Comprehensive Study of H800x104 DGX SuperPod Disaggregation Strategy in SGLang v0.4.8



We evaluated the maximum prefill and decode goodput (throughput under SLOs, i.e., TTFT < 2s, ITL < 50ms) [6] in a disaggregated LLM inference architecture using 13x8 H800 DGX SuperPod nodes. The system achieved approximately 1.3 million tokens per second (toks/sec) for input throughput and 20,000 toks/sec for max output throughput across various server-side disaggregation configurations ((P3x3)D4 (i.e., 3 groups of P3, 1 group of D4), P4D9, P4D6, P2D4, P4D2, P2D2). In the major cases, prefill is the bottlenect in our experiment, bringing us with large TTFT. Reference to the computed Decodes/Prefill nodes ratio
1.4derived from DeepSeek workload [9], to achieve high server side goodput rates, we tried largerPnodes group (3) and smaller tp size (24). Performance was measured using the SGLangbench_one_batch_server.pybenchmark script [1], which evaluates URL API call performance and latergenai-bench[10] to generate more reliable output throughput at different level of concurrencies. On the user side, we conducted online observations under service level objectives (SLOs), using evalscope [2] to benchmark OpenAI-compatible endpoint APIs with API key authentication. Under these conditions, the system sustained 25,000 toks/sec output throughput at the concurrency of 50, and 55,000 toks/sec at the concurrency of 150 for small input queries. We observed that whenbatch size × input lengthexceeds a certain threshold (e.g., due to KV cache transferring limitations[7]), Time to First Token (TTFT) increases sharply. Morever, to obtain better goodput rate, input seqeunce length (ISL) over output sequence length (OSL) should be at specific ratio, preferablely 4:1. As a result, overall latency dominated by TTFT if we want to achieve high thoughput with larger batch sizes and sequence length. To maintain high GPU utilization and goodput, concurrencies should be less than 128 to avoid sharp growth of TTFT. This balance is particularly effective onH800DGX SuperPod systems. Excessively high TTFT leads to unstable output throughput and a significant decline in server-side goodput.
Authors : LEI WANG (yiakwang@ust.hk), Yujie Pu (yujiepu@ust.hk), Andy Guo (guozhenhua@hkgai.org), Yi Chao (chao.yi@hkgai.org), Yiwen Wang (yepmanwong@hkgai.org), Xue Wei (weixue@ust.hk)
Contents
- Motivation & Background
- Benchmarking Method
- Benchmarking of P/D
- Conclusion
- Future Work
- Acknowledgement
- Appendix
- Reference
- Sponsor Sources
Motivation & Background
In Prefill-Decode aggregated LLM inference architecture, an interleveating schedule plan between prefill tokens and decodes tokens was implemented in vLLM bofore 2024 Q2, and later improved with continuous scheduling [3] with higher overall GPU utimizaton.
However due to distinct computing natures of prefill and decode stages, continous batching of full un-chunked prefill tokens of incoming requests with decode tokens of running requests increase decode latency significantly. This leads to large inter token latency (ITL) and degrades responsiveness.
To address this issue, chunk-prefill feature [4] was proposed and introduced in PR#3130 so that chunked prefill tokens of incoming requests and decode tokens of runing requests are batched together in a colocated system as demonstrated below for better ITL and GPU utilization:

However chunked-prefill does not take into account distinct computing natures of prefilling and decodeing.
The process of decoding is often captured by a cuda graph for multiple rounds of generation, hence additional overhead brought in when decoding is batched with chunked prefill where cuda graph is not viable for use.
Moreover, as observed in DistServe [4] [5] [6] on 13 B dense model and our experiments on 671 B MoE model, prefill computation cost increases significantly once batch_size x output_length exceeds a certain threshold (i.e. 128 x 128) in a colocated serving system, regardless of chunk-fill size.
Hereby disaggregated serving architecture was proposed [4]. DeepSeek further reduces latencies, and throughput by DeepEP and MLA, which were quickly integrated into SGLang, and the system achieves epic 73.7k toks/node/sec and 14.8k toks/node/sec under SLOs at the deployment unit P4D18.
However, a common misunderstanding is that the number of P nodes should not exceed that of D nodes, as DeepSeek does not disclose the actual ratio of P to D nodes in its blog post [8].
According to its revealed total served tokens 608B input tokens, and 168B output tokens within 24 hours a day, and the Prefill/Decode speeds, the total number of prefill nodes used is estimated to be
, and total number of decode nodes is estimated to be
The reference test ratio of Decode/Prefill nodes is computed as 1.4 = 1314 / 955, and the P4D18 configuration ratio is 3.27 : 1 = (955 / 4)/ (1314 / 18). For H800 13x8 DGX SuperPod, P/D disaggregation configuation (P3x2)D4, (P3x3)D4 and (P4x2)D4 are hence recommended. Since Prefill is more likely to be the bottlenect of the system as we analyze, we limited the TP size to 4, becuase larger TP size degregrads inference speed and less TP size leads to less volume reserved for KV cache.
In our test, (P3x3)D4 and P4D6 outperforms P9D4 with better TTFT due to less TP size, and relative more prefill stage processing capacities:
| Concurrency | Input | Output | latency | Input Tput | Output Tput | Overall Tput | TTFT (95) (s) | |
|---|---|---|---|---|---|---|---|---|
| (P3x3)D4 | 1 | 2000 | 200 | 901.13 | 214.74 | 21.75 | 0.44 | |
| 2 | 2000 | 200 | 611.92 | 413.22 | 41.83 | 0.61 | ||
| 8 | 2000 | 200 | 160.74 | 1,587.72 | 160.74 | 2.69 | ||
| 64 | 2000 | 200 | 27.27 | 9,267.40 | 938.58 | 2.91 | ||
| 128 | 2000 | 200 | 18.64 | 13,555.56 | 1,372.96 | 7.69 | ||
| 256 | 2000 | 200 | 21.60 | 23,398.95 | 2,370.23 | 8.4 | ||
| 512 | 2000 | 500 | 522.80 | 31,016.53 | 7,852.82 | 4.97 | ||
| 1024 | 2000 | 500 | 374.90 | 53,494.96 | 13,543.28 | 9.85 | ||
| P4D6 | ||||||||
| 1024 | 1024 | 32 | 15.85 | 75,914.78 | 16,103.44 | 68,234.85 | 13.81 | |
| 1024 | 1024 | 128 | 18.30 | 100,663.25 | 16,626.85 | 64,462.25 | 10.42 | |
| 1024 | 1024 | 256 | 23.97 | 95,540.18 | 20,176.66 | 54,686.99 | 10.98 | |
| 1024 | 1024 | 512 | 39.84 | 79,651.21 | 19,654.31 | 39,479.45 | 13.16 | |
| 2048 | 2048 | 256 | 60.08 | 77,367.28 | 89,299.88 | 78,533.27 | 54.21 | |
| P4D9 | ||||||||
| 64 | 128 | 128 | 12.51 | 1,701.88 | 1,064.16 | 1,309.50 | 4.81 | |
| 64 | 4,096 | 128 | 20.21 | 22,185.68 | 975.58 | 13,374.37 | 11.82 | |
| 64 | 2,048 | 128 | 41.70 | 3,553.74 | 1,699.56 | 3,339.43 | 36.88 | |
| 64 | 1,024 | 128 | 69.72 | 1,017.38 | 1,543.28 | 64.42 | ||
| 512 | 4,096 | 128 | 36.75 | 85,749.88 | 5,332.19 | 58,853.06 | 24.46 | |
| 512 | 2,048 | 128 | 213.43 | 5,021.26 | 14,249.05 | 5,220.12 | 208.83 | |
| 512 | 1,024 | 128 | 112.81 | 4,849.07 | 13,976.04 | 5,228.45 | 108.12 | |
| 1,024 | 4,096 | 128 | 58.47 | 77,876.48 | 28,407.07 | 73,972.85 | 53.86 | |
| 2,048 | 4,096 | 256 | 105.21 | 80,227.44 | 808,820.03 | 84,716.46 | 104.56 | |
| 2,048 | 2,048 | 256 | 72.53 | 89,296.97 | 20,513.48 | 65,058.45 | 46.97 |
We conducted both aggregated and disaggregated serving experiments at scales with our own finetuned DeepSeek V3 (0324) alike model in SGLang v0.4.8.
Given an input sequence length (in_seq_len : 128 ~ 4096) and short output sequence length (out_seq_len : 1~256), tuning over various batch sizes (bs), we concluded that
maximum of prefill goodput, when seving DeepSeek V3 alike massive MoE model, arrives at specific
batch size (bs) x output length (out_seq_len)in an aggregated LLM inference architecture, and at specificbatch size (bs) * input length (in_seq_len)in a disaggregated LLM inference architecture;prefill is more likely to be the bottlenect, hence more prefill groups (P3x3, i.e. 3 groups of P3) and ratio of
WORLD_SIZEof prefill group over the decode group is recommended to be in the range of (0.75(P3D4), 1(PXDX));
Unlike serving 13 B dense model in DistServe [4] [5] [6] , prefill goodput in serving 671 B large MoE (8 out of 256 experts, plus P * 8 redundant experts), is negatively affected by the product of the output length and the batch size until its max is achieved. The details of statistics can be found in Appendix.
Review H800 x 2 test of Prefill Decode Colocated Architecture
In a H800 x 2 (DGX SuperPod) test config, each node is connected via infiniband, the max of input throughput arrives at 20 k toks/sec :
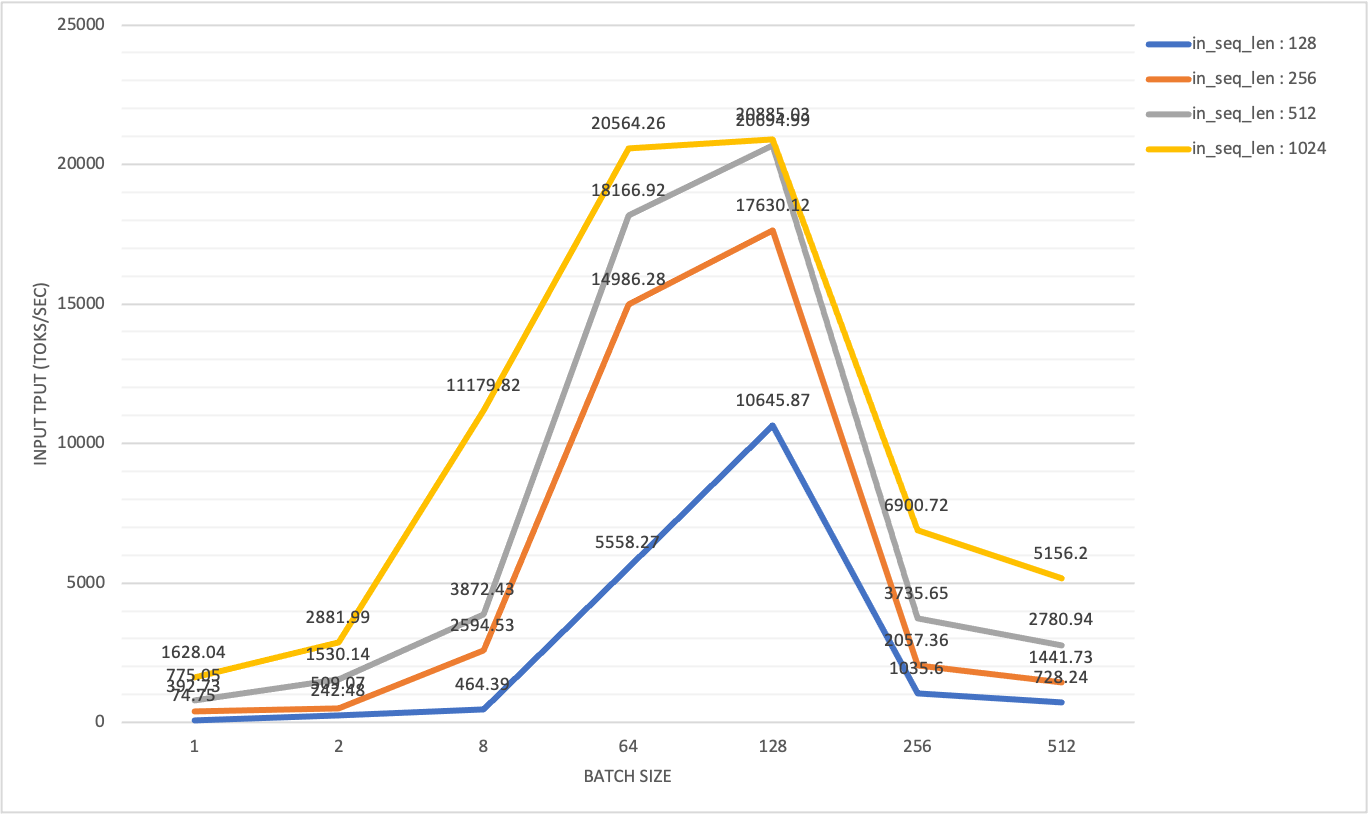
When batch size x output length exceeds 128x128, we observed significant drop in input throughput, accompanied with a sudden and steep growth of TTFT. In contrast, output throughput increase gradually with larger batch size, reaching its max.
All of these statistics indicate that achieving maximum of prefill and decode throughput involves different workloads pattern.
Intuitively, in a disaggregated serving architecture, goodput of prefill nodes with suitable chunk-prefill size, TP sizes, is bounded with certain batch size, since KV cache transfer speed is limited [7].
How P/D works in SGLang
SGLang loader balancer service now supports multiple Prefill (P) nodes setup (multiple P nodes master addresses), and multiple Decode (D) nodes setup (multiple D nodes master addresses):
# start_lb_service.sh
...
docker_args=$(echo -it --rm --privileged \
--name $tag \
--ulimit memlock=-1:-1 --net=host --cap-add=IPC_LOCK --ipc=host \
--device=/dev/infiniband \
-v $(readlink -f $SGLang):/workspace \
-v $MODEL_DIR:/root/models \
-v /etc/localtime:/etc/localtime:ro \
-e LOG_DIR=$LOG_DIR \
--workdir /workspace \
--cpus=64 \
--shm-size 32g \
$IMG
)
# (P3x3)D4 setup
docker run --gpus all "${docker_args[@]}" python -m sglang.srt.disaggregation.mini_lb \
--prefill "http://${prefill_group_0_master_addr}:${api_port}" \
"http://${prefill_group_1_master_addr}:${api_port}" \
"http://${prefill_group_2_master_addr}:${api_port}" \
--decode "http://${decode_group_0_master_addr}:${api_port}" \
--rust-lb
One can also tune the TP size, as P nodes can have smaller TP sizes than D nodes to achieve better TTFT.
Two load balancer RustLB and old MiniLoadBalancer are provided. They follow the same HTTP API to redirect HTTP requests to prefill and decode servers respectively:
# load balance API interface
INFO: 10.33.4.141:41296 - "GET /get_server_info HTTP/1.1" 200 OK
INFO: 10.33.4.141:41312 - "POST /flush_cache HTTP/1.1" 200 OK
INFO: 10.33.4.141:41328 - "POST /generate HTTP/1.1" 200 OK
They are also internally implemented in the same way to handle incoming requests.
# Rust : sgl-pdlb/src/lb_state.rs
pub async fn generate(
&self,
api_path: &str,
mut req: Box<dyn Bootstrap>,
) -> Result<HttpResponse, actix_web::Error> {
let (prefill, decode) = self.strategy_lb.select_pair(&self.client).await;
let stream = req.is_stream();
req.add_bootstrap_info(&prefill)?;
let json = serde_json::to_value(req)?;
let prefill_task = self.route_one(&prefill, Method::POST, api_path, Some(&json), false);
let decode_task = self.route_one(&decode, Method::POST, api_path, Some(&json), stream);
let (_, decode_response) = tokio::join!(prefill_task, decode_task);
decode_response?.into()
}
The problem of SGLang Loadblancer is that the selection of a pair of prefill server and decode server is not traffic based. Then you can not garantee load balance among prefill servers.
Prefill server always return first to complete KV cache generation:
Refering to Dynamo workflow [11], we draft a simple workflow for SGLang RustLB based P/D architecture to better understand how we can optimize the workflow later :
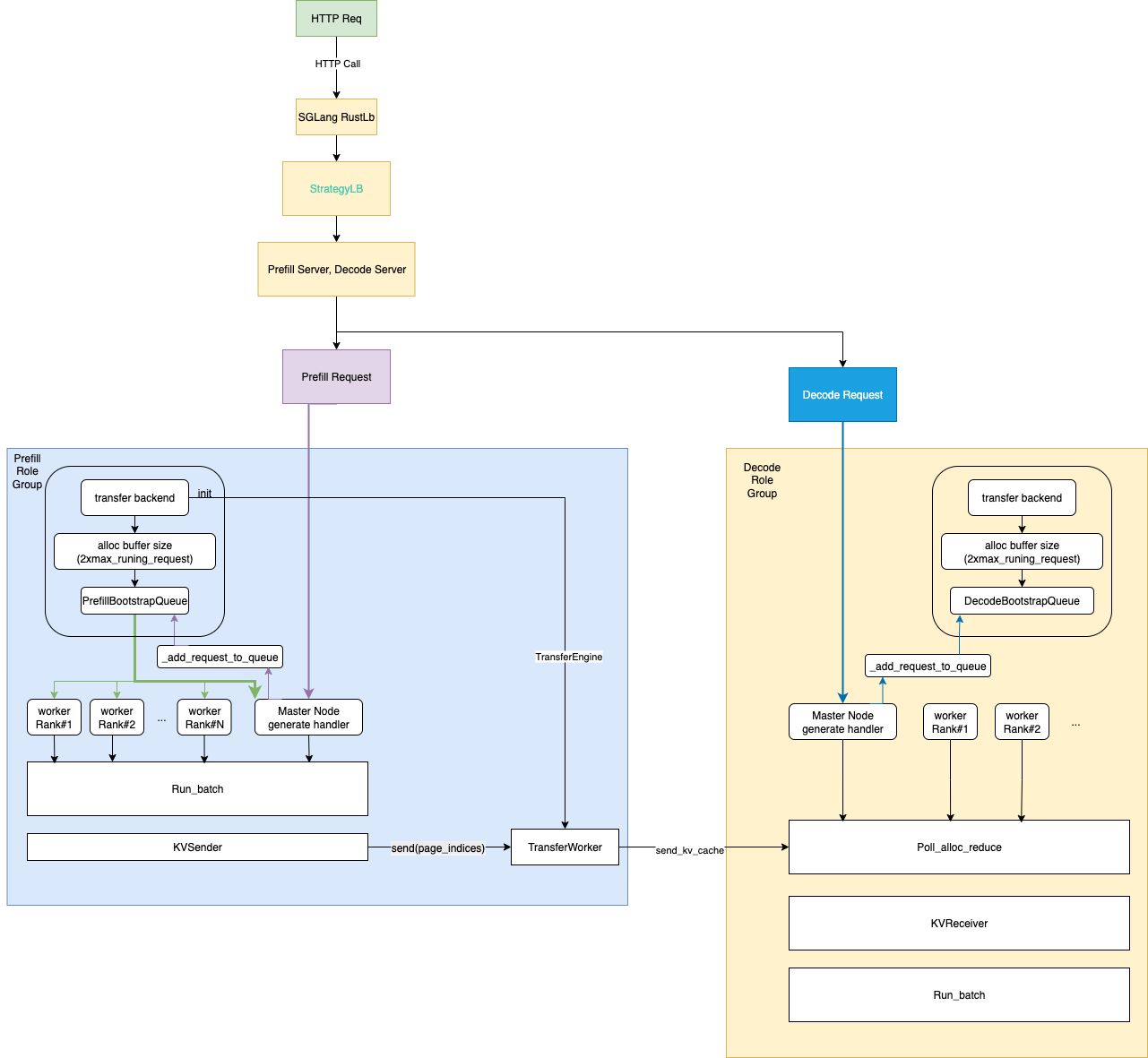
Each P/D process starts a background thread to run a forever event loop to gather requests, the batch of its input and optional ncessary KV cache to start inference.
Benchmarking Method
Investigating over all feasible disaggregation configs with 13 x H800 DGX SupperPod machines, and diving into SGLang (v4.8.0) disaggregation mode, we conducted online P/D disaggregation serving evalution both in server side and user side independently.
To prepare for the test, we first align our hardware and software with the latest open source community, and followed instructions from SGLang team [1] to prepare the configuration files :
| name | role | example |
|---|---|---|
| EXPERT_DISTRIBUTION_PT_LOCATION | decode | ./attachment_ep_statistics/decode_in1000out1000.json |
| EXPERT_DISTRIBUTION_PT_LOCATION | prefill | ./attachment_ep_statistics/prefill_in1024.json |
| DEEP_EP_CFG | prefill | ./benchmark/kernels/deepep/deepep_nnodes_H800x4_tuned.json |
| fused_moe_config | prefill/decode | fused_moe/configs/E=257,N=256,device_name=NVIDIA_H800,block_shape=[128,128].json |
After obtaining the configuration files, and preparing the test scripts properly, we warm up services with a few batches of queries via CURL API since JIT kernel compilation services take a long time from cold start of SGLang event loop workers. Once warmed up, we proceed to collect test statistics.
Hardware & Software
The hardware of H800 SuperPod used in this experiment organized in racks :
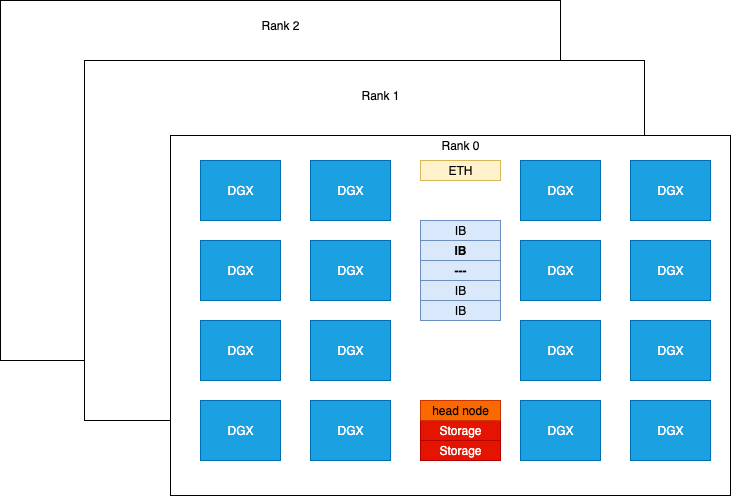
The NVIDIA H800 DGX has compute performance comparable to the H100 DGX, except for FP64/FP32 data type and approximate half of the communication bandwidth due to reduced NVLINK configuration. Each H800 card is connected to a single mellanox CX-7 (MT2910) NIC card, which connects to an infiniband switch, supports a peak bidirectional bandwidth of 50 GB/s.
In a single node NCCL test, nccl_all_reduce runs at 213 GB/s bus bandwidth. In two nodes test, nccl_all_reduce runs at 171 GB/s bus bandwidth. In a rail test (all GPUs cross racks connected with the same ib link), nccl_all_reduce runs at 49 GB/s.
Most of our communication functions in P/D disaggregation test runs DeepEP with NVSHMEM. DeepEP has changed a lot since the version used in May 2025 for P/D experiment by SGLang core team. So we build it from scatch inside customer docker:
Deepep : deep-ep==1.1.0+c50f3d6
For now, we choose mooncake as our disaggregation backend, but other backends will be tried later:
# optional for disaggregation option
disaggregation_opt=" \
$disaggregation_opt \
--disaggregation-transfer-backend mooncake \
"
We require the latest transfer engine as it is 10x faster ( see PR#499 and PR#7236 ) than that was used in May 2025.
mooncake-transfer-engine==v0.3.4
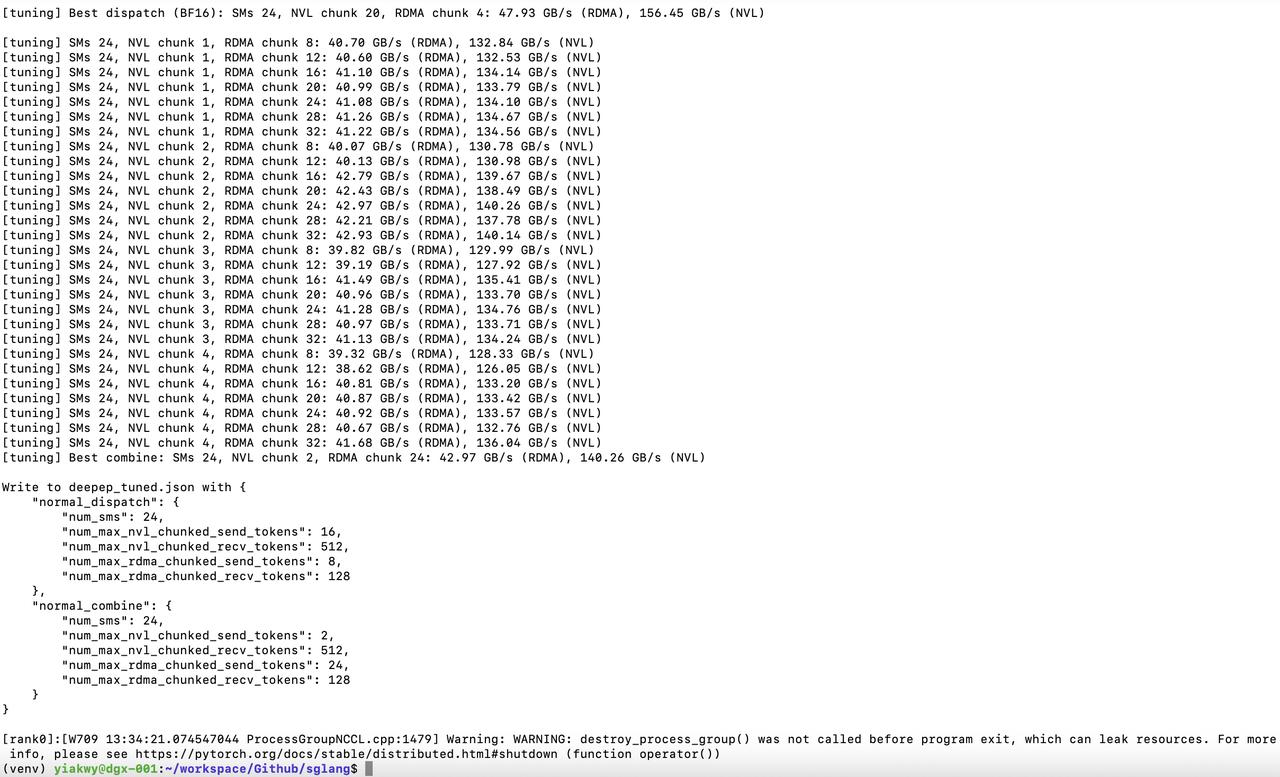
Tunning DeepEP is the first step in our test. Prefill nodes are 2, 3 (direct use of 3 prefill nodes may cause problem in current configuration for SGLang v0.4.8) and 4 :
| Prefill GPU | dtype | dispatch (RDMA GB/s) | dispatch (NVL GB/s) | combine (RDMA GB/s) | combine (NVL GB/s) | loc |
|---|---|---|---|---|---|---|
| 4 | bf16 | 60.58 | 121.63 | 56.72 | 113.88 | deepep_nnodes_H800x4_tuned.json |
| 2 | bf16 | 47.93 | 156.45 | 42.97 | 140.26 | deepep_nnodes_H800x2_tuned.json |
In this experiment, DeepEP test shows that the performance for bf16 is much higher than OCP fp8e4m3. We tried different combination of NCCL, NVSHMEM envrionment variables, only few succeeded due to compatible problems with libtorch:
# env - nccl 2.23, nccl 2.27 symmetric memroy branch
export NCCL_IB_HCA=mlx5_0,mlx5_3,mlx5_4,mlx5_5,mlx5_6,mlx5_9,mlx5_10,mlx5_11
# traffic class for QoS tunning
# export NCCL_IB_TC=136
# service level that maps virtual lane
# export NCCL_IB_SL=5
export NCCL_IB_GID_INDEX=3
export NCCL_SOCKET_IFNAME=ibp24s0,ibp41s0f0,ibp64s0,ibp79s0,ibp94s0,ibp154s0,ibp170s0f0,ibp192s0
# export NCCL_DEBUG=DEBUG
# export NCCL_IB_QPS_PER_CONNECTION=8
# export NCCL_IB_SPLIT_DATA_ON_QPS=1
# export NCCL_MIN_NCHANNELS=4
# NOTE Torch 2.7 has issues to support commented options
# env - nvshmem
# export NVSHMEM_ENABLE_NIC_PE_MAPPING=1
# export NVSHMEM_HCA_LIST=$NCCL_IB_HCA
# export NVSHMEM_IB_GID_INDEX=3
# NOTE Torch 2.7 has issues to support commented options, see Appendix
Successful tuning should expect to see this:
In SGLang v0.4.8, DeepGEMM is by default not in use, and there is no tunning configs for fused MoE triton kernels running in H800.
So we fine tuned fused MoE triton kernels to generate triton kernel configs for H800 and enable DeepGEMM JIT GEMM kernel.
Due to the system memory limit in H800, depolyment unit for Prefill and Decode are carefully selected from :
| Deploy Unit | TP | E(D)P | |
|---|---|---|---|
| H100 / H800 | 2+X | 16 + 8 X | 16 + 8 X |
| H200 / H20 / B200 | 2+Y | 8 + 8 Y | 8 + 8 Y |
In our testing scripts, we classified configs as scaling config, model info, server info, basic config, disaggregation config, tuning parameters, envrionmental variables.
Common Basic Config
#### Scaling config
RANK=${RANK:-0}
WORLD_SIZE=${WORLD_SIZE:-2}
TP=${TP:-16} # 32
DP=${DP:-1} # 32
#### Model config
bs=${bs:-128} # 8192
ctx_len=${ctx_len:-65536} # 4096
#### Basic config
concurrency_opt=" \
--max-running-requests $bs
"
if [ "$DP" -eq 1 ]; then
dp_attention_opt=""
dp_lm_head_opt=""
deepep_moe_opt=""
else
dp_attention_opt=" \
--enable-dp-attention \
"
dp_lm_head_opt=" \
--enable-dp-lm-head \
"
# in this test, we use deep-ep==1.1.0+c50f3d6
# decode is in low_latency mode
deepep_moe_opt=" \
--enable-deepep-moe \
--deepep-mode normal \
"
fi
log_opt=" \
--decode-log-interval 1 \
"
timeout_opt=" \
--watchdog-timeout 1000000 \
"
# dp_lm_head_opt and moe_dense_tp_opt are needed
dp_lm_head_opt=" \
--enable-dp-lm-head \
"
moe_dense_tp_opt=" \
--moe-dense-tp-size ${moe_dense_tp_size} \
"
page_opt=" \
--page-size ${page_size} \
"
radix_cache_opt=" \
--disable-radix-cache \
"
##### Optimization Options
batch_overlap_opt=" \
--enable-two-batch-overlap \
"
#### Disaggregation config
ib_devices="mlx5_0,mlx5_3,mlx5_4,mlx5_5,mlx5_6,mlx5_9,mlx5_10,mlx5_11"
disaggregation_opt=" \
--disaggregation-ib-device ${ib_devices} \
--disaggregation-mode ${disaggregation_mode} \
"
These common configs for prefill and decode disaggregation roles contain tunnable parameters WORLD_SIZE, TP, DP, max_running_request_size, page_size.
max_running_request_size affects the batch size and buffer size. Page size affects number tokens transfered. We recommend to set max_running_request_size to 128, and page_size to 32.
For Prefill node, deepep_mode is set to normal, while in decode node, is set to low_latency:
| deepep mode | input | ouput | cuda graph | |
|---|---|---|---|---|
| prefill | normal | long | short (1) | --disable-cuda-graph |
| deocde | low-latency | short | very long | --cuda-graph-bs 256,128,64,32,16,8,4,2,1 |
Moreover, it is alwasy better for prefill nodes to set small to middle chunk-prefill size to reduce TTFT.
Besides, prefill-decode configs, expert parallel load balance should be configured :
#### expert distribution options
if [ "$deepep_moe_opt" != "" ]; then
if [ "$stage" == "create_ep_dis" ]; then
create_ep_dis_opt=" \
--expert-distribution-recorder-mode stat \
--disable-overlap-schedule \
--expert-distribution-recorder-buffer-size -1 \
"
expert_distribution_opt=""
else
create_ep_dis_opt=""
expert_distribution_opt=" \
--init-expert-location ${EXPERT_DISTRIBUTION_PT_LOCATION} \
"
fi
fi
# --enable-tokenizer-batch-encode \
nccl_opts=" \
--enable-nccl-nvls \
"
#### EP Load balance - Prefill
if [ "$deepep_moe_opt" == "" ]; then
moe_dense_tp_opt=""
eplb_opt=""
else
moe_dense_tp_opt=" \
--moe-dense-tp-size ${moe_dense_tp_size} \
"
deepep_opt=" \
--deepep-config $DEEP_EP_CFG \
"
ep_num_redundant_experts_opt=" \
--ep-num-redundant-experts 32 \
"
rebalance_iters=1024
eplb_opt=" \
--enable-eplb \
--eplb-algorithm deepseek \
--ep-dispatch-algorithm dynamic \
--eplb-rebalance-num-iterations $rebalance_iters \
$ep_num_redundant_experts_opt \
$deepep_opt \
"
fi
#### EP Load balance - Decode
deepep_opt=""
eplb_opt=" \
$ep_num_redundant_experts_opt \
"
So the full config in test is hereby:
#### Full Basic Common Config
basic_config_opt=" \
--dist-init-addr $MASTER_ADDR:$MASTER_PORT \
--nnodes ${WORLD_SIZE} --node-rank $RANK --tp $TP --dp $DP \
--mem-fraction-static ${memory_fraction_static} \
$moe_dense_tp_opt \
$dp_lm_head_opt \
$log_opt \
$timeout_opt \
$dp_attention_opt \
$deepep_moe_opt \
$page_opt \
$radix_cache_opt \
--trust-remote-code --host "0.0.0.0" --port 30000 \
--log-requests \
--served-model-name DeepSeek-0324 \
--context-length $ctx_len \
"
#### Prefill Config
chunk_prefill_opt=" \
--chunked-prefill-size ${chunked_prefill_size} \
"
max_token_opt=" \
--max-total-tokens 131072 \
"
ep_num_redundant_experts_opt=" \
--ep-num-redundant-experts 32 \
"
prefill_node_opt=" \
$disaggregation_opt \
$chunk_prefill_opt \
$max_token_opt \
--disable-cuda-graph
"
# optional for prefill node
prefill_node_opt=" \
$prefill_node_opt \
--max-prefill-tokens ${max_prefill_tokens} \
"
#### Decode Config
decode_node_opt=" \
$disaggregation_opt \
--cuda-graph-bs {cubs} \
"
Envrionmental Variables
Now SGLang enables GEMM kernels from DeepGEMM, since prefill as we observed, will always be the bottlenect of system goodput when batch size exceeds some level, we enable faster implementation of GEMM from DeepGEMM, moon-cake (0.3.4) as default.
These are controled by envrionmental variables.
#### SGLang env
MC_TE_METRIC=true
SGLANG_TBO_DEBUG=1
export MC_TE_METRIC=$MC_TE_METRIC
export SGLANG_TBO_DEBUG=$SGLANG_TBO_DEBUG
export SGL_ENABLE_JIT_DEEPGEMM=1
export SGLANG_SET_CPU_AFFINITY=1
export SGLANG_DEEPEP_NUM_MAX_DISPATCH_TOKENS_PER_RANK=256
export SGLANG_HACK_DEEPEP_NEW_MODE=0
export SGLANG_HACK_DEEPEP_NUM_SMS=8
export SGLANG_DISAGGREGATION_BOOTSTRAP_TIMEOUT=360000
# env - nccl
export NCCL_IB_HCA=mlx5_0,mlx5_3,mlx5_4,mlx5_5,mlx5_6,mlx5_9,mlx5_10,mlx5_11
export NCCL_IB_GID_INDEX=3
export NCCL_SOCKET_IFNAME=ibp24s0,ibp41s0f0,ibp64s0,ibp79s0,ibp94s0,ibp154s0,ibp170s0f0,ibp192s0
Tunning parameters.
The basic tunning parameters are world sizes of prefill nodes and decode nodes : P${P}D${D}. We iterative over different P/D disaggregation settings to find reasonable server side partitions for an optimized goodput rate observed in client side benchmarking.
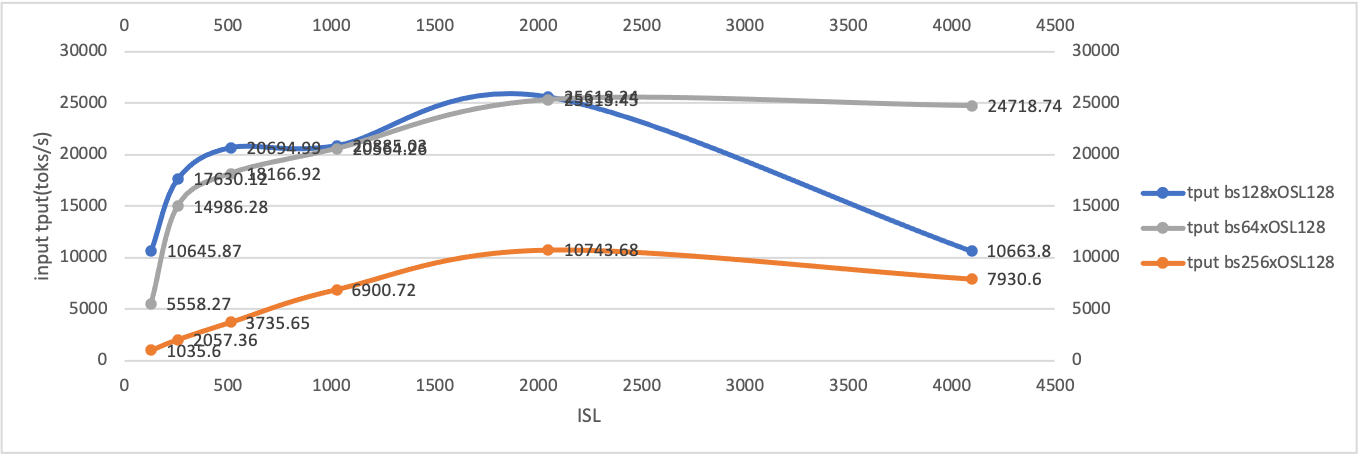
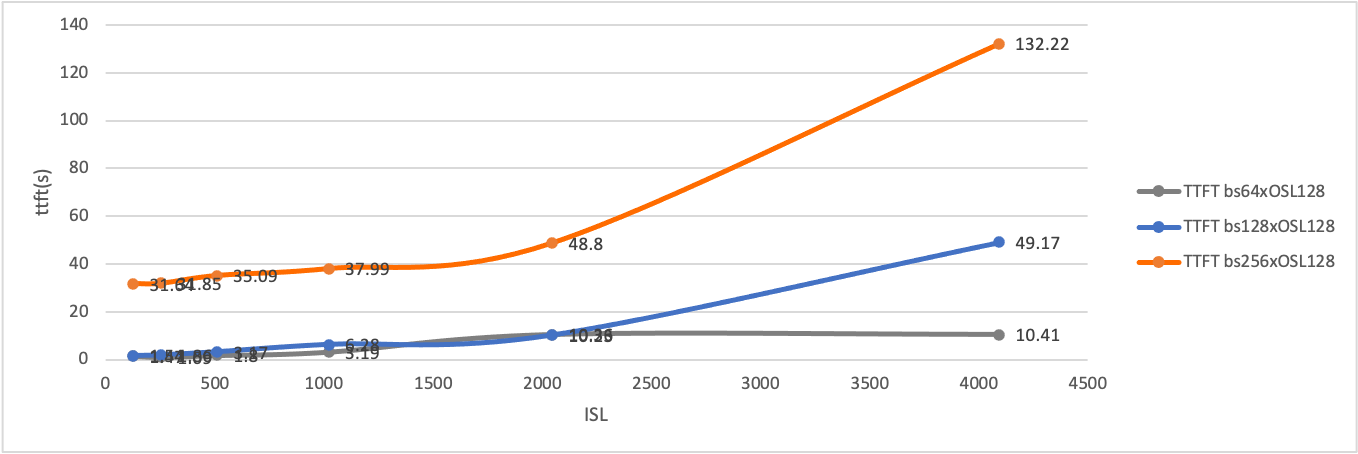
Though we didn't achieve deepseek performance under SLO, we found P4D6 and (P3x3)D4 output performs of P4D9 in goodput, with 1024 batch size, 1K input / 256 output to generate 95 k toks/sec input throughput, 20 k toks/sec output throughput at maximum of 356 MB/sec transfer speed, and 9~10s TTFT, less than 30% of total latency.
#### Scaling config
RANK=${RANK:-0}
WORLD_SIZE=${WORLD_SIZE:-2}
TP=${TP:-16} # 32
DP=${DP:-1} # 32
#### Model config
bs=${bs:-128} # 8192
# ctx_len=${ctx_len:-65536}
ctx_len=4096
#### Tunning info
EXPERT_DISTRIBUTION_PT_LOCATION="./attachment_ep_statistics/decode_in1000out1000.json"
# NOTE (yiakwy) : create in 'create_ep_dis' stage
moe_dense_tp_size=${moe_dense_tp_size:-1}
page_size=${page_size:-1}
cubs=${cubs:-256}
memory_fraction_static=${memory_fraction_static:-0.81}
Additional Options
MTP
In our initial attempt (thanks to Yujie Pu), MTP decoding (with deepseek draft model) does not show improvement for the overall goodput, we will invesigate it later:
Benchmarking of P/D
P2D2
For P2D2 configuation, due to limited space reserved for KV cache (P node 65 GB / 79 Gb, D node 70 GB / 79 GB HBM utilization), we frequently see KV cache OOM for batch size 1024 in client side. And when batch size * input length > 128, we observed steep growth of TTFT and unreliable measurement of output throughput in SGLang :
| batch_size | Input | Output | latency | Input throughput | Output throughput | Overal throughput | TTFT (95) (s) | MAX transfer (MB/s) | last toks generation (toks/sec) | comment |
|---|---|---|---|---|---|---|---|---|---|---|
| 1024 | 1024 | 1 | 72.97 | 14,370.73 | 1,367,184.47 | 14,384.62 | 72.7 | 109.82 | 22.19 | |
| 1024 | 1024 | 32 | exception KVTransferError(bootstrap_room=8053843183886796622): Request 8053843183886796622 timed out after 120.0s in KVPoll.Bootstrapping", 'status_code': 500, 'err_type': None}, 'prompt_tokens': 512, 'completion_tokens': 0, 'cached_tokens': 0, 'e2e_latency': 124.1377534866333}} | |||||||
| 1024 | 512 | 32 | 52.38 | 10,341.56 | 19,519.12 | 10,635.72 | 50.7 | 144.17 | 19.4 | |
| 1024 | 512 | 128 | 68.95 | 8,418.81 | 19,640.21 | 9,504.93 | 62.28 | 54.92 | 99.08 | |
| 1024 | 512 | 512 | exception KVTransferError(bootstrap_room=8053843183886796622): Request 8053843183886796622 timed out after 120.0s in KVPoll.Bootstrapping", 'status_code': 500, 'err_type': None}, 'prompt_tokens': 512, 'completion_tokens': 0, 'cached_tokens': 0, 'e2e_latency': 124.1377534866333}} | |||||||
| 1024 | 128 | 128 | 72.37 | 1,971.51 | 22,267.64 | 3,622.32 | 66.48 | 89.23 | 147.64 | |
| 512 | 256 | 256 | ||||||||
| 256 | 128 | 128 | 47.3 | 799.71 | 5,184.33 | 1,385.67 | 40.98 | 36.04 | 222.95 | |
| 128 | 128 | 128 | 49.64 | 389.53 | 2161.38 | 42.06 | 42.88 | |||
| 64 | 128 | 128 | 9.05 | 5365.11 | 1089.32 | 1.53 | 39.74 | |||
| 64 | 128 | 256 | 16.76 | 4678.39 | 1091.4 | 1.75 | 19.06 | |||
| 64 | 128 | 512 | 32.42 | 3638.99 | 1086.33 | 2.25 | 16.96 | |||
| 8 | 128 | 128 | 7.02 | 1464.24 | 162.07 | 0.7 | 16.95 | |||
| 64 | 256 | 128 | 9.88 | 6782.64 | 1097.06 | 2.42 | 20.28 | |||
| 64 | 512 | 128 | 12.65 | 5934.04 | 1149.83 | 5.52 | 16.94 | |||
| 64 | 1024 | 128 | 28.09 | 3064.63 | 1221.39 | 21.38 | 19.49 |
Based on this observations, later we classified our online tests input in user side into two catgories :
short queries (in_seq_len < 128) to achieve hight goodput rate for at maximum 128 concurrencies;
long queries, maximum of throughput, and maximum 120s to return
When batch size * input length exceed 128 x 128 for P2D2, transfering KV cache block inference speed, then whole system becomes network IO bound in data plane.
Mooncake developers identified performance issue of transfering engine in PR#499 and quickly integrated the new batched transfering feature into SGLang v0.4.8 (also need to install transfer-engine==0.3.4) in PR#7236.
Althought, 10x boost from transfering engine, network IO bound in data plane is ubiquitous in different P/D settings.
If not consider goodput rate under SLO, it is easy to obtain max input throughput 45 k toks/sec. As we analyzed above the output throughput is bounded by TTFT, hence the measurement is not accurate.
Notablly, when input sequence length over output length has the raio of 4:1, in this H800 SuperPod machine, the utilization of GPU arrives its best, and maximum of last token generation speed arrives:

P2D4/P4D2
In P2D4 and P4D2 test, one of the objects is to determine scaling direction to reduce TTFT and maximum goodput. To reduce TTFT, as we discussed in Motivation Section, one of option is to reduce Chunk-prefill size, and reduce data parallel for prefill nodes.
| Chunk prefill size | batch_size | Input | Output | latency | Input Tput | Output Tput | TTFT (95) (s) | last_gen_throughput (toks/sec) |
|---|---|---|---|---|---|---|---|---|
| Large | 64 | 128 | 128 | 44.74 | 235.92 | 817.68 | 34.72 | 66.61 |
| Small | 64 | 128 | 128 | 8.16 | 4820.89 | 1268.5 | 1.7 | 24.01 |
| Large | 128 | 128 | 128 | 13.78 | 3055.26 | 1947.41 | 5.36 | 20.79 |
| Small | 128 | 128 | 128 | 9.96 | 5425.92 | 2358.96 | 3.02 | 22.62 |
Data parallel and dp attention (DP > 1) must be turned on, otherwise, we shall see significant degradation of TTFT and goodput rate:
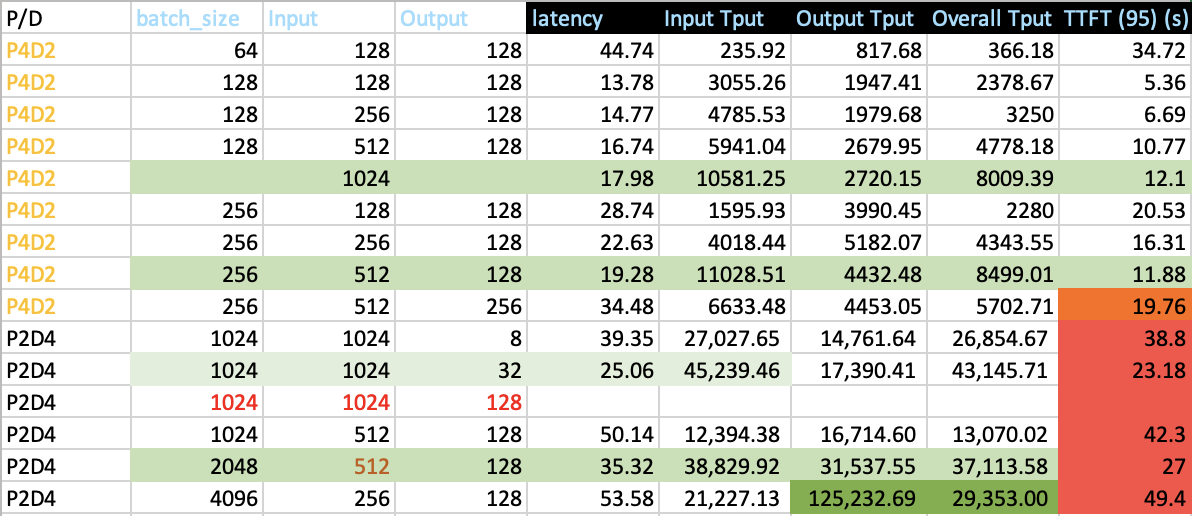
From the statistics collected above, we conclude that to support input sequence length more than 1024 in P2D4, most of running time spent in prefill stage, hence TTFT is very close to the overall latency.
Hence we consider to expand percentage of prefill nodes r (r > 1, r < 2).
P4D6

For P4D6 disaggregation test, average TTFT is raised up to 10s, and when batch size * input_length > 2048 * 1024, TTFT grows along a sharp slope rate.
P4D9
P4D9 is gold configuration recommended by SGLang team [8], however in our test, it does not generate acceptable goodput rate and its overall throughput is limited to 80 k toks / sec at 4 K input, 256 output length :

We verified this in online test for P4D9 disaggregation config in user side. For short queries, maximum 8 k toks /sec observed in user side (user's SDK) :
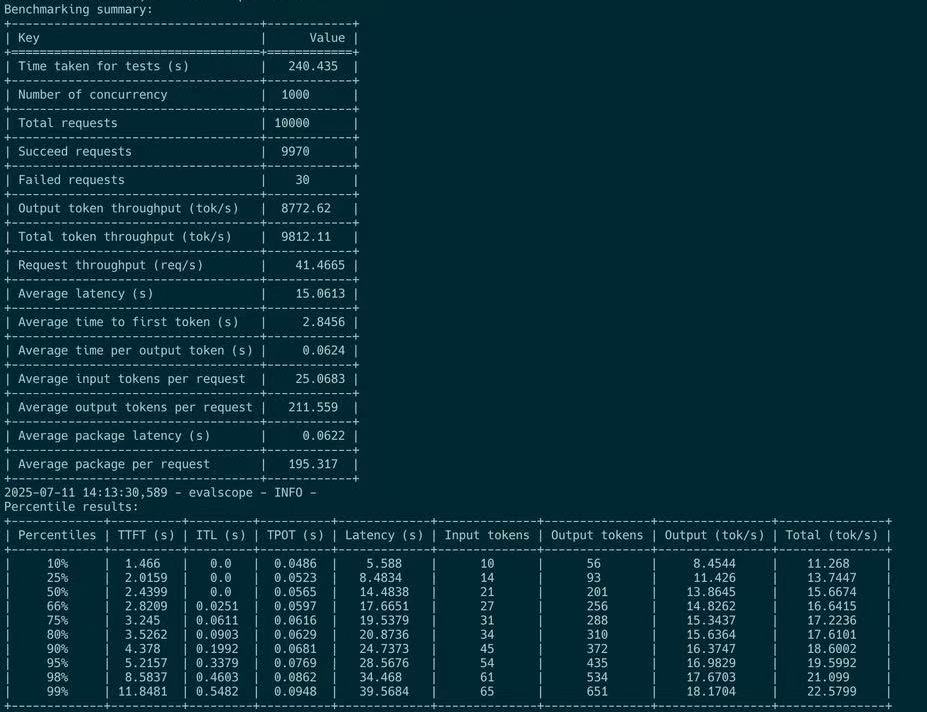
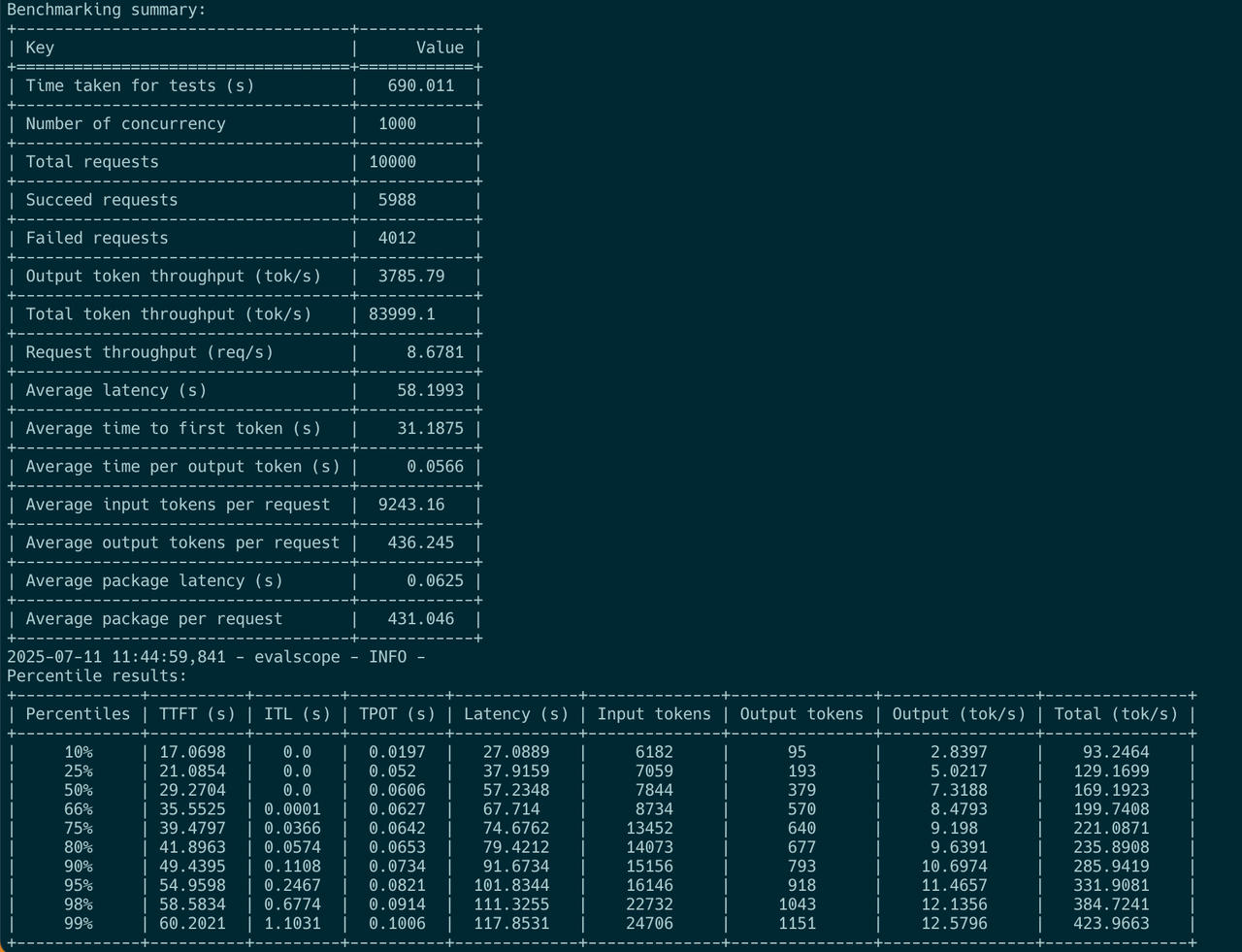
When it comes to long query, only maximum 400 toks / sec observed in user side (user's SDK) :
Conclusion
We make comprehensive study of hosting DeepSeek V3 671 B alike model in a disaggregated serving architecture with SGLang V0.4.8 with 13x8 H800 SuperNodes.
We first concluded and verified that larger prefill groups — preferably with a prefill-to-decode group ratio of 3:1 — and smaller TP sizes — preferably with a total prefill-to-decode node ratio of 1:1 —, generate better TTFT and higher goodput.
We second verified the P/D setting for large MoE models that leads to sharp TTFT growth when input length * batch size exceed certain number, we should limit max_running_request_size in actual deployment.
To improve TTFT and compute efficiency of prefill nodes, we choose smaller chunked-prefill sizes.
This configuration generates almost 80 k toks / sec overall goodput and observed 8 k toks / sec in user side for short queries, compared to maximum of 10 k overall goodput per 2xH800 colocated deployment unit, much smaller throughput limits.
Future Work
Disaggregated serving architecture exposes multiple nodes as a deployment unit. It exploits the distinct computational characteristics of the prefill and decoding stages, and delivers significantly better overall goodput compared to traditional colocated serving architectures.
However, a larger deployment unit also introduces greater risk — if even a single card requires repair, the entire unit may be affected. Therefore, selecting a reasonable unit size while maintaining competitive goodput is critical for the success of this solution in real-world deployments.
Next, we focus on communication-level libraries to unlock the full potential of prefill nodes and further reduce TTFT.
Acknowledgement
Thanks to Mr Yiwen Wang (yepmanwong@hkgai.org) and Prof Wei Xue (weixue@ust.hk) for the support and suggestion for this article, and to Andy Guo (guozhenhua@hkgai.org) for user side tests, Yu Jiepu (yujiepu@hkgai.org) for the deployment to verify effectiveness of MTP and (P3x3)D4, and to Yi Chao (chao.yi@hkgai.org) for help of arrangement of resources.
Appendix
Prefill decode nodes Colocated H800 X 2 test full reference
| bs | input_lenght | output_length | latency (s) | input throughput (toks/sec) | output throughput (toks/sec) | ttft (s) | last tok generation (tok/s) |
|---|---|---|---|---|---|---|---|
| 1 | 128 | 1 | 13.94 | 9.18 | N/A | 13.94 | N/A |
| 1 | 128 | 128 | 24.85 | 74.75 | 5.53 | 1.71 | |
| 2 | 128 | 128 | 27.45 | 242.48 | 9.7 | 1.06 | 5.05 |
| 8 | 128 | 128 | 29.41 | 464.39 | 37.64 | 2.21 | 37.64 |
| 64 | 128 | 128 | 31.33 | 5558.27 | 274.38 | 1.47 | 150.97 |
| 128 | 128 | 128 | 30.1 | 10645.87 | 573.56 | 1.54 | 297.73 |
| 256 | 128 | 128 | 59.03 | 1035.6 | 1196.2 | 31.64 | 300.72 |
| 512 | 128 | 128 | 118.87 | 728.24 | 2269.65 | 89.99 | 293.69 |
| 1024 | 128 | 128 | 232.41 | 638.05 | 4857.73 | 205.42 | 302.01 |
| 2048 | 128 | 128 | 463.71 | 604.48 | 8727.43 | 433.67 | 284.32 |
| 256 | 128 | 64 | 32.05 | 1888.49 | 1114.7 | 17.35 | 262.18 |
| 256 | 128 | 32 | 17.94 | 2996.34 | 1169.3 | 10.94 | 17.57 |
| 256 | 128 | 16 | 9.85 | 4944.47 | 1269.26 | 6.63 | 17.57 |
| 256 | 128 | 8 | 6.3 | 6804.99 | 1376.58 | 4.82 | 17.57 |
| 256 | 128 | 4 | 4.54 | 9268.11 | 1014.83 | 3.54 | 17.57 |
| 256 | 128 | 2 | 3.27 | 11221.3 | 1483.17 | 2.92 | 17.57 |
| 256 | 128 | 1 | 3.67 | 8931.5 | N/A | 3.67 | 17.57 |
Reference
[1]: Instruction for Running DeepSeek with Large-scale PD and EP, https://github.com/sgl-project/sglang/issues/6017, retrieved on 12 July 2025.
[2]: Evaluation Framework for Large Models, ModelScope team, 2024, https://github.com/modelscope/evalscope, retrieved on 12 July 2025.
[3]: Orca : A Distributed Serving System for transformer-Based Generative Models, https://www.usenix.org/conference/osdi22/presentation/yu, Gyeong-In Yu and Joo Seong Jeong and Geon-Woo Kim and Soojeong Kim and Byung-Gon Chun, OSDI 2022, https://www.usenix.org/conference/osdi22/presentation/yu
[4]: SARATHI : efficient LLM inference by piggybacking decodes with chunked prefills, https://arxiv.org/pdf/2308.16369
[5]: DistServe : Disaggregating Prefill and Decoding for Goodput-optimized large language model serving, Yinmin Zhong, Shengyu Liu, Junda Chen, Jianbo Hu, Yibo Zhu, Xuanzhe Liu, Xin Jin, Hao Zhang, 6 Jun 2024, https://arxiv.org/pdf/2401.09670
[6]: Throughput is Not All You Need : Maximizing Goodput in LLM Serving using Prefill-decode Disaggregation, Junda Chen, Yinmin Zhong, Shengyu Liu, Yibo Zhu, Xin Jin, Hao Zhang, 3 March 2024, accessed online on 12 July 2025.
[7]: MoonCake transfer engine performance : https://kvcache-ai.github.io/Mooncake/performance/sglang-benchmark-results-v1.html, accessed online 18 july 2025
[8]: https://lmsys.org/blog/2025-05-05-large-scale-ep/, accessed online on 12 July 2025
[9]: DeepSeek OpenWeek : https://github.com/deepseek-ai/open-infra-index?tab=readme-ov-file
[10]: SGLang genai-bench : https://github.com/sgl-project/genai-bench, accessed online on 18 July
[11]: https://github.com/ai-dynamo/dynamo/blob/main/docs/images/dynamo_flow.png, accessed online on 18 July
{kind=link}
Sponsor Sources
Also see Github