
File size: 1,811 Bytes
d625fb9 e02dbe8 |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 |
---
license: mit
tags:
- language-model
- instruction-tuning
- lora
- tinyllama
- text-generation
---
# TinyLlama-1.1B-Chat LoRA Fine-Tuned Model
## Table of Contents
- [Model Overview](#overview)
- [Key Features](#key-features)
- [Installation](#installation)
## Overview
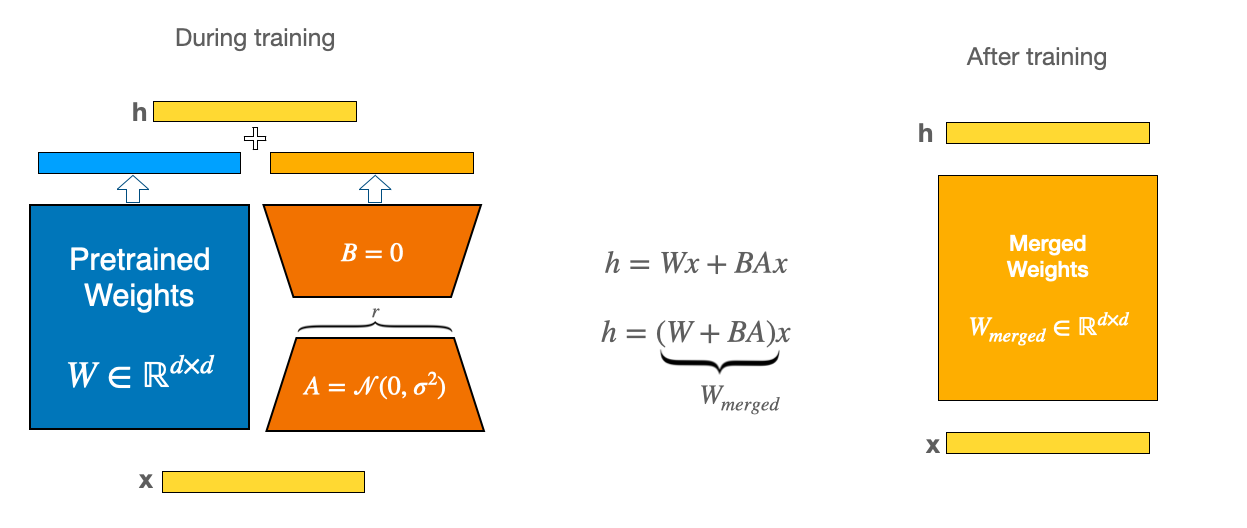
This repository contains a LoRA (Low-Rank Adaptation) fine-tuned version of the `TinyLlama/TinyLlama-1.1B-Chat-v0.6` model, optimized for instruction-following and question-answering tasks. The model has been adapted using Parameter-Efficient Fine-Tuning (PEFT) techniques to specialize in conversational AI applications while maintaining the base model's general capabilities.
### Model Architecture
- **Base Model**: TinyLlama-1.1B-Chat (Transformer-based)
- **Layers**: 22
- **Attention Heads**: 32
- **Hidden Size**: 2048
- **Context Length**: 2048 tokens (limited to 256 during fine-tuning)
- **Vocab Size**: 32,000
## Key Features
- 🚀 **Parameter-Efficient Fine-Tuning**: Only 0.39% of parameters (4.2M) trained
- 💾 **Memory Optimization**: 8-bit quantization via BitsAndBytes
- ⚡ **Fast Inference**: Optimized for conversational response times
- 🤖 **Instruction-Tuned**: Specialized for Q&A and instructional tasks
- 🔧 **Modular Design**: Easy to adapt for different use cases
- 📦 **Hugging Face Integration**: Fully compatible with Transformers ecosystem
## Installation
### Prerequisites
- Python 3.8+
- PyTorch 2.0+ (with CUDA 11.7+ if GPU acceleration desired)
- NVIDIA GPU (recommended for training and inference)
### Package Installation
```bash
pip install torch transformers peft accelerate bitsandbytes pandas datasets |