch.zeros([1, feat_len.max().item(), self.output_size], device=token.device)
|
| 126 |
+
if prompt_feat.shape[1] != 0:
|
| 127 |
+
for i, j in enumerate(prompt_feat_len):
|
| 128 |
+
conds[i, :j] = prompt_feat[i]
|
| 129 |
+
conds = conds.transpose(1, 2)
|
| 130 |
+
|
| 131 |
+
mask = (~make_pad_mask(feat_len)).to(h)
|
| 132 |
+
feat = self.decoder(
|
| 133 |
+
mu=h.transpose(1, 2).contiguous(),
|
| 134 |
+
mask=mask.unsqueeze(1),
|
| 135 |
+
spks=embedding,
|
| 136 |
+
cond=conds,
|
| 137 |
+
n_timesteps=10
|
| 138 |
+
)
|
| 139 |
+
if prompt_feat.shape[1] != 0:
|
| 140 |
+
feat = feat[:, :, prompt_feat.shape[1]:]
|
| 141 |
+
return feat
|
CosyVoice/cosyvoice/flow/flow_matching.py
ADDED
|
@@ -0,0 +1,138 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) 2024 Alibaba Inc (authors: Xiang Lyu, Zhihao Du)
|
| 2 |
+
#
|
| 3 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 4 |
+
# you may not use this file except in compliance with the License.
|
| 5 |
+
# You may obtain a copy of the License at
|
| 6 |
+
#
|
| 7 |
+
# http://www.apache.org/licenses/LICENSE-2.0
|
| 8 |
+
#
|
| 9 |
+
# Unless required by applicable law or agreed to in writing, software
|
| 10 |
+
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 11 |
+
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 12 |
+
# See the License for the specific language governing permissions and
|
| 13 |
+
# limitations under the License.
|
| 14 |
+
import torch
|
| 15 |
+
import torch.nn.functional as F
|
| 16 |
+
from matcha.models.components.flow_matching import BASECFM
|
| 17 |
+
|
| 18 |
+
class ConditionalCFM(BASECFM):
|
| 19 |
+
def __init__(self, in_channels, cfm_params, n_spks=1, spk_emb_dim=64, estimator: torch.nn.Module = None):
|
| 20 |
+
super().__init__(
|
| 21 |
+
n_feats=in_channels,
|
| 22 |
+
cfm_params=cfm_params,
|
| 23 |
+
n_spks=n_spks,
|
| 24 |
+
spk_emb_dim=spk_emb_dim,
|
| 25 |
+
)
|
| 26 |
+
self.t_scheduler = cfm_params.t_scheduler
|
| 27 |
+
self.training_cfg_rate = cfm_params.training_cfg_rate
|
| 28 |
+
self.inference_cfg_rate = cfm_params.inference_cfg_rate
|
| 29 |
+
in_channels = in_channels + (spk_emb_dim if n_spks > 0 else 0)
|
| 30 |
+
# Just change the architecture of the estimator here
|
| 31 |
+
self.estimator = estimator
|
| 32 |
+
|
| 33 |
+
@torch.inference_mode()
|
| 34 |
+
def forward(self, mu, mask, n_timesteps, temperature=1.0, spks=None, cond=None):
|
| 35 |
+
"""Forward diffusion
|
| 36 |
+
|
| 37 |
+
Args:
|
| 38 |
+
mu (torch.Tensor): output of encoder
|
| 39 |
+
shape: (batch_size, n_feats, mel_timesteps)
|
| 40 |
+
mask (torch.Tensor): output_mask
|
| 41 |
+
shape: (batch_size, 1, mel_timesteps)
|
| 42 |
+
n_timesteps (int): number of diffusion steps
|
| 43 |
+
temperature (float, optional): temperature for scaling noise. Defaults to 1.0.
|
| 44 |
+
spks (torch.Tensor, optional): speaker ids. Defaults to None.
|
| 45 |
+
shape: (batch_size, spk_emb_dim)
|
| 46 |
+
cond: Not used but kept for future purposes
|
| 47 |
+
|
| 48 |
+
Returns:
|
| 49 |
+
sample: generated mel-spectrogram
|
| 50 |
+
shape: (batch_size, n_feats, mel_timesteps)
|
| 51 |
+
"""
|
| 52 |
+
z = torch.randn_like(mu) * temperature
|
| 53 |
+
t_span = torch.linspace(0, 1, n_timesteps + 1, device=mu.device)
|
| 54 |
+
if self.t_scheduler == 'cosine':
|
| 55 |
+
t_span = 1 - torch.cos(t_span * 0.5 * torch.pi)
|
| 56 |
+
return self.solve_euler(z, t_span=t_span, mu=mu, mask=mask, spks=spks, cond=cond)
|
| 57 |
+
|
| 58 |
+
def solve_euler(self, x, t_span, mu, mask, spks, cond):
|
| 59 |
+
"""
|
| 60 |
+
Fixed euler solver for ODEs.
|
| 61 |
+
Args:
|
| 62 |
+
x (torch.Tensor): random noise
|
| 63 |
+
t_span (torch.Tensor): n_timesteps interpolated
|
| 64 |
+
shape: (n_timesteps + 1,)
|
| 65 |
+
mu (torch.Tensor): output of encoder
|
| 66 |
+
shape: (batch_size, n_feats, mel_timesteps)
|
| 67 |
+
mask (torch.Tensor): output_mask
|
| 68 |
+
shape: (batch_size, 1, mel_timesteps)
|
| 69 |
+
spks (torch.Tensor, optional): speaker ids. Defaults to None.
|
| 70 |
+
shape: (batch_size, spk_emb_dim)
|
| 71 |
+
cond: Not used but kept for future purposes
|
| 72 |
+
"""
|
| 73 |
+
t, _, dt = t_span[0], t_span[-1], t_span[1] - t_span[0]
|
| 74 |
+
|
| 75 |
+
# I am storing this because I can later plot it by putting a debugger here and saving it to a file
|
| 76 |
+
# Or in future might add like a return_all_steps flag
|
| 77 |
+
sol = []
|
| 78 |
+
|
| 79 |
+
for step in range(1, len(t_span)):
|
| 80 |
+
dphi_dt = self.estimator(x, mask, mu, t, spks, cond)
|
| 81 |
+
# Classifier-Free Guidance inference introduced in VoiceBox
|
| 82 |
+
if self.inference_cfg_rate > 0:
|
| 83 |
+
cfg_dphi_dt = self.estimator(
|
| 84 |
+
x, mask,
|
| 85 |
+
torch.zeros_like(mu), t,
|
| 86 |
+
torch.zeros_like(spks) if spks is not None else None,
|
| 87 |
+
torch.zeros_like(cond)
|
| 88 |
+
)
|
| 89 |
+
dphi_dt = ((1.0 + self.inference_cfg_rate) * dphi_dt -
|
| 90 |
+
self.inference_cfg_rate * cfg_dphi_dt)
|
| 91 |
+
x = x + dt * dphi_dt
|
| 92 |
+
t = t + dt
|
| 93 |
+
sol.append(x)
|
| 94 |
+
if step < len(t_span) - 1:
|
| 95 |
+
dt = t_span[step + 1] - t
|
| 96 |
+
|
| 97 |
+
return sol[-1]
|
| 98 |
+
|
| 99 |
+
def compute_loss(self, x1, mask, mu, spks=None, cond=None):
|
| 100 |
+
"""Computes diffusion loss
|
| 101 |
+
|
| 102 |
+
Args:
|
| 103 |
+
x1 (torch.Tensor): Target
|
| 104 |
+
shape: (batch_size, n_feats, mel_timesteps)
|
| 105 |
+
mask (torch.Tensor): target mask
|
| 106 |
+
shape: (batch_size, 1, mel_timesteps)
|
| 107 |
+
mu (torch.Tensor): output of encoder
|
| 108 |
+
shape: (batch_size, n_feats, mel_timesteps)
|
| 109 |
+
spks (torch.Tensor, optional): speaker embedding. Defaults to None.
|
| 110 |
+
shape: (batch_size, spk_emb_dim)
|
| 111 |
+
|
| 112 |
+
Returns:
|
| 113 |
+
loss: conditional flow matching loss
|
| 114 |
+
y: conditional flow
|
| 115 |
+
shape: (batch_size, n_feats, mel_timesteps)
|
| 116 |
+
"""
|
| 117 |
+
b, _, t = mu.shape
|
| 118 |
+
|
| 119 |
+
# random timestep
|
| 120 |
+
t = torch.rand([b, 1, 1], device=mu.device, dtype=mu.dtype)
|
| 121 |
+
if self.t_scheduler == 'cosine':
|
| 122 |
+
t = 1 - torch.cos(t * 0.5 * torch.pi)
|
| 123 |
+
# sample noise p(x_0)
|
| 124 |
+
z = torch.randn_like(x1)
|
| 125 |
+
|
| 126 |
+
y = (1 - (1 - self.sigma_min) * t) * z + t * x1
|
| 127 |
+
u = x1 - (1 - self.sigma_min) * z
|
| 128 |
+
|
| 129 |
+
# during training, we randomly drop condition to trade off mode coverage and sample fidelity
|
| 130 |
+
if self.training_cfg_rate > 0:
|
| 131 |
+
cfg_mask = torch.rand(b, device=x1.device) > self.training_cfg_rate
|
| 132 |
+
mu = mu * cfg_mask.view(-1, 1, 1)
|
| 133 |
+
spks = spks * cfg_mask.view(-1, 1)
|
| 134 |
+
cond = cond * cfg_mask.view(-1, 1, 1)
|
| 135 |
+
|
| 136 |
+
pred = self.estimator(y, mask, mu, t.squeeze(), spks, cond)
|
| 137 |
+
loss = F.mse_loss(pred * mask, u * mask, reduction="sum") / (torch.sum(mask) * u.shape[1])
|
| 138 |
+
return loss, y
|
CosyVoice/cosyvoice/flow/length_regulator.py
ADDED
|
@@ -0,0 +1,49 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) 2024 Alibaba Inc (authors: Xiang Lyu, Zhihao Du)
|
| 2 |
+
#
|
| 3 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 4 |
+
# you may not use this file except in compliance with the License.
|
| 5 |
+
# You may obtain a copy of the License at
|
| 6 |
+
#
|
| 7 |
+
# http://www.apache.org/licenses/LICENSE-2.0
|
| 8 |
+
#
|
| 9 |
+
# Unless required by applicable law or agreed to in writing, software
|
| 10 |
+
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 11 |
+
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 12 |
+
# See the License for the specific language governing permissions and
|
| 13 |
+
# limitations under the License.
|
| 14 |
+
from typing import Tuple
|
| 15 |
+
import torch.nn as nn
|
| 16 |
+
from torch.nn import functional as F
|
| 17 |
+
from cosyvoice.utils.mask import make_pad_mask
|
| 18 |
+
|
| 19 |
+
|
| 20 |
+
class InterpolateRegulator(nn.Module):
|
| 21 |
+
def __init__(
|
| 22 |
+
self,
|
| 23 |
+
channels: int,
|
| 24 |
+
sampling_ratios: Tuple,
|
| 25 |
+
out_channels: int = None,
|
| 26 |
+
groups: int = 1,
|
| 27 |
+
):
|
| 28 |
+
super().__init__()
|
| 29 |
+
self.sampling_ratios = sampling_ratios
|
| 30 |
+
out_channels = out_channels or channels
|
| 31 |
+
model = nn.ModuleList([])
|
| 32 |
+
if len(sampling_ratios) > 0:
|
| 33 |
+
for _ in sampling_ratios:
|
| 34 |
+
module = nn.Conv1d(channels, channels, 3, 1, 1)
|
| 35 |
+
norm = nn.GroupNorm(groups, channels)
|
| 36 |
+
act = nn.Mish()
|
| 37 |
+
model.extend([module, norm, act])
|
| 38 |
+
model.append(
|
| 39 |
+
nn.Conv1d(channels, out_channels, 1, 1)
|
| 40 |
+
)
|
| 41 |
+
self.model = nn.Sequential(*model)
|
| 42 |
+
|
| 43 |
+
def forward(self, x, ylens=None):
|
| 44 |
+
# x in (B, T, D)
|
| 45 |
+
mask = (~make_pad_mask(ylens)).to(x).unsqueeze(-1)
|
| 46 |
+
x = F.interpolate(x.transpose(1, 2).contiguous(), size=ylens.max(), mode='nearest')
|
| 47 |
+
out = self.model(x).transpose(1, 2).contiguous()
|
| 48 |
+
olens = ylens
|
| 49 |
+
return out * mask, olens
|
CosyVoice/cosyvoice/hifigan/f0_predictor.py
ADDED
|
@@ -0,0 +1,55 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) 2024 Alibaba Inc (authors: Xiang Lyu, Kai Hu)
|
| 2 |
+
#
|
| 3 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 4 |
+
# you may not use this file except in compliance with the License.
|
| 5 |
+
# You may obtain a copy of the License at
|
| 6 |
+
#
|
| 7 |
+
# http://www.apache.org/licenses/LICENSE-2.0
|
| 8 |
+
#
|
| 9 |
+
# Unless required by applicable law or agreed to in writing, software
|
| 10 |
+
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 11 |
+
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 12 |
+
# See the License for the specific language governing permissions and
|
| 13 |
+
# limitations under the License.
|
| 14 |
+
import torch
|
| 15 |
+
import torch.nn as nn
|
| 16 |
+
from torch.nn.utils import weight_norm
|
| 17 |
+
|
| 18 |
+
|
| 19 |
+
class ConvRNNF0Predictor(nn.Module):
|
| 20 |
+
def __init__(self,
|
| 21 |
+
num_class: int = 1,
|
| 22 |
+
in_channels: int = 80,
|
| 23 |
+
cond_channels: int = 512
|
| 24 |
+
):
|
| 25 |
+
super().__init__()
|
| 26 |
+
|
| 27 |
+
self.num_class = num_class
|
| 28 |
+
self.condnet = nn.Sequential(
|
| 29 |
+
weight_norm(
|
| 30 |
+
nn.Conv1d(in_channels, cond_channels, kernel_size=3, padding=1)
|
| 31 |
+
),
|
| 32 |
+
nn.ELU(),
|
| 33 |
+
weight_norm(
|
| 34 |
+
nn.Conv1d(cond_channels, cond_channels, kernel_size=3, padding=1)
|
| 35 |
+
),
|
| 36 |
+
nn.ELU(),
|
| 37 |
+
weight_norm(
|
| 38 |
+
nn.Conv1d(cond_channels, cond_channels, kernel_size=3, padding=1)
|
| 39 |
+
),
|
| 40 |
+
nn.ELU(),
|
| 41 |
+
weight_norm(
|
| 42 |
+
nn.Conv1d(cond_channels, cond_channels, kernel_size=3, padding=1)
|
| 43 |
+
),
|
| 44 |
+
nn.ELU(),
|
| 45 |
+
weight_norm(
|
| 46 |
+
nn.Conv1d(cond_channels, cond_channels, kernel_size=3, padding=1)
|
| 47 |
+
),
|
| 48 |
+
nn.ELU(),
|
| 49 |
+
)
|
| 50 |
+
self.classifier = nn.Linear(in_features=cond_channels, out_features=self.num_class)
|
| 51 |
+
|
| 52 |
+
def forward(self, x: torch.Tensor) -> torch.Tensor:
|
| 53 |
+
x = self.condnet(x)
|
| 54 |
+
x = x.transpose(1, 2)
|
| 55 |
+
return torch.abs(self.classifier(x).squeeze(-1))
|
CosyVoice/cosyvoice/hifigan/generator.py
ADDED
|
@@ -0,0 +1,391 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) 2024 Alibaba Inc (authors: Xiang Lyu, Kai Hu)
|
| 2 |
+
#
|
| 3 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 4 |
+
# you may not use this file except in compliance with the License.
|
| 5 |
+
# You may obtain a copy of the License at
|
| 6 |
+
#
|
| 7 |
+
# http://www.apache.org/licenses/LICENSE-2.0
|
| 8 |
+
#
|
| 9 |
+
# Unless required by applicable law or agreed to in writing, software
|
| 10 |
+
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 11 |
+
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 12 |
+
# See the License for the specific language governing permissions and
|
| 13 |
+
# limitations under the License.
|
| 14 |
+
|
| 15 |
+
"""HIFI-GAN"""
|
| 16 |
+
|
| 17 |
+
import typing as tp
|
| 18 |
+
import numpy as np
|
| 19 |
+
from scipy.signal import get_window
|
| 20 |
+
import torch
|
| 21 |
+
import torch.nn as nn
|
| 22 |
+
import torch.nn.functional as F
|
| 23 |
+
from torch.nn import Conv1d
|
| 24 |
+
from torch.nn import ConvTranspose1d
|
| 25 |
+
from torch.nn.utils import remove_weight_norm
|
| 26 |
+
from torch.nn.utils import weight_norm
|
| 27 |
+
from torch.distributions.uniform import Uniform
|
| 28 |
+
|
| 29 |
+
from cosyvoice.transformer.activation import Snake
|
| 30 |
+
from cosyvoice.utils.common import get_padding
|
| 31 |
+
from cosyvoice.utils.common import init_weights
|
| 32 |
+
|
| 33 |
+
|
| 34 |
+
"""hifigan based generator implementation.
|
| 35 |
+
|
| 36 |
+
This code is modified from https://github.com/jik876/hifi-gan
|
| 37 |
+
,https://github.com/kan-bayashi/ParallelWaveGAN and
|
| 38 |
+
https://github.com/NVIDIA/BigVGAN
|
| 39 |
+
|
| 40 |
+
"""
|
| 41 |
+
class ResBlock(torch.nn.Module):
|
| 42 |
+
"""Residual block module in HiFiGAN/BigVGAN."""
|
| 43 |
+
def __init__(
|
| 44 |
+
self,
|
| 45 |
+
channels: int = 512,
|
| 46 |
+
kernel_size: int = 3,
|
| 47 |
+
dilations: tp.List[int] = [1, 3, 5],
|
| 48 |
+
):
|
| 49 |
+
super(ResBlock, self).__init__()
|
| 50 |
+
self.convs1 = nn.ModuleList()
|
| 51 |
+
self.convs2 = nn.ModuleList()
|
| 52 |
+
|
| 53 |
+
for dilation in dilations:
|
| 54 |
+
self.convs1.append(
|
| 55 |
+
weight_norm(
|
| 56 |
+
Conv1d(
|
| 57 |
+
channels,
|
| 58 |
+
channels,
|
| 59 |
+
kernel_size,
|
| 60 |
+
1,
|
| 61 |
+
dilation=dilation,
|
| 62 |
+
padding=get_padding(kernel_size, dilation)
|
| 63 |
+
)
|
| 64 |
+
)
|
| 65 |
+
)
|
| 66 |
+
self.convs2.append(
|
| 67 |
+
weight_norm(
|
| 68 |
+
Conv1d(
|
| 69 |
+
channels,
|
| 70 |
+
channels,
|
| 71 |
+
kernel_size,
|
| 72 |
+
1,
|
| 73 |
+
dilation=1,
|
| 74 |
+
padding=get_padding(kernel_size, 1)
|
| 75 |
+
)
|
| 76 |
+
)
|
| 77 |
+
)
|
| 78 |
+
self.convs1.apply(init_weights)
|
| 79 |
+
self.convs2.apply(init_weights)
|
| 80 |
+
self.activations1 = nn.ModuleList([
|
| 81 |
+
Snake(channels, alpha_logscale=False)
|
| 82 |
+
for _ in range(len(self.convs1))
|
| 83 |
+
])
|
| 84 |
+
self.activations2 = nn.ModuleList([
|
| 85 |
+
Snake(channels, alpha_logscale=False)
|
| 86 |
+
for _ in range(len(self.convs2))
|
| 87 |
+
])
|
| 88 |
+
|
| 89 |
+
def forward(self, x: torch.Tensor) -> torch.Tensor:
|
| 90 |
+
for idx in range(len(self.convs1)):
|
| 91 |
+
xt = self.activations1[idx](x)
|
| 92 |
+
xt = self.convs1[idx](xt)
|
| 93 |
+
xt = self.activations2[idx](xt)
|
| 94 |
+
xt = self.convs2[idx](xt)
|
| 95 |
+
x = xt + x
|
| 96 |
+
return x
|
| 97 |
+
|
| 98 |
+
def remove_weight_norm(self):
|
| 99 |
+
for idx in range(len(self.convs1)):
|
| 100 |
+
remove_weight_norm(self.convs1[idx])
|
| 101 |
+
remove_weight_norm(self.convs2[idx])
|
| 102 |
+
|
| 103 |
+
class SineGen(torch.nn.Module):
|
| 104 |
+
""" Definition of sine generator
|
| 105 |
+
SineGen(samp_rate, harmonic_num = 0,
|
| 106 |
+
sine_amp = 0.1, noise_std = 0.003,
|
| 107 |
+
voiced_threshold = 0,
|
| 108 |
+
flag_for_pulse=False)
|
| 109 |
+
samp_rate: sampling rate in Hz
|
| 110 |
+
harmonic_num: number of harmonic overtones (default 0)
|
| 111 |
+
sine_amp: amplitude of sine-wavefrom (default 0.1)
|
| 112 |
+
noise_std: std of Gaussian noise (default 0.003)
|
| 113 |
+
voiced_thoreshold: F0 threshold for U/V classification (default 0)
|
| 114 |
+
flag_for_pulse: this SinGen is used inside PulseGen (default False)
|
| 115 |
+
Note: when flag_for_pulse is True, the first time step of a voiced
|
| 116 |
+
segment is always sin(np.pi) or cos(0)
|
| 117 |
+
"""
|
| 118 |
+
|
| 119 |
+
def __init__(self, samp_rate, harmonic_num=0,
|
| 120 |
+
sine_amp=0.1, noise_std=0.003,
|
| 121 |
+
voiced_threshold=0):
|
| 122 |
+
super(SineGen, self).__init__()
|
| 123 |
+
self.sine_amp = sine_amp
|
| 124 |
+
self.noise_std = noise_std
|
| 125 |
+
self.harmonic_num = harmonic_num
|
| 126 |
+
self.sampling_rate = samp_rate
|
| 127 |
+
self.voiced_threshold = voiced_threshold
|
| 128 |
+
|
| 129 |
+
def _f02uv(self, f0):
|
| 130 |
+
# generate uv signal
|
| 131 |
+
uv = (f0 > self.voiced_threshold).type(torch.float32)
|
| 132 |
+
return uv
|
| 133 |
+
|
| 134 |
+
@torch.no_grad()
|
| 135 |
+
def forward(self, f0):
|
| 136 |
+
"""
|
| 137 |
+
:param f0: [B, 1, sample_len], Hz
|
| 138 |
+
:return: [B, 1, sample_len]
|
| 139 |
+
"""
|
| 140 |
+
|
| 141 |
+
F_mat = torch.zeros((f0.size(0), self.harmonic_num + 1, f0.size(-1))).to(f0.device)
|
| 142 |
+
for i in range(self.harmonic_num + 1):
|
| 143 |
+
F_mat[:, i: i + 1, :] = f0 * (i + 1) / self.sampling_rate
|
| 144 |
+
|
| 145 |
+
theta_mat = 2 * np.pi * (torch.cumsum(F_mat, dim=-1) % 1)
|
| 146 |
+
u_dist = Uniform(low=-np.pi, high=np.pi)
|
| 147 |
+
phase_vec = u_dist.sample(sample_shape=(f0.size(0), self.harmonic_num + 1, 1)).to(F_mat.device)
|
| 148 |
+
phase_vec[:, 0, :] = 0
|
| 149 |
+
|
| 150 |
+
# generate sine waveforms
|
| 151 |
+
sine_waves = self.sine_amp * torch.sin(theta_mat + phase_vec)
|
| 152 |
+
|
| 153 |
+
# generate uv signal
|
| 154 |
+
uv = self._f02uv(f0)
|
| 155 |
+
|
| 156 |
+
# noise: for unvoiced should be similar to sine_amp
|
| 157 |
+
# std = self.sine_amp/3 -> max value ~ self.sine_amp
|
| 158 |
+
# . for voiced regions is self.noise_std
|
| 159 |
+
noise_amp = uv * self.noise_std + (1 - uv) * self.sine_amp / 3
|
| 160 |
+
noise = noise_amp * torch.randn_like(sine_waves)
|
| 161 |
+
|
| 162 |
+
# first: set the unvoiced part to 0 by uv
|
| 163 |
+
# then: additive noise
|
| 164 |
+
sine_waves = sine_waves * uv + noise
|
| 165 |
+
return sine_waves, uv, noise
|
| 166 |
+
|
| 167 |
+
|
| 168 |
+
class SourceModuleHnNSF(torch.nn.Module):
|
| 169 |
+
""" SourceModule for hn-nsf
|
| 170 |
+
SourceModule(sampling_rate, harmonic_num=0, sine_amp=0.1,
|
| 171 |
+
add_noise_std=0.003, voiced_threshod=0)
|
| 172 |
+
sampling_rate: sampling_rate in Hz
|
| 173 |
+
harmonic_num: number of harmonic above F0 (default: 0)
|
| 174 |
+
sine_amp: amplitude of sine source signal (default: 0.1)
|
| 175 |
+
add_noise_std: std of additive Gaussian noise (default: 0.003)
|
| 176 |
+
note that amplitude of noise in unvoiced is decided
|
| 177 |
+
by sine_amp
|
| 178 |
+
voiced_threshold: threhold to set U/V given F0 (default: 0)
|
| 179 |
+
Sine_source, noise_source = SourceModuleHnNSF(F0_sampled)
|
| 180 |
+
F0_sampled (batchsize, length, 1)
|
| 181 |
+
Sine_source (batchsize, length, 1)
|
| 182 |
+
noise_source (batchsize, length 1)
|
| 183 |
+
uv (batchsize, length, 1)
|
| 184 |
+
"""
|
| 185 |
+
|
| 186 |
+
def __init__(self, sampling_rate, upsample_scale, harmonic_num=0, sine_amp=0.1,
|
| 187 |
+
add_noise_std=0.003, voiced_threshod=0):
|
| 188 |
+
super(SourceModuleHnNSF, self).__init__()
|
| 189 |
+
|
| 190 |
+
self.sine_amp = sine_amp
|
| 191 |
+
self.noise_std = add_noise_std
|
| 192 |
+
|
| 193 |
+
# to produce sine waveforms
|
| 194 |
+
self.l_sin_gen = SineGen(sampling_rate, harmonic_num,
|
| 195 |
+
sine_amp, add_noise_std, voiced_threshod)
|
| 196 |
+
|
| 197 |
+
# to merge source harmonics into a single excitation
|
| 198 |
+
self.l_linear = torch.nn.Linear(harmonic_num + 1, 1)
|
| 199 |
+
self.l_tanh = torch.nn.Tanh()
|
| 200 |
+
|
| 201 |
+
def forward(self, x):
|
| 202 |
+
"""
|
| 203 |
+
Sine_source, noise_source = SourceModuleHnNSF(F0_sampled)
|
| 204 |
+
F0_sampled (batchsize, length, 1)
|
| 205 |
+
Sine_source (batchsize, length, 1)
|
| 206 |
+
noise_source (batchsize, length 1)
|
| 207 |
+
"""
|
| 208 |
+
# source for harmonic branch
|
| 209 |
+
with torch.no_grad():
|
| 210 |
+
sine_wavs, uv, _ = self.l_sin_gen(x.transpose(1, 2))
|
| 211 |
+
sine_wavs = sine_wavs.transpose(1, 2)
|
| 212 |
+
uv = uv.transpose(1, 2)
|
| 213 |
+
sine_merge = self.l_tanh(self.l_linear(sine_wavs))
|
| 214 |
+
|
| 215 |
+
# source for noise branch, in the same shape as uv
|
| 216 |
+
noise = torch.randn_like(uv) * self.sine_amp / 3
|
| 217 |
+
return sine_merge, noise, uv
|
| 218 |
+
|
| 219 |
+
|
| 220 |
+
class HiFTGenerator(nn.Module):
|
| 221 |
+
"""
|
| 222 |
+
HiFTNet Generator: Neural Source Filter + ISTFTNet
|
| 223 |
+
https://arxiv.org/abs/2309.09493
|
| 224 |
+
"""
|
| 225 |
+
def __init__(
|
| 226 |
+
self,
|
| 227 |
+
in_channels: int = 80,
|
| 228 |
+
base_channels: int = 512,
|
| 229 |
+
nb_harmonics: int = 8,
|
| 230 |
+
sampling_rate: int = 22050,
|
| 231 |
+
nsf_alpha: float = 0.1,
|
| 232 |
+
nsf_sigma: float = 0.003,
|
| 233 |
+
nsf_voiced_threshold: float = 10,
|
| 234 |
+
upsample_rates: tp.List[int] = [8, 8],
|
| 235 |
+
upsample_kernel_sizes: tp.List[int] = [16, 16],
|
| 236 |
+
istft_params: tp.Dict[str, int] = {"n_fft": 16, "hop_len": 4},
|
| 237 |
+
resblock_kernel_sizes: tp.List[int] = [3, 7, 11],
|
| 238 |
+
resblock_dilation_sizes: tp.List[tp.List[int]] = [[1, 3, 5], [1, 3, 5], [1, 3, 5]],
|
| 239 |
+
source_resblock_kernel_sizes: tp.List[int] = [7, 11],
|
| 240 |
+
source_resblock_dilation_sizes: tp.List[tp.List[int]] = [[1, 3, 5], [1, 3, 5]],
|
| 241 |
+
lrelu_slope: float = 0.1,
|
| 242 |
+
audio_limit: float = 0.99,
|
| 243 |
+
f0_predictor: torch.nn.Module = None,
|
| 244 |
+
):
|
| 245 |
+
super(HiFTGenerator, self).__init__()
|
| 246 |
+
|
| 247 |
+
self.out_channels = 1
|
| 248 |
+
self.nb_harmonics = nb_harmonics
|
| 249 |
+
self.sampling_rate = sampling_rate
|
| 250 |
+
self.istft_params = istft_params
|
| 251 |
+
self.lrelu_slope = lrelu_slope
|
| 252 |
+
self.audio_limit = audio_limit
|
| 253 |
+
|
| 254 |
+
self.num_kernels = len(resblock_kernel_sizes)
|
| 255 |
+
self.num_upsamples = len(upsample_rates)
|
| 256 |
+
self.m_source = SourceModuleHnNSF(
|
| 257 |
+
sampling_rate=sampling_rate,
|
| 258 |
+
upsample_scale=np.prod(upsample_rates) * istft_params["hop_len"],
|
| 259 |
+
harmonic_num=nb_harmonics,
|
| 260 |
+
sine_amp=nsf_alpha,
|
| 261 |
+
add_noise_std=nsf_sigma,
|
| 262 |
+
voiced_threshod=nsf_voiced_threshold)
|
| 263 |
+
self.f0_upsamp = torch.nn.Upsample(scale_factor=np.prod(upsample_rates) * istft_params["hop_len"])
|
| 264 |
+
|
| 265 |
+
self.conv_pre = weight_norm(
|
| 266 |
+
Conv1d(in_channels, base_channels, 7, 1, padding=3)
|
| 267 |
+
)
|
| 268 |
+
|
| 269 |
+
# Up
|
| 270 |
+
self.ups = nn.ModuleList()
|
| 271 |
+
for i, (u, k) in enumerate(zip(upsample_rates, upsample_kernel_sizes)):
|
| 272 |
+
self.ups.append(
|
| 273 |
+
weight_norm(
|
| 274 |
+
ConvTranspose1d(
|
| 275 |
+
base_channels // (2**i),
|
| 276 |
+
base_channels // (2**(i + 1)),
|
| 277 |
+
k,
|
| 278 |
+
u,
|
| 279 |
+
padding=(k - u) // 2,
|
| 280 |
+
)
|
| 281 |
+
)
|
| 282 |
+
)
|
| 283 |
+
|
| 284 |
+
# Down
|
| 285 |
+
self.source_downs = nn.ModuleList()
|
| 286 |
+
self.source_resblocks = nn.ModuleList()
|
| 287 |
+
downsample_rates = [1] + upsample_rates[::-1][:-1]
|
| 288 |
+
downsample_cum_rates = np.cumprod(downsample_rates)
|
| 289 |
+
for i, (u, k, d) in enumerate(zip(downsample_cum_rates[::-1], source_resblock_kernel_sizes,
|
| 290 |
+
source_resblock_dilation_sizes)):
|
| 291 |
+
if u == 1:
|
| 292 |
+
self.source_downs.append(
|
| 293 |
+
Conv1d(istft_params["n_fft"] + 2, base_channels // (2 ** (i + 1)), 1, 1)
|
| 294 |
+
)
|
| 295 |
+
else:
|
| 296 |
+
self.source_downs.append(
|
| 297 |
+
Conv1d(istft_params["n_fft"] + 2, base_channels // (2 ** (i + 1)), u * 2, u, padding=(u // 2))
|
| 298 |
+
)
|
| 299 |
+
|
| 300 |
+
self.source_resblocks.append(
|
| 301 |
+
ResBlock(base_channels // (2 ** (i + 1)), k, d)
|
| 302 |
+
)
|
| 303 |
+
|
| 304 |
+
self.resblocks = nn.ModuleList()
|
| 305 |
+
for i in range(len(self.ups)):
|
| 306 |
+
ch = base_channels // (2**(i + 1))
|
| 307 |
+
for j, (k, d) in enumerate(zip(resblock_kernel_sizes, resblock_dilation_sizes)):
|
| 308 |
+
self.resblocks.append(ResBlock(ch, k, d))
|
| 309 |
+
|
| 310 |
+
self.conv_post = weight_norm(Conv1d(ch, istft_params["n_fft"] + 2, 7, 1, padding=3))
|
| 311 |
+
self.ups.apply(init_weights)
|
| 312 |
+
self.conv_post.apply(init_weights)
|
| 313 |
+
self.reflection_pad = nn.ReflectionPad1d((1, 0))
|
| 314 |
+
self.stft_window = torch.from_numpy(get_window("hann", istft_params["n_fft"], fftbins=True).astype(np.float32))
|
| 315 |
+
self.f0_predictor = f0_predictor
|
| 316 |
+
|
| 317 |
+
def _f02source(self, f0: torch.Tensor) -> torch.Tensor:
|
| 318 |
+
f0 = self.f0_upsamp(f0[:, None]).transpose(1, 2) # bs,n,t
|
| 319 |
+
|
| 320 |
+
har_source, _, _ = self.m_source(f0)
|
| 321 |
+
return har_source.transpose(1, 2)
|
| 322 |
+
|
| 323 |
+
def _stft(self, x):
|
| 324 |
+
spec = torch.stft(
|
| 325 |
+
x,
|
| 326 |
+
self.istft_params["n_fft"], self.istft_params["hop_len"], self.istft_params["n_fft"], window=self.stft_window.to(x.device),
|
| 327 |
+
return_complex=True)
|
| 328 |
+
spec = torch.view_as_real(spec) # [B, F, TT, 2]
|
| 329 |
+
return spec[..., 0], spec[..., 1]
|
| 330 |
+
|
| 331 |
+
def _istft(self, magnitude, phase):
|
| 332 |
+
magnitude = torch.clip(magnitude, max=1e2)
|
| 333 |
+
real = magnitude * torch.cos(phase)
|
| 334 |
+
img = magnitude * torch.sin(phase)
|
| 335 |
+
inverse_transform = torch.istft(torch.complex(real, img), self.istft_params["n_fft"], self.istft_params["hop_len"], self.istft_params["n_fft"], window=self.stft_window.to(magnitude.device))
|
| 336 |
+
return inverse_transform
|
| 337 |
+
|
| 338 |
+
def forward(self, x: torch.Tensor) -> torch.Tensor:
|
| 339 |
+
f0 = self.f0_predictor(x)
|
| 340 |
+
s = self._f02source(f0)
|
| 341 |
+
|
| 342 |
+
s_stft_real, s_stft_imag = self._stft(s.squeeze(1))
|
| 343 |
+
s_stft = torch.cat([s_stft_real, s_stft_imag], dim=1)
|
| 344 |
+
|
| 345 |
+
x = self.conv_pre(x)
|
| 346 |
+
for i in range(self.num_upsamples):
|
| 347 |
+
x = F.leaky_relu(x, self.lrelu_slope)
|
| 348 |
+
x = self.ups[i](x)
|
| 349 |
+
|
| 350 |
+
if i == self.num_upsamples - 1:
|
| 351 |
+
x = self.reflection_pad(x)
|
| 352 |
+
|
| 353 |
+
# fusion
|
| 354 |
+
si = self.source_downs[i](s_stft)
|
| 355 |
+
si = self.source_resblocks[i](si)
|
| 356 |
+
x = x + si
|
| 357 |
+
|
| 358 |
+
xs = None
|
| 359 |
+
for j in range(self.num_kernels):
|
| 360 |
+
if xs is None:
|
| 361 |
+
xs = self.resblocks[i * self.num_kernels + j](x)
|
| 362 |
+
else:
|
| 363 |
+
xs += self.resblocks[i * self.num_kernels + j](x)
|
| 364 |
+
x = xs / self.num_kernels
|
| 365 |
+
|
| 366 |
+
x = F.leaky_relu(x)
|
| 367 |
+
x = self.conv_post(x)
|
| 368 |
+
magnitude = torch.exp(x[:, :self.istft_params["n_fft"] // 2 + 1, :])
|
| 369 |
+
phase = torch.sin(x[:, self.istft_params["n_fft"] // 2 + 1:, :]) # actually, sin is redundancy
|
| 370 |
+
|
| 371 |
+
x = self._istft(magnitude, phase)
|
| 372 |
+
x = torch.clamp(x, -self.audio_limit, self.audio_limit)
|
| 373 |
+
return x
|
| 374 |
+
|
| 375 |
+
def remove_weight_norm(self):
|
| 376 |
+
print('Removing weight norm...')
|
| 377 |
+
for l in self.ups:
|
| 378 |
+
remove_weight_norm(l)
|
| 379 |
+
for l in self.resblocks:
|
| 380 |
+
l.remove_weight_norm()
|
| 381 |
+
remove_weight_norm(self.conv_pre)
|
| 382 |
+
remove_weight_norm(self.conv_post)
|
| 383 |
+
self.source_module.remove_weight_norm()
|
| 384 |
+
for l in self.source_downs:
|
| 385 |
+
remove_weight_norm(l)
|
| 386 |
+
for l in self.source_resblocks:
|
| 387 |
+
l.remove_weight_norm()
|
| 388 |
+
|
| 389 |
+
@torch.inference_mode()
|
| 390 |
+
def inference(self, mel: torch.Tensor) -> torch.Tensor:
|
| 391 |
+
return self.forward(x=mel)
|