

Submitted by
 Hennara
Hennara
HennaraGet trending papers in your email inbox once a day!
Get trending papers in your email inbox!
Subscribe
Hennara
 iseesaw
iseesaw
 minghaowu
minghaowu longlian
longlian longlian
longlian
 Neph0s
Neph0s
 zhangysk
zhangysk
 bongbohong
bongbohong
 yueyang2000
yueyang2000
 Kaiyue
Kaiyue chenjoya
chenjoya
 Zilence006
Zilence006
 thomasschmied
thomasschmied
 zhoutianyi
zhoutianyi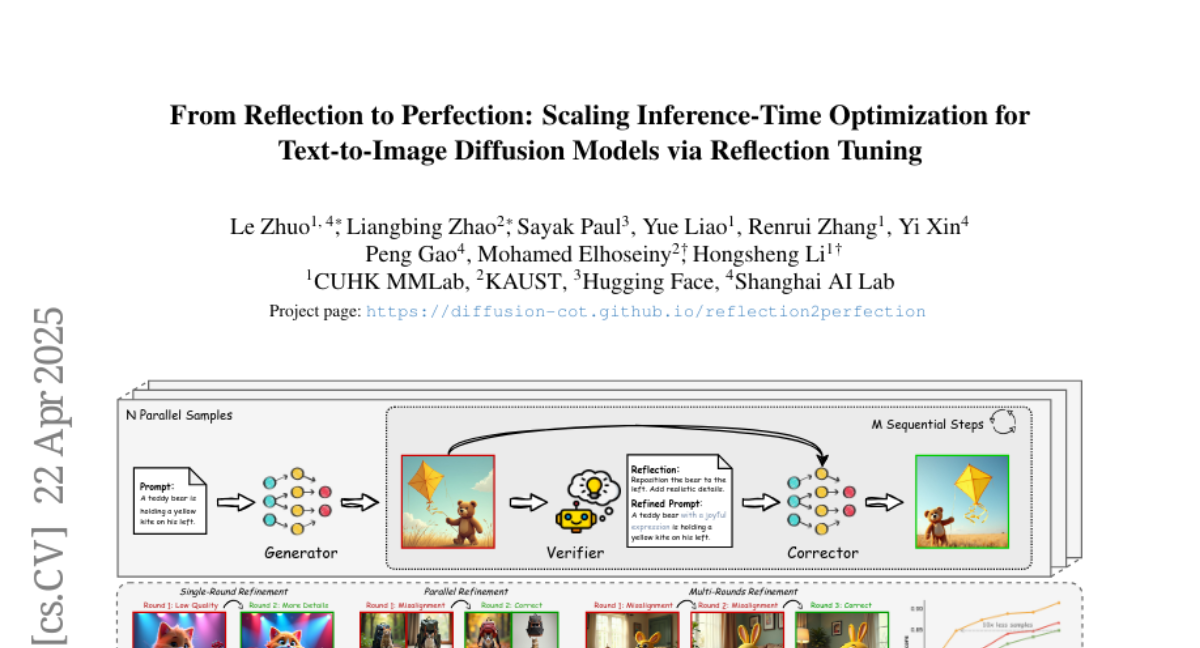
 sayakpaul
sayakpaul
 theFoxofSky
theFoxofSky
 stneng
stneng
 ziqipang
ziqipang
 QiYao-Wang
QiYao-Wang
 j-min
j-min
 yoyolicoris
yoyolicoris














































